Command Palette
Search for a command to run...
Fast-ThinkAct:通过可表述的潜在规划实现高效的视觉-语言-动作推理
Fast-ThinkAct:通过可表述的潜在规划实现高效的视觉-语言-动作推理
Chi-Pin Huang Yunze Man Zhiding Yu Min-Hung Chen Jan Kautz Yu-Chiang Frank Wang Fu-En Yang
摘要
视觉-语言-动作(Vision-Language-Action, VLA)任务要求在复杂视觉场景中进行推理,并在动态环境中执行自适应动作。尽管近期关于推理型VLA的研究表明,显式的思维链(Chain-of-Thought, CoT)能够提升模型的泛化能力,但其因推理过程冗长而导致推理延迟较高。为此,我们提出Fast-ThinkAct——一种高效的推理框架,通过可表述的隐式推理实现紧凑而高效的规划。Fast-ThinkAct通过知识蒸馏从教师模型中学习,采用偏好引导的目标函数,使操作轨迹在迁移过程中同时保留语言与视觉层面的规划能力,从而实现对具身控制的跨模态规划能力对齐。该机制支持增强型推理策略学习,有效将紧凑的推理过程与动作执行相连接。在多种具身操作与推理基准任务上的大量实验表明,Fast-ThinkAct在保持强大长时程规划能力、少样本适应性及故障恢复能力的同时,相较于当前最先进的推理型VLA模型,推理延迟最高降低达89.3%。
一句话总结
作者来自英伟达及多家机构,提出 Fast-ThinkAct,一种紧凑的推理框架,通过偏好引导的目标从教师模型中提炼潜在的思维链推理,实现高效、高性能的具身控制,在推理延迟上相比先前的推理型视觉-语言-动作(VLA)模型降低高达 89.3%,同时保持长时程规划、少样本适应和失败恢复能力,适用于多样化的操作任务。
主要贡献
- 视觉-语言-动作(VLA)任务需要在复杂视觉场景中进行鲁棒推理,并在动态环境中执行自适应动作,但现有依赖于冗长显式思维链(CoT)的推理型 VLA 存在高推理延迟问题,限制了其在实时具身系统中的应用。
- Fast-ThinkAct 引入一种紧凑的推理框架,通过偏好引导的目标从教师模型中提炼出高效且可表述的潜在推理,利用轨迹级监督对齐语言与视觉规划,以保留关键的空间-时间动态。
