Command Palette
Search for a command to run...
A^3-Bench:通过锚点与吸引子激活进行内存驱动型科学推理的基准测试
A^3-Bench:通过锚点与吸引子激活进行内存驱动型科学推理的基准测试
Jian Zhang Yu He Zhiyuan Wang Zhangqi Wang Kai He Fangzhi Xu Qika Lin Jun Liu
摘要
科学推理不仅依赖于逻辑推理,还涉及激活先前知识与经验结构。记忆能够高效地复用知识,从而提升推理的一致性与稳定性。然而,现有的评估基准主要关注最终答案或逐步推理的连贯性,忽视了人类推理背后由记忆驱动的机制——这一机制包括激活“锚点”(anchors)与“吸引子”(attractors),并将其整合进多步推理过程。为弥补这一空白,我们提出了 A^3-Bench(https://a3-bench.github.io),一个基于“锚点与吸引子激活”(Anchor and Attractor Activation)机制、通过双尺度记忆驱动激活来评估科学推理能力的基准。首先,我们采用SAPM流程(即:主题、锚点与吸引子、问题、记忆构建)对跨领域的2,198个科学推理问题进行了标注。其次,我们设计了一套双尺度记忆评估框架,结合锚点与吸引子的激活机制,并引入AAUI(锚点-吸引子利用指数,Anchor--Attractor Utilization Index)作为量化指标,用以衡量记忆激活的强度与效率。最后,通过对多种基础模型与推理范式的实验验证,我们评估了A^3-Bench的有效性,并深入分析了记忆激活对推理性能的影响,为理解记忆驱动型科学推理提供了新的洞见。
一句话总结
西安交通大学与新加坡国立大学的作者提出 A³-Bench,一个基于双尺度记忆驱动的科学推理基准,通过 SAPM 注释框架和 AAUI 指标评估锚点与吸引子的激活情况,揭示了记忆利用如何在标准连贯性或答案准确率之外提升推理一致性。
主要贡献
-
我们提出 A3-Bench,一个新颖的科学推理基准,通过在数学、物理和化学领域 2,198 个问题中采用 SAPM 流程进行双尺度注释,显式建模类人记忆机制,包括锚点(基础性知识)和吸引子(基于经验的推理模板)。
-
