Command Palette
Search for a command to run...
STEP3-VL-10B 技术报告
STEP3-VL-10B 技术报告
摘要
我们提出 STEP3-VL-10B,一个轻量级开源基础模型,旨在重新定义紧凑性与前沿级多模态智能之间的权衡。STEP3-VL-10B 的实现依托于两项关键策略:其一,基于 1.2T 多模态 token 的统一、全参数未冻结预训练策略,将语言对齐的感知编码器(Perception Encoder)与 Qwen3-8B 解码器深度融合,构建内在的视觉-语言协同机制;其二,采用规模化后训练流程,包含超过 1,000 次迭代的强化学习优化。尤为重要的是,我们引入并行协同推理(Parallel Coordinated Reasoning, PaCoRe)机制,实现推理阶段计算资源的高效扩展,通过可扩展的感知推理能力,系统性地探索与融合多样化的视觉假设。因此,尽管模型参数量仅为 10B,STEP3-VL-10B 在性能上已可媲美甚至超越参数规模达其 10 倍至 20 倍的大型模型(如 GLM-4.6V-106B、Qwen3-VL-235B),并全面超越顶级闭源旗舰模型,包括 Gemini 2.5 Pro 与 Seed-1.5-VL。在多项基准测试中,该模型表现卓越:MMBench 达到 92.2%,MMMU 达到 80.11%;在复杂推理任务中,AIME2025 达到 94.43%,MathVision 达到 75.95%。我们已开源完整模型系列,为研究社区提供一个强大、高效且可复现的基准平台。
一句话总结
StepFun团队提出STEP3-VL-10B,一个参数量为100亿的紧凑型多模态基础模型,通过统一的预训练策略(融合语言对齐的感知编码器与Qwen3-8B解码器),结合扩展的后训练流程和并行协同推理(PaCoRe)实现可扩展的推理时计算,使其在MM-Bench、MMMU、AIME2025和MathVision等基准测试中超越参数量大10–20倍的模型。
主要贡献
- STEP3-VL-10B通过在1.2万亿多模态标记上采用统一且完全解冻的预训练策略,解决了在紧凑模型中实现前沿级多模态智能的挑战,将语言对齐的感知编码器与Qwen3-8B解码器融合,建立内在的视觉-语言协同机制。
- 该模型利用超过1000轮强化学习的扩展后训练流程,并引入并行协同推理(PaCoRe),动态分配推理时计算资源以探索和合成多样化的视觉假设,实现高效的感知推理。
- 尽管参数量仅为100亿,STEP3-VL-10B在关键基准测试中达到最先进水平——MM-Bench为92.2%,MMMU为80.11%,AIME2025为94.43%,MathVision为75.95%,超越参数量大10–20倍的模型,以及Gemini 2.5 Pro、Seed-1.5-VL等顶级专有系统。
引言
