Command Palette
Search for a command to run...
TranslateGemma 技术报告
TranslateGemma 技术报告
摘要
我们提出 TranslateGemma,这是一套基于 Gemma 3 基础模型的开源机器翻译模型系列。为增强 Gemma 3 原生的多语言能力以适应翻译任务,我们采用两阶段微调策略。首先,利用前沿模型生成的高质量大规模合成平行语料与人工翻译的平行语料相结合,进行监督微调;随后进入强化学习阶段,通过集成多种奖励模型(包括 MetricX-QE 和 AutoMQM)优化翻译质量。我们在 WMT25 测试集上对 10 个语言对进行了人工评估,同时在 WMT24++ 基准测试中对 55 个语言对进行了自动评估,充分验证了 TranslateGemma 的有效性。自动评估指标显示,相较于基线 Gemma 3 模型,所有尺寸的 TranslateGemma 模型均实现了稳定且显著的性能提升。值得注意的是,较小规模的 TranslateGemma 模型通常可达到与更大规模基线模型相当的性能,展现出更高的效率优势。此外,我们还证明了 TranslateGemma 模型在多模态任务中仍保持强大的能力,在 Vistra 图像翻译基准测试中表现更优。TranslateGemma 模型的开源发布,旨在为研究社区提供强大且可灵活适配的机器翻译工具。
一句话摘要
谷歌翻译研究团队推出了 TranslateGemma,这是一个基于 Gemma 3 通过两阶段微调流程构建的开源机器翻译系统:首先在人类翻译数据与高质量合成平行数据的混合数据上进行监督微调,随后利用包含 MetricX-QE 和 AutoMQM 的奖励模型集成进行强化学习,显著提升了 55 个语言对的翻译质量——尤其在低资源语言上表现突出,同时使更小的模型达到甚至超越更大基线模型的性能,并在无需额外训练的情况下保留了强大的多模态翻译能力。
主要贡献
-
TranslateGemma 是一个基于 Gemma 3 构建的开源机器翻译模型,通过两阶段微调流程增强:在多样化的混合数据(包括人工翻译与高质量合成平行数据)上进行监督微调,随后利用包含 MetricX-QE 和 AutoMQM 的奖励模型集成进行强化学习,以优化翻译质量。
-
该模型在 WMT24++ 基准测试中对 55 个语言对表现出显著提升,自动评估指标如 MetricX 和 CoMET22 均有稳定增长;较小的 TranslateGemma 变体(4B、12B)通常达到或超过更大基线 Gemma 3 模型的性能,展现出更高的效率。