该基准包含双尺度评估框架和 AAUI(锚点-吸引子利用指数)指标,通过测量模型在上下文依赖的多步推理中检索并应用相关知识的有效性,量化记忆激活率。
-
在十种大语言模型(LLM)和三种记忆范式上的实验表明,增强的记忆激活显著提升了推理准确率,同时保持高效的 token 使用,验证了 A3-Bench 作为认知对齐工具在细粒度评估与开发记忆驱动模型方面的有效性。
引言
大语言模型(LLM)中的科学推理不仅需要逻辑推理,更需要动态激活结构类似人类记忆的先前知识。当前基准主要关注最终答案准确率或逐步推理的连贯性,未能评估模型在推理过程中是否有效检索并激活相关知识。这一差距限制了对因逻辑缺陷还是记忆利用不佳导致失败的诊断能力。作者提出 A3-Bench,首个从锚点与吸引子激活视角评估记忆驱动科学推理的基准。他们使用 SAPM 框架对数学、物理和化学领域的 2,198 个问题进行注释,将每个问题映射到基础性知识单元(锚点)和基于经验的推理模板(吸引子)。为衡量记忆激活,作者在双尺度评估框架内提出 AAUI 指标,实现对模型何时以及如何调用记忆的细粒度分析。实验表明,利用锚点-吸引子激活的模型在控制 token 成本的前提下实现了更高的准确率,揭示了记忆利用的关键洞见,并指导更具认知一致性的 LLM 发展。
数据集

- A3-Bench 数据集源自四个现有基准数据集:MathVista、OlympiadBench、EMMA 和 Humanity's Last Exam,覆盖数学、物理和化学领域。
- 数据集按层级分类体系组织:数学(8 个子领域)、物理(5 个子领域)、化学(5 个子领域),依据 MSC、高等教育课程体系及 IUPAC 标准等公认分类系统。
- 每道题目经历四阶段精炼流程:(1) 使用三台大语言模型(GPT-5、Deepseek-V3.2、Qwen-30B)进行初步筛选,仅保留至少一台模型答错的问题;(2) 同样三台模型进行交叉分析,其中两台评估第三台的推理过程,随后由人类专家修订以增强多步推理质量;(3) 每道题由三台模型各生成 10 次重复答案,根据多数正确率分类为:简单(15–30 正确)、中等(5–14)、困难(0–4);(4) 通过三台模型投票分配子领域,人类专家验证并最终确定分类与二级学科。
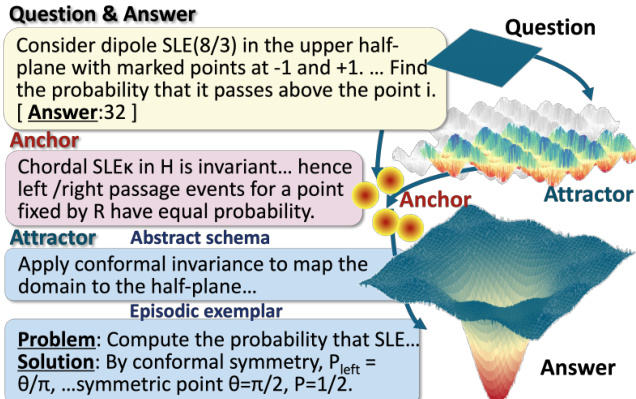