作者采用紧凑的100亿参数架构,挑战了“高性能多模态推理必须依赖大规模模型”的普遍假设。尽管以往轻量级模型在推理与感知能力上有所牺牲,而大型模型又因计算需求高而面临部署障碍,STEP3-VL-10B通过在1.2万亿标记的多模态语料上采用统一预训练策略,并结合复杂的后训练流程,实现了前沿级性能。该流程包括两阶段监督微调和超过1000轮基于可验证奖励与人类反馈的强化学习,辅以并行协同推理(PaCoRe)实现推理阶段的多智能体假设生成与交叉验证。该模型在关键基准测试中显著超越更大规模的开源与专有模型,证明通过有针对性的架构与训练创新,高效且高容量的多模态智能是可实现的。
数据集

- 数据集由多个高质量、领域特定来源构建,以支持STEP3-VL-10B的细粒度感知与复杂推理能力。
- 知识:整合1500万教育样本(K-12至成人学习)与来自Common Crawl、StepCrawl及关键词搜索结果的多模态数据。交错数据经筛选,剔除图像下载失败率>90%、含二维码或极端长宽比的页面。图像-文本对来自LAION、COYO、BLIP-CCS、Zero,并通过关键词检索、上下文文本提取及CLIP-based选择进行增强。马赛克增强将四张图像合并为一张,以提升空间推理能力。
- 教育:涵盖K-12(数学、科学、人文)、高等教育(STEM、医学、金融)及成人考试(驾驶、CPA、法律)的1500万样本。数据来源包括开源数据集、CoSyn生成的合成数据及真实考试材料,辅以教科书与教育网站内容。
- OCR:包含1000万真实世界与3000万合成的图像到文本样本,使用PaddleOCR与SynthDog生成。文档到文本包含8000万全页文档,通过PaddleOCR或MinerU 2.0标注。
- 视觉到代码:覆盖标记语言(Markdown、LaTeX、Matplotlib)的1000万+开源与1500万+合成信息图,生成遵循严格渲染规则;程序化代码(TikZ、Graphviz)包含500万从多样化视觉中重建的任务。
- 文档到代码:来自arXiv的400万表格与1亿公式,结合开源数据集,渲染过程中对引用与超链接进行谨慎处理。
- 定位与计数:来自OpenImages、COCO、Merlin、PixMo及内部检测任务的4亿样本;计数数据源自检测标注。
- VQA:来自开源数据集的1000万幅图像整体理解样本及自动生成的问答对;2000万以OCR为重点的VQA样本来自开源与合成来源。
- GUI:来自Android、iOS、Windows、Linux、macOS应用的2300万样本,包含联合定位与轨迹标注。包括70万UI描述、100万知识型VQA对、200万轨迹序列(12个原子动作)及1900万定位样本。基于网页的GUI数据包含3000万爬取页面,具备精确文本坐标。
- 模型采用两阶段监督微调流程:
- 第一阶段(文本主导):文本到多模态比例为9:1,共1900亿标记,聚焦逻辑与语言推理。
- 第二阶段(多模态融合):比例为1:1,共360亿标记,平衡视觉与文本推理。
- 训练使用128k序列长度,全局批量大小为32,余弦学习率调度(200步预热,峰值1e-4,最终1e-5),并采用领域特定采样权重。
- 数据通过基于规则的去噪机制剔除退化模式,并使用精确匹配与64-gram匹配进行基准去污染。
- 马赛克增强提升输入分辨率与视觉密度,合成数据生成确保渲染一致性。