-
TranslateGemma 保留了 Gemma 3 的多模态能力,在未进行额外多模态训练的情况下,于 Vistra 图像翻译基准测试中表现更优,表明文本翻译的改进可泛化至跨模态任务。
引言
机器翻译(MT)对全球沟通至关重要,近年来大型语言模型(LLMs)的进展显著提升了翻译质量。然而,由于缺乏强大且开源的模型,研究在透明度、可复现性和协作创新方面受到限制。以往方法常依赖有限或静态的训练数据,难以在翻译准确性与更广泛的语言能力之间取得平衡。本文作者提出 TranslateGemma,一个专为机器翻译优化的 Gemma 3 开源变体,采用两阶段流程:在多样化的人工与合成平行数据上进行监督微调,随后结合人类与模型反馈进行强化学习。该方法在 WMT25 和 WMT24++ 基准测试中对 55 个语言对均实现显著提升,同时保持原始模型的多模态能力——体现在图像翻译任务上的性能增强。TranslateGemma 的发布旨在加速开放、高质量机器翻译的研究与应用。
数据集

- TranslateGemma 的数据集包含两类主要数据,用于监督微调(SFT)和强化学习(RL)两个阶段,其中大部分数据在两阶段间共享。
- 针对低资源语言,作者引入了 SMOL(123 种语言)和 GATITOS(170 种语言)中的人工生成平行数据,增强了脚本多样性和覆盖范围。
- SFT 阶段使用混合数据,其中 30% 来自原始 Gemma 3 通用指令遵循数据集,以防止模型过度拟合翻译任务,同时保留通用指令遵循能力。
- 除 WMT24++ 数据外,还为 30 个涉及英语的特定语言对(如英语–亚美尼亚语、英语–夏威夷语、英语–马耳他语)生成了合成数据,扩展了现有数据源的覆盖范围。
- RL 阶段使用与 SFT 相同的翻译数据,但 GATITOS 和 SMOL 数据仅用于 SFT 阶段。
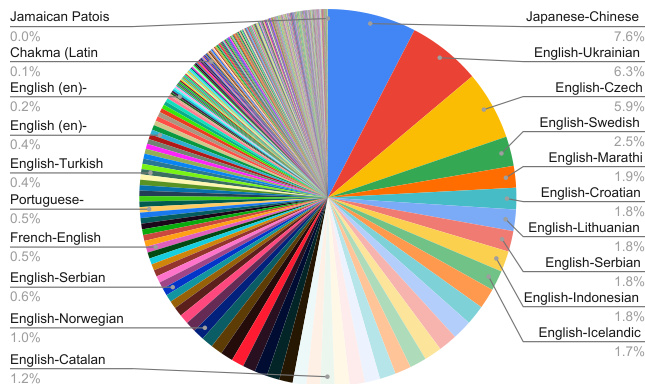
- SFT 与 RL 的语言分布详见图 1,完整语言对信息见附录 C 中的三张表格:双向英语对(表 5)、英语到其他语言对(表 6)以及非英语语言对(表 7)。
- 未提及显式的裁剪策略,但数据过滤与选择基于语言覆盖范围、资源可用性及任务相关性。
- 语言对与数据源的元数据已构建,以支持均衡训练并清晰追踪各语言的贡献。
方法