- 在多个具身操作与推理基准上的实验表明,Fast-ThinkAct 相比最先进推理型 VLA 将推理延迟降低高达 89.3%,同时在长时程规划、少样本适应和失败恢复方面保持优异性能。
引言
视觉-语言-动作(VLA)模型使具身智能体能够对复杂视觉场景进行推理并执行自适应动作,但先前增强推理的方法依赖于冗长的思维链(CoT)轨迹,引入了高推理延迟,阻碍了机器人操作和自动驾驶等实时应用。尽管监督学习和强化学习方法提升了泛化能力,但在压缩推理时往往效率低下且性能下降。作者提出 Fast-ThinkAct,通过偏好引导的蒸馏与视觉轨迹对齐,将显式文本推理蒸馏为紧凑、可表述的潜在表示。该方法通过在连续潜在空间中编码语言与视觉推理,实现高效、高保真的规划,再通过一个表述器将潜在表示解码为可解释语言,同时保持动作准确性。结果表明,相比最先进推理型 VLA,推理延迟降低高达 89.3%,并保持长时程规划、少样本适应和失败恢复能力。
数据集

- 数据集包含多个来源的训练与评估数据,包括来自 OXE 数据集(O'Neill et al., 2024)中 MolmoAct(Lee et al., 2025)的单臂视觉轨迹、来自 AIST 数据集(Motoda et al., 2025)的双臂轨迹,以及来自 PixMo(Deitke et al., 2024)、RoboFAC(Lu et al., 2025)、RoboVQA(Sermanet et al., 2024)、ShareRobot(Ji et al., 2025)、EgoPlan(Chen et al., 2023)和 Video-R1-CoT(Feng et al., 2025)的问答任务。
- 单臂子集包含约 130 万条 2D 视觉轨迹,来自 MolmoAct;双臂子集包含约 9.2 万条双臂轨迹,从 AIST 中提取。轨迹通过 Molmo-72B 检测首帧夹爪位置,并使用 CoTracker3 实现视频序列的端到端跟踪。
- 训练阶段,作者在约 400 万条样本上进行监督微调,结合上述来源的视觉轨迹与问答数据,构建基础的具身知识。
- 为增强推理能力,作者使用 20 万条样本(SFT 数据的 5%)进行思维链监督微调,并结合 Video-R1-CoT 提供的 16.5 万条高质量 CoT 标注样本。提示词结构设计为在