- 元数据包含精确坐标、动作轨迹与结构化标注,以支持定位、布局理解与可执行交互建模。
方法
作者采用模块化且可扩展的框架开发STEP3-VL-10B,一个紧凑但高性能的多模态基础模型。整体架构融合语言优化的感知编码器与Qwen3-8B解码器,形成统一的视觉-语言骨干网络。感知编码器为18亿参数模型,因其预对齐的语言特征而被选中,有助于训练过程中的收敛。该视觉编码器通过一个投影器连接至解码器,采用两个连续的步长为2的层实现16×空间下采样,有效压缩视觉标记的同时保留关键信息。为捕捉细粒度细节,模型采用多裁剪策略,将输入图像分解为728×728全局视图与多个504×504局部裁剪。该设计利用批处理维度并行性,避免可变长度打包的复杂性。空间结构通过在补丁行后追加换行符编码,位置建模则采用标准1D RoPE,因高级变体在作者设置中未带来显著增益。
预训练阶段旨在通过关注数据质量与架构协同建立坚实基础。模型在1.2万亿多模态标记语料上采用完全解冻策略进行训练,实现内在的视觉-语言协同。预训练完成后,采用扩展的后训练流程,包含超过1000轮强化学习。该流程分为三个阶段,逐步提升模型能力。第一阶段为可验证奖励强化学习(RLVR),聚焦于在具备可访问真实答案的任务上建立稳健的逻辑基础。其利用来自开源数据集与内部教育资源的多样化可验证多模态任务。多维过滤流程确保高质量监督:可验证性由GPT-OSS-120B执行四次独立验证保证,视觉相关性由STEP3-VL-10B早期版本确保,难度通过每提示24次回放识别“部分接受”样本进行控制。该阶段运行600轮,最大序列长度为24k。
第二阶段为基于人类反馈的强化学习(RLHF),在开放式、不可验证任务上对齐人类偏好。其使用来自开源竞技场数据集与内部指令池的精选提示,由更强的内部模型生成高质量参考响应作为锚点。该阶段运行300轮,最大序列长度为32k,优化对话能力与对齐性,同时保持底层推理强度。
第三阶段通过并行协同推理(PaCoRe)进一步扩展,将计算资源分配至并行探索多样化的感知假设,并将其合成统一结论。该阶段训练数据通过扩展RLVR阶段的难度过滤机制构建。24次回放结果被重用为消息缓存池。二级合成过滤通过模拟并行推理过程,从池中采样16–24条消息作为“合成上下文”以重新生成响应,并仅保留仍被归类为“部分接受”的实例。这防止任务简化,迫使模型执行多视角自我验证。模型在严格在线策略下使用PPO优化500轮,最大序列长度为64k,以容纳聚合上下文。
强化学习的优化算法为PPO结合GAE,有效平衡策略梯度估计中的偏差-方差权衡。策略参数通过最大化裁剪的替代目标进行更新,以维持训练稳定性;价值函数则通过最小化估计值与目标值之间的均方误差进行更新。整个强化学习阶段共运行1400轮,仅更新解码器,保持编码器冻结。奖励系统分为两部分,以支持跨异构模态的可扩展训练。对于可验证任务,优先保证严格正确性与推理一致性,通过基于感知的奖励(如IoU、欧氏距离)与基于GPT-OSS-120B的模型验证提供稳健、解析无关的评估。对于不可验证任务,依赖学习的偏好模型与行为正则化,包括语言一致性惩罚、引用验证与认知校准惩罚,以引导对齐并强制执行安全约束。
实验