- 每道题由人类专家手动标注最多 6 个锚点-吸引子单元:锚点(核心概念、原理、公式)和吸引子(抽象模式、范例),确保其相关性、非冗余性与推理路径的一致性。
- 每个标注数据点包含修订后的问题、标准答案、子领域标签,以及一组锚点与吸引子,构成支持记忆增强推理的丰富结构化数据集。
- 该数据集用于本文训练与评估 HybridRAG 框架,模型在推理过程中利用锚点-吸引子对作为记忆提示。
- 训练过程中,作者采用不同难度层级与子领域的混合样本,对各领域与难度层级进行均衡采样,以确保全面评估。
- 未使用显式裁剪;而是通过迭代精炼与专家验证处理数据,确保高质量、语义扎根的推理轨迹。
- 元数据包含子领域、难度等级、锚点-吸引子集合及每条注释的推理日志,支持可追溯性与未来模型调试。
方法
作者基于锚点与吸引子、记忆激活及记忆增强推理的理论概念,构建了一个记忆驱动的推理框架。整体架构围绕四步注释流程展开,如框架图所示。该流程始于学科基准化,即在数学、物理、化学等学科内定义并分类子领域。专家随后为每个子领域构建锚点与吸引子,建立结构化知识库。锚点被识别为基础性推理原语,如核心概念、原理与公式;吸引子则定义为连接这些锚点与可操作问题求解模板的解题路径。每个吸引子包含抽象模式与情景范例,确保推理既受一般原则引导,也受具体实例启发。锚点与吸引子之间的关系被显式指定,以维持连贯性并避免冗余。
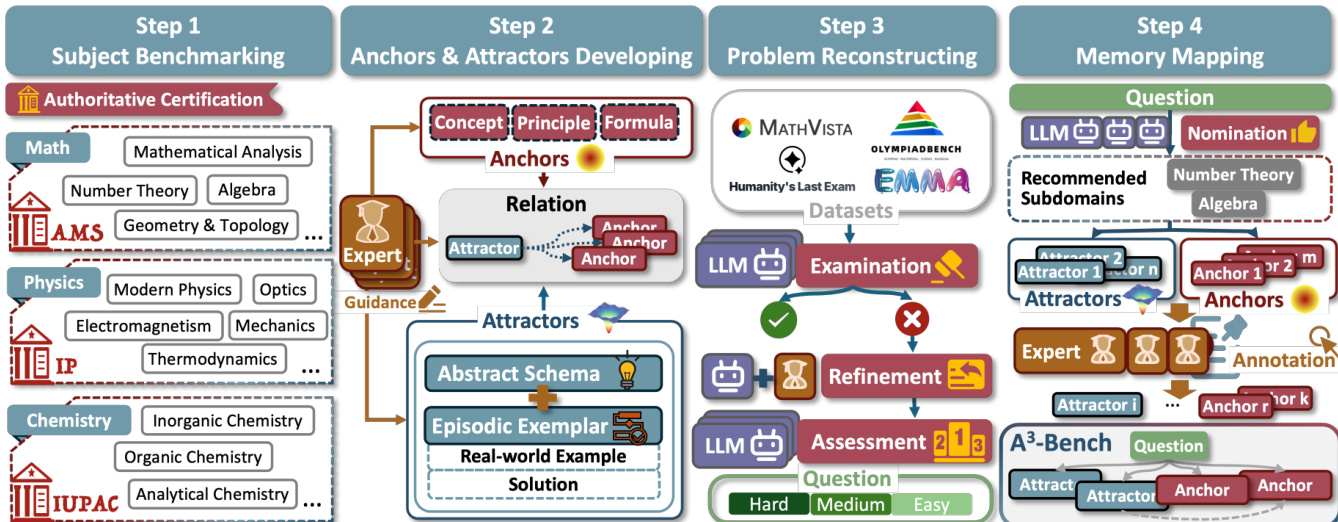
在知识库构建完成后,框架进入问题重构阶段,对现有题目进行优化,确保其需要多步推理且无常见失败模式。此步骤包括错误诊断与跨模型精炼,以识别并修正缺失步骤或错误假设等问题。重构后的问题被映射到相关锚点与吸引子,构成记忆增强推理的基础。最后一步为记忆映射,即将问题与适当的知识结构关联,以引导推理过程。
该方法的核心实现为一种称为“记忆双针激活器”的混合检索机制,运行于 HybridRAG 框架中。该激活器包含两个组件:基于向量的检索系统与基于图的检索系统。向量针根据语义相似性从密集存储中检索 top-k 节点,而图针则遍历知识图谱以恢复节点间的逻辑关联。混合检索过程形式化为 z∗≈Φhybrid(x)≜V(x)⊕G(V(x)),其中 V(x) 表示基于向量的检索,G(V(x)) 表示基于图的检索。该混合方法确保同时利用语义与结构信息,激活最相关的记忆状态。
