Command Palette
Search for a command to run...
DeepResearchEval:一种用于深度研究任务构建与代理评估的自动化框架
DeepResearchEval:一种用于深度研究任务构建与代理评估的自动化框架
Yibo Wang Lei Wang Yue Deng Keming Wu Yao Xiao Huanjin Yao Liwei Kang Hai Ye Yongcheng Jing Lidong Bing
摘要
深度研究系统广泛应用于多步骤网络调研、分析与跨源信息整合,然而其评估仍面临诸多挑战。现有基准测试通常依赖于大量人工标注来构建任务,评估维度固定不变,或在缺乏引用的情况下难以可靠验证事实。为弥补这些不足,我们提出 DeepResearchEval——一个用于深度研究任务构建与智能体式评估的自动化框架。在任务构建方面,我们提出一种基于角色(persona-driven)的流水线,能够生成基于多样化用户画像的、具有现实背景且复杂的科研任务。该流水线通过两阶段筛选机制——任务资格筛选(Task Qualification)与搜索必要性评估(Search Necessity)——仅保留那些需要多源证据融合与外部信息检索的任务。在评估方面,我们设计了一种智能体式评估流水线,包含两个核心组件:一是自适应逐项质量评估(Adaptive Point-wise Quality Evaluation),该组件能够根据每个生成任务动态推导出相应的评估维度、评判标准及权重;二是主动事实核查(Active Fact-Checking),该组件可在无引用信息的情况下,自主通过网络搜索提取并验证报告中的陈述内容,实现端到端的事实可靠性验证。
一句话总结
来自Infinity Lab、盛大集团和南洋理工大学的研究人员提出了DeepResearchEval,这是一个自动化框架,通过角色驱动生成真实且复杂的深度研究任务,并采用自适应、任务特定的质量评估与主动事实核查机制来评估基于大语言模型的智能体,无需引用即可验证主张,从而实现对多步骤网络研究系统的可靠评估。
主要贡献
-
我们提出了DeepResearchEval,一个自动化框架,通过角色驱动的流程生成真实且复杂的深度研究任务,克服了现有基准在标注负担和静态性方面的局限,利用多样化的用户画像和两阶段过滤流程,确保任务需要多源证据整合与外部检索。