<reasoning>标签中激发推理,在<answer>标签中输出答案,非 CoT 数据则直接使用答案。 - 模型训练采用这些数据集的混合,其中 PixMo 用于保持通用视觉理解,并防止在具身任务训练中发生灾难性遗忘。
- 评估在四个具身推理基准上进行:EgoPlan-Bench(Qiu et al., 2024)、RoboVQA、OpenEQA(Majumdar et al., 2024)和 RoboFAC;以及三个机器人操作基准:SimplerEnv(Li et al., 2024)、LIBERO(Liu et al., 2023)和 RoboTwin2.0(Chen et al., 2025),任务成功率作为操作任务的主要评估指标。
方法
作者采用两阶段框架,实现具身任务中的高效推理与动作执行。整体架构如图所示,包含一个生成紧凑视觉计划的推理模块和一个将计划转化为可执行动作的策略模块。框架以一个文本教师 VLM,FθT,为起点,处理观测 ot 和指令 l,生成显式推理链,包括表示预期视觉轨迹的一系列航点。该教师模型通过轨迹级奖励进行训练,以确保视觉规划的合理性。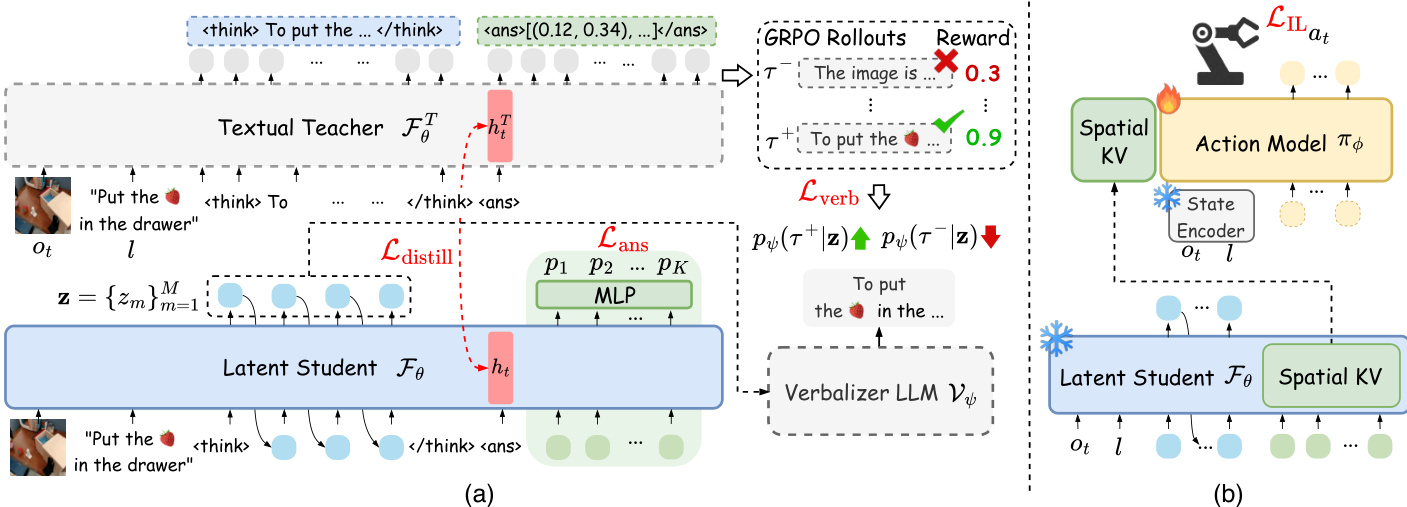
方法的核心是潜在学生 VLM,Fθ,它将教师的推理蒸馏到紧凑的潜在空间中。该蒸馏过程由基于偏好的损失 Lverb 引导,该损失使用一个表述器大语言模型 Vψ,将学生潜在标记 z 解码为文本,并与教师的推理链进行比较。为确保学生捕捉到视觉规划能力,作者引入动作对齐的视觉计划蒸馏 Ldistill,通过最小化教师与学生在 <answer> 标记隐藏状态之间的 L2 距离,对齐其轨迹级表示。为实现视觉轨迹的高效并行预测,学生在推理潜在序列后附加 K 个可学习的空间标记。每个空间标记的输出隐藏状态通过 MLP 映射为一个航点,损失 Lans 计算为预测航点与真实航点之间的 L2 距离。学生总训练目标为三部分之和:Lstudent=Lverb+Ldistill+Lans。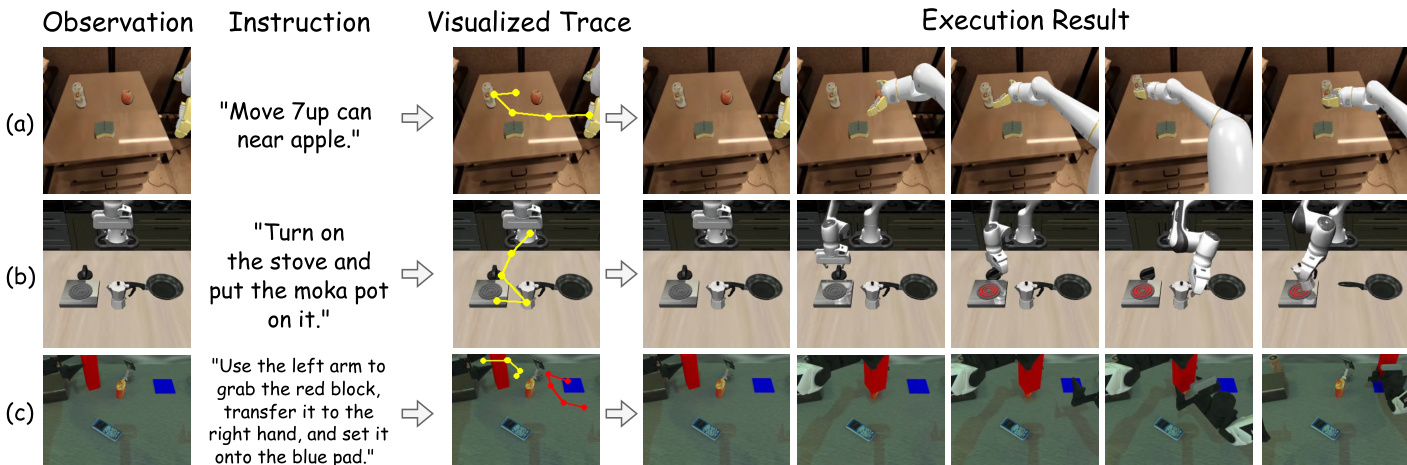