激活的记忆状态 z∗ 随后由上下文织造编排器(Context Fabric Composer)用于构建语言模型的最终上下文。上下文通过将原始查询 x 与激活状态 z∗ 编织而成,形成 Cfinal=W(x,z∗)≜I⊕[x⋈S(z∗)],其中 I 为固定指令前缀,S(⋅) 将记忆状态序列化为语言模型可读的形式。该组合上下文随后输入语言模型以生成最终答案,确保推理过程受激活记忆结构的引导。
作者进一步将记忆激活过程形式化为“锚点诱导的吸引子动力学”,将认知演化描述为势能场中的轨迹。记忆状态 m∗ 定义为变分自由能 F(m,A,q)=DKL(q∥p(m∣A))+H(m) 的最小化者,其中 DKL 衡量预测误差,H(m) 表示系统熵。推理过程遵循梯度流 m˙=−η∇mF(m,A,q),其中锚点作为吸引子,形成吸引盆地,将轨迹拉向稳定不动点。这确保系统收敛至稳定平衡,将记忆激活形式化为吸引子动力学与自由能最小化的涌现属性。
实验
- 在 OlympiadBench 和 TheoremQA 上,使用 10 个 LLM 对三种范式进行评估:无记忆(Vanilla)、全记忆、黄金记忆(人工标注激活)。
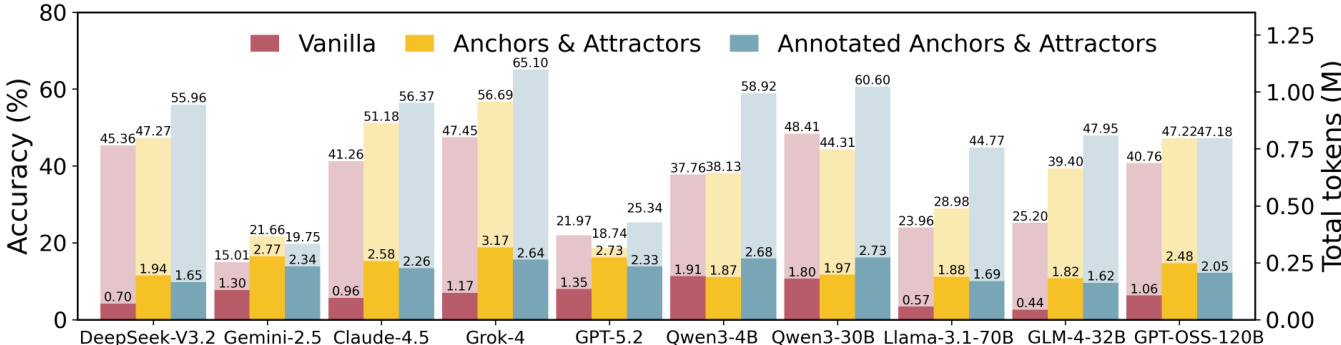
- 记忆增强显著提升准确率:平均从 34.71%(Vanilla)提升至 48.19%(注释激活),增幅在 +3.37(GPT-5-Mini)至 +22.75(GLM-4-32B)之间。
- 在难题上表现显著提升,尤其在物理领域(如 Grok-4-Fast +25.00,GLM-4-32B +15.56),表明激活的吸引子有助于恢复可行解题路径。
- AAUI(锚点-吸引子利用指数)与准确率强相关,验证其在衡量推理保真度中的作用;AAUI 越高,性能越好(如 Grok-4-Fast:AAUI=0.66,Acc=56.69%;GPT-5-Mini:AAUI=0.09,Acc=18.74%)。
- 锚点-吸引子激活可泛化至竞赛级问题(P.C.),平均得分较 Vanilla 提升 11.12 分,较 CoT 提升 6.35 分;在最难题集上增益最为显著(如 Qwen3-4B:P.C. 上从 1.69% 提升至 7.63%)。
- 仅激活吸引子在多数模型中优于仅激活锚点,但双激活实现最高性能,证实二者互补:锚点提供概念基础,吸引子提供程序指导。