-
该框架具备智能体式评估系统,采用自适应逐点质量评估,能够根据每个任务的具体上下文动态调整评估维度、标准和权重,相比固定、任务无关的基准,实现更细致且相关的评估。
-
框架包含主动事实核查功能,可自主提取并验证引用与未引用的主张,通过网络搜索进行验证,显著提升报告评估中的事实可靠性,即使原始来源未提供也有效。
引言
深度研究系统在需要规划、跨源整合与引用意识报告的复杂多步骤网络调查中日益普及。然而,评估这些系统仍面临挑战,主要源于人工密集型的任务标注、静态的评估标准以及有限的事实核查覆盖范围——尤其是针对未引用主张的情况。以往的基准往往无法捕捉现实世界的复杂性,或难以适应特定领域的细微差别,导致评估结果不一致且不完整。本文作者提出DeepResearchEval,一个通过角色驱动流程生成真实研究任务的自动化框架,确保任务需依赖多源证据与外部检索,通过两阶段过滤流程实现。在评估方面,提出一种智能体系统,其自适应、任务特定的质量维度动态源自查询内容,并配备主动事实核查模块,通过网络搜索自主验证引用与未引用主张,实现全面、无需参考的报告质量与事实准确性评估。
数据集

- 数据集包含从10个不同来源收集的深度研究系统输出,包括Gemini-2.5-Pro、通义千问、OpenAI Deep Research及其他八个系统,所有系统均通过自动化工具从其官网访问获取。
- 所有报告均采集于2025年,每个系统在一系列评估任务中提供响应。
- 平均输出长度差异显著:大多数系统生成的响应超过10,000个字符,而Gemini-2.5-Pro、通义千问和OpenAI Deep Research的输出明显更长,平均达到数万字符。
- 数据用于训练时采用混合比例,平衡各系统贡献,确保涵盖多样化的推理风格与输出结构。
- 未采用显式裁剪策略,而是保留原始输出并进行最小过滤,以完整保留上下文与深度。
- 元数据基于来源系统、任务类型与输出长度构建,支持下游分析与模型评估。
- 该数据集用于训练DeepSeek V3,其开发耗资约560万美元计算资源,使用2,788百万H800 GPU小时。
方法
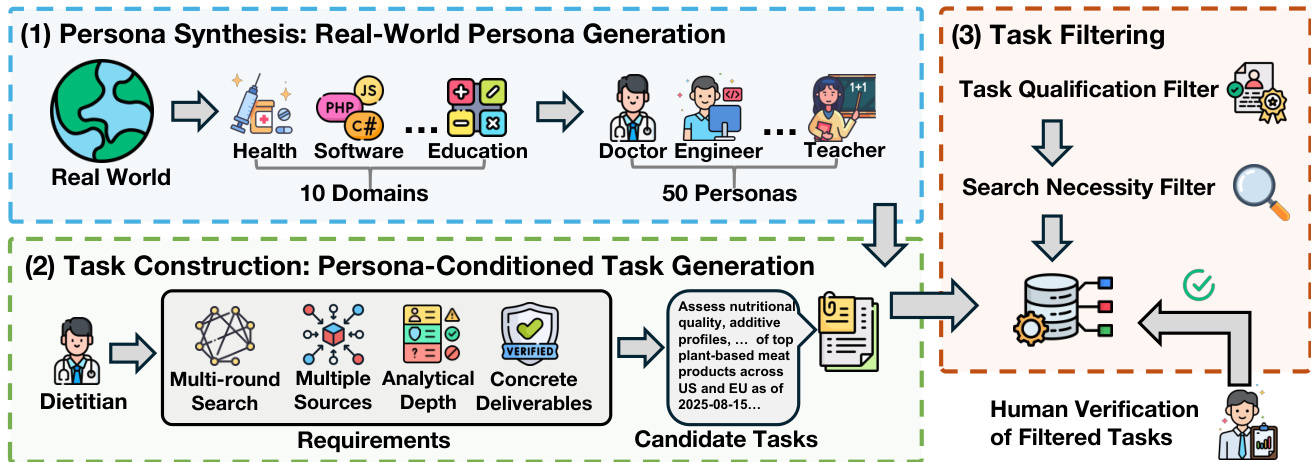