在学生生成视觉计划潜在表示 ct 后,框架进入动作执行阶段。视觉潜在计划 ct 从学生 VLM 中空间标记的键值缓存中提取,并用于条件化一个基于扩散 Transformer 的动作模型 πϕ。该动作模型通过模仿学习目标 LIL 进行训练,冻结学生 VLM 和状态编码器,仅更新动作模型参数。动作模型的交叉注意力机制同时关注视觉规划上下文与状态观测,有效连接高层视觉规划与底层动作生成。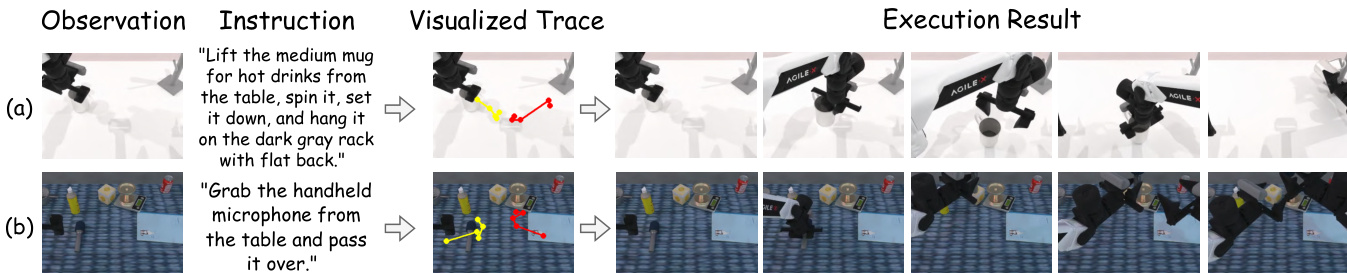
推理阶段流程被大幅简化。学生 VLM 处理观测与指令,通过空间标记生成紧凑的视觉计划。随后提取视觉潜在计划 ct,用于条件化动作模型,预测下一步动作 at。该推理流程仅需学生 VLM 与动作模型,无需在推理时使用表述器(仅在训练阶段使用)。作者报告,该方法相比最先进推理型 VLA 实现高达 89.3% 的推理延迟降低,同时在多样化的具身基准上保持强大性能。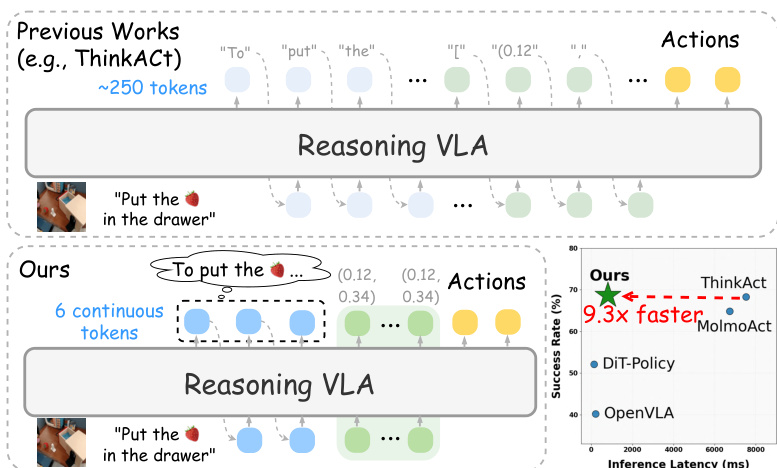
实验
- 在机器人操作基准 LIBERO、SimplerEnv 和 RoboTwin2.0 上评估,Fast-ThinkAct 达到最先进成功率,优于 OpenVLA、CoT-VLA、ThinkAct 和 MolmoAct,相比 ThinkAct-7B 和 ThinkAct-3B 分别实现 89.3% 和 88.0% 的延迟降低,推理速度提升 7 倍。
- 在 RoboTwin2.0 上,Fast-ThinkAct 在简单与困难设置下分别比 RDT 提高 9.3% 和 3.6%,比 ThinkAct 提高 3.3% 和 1.7%,同时保持卓越效率。
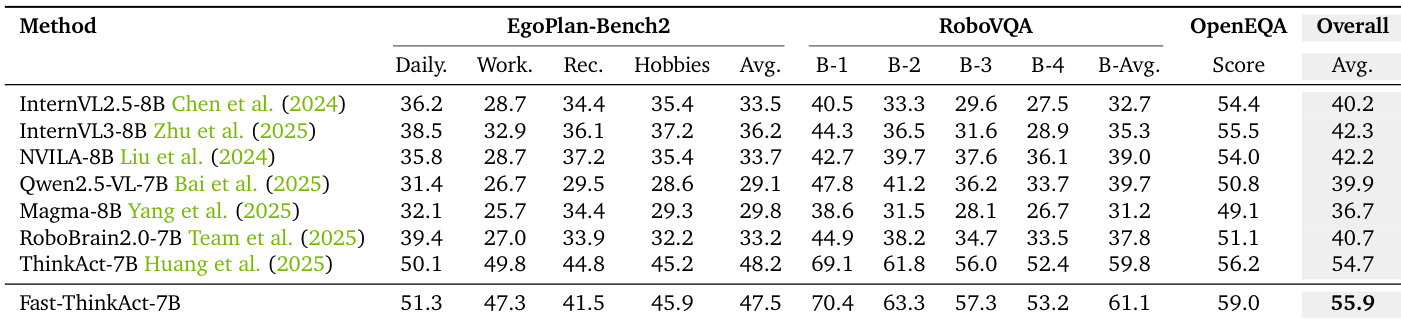
- 在 EgoPlan-Bench2、RoboVQA 和 OpenEQA 上展现出强大的具身推理能力,超越所有基线模型(包括 GPT-4V 和 Gemini-2.5-Flash),在 EgoPlan-Bench2 上提升 2.4%,RoboVQA 上 BLEU 提升 5.5,OpenEQA 上提升 1.1 分。
- 在长时程规划方面表现优异,在 RoboTwin2.0(简单/困难)的长时程任务上平均得分分别为 48.8 和 16.8,优于 RDT(35.0/12.3)和 ThinkAct(42.8/15.3),并实现准确的视觉轨迹预测。