- 采用两阶段训练方案,使用1.2万亿标记,结合AdamW优化器与扩展学习率调度,平衡表征学习与细粒度感知/推理能力的巩固。
- 实施两阶段后训练流程:监督微调后接近端策略优化(PPO)与广义优势估计(GAE),通过奖励系统实现高级推理与感知能力。
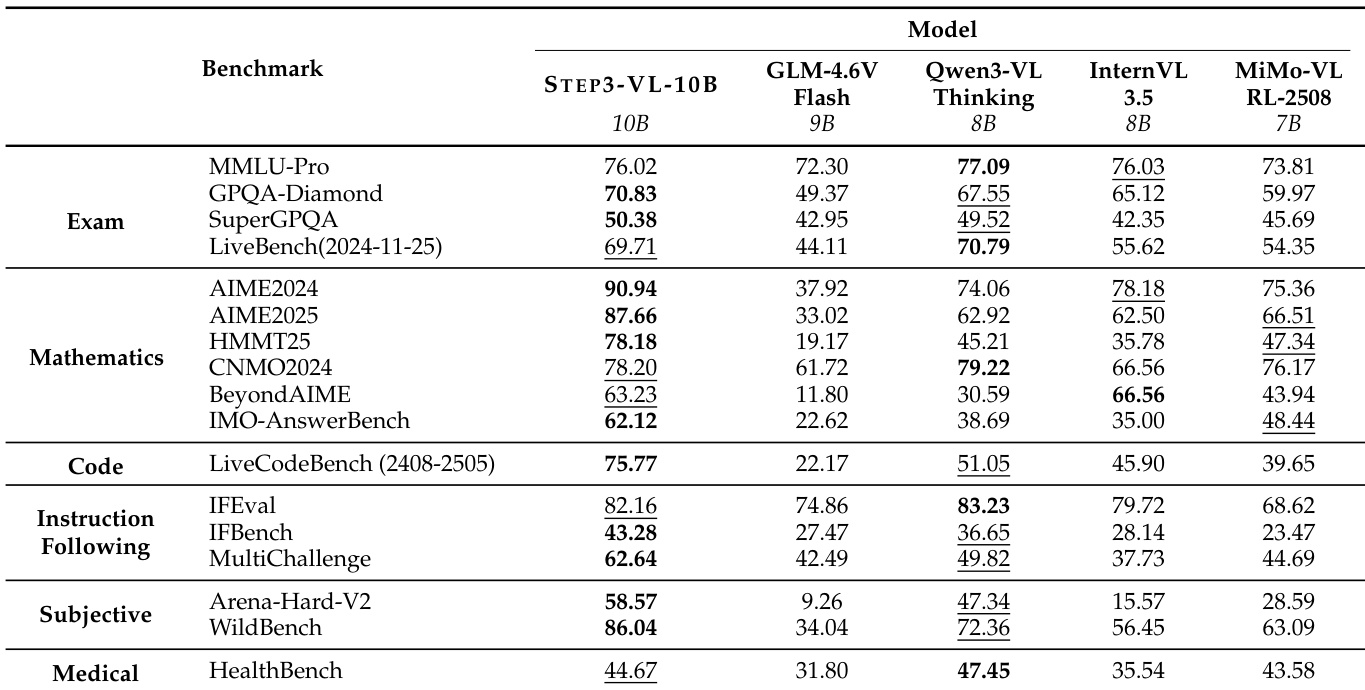
- 在60多个多模态与文本中心基准上验证STEP3-VL-10B,证明其作为100亿参数模型达到最先进水平。
- 在多模态基准上,MMMU(标准)为78.11%,MMBench(EN)为92.05%,OCRBench为86.75%,ScreenSpot-V2为92.61%,AI2D为89.35%,超越7–10B开源模型,媲美更大规模专有系统。
- 在文本中心基准上,IMO-AnswerBench为62.12%,LiveCodeBench为75.77%,AIME 2025为94.43%,展现强大的推理与代码生成能力。
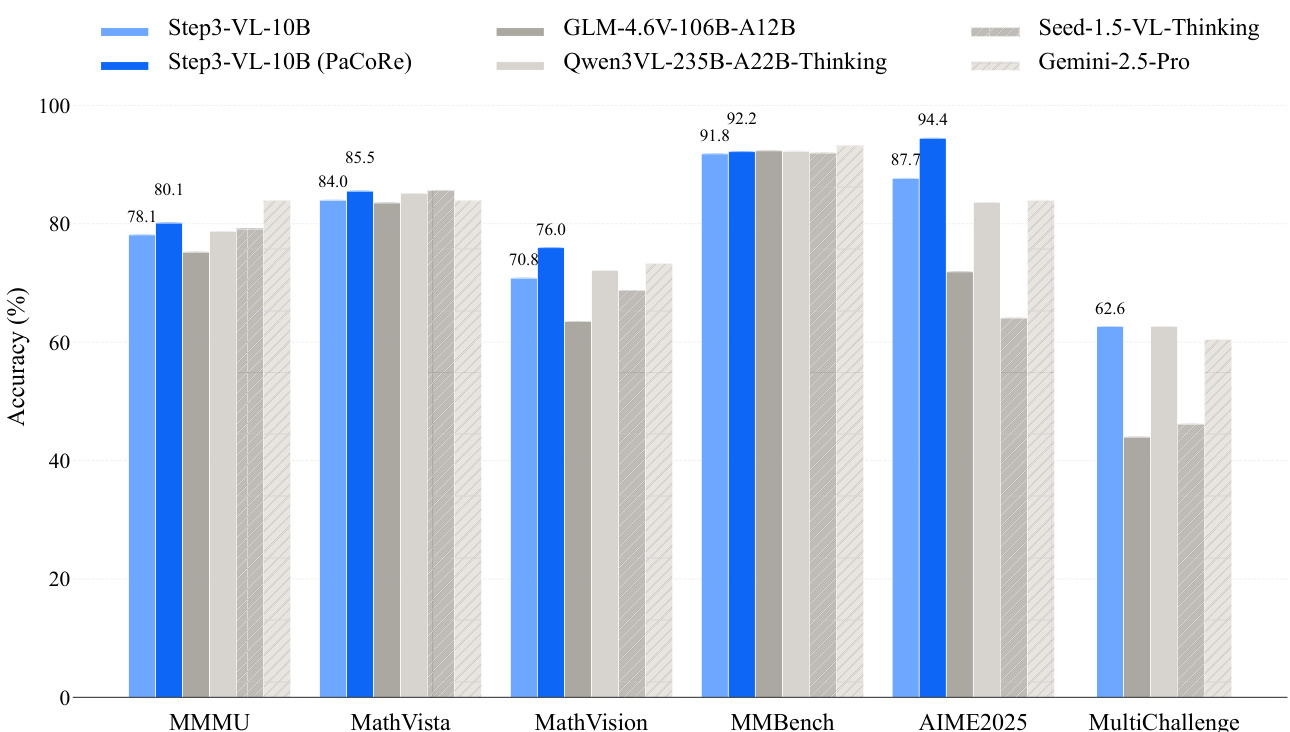
- 采用并行协同推理(PaCoRe)后,超越顺序推理(SeRe)模式,在MMMU上达80.11%,MathVista为85.50%,MMBench(平均)为92.17%,HMMT25为92.14%,证明模型智能并非严格受限于规模。
- 消融研究确认PE-lang视觉编码器优于DINOv3,AdamW优于Muon,尽管Deepstack收敛更快,但未带来下游收益。
结果表明,STEP3-VL-10B在多个文本中心基准上达到顶尖性能,超越其他开源模型在考试、数学与代码任务中的表现。其在高级推理方面表现突出,尤其在AIME与IMO基准上,同时在指令遵循与主观评估中保持竞争力。
作者对比了Muon与AdamW优化器在多模态基准上的表现,结果显示AdamW在大多数任务中得分更高,尤其在感知与通用推理方面。尽管Muon在某些领域(如SimpleVQA)有所提升,但AdamW展现出更优的整体性能与训练效率,因此被选为最终优化器。

作者对比了STEP3-VL-10B启用与禁用DeepStack架构的性能,结果显示移除DeepStack导致BLINK与OCRBench等感知任务略有下降,但在MMSI-Bench与ReMI等通用推理任务上表现提升。结果表明,DeepStack在感知方面提供微弱优势,但在某些推理领域可能产生负面影响。

作者使用全面的多模态与文本中心基准评估STEP3-VL-10B,证明其在7B–10B参数范围内的大多数领域超越其他开源模型。结果显示,STEP3-VL-10B在MathVision与MMBench等关键基准上达到顶尖水平,其并行协同推理模式进一步提升准确率,在多项任务中超越Gemini-2.5-Pro与Seed-1.5-VL等更大模型。
作者在多个多模态基准上对比了两种视觉编码器DINOv3与PE-lang的性能。结果显示,PE-lang在大多数任务中表现优于DINOv3,尤其在OCRBench上提升12.50分,在MMVP上提升4.00分,表明其与语言模型具有更好的对齐性,支持高效的视觉-语言建模。