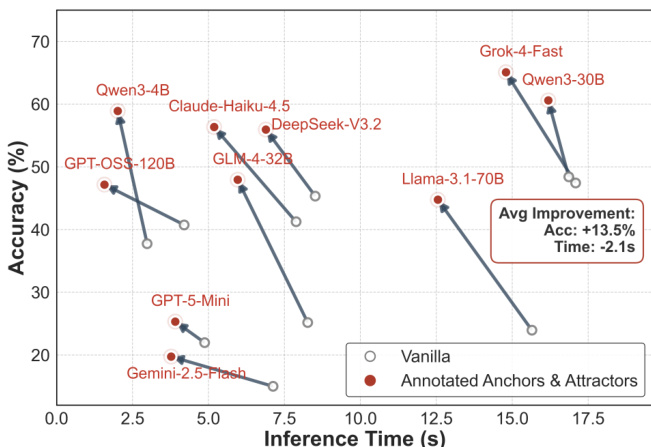
- 注释激活下推理时间平均减少 2.1 秒,同时准确率提升(最高 +13.5%),表明效率提升。
- 错误分析显示,注释激活下推理与知识类错误显著减少,而计算与理解类错误保持稳定。
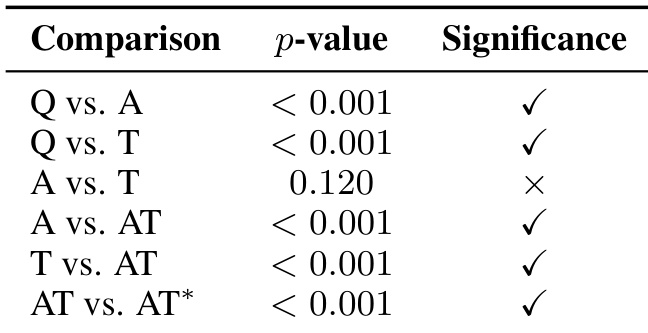
- 统计显著性检验(McNemar’s)确认记忆增强至关重要(p < 0.001),且锚点与吸引子联合激活优于单独使用。
- 随着记忆噪声增加,性能单调下降(如 Grok-4-Fast:100% 噪声下从 65.1% 降至 32.5%),表明记忆相关性对可靠推理至关重要。
作者使用热力图分析不同学科与难度层级下记忆激活与性能提升的关系。结果表明,记忆增强在难题上带来最大准确率提升,数学与化学在高难度下均表现出显著的准确率与 AAUI 提升,而物理提升相对温和。数据表明,记忆激活在挑战性场景中最为有效,能显著提升性能并对应更高的 AAUI 值。

作者使用散点图比较十种 LLM 在两种范式下(Vanilla 与注释锚点与吸引子)的准确率与推理时间。结果表明,激活注释记忆可提升所有模型的准确率,同时降低推理时间,平均准确率提升 13.5%,推理时间减少 2.1 秒。
结果表明,相较于仅依赖参数化知识,记忆增强显著提升了科学推理性能,表现为问题仅基准与锚点仅激活、吸引子仅激活之间存在统计显著差异。锚点与吸引子联合激活进一步显著优于任一单独组件,表明两种记忆类型对最优推理均不可或缺。然而,锚点仅激活与吸引子仅激活之间无显著差异,表明二者在支持科学问题求解中扮演互补角色。
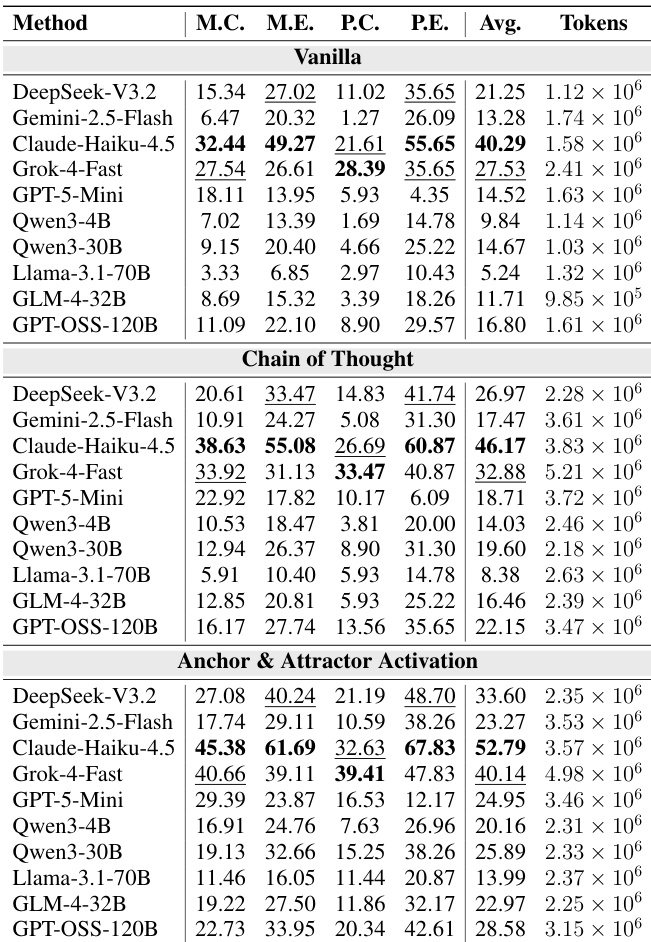
作者采用记忆驱动框架,在三种范式下评估大语言模型的科学推理能力:原始(Vanilla)、思维链(Chain of Thought)、锚点与吸引子激活。结果表明,锚点与吸引子激活显著优于原始与思维链基线,平均分别提升 11.12% 与 6.35%,尤其在竞赛级问题上表现突出。
作者通过对比三种记忆范式——Vanilla、锚点与吸引子、注释锚点与吸引子——评估记忆激活对十种大语言模型科学推理准确率的影响。结果表明,激活注释锚点与吸引子在所有模型上均持续提升准确率,尤其在难题与竞赛级任务中增益最大,同时多数模型推理时间减少。