作者提出一个完整的深度研究任务与报告构建与评估流程,分为两个主要阶段:任务构建与智能体评估。整体框架如第一张图所示,首先进行角色合成,选取10个真实世界领域,生成50个不同角色,每个角色具有特定属性,如角色、隶属关系与背景。这些角色作为生成候选深度研究任务的基础,任务设计需满足多轮网络搜索、多源证据整合、分析深度以及具有明确约束的具体交付成果。生成的候选任务经过两阶段过滤流程:任务资格过滤器确保任务具备深度与相关性,搜索必要性过滤器排除仅靠内部知识即可解决的任务,从而确保基准聚焦于需要外部信息检索的任务。过滤后的任务由领域专家进行人工验证,以确保质量。
第二张图详细描述了智能体评估流程,通过两个互补组件评估生成的深度研究报告质量:自适应逐点质量评估与主动事实核查。自适应逐点质量评估框架在固定的一般维度(覆盖度、洞察力、指令遵循、清晰度)基础上,动态生成任务特定的评估维度,以匹配每项研究任务的具体需求。针对每个维度,生成一组标准及其对应权重,实现细粒度评分。最终质量得分是各维度下准则得分的加权和,权重由评估者根据任务中各维度的相对重要性确定。该方法相比固定评分标准,能实现更细致且上下文感知的评估。
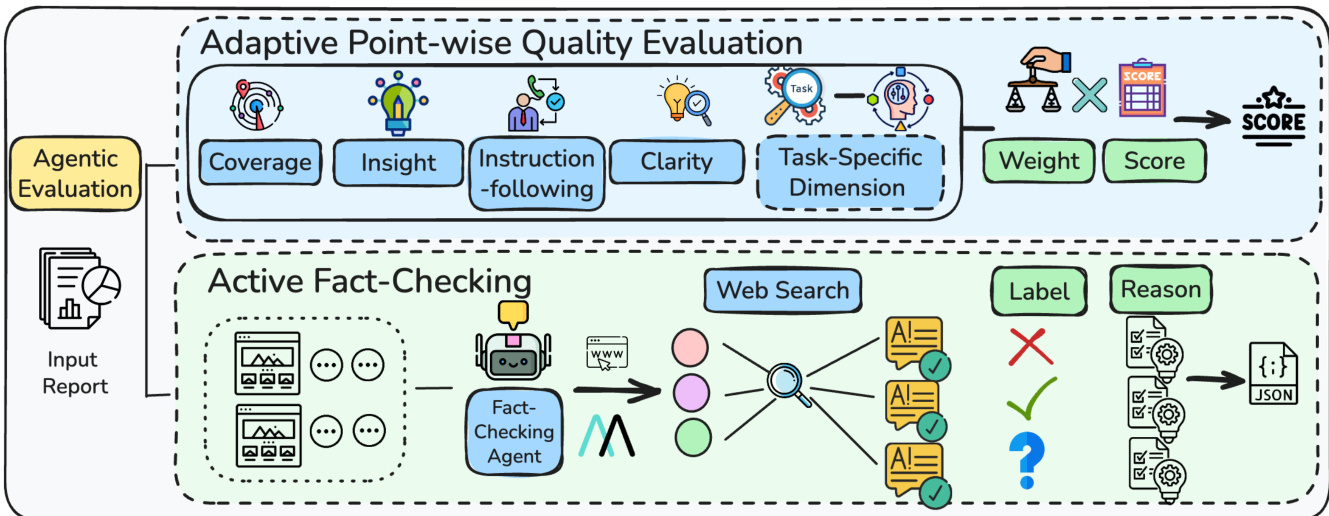
主动事实核查组件解决了长篇报告中事实一致性这一关键需求。其工作流程首先将报告分割为较小部分,并从每部分提取可验证陈述。随后,事实核查智能体迭代调用检索工具获取外部证据,将每个陈述与检索到的信息进行比对验证。智能体根据陈述与证据之间的一致性,为每个陈述分配“正确”、“错误”或“未知”三类标签,其中“未知”明确表示证据不足而非错误。该过程确保对所有陈述(包括未引用主张)进行全面的逐条验证,并生成包含标签、证据与推理过程的结构化JSON输出。自适应质量评估与主动事实核查的结合,提供了稳健、多维度的报告质量评估,既捕捉整体质量维度,也实现细粒度的事实准确性分析。
实验
- 使用DeepResearchEval框架,在100个角色驱动的高质量任务上评估了9个深度研究系统(如Gemini-2.5-Pro、Manus、OpenAI、Claude-Sonnet-4.5),该框架支持自动化任务构建与智能体评估。
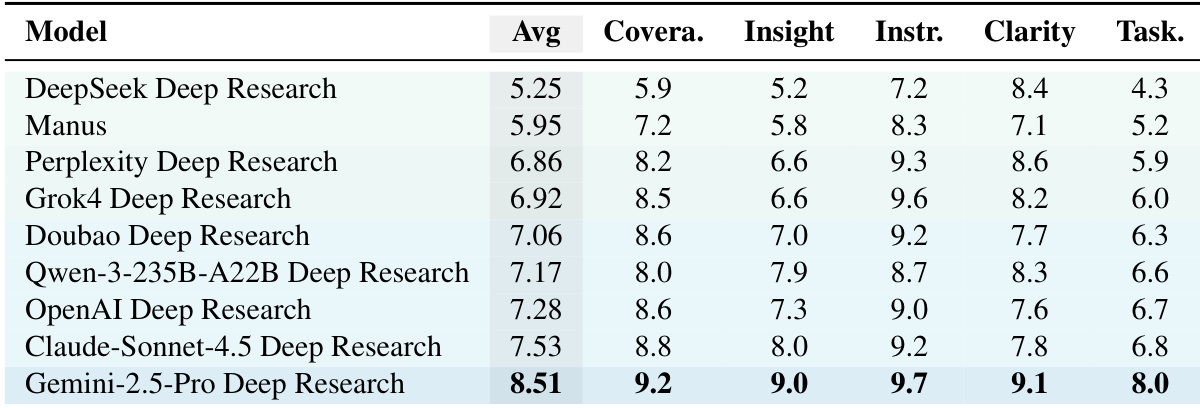
- Gemini-2.5-Pro获得最高总体质量得分(8.51/10),在覆盖度、洞察力与指令遵循方面表现优异;Manus与Gemini-2.5-Pro在事实正确性上领先,分别达到82.3%与76.3%的正确陈述率。