作者采用两阶段微调框架,以增强 Gemma 3 基础模型的多语言翻译能力,最终形成 TranslateGemma 系列。整体方法始于在多样化平行数据上的监督微调(SFT),随后进入强化学习阶段,利用奖励模型集成优化翻译质量。该框架旨在提升广泛语言对的翻译性能,同时保持高效性与多模态能力。
在监督微调阶段,作者从公开发布的 Gemma 3 27B、12B 和 4B 检查点开始。他们使用人工翻译的平行数据与通过 Gemini 2.5 Flash 生成的高质量合成数据对这些模型进行微调。合成数据的生成流程为:首先根据长度桶从 MADLAD-400 语料库中选取源段落,然后通过初步质量评估步骤筛选,该步骤比较 Gemini 2.5 Flash 的贪婪解码与采样解码输出。此筛选确保仅选择可能从进一步优化中受益的源段落。对每个选定源段落,生成 128 个翻译,并使用 MetricX 24-QE 进行过滤,保留质量最高的样本。合成数据包括单句翻译和最长达 512 个 token 的长文本块,支持短文本与长文本翻译。除平行数据外,还整合了通用指令遵循数据,以提升通用语言理解能力。微调过程采用 AdaFactor 优化器,学习率为 0.0001,批量大小为 64,共运行 200k 步。所有模型参数均被更新,唯独嵌入层参数被冻结,以保护在 SFT 数据混合中未出现的语言与脚本的翻译性能。
实验
- 在 SFT 检查点上应用强化学习,使用包含 MetricX-24-XXL-QE、Gemma-AutoMQM-QE、ChrF、自定义自然度自动评分器及通用奖励模型的集成,通过 token 级优势实现细粒度奖励分配。
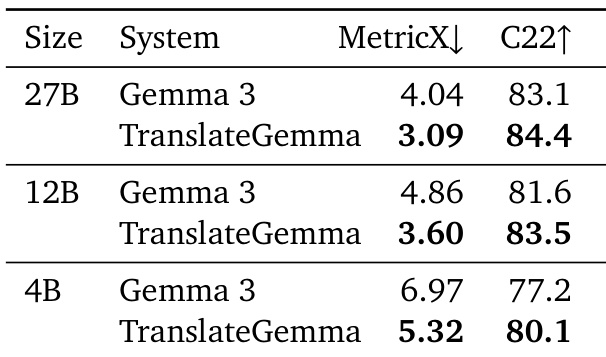
- 在 WMT24++ 数据集上,TranslateGemma 相较于基线 Gemma 3 模型取得显著提升:27B 模型的 MetricX 分数从 4.04 降至 3.09(相对下降 23.5%),12B 模型从 4.86 降至 3.60(相对下降 25.9%),4B 模型从 6.97 降至 5.32(相对下降 23.6%),所有 55 个语言对均实现一致提升。
- COMET22 结果验证了改进效果,12B TranslateGemma 得分为 83.5(较 81.6 上升),4B 模型达到 80.1(较 77.2 上升),表明其性能超越了优化指标的范围。
- TranslateGemma 模型性能可与或超过更大基线模型——例如,12B TranslateGemma 超越 27B 基线 Gemma 3,4B TranslateGemma 达到 12B 基线性能,表明效率显著提升。