- 在 RoboFAC 上表现出稳健的失败恢复能力,相比 RoboFAC-3B 在模拟与真实场景中分别提升 10.9 和 16.4 分,具备有效的根因分析与纠正规划能力。
- 在 RoboTwin2.0 上仅需 10 次示范即可实现强少样本适应能力,显著优于 pi0 和 ThinkAct,同时保持低推理延迟。
- 消融实验确认 Lverb 与 Ldistill 的必要性,M=6 个潜在推理步骤提供最优性能。
- 紧凑的潜在推理设计实现了高效、准确且可解释的推理,其表述化输出比教师生成文本更简洁、更相关。
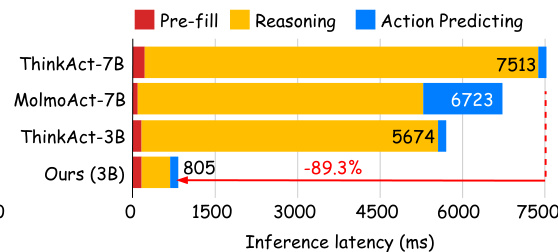
结果表明,Fast-ThinkAct 相比 ThinkAct-7B 和 MolmoAct-7B 显著降低推理延迟,延迟为 805 毫秒,比 ThinkAct-7B 降低 89.3%。作者利用此延迟降低,展示了显著的效率提升,同时保持竞争性性能。
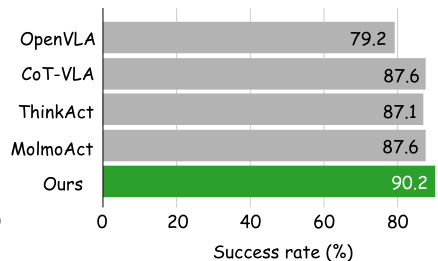
结果表明,Fast-ThinkAct 在评估的机器人操作任务上达到 90.2% 的成功率,优于 OpenVLA、CoT-VLA、ThinkAct 和 MolmoAct。作者利用此结果证明,其方法在性能上超越现有基于推理的视觉-语言-动作模型。
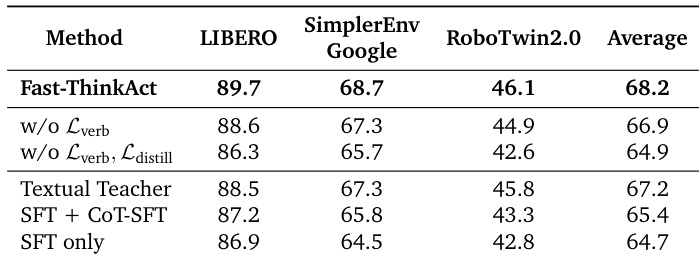
结果表明,Fast-ThinkAct 在所有评估基准上均取得最高成功率,平均得分为 68.2,优于所有消融变体与基线方法。消融实验表明,表述损失与蒸馏损失对维持高性能至关重要,其移除会导致成功率显著下降。
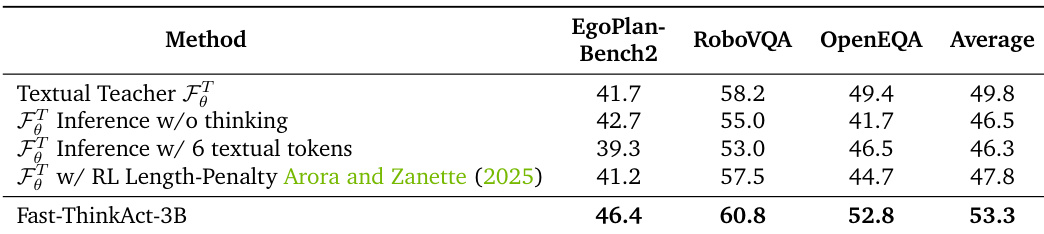
结果表明,Fast-ThinkAct-3B 在所有三个具身推理基准上均优于文本教师及其变体,尤其在 RoboVQA 和 OpenEQA 上取得最高分,证明紧凑潜在推理优于受限的文本推理方法。
结果表明,Fast-ThinkAct-7B 在具身推理基准上取得 55.9 的最高总分,超越所有对比方法,包括 GPT-4V 和 Gemini-2.5-Flash 等专有模型。其在总分上比第二名 ThinkAct-7B 高出 1.2 分,充分证明其在 EgoPlan-Bench2、RoboVQA 和 OpenEQA 上的卓越推理能力。