- 所有系统在任务特定得分上均显著低于通用得分,表明在满足任务特定要求方面存在差距,凸显自适应评估的必要性。
- 主动事实核查显示,“错误”主张较为罕见,但“未知”主张普遍存在,表明事实风险更多源于证据薄弱而非明显错误。
- 跨评审者一致性、随机稳定性与人机对齐分析证实了评估框架的可靠性,自动化与人工标注间达成73%的一致性,且排名具有高度鲁棒性。
作者采用自适应逐点质量评估框架对九个深度研究系统进行多维度评估,Gemini-2.5-Pro Deep Research获得最高总体得分8.51,主要得益于在覆盖度、洞察力与指令遵循方面的出色表现。结果显示,尽管系统在通用质量维度上表现良好,但其任务特定得分始终较低,表明当前系统在满足定制化任务要求方面存在明显差距。
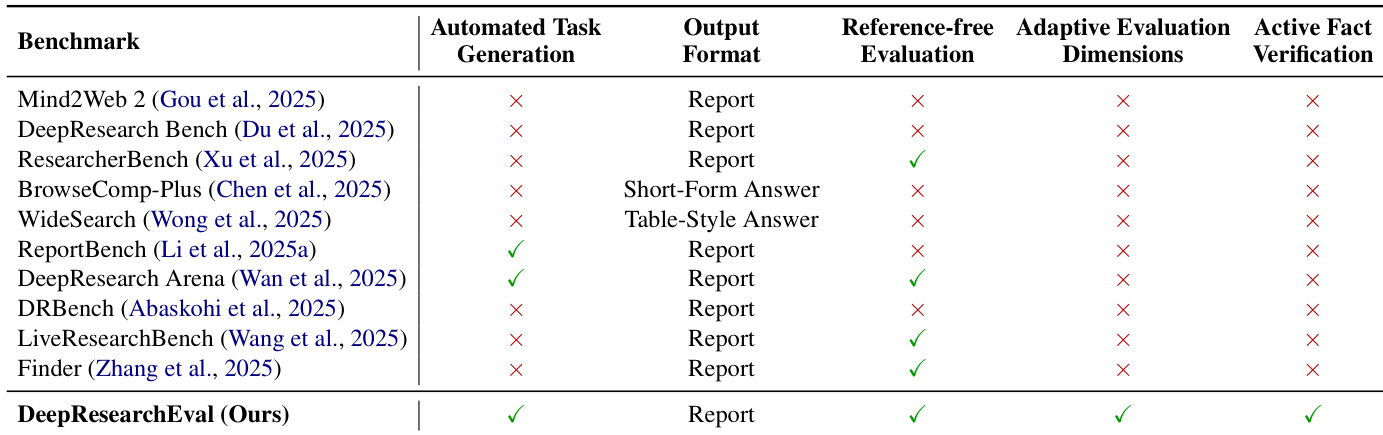
作者使用DeepResearchEval评估深度研究系统,凸显其相较于现有基准的优势:支持自动化任务生成、自适应评估维度与主动事实核查。结果表明,DeepResearchEval相比以往工作提供了更全面、动态的评估框架,而后者往往缺乏其中一项或多项能力。
作者采用自适应逐点质量评估框架评估深度研究系统,结果显示Gemini-2.5-Pro Deep Research平均得分最高,达5.29,优于其他系统。评估结果在独立运行中表现出一致的排名稳定性,表明评分方法具有稳健性。
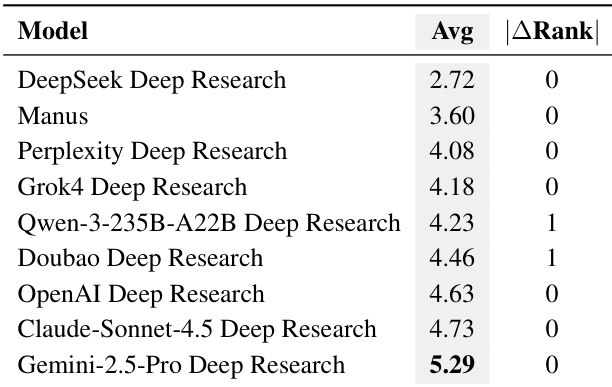
结果显示,Gemini-2.5-Pro Deep Research在质量评估中得分最高,达8.52,优于所有其他系统,排名第一。Manus与Perplexity Deep Research紧随其后,得分分别为5.92与6.85,而DeepSeek Deep Research得分最低,为5.24。
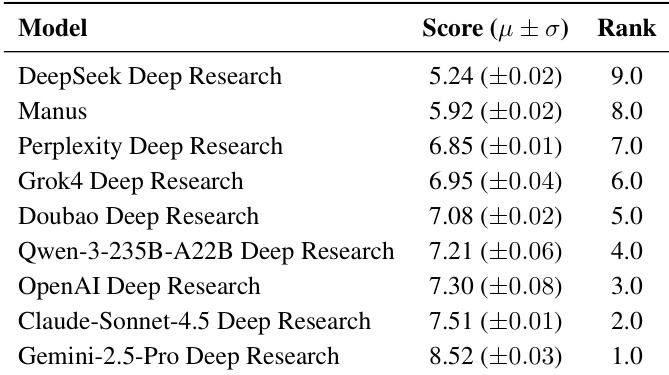
作者使用质量评估框架评估深度研究系统,结果显示Gemini-2.5-Pro在所有维度上平均得分最高,达8.51,表明其在覆盖度、洞察力与指令遵循方面表现卓越。评估揭示了通用得分与任务特定得分之间存在持续差距,说明当前系统虽在广泛整合方面表现优异,却常无法满足任务特定要求。