- 在图像翻译的 Vistra 基准测试中,TranslateGemma 保留了多模态能力,27B 模型的 MetricX 提升近 0.5 分,12B 模型提升 0.25 分,尽管 SFT 和 RL 阶段均未进行多模态训练。
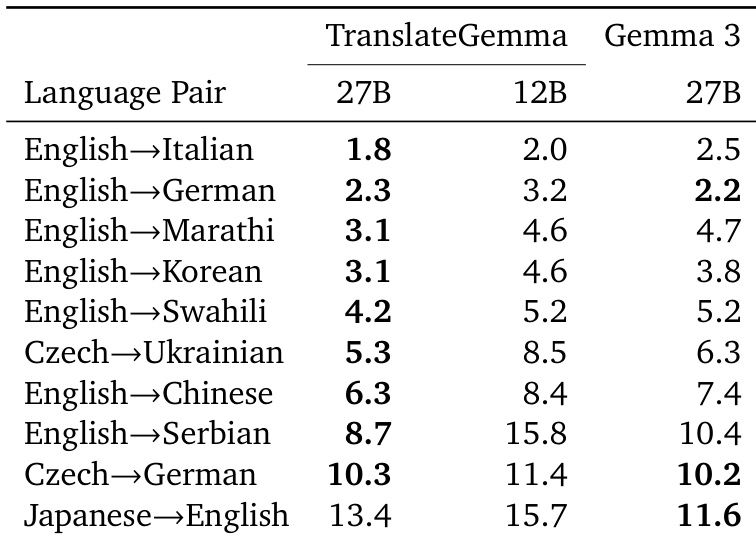
- 在 10 个语言对上的人工评估(使用 MQM)确认 TranslateGemma 在多数情况下表现更优,尤其在低资源语言对上提升显著(如 英语→马拉地语 +1.6,英语→斯瓦希里语 +1.0),但日语→英语任务中因命名实体错误出现性能下降。
结果表明,TranslateGemma 模型在所有尺寸上均持续优于基线 Gemma 3 模型,MetricX 与 CoMET22 指标均表现优异,27B TranslateGemma 相较于 27B 基线实现 23.5% 的 MetricX 分数相对降低。提升效果在不同模型尺寸间保持一致,较小的 TranslateGemma 模型达到或超越更大基线模型的性能,表明其效率与翻译质量均得到增强。
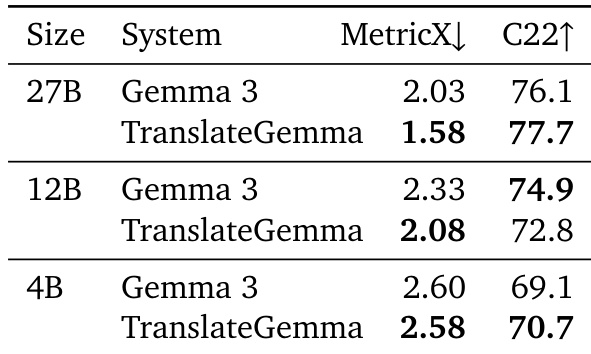
结果表明,TranslateGemma 模型在所有评估尺寸和指标上均持续优于基线 Gemma 3 模型,MetricX 与 COMET22 分数均有显著提升。27B TranslateGemma 模型的 MetricX 得分为 1.58,相比基线 Gemma 3 的 2.03 有显著降低,12B 与 4B TranslateGemma 模型也均显著优于各自基线。
作者使用 TranslateGemma 模型评估多个语言对的翻译质量,与基线 Gemma 3 模型进行对比,采用 MetricX 分数。结果表明,TranslateGemma 在所有尺寸与语言对上均持续获得更低的 MetricX 分数,表明翻译质量提升,12B TranslateGemma 模型在多个案例中表现优于更大的 27B Gemma 3 模型。
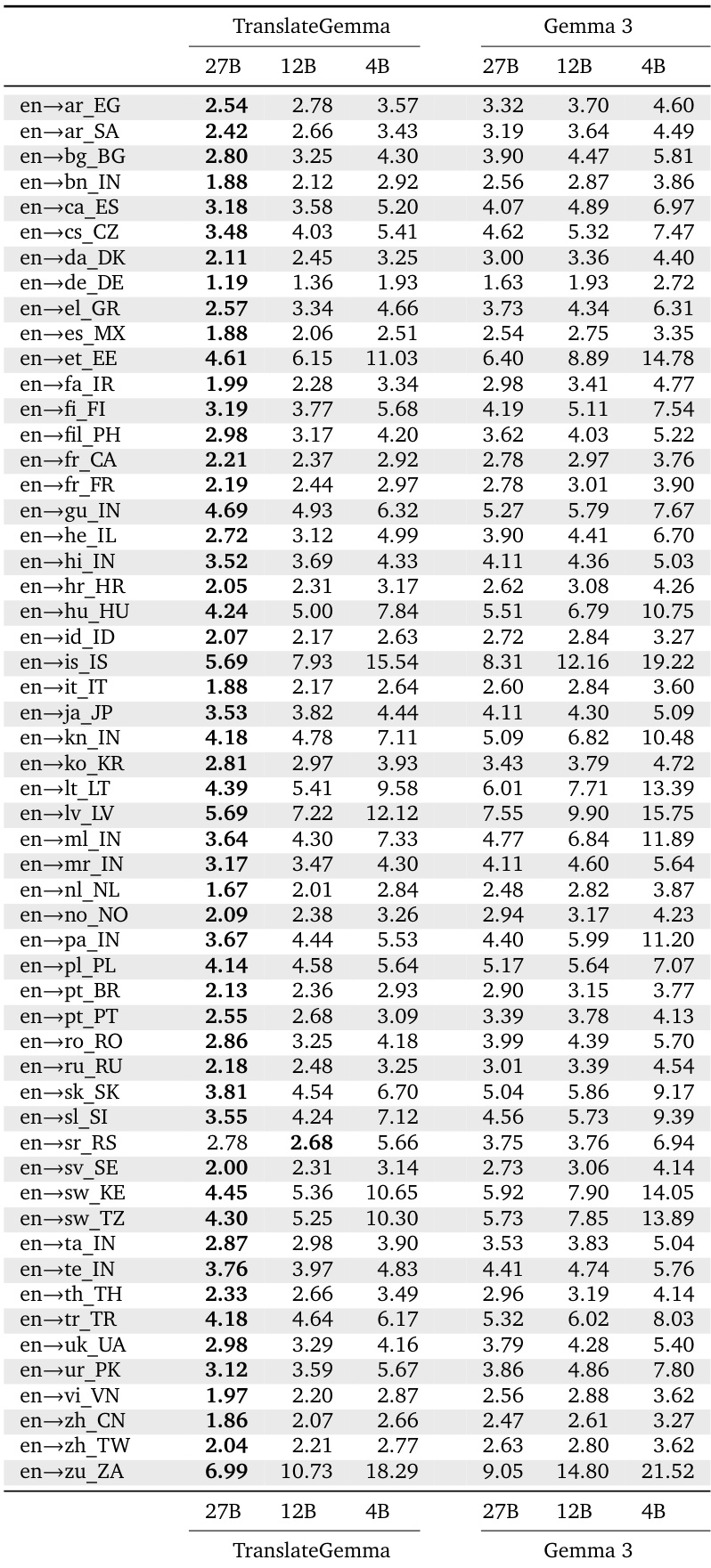
结果表明,TranslateGemma 模型在所有评估语言对上均获得低于基线 Gemma 3 模型的 MetricX 分数,表明翻译质量提升。27B TranslateGemma 模型始终优于 27B Gemma 3 模型,例如在 英语→德语 上得分从 2.2 降至 1.8,在 英语→中文 上从 7.4 降至 6.3。