Command Palette
Search for a command to run...
视频生成中的运动归因
视频生成中的运动归因
Xindi Wu Despoina Paschalidou Jun Gao Antonio Torralba Laura Leal-Taixé Olga Russakovsky Sanja Fidler Jonathan Lorraine
摘要
尽管视频生成模型取得了快速发展,但数据对运动特性的影响机制仍缺乏深入理解。为此,我们提出了Motive(MOTIon attribution for Video gEneration),一种以运动为中心、基于梯度的数据归因框架,能够扩展至现代大规模、高质量的视频数据集与模型。利用该框架,我们系统研究了哪些微调片段有助于提升或损害时间动态性。Motive通过运动加权损失掩码,将时间动态性与静态外观特征有效分离,实现了高效且可扩展的运动特异性影响计算。在文本到视频模型上,Motive能够识别出显著影响运动表现的视频片段,并指导数据筛选,从而提升生成视频的时间一致性与物理合理性。采用Motive筛选出的高影响力数据进行微调后,我们的方法在VBench评测中同时提升了运动流畅性与动态表现力,相较于预训练基线模型,人类偏好得分达到74.1%的胜率。据我们所知,这是首个针对视频生成模型中运动而非视觉外观进行归因,并据此优化微调数据集的框架。
一句话总结
NVIDIA、普林斯顿大学和MIT CSAIL的研究人员提出了Motive,一种以运动为中心的基于梯度的数据归因框架,通过运动加权损失掩码将时序动态与静态外观分离,实现了对影响微调片段的可扩展识别,从而提升文本到视频生成中的运动平滑性和物理合理性,在VBench上取得了74.1%的人类偏好胜率。
主要贡献
- Motive是首个在视频生成模型中对运动而非静态外观进行归因的框架,填补了理解训练数据如何影响轨迹、形变和物理合理性等时序动态的关键空白。
- 它引入了运动加权损失掩码,以高效分离动态区域并计算特定于运动的梯度,支持在大规模视频数据集和现代扩散模型上实现可扩展的归因。
- 使用Motive指导微调数据筛选,显著提升了VBench上的运动平滑性和动态程度,相较于预训练基线模型,人类偏好胜率达到74.1%。
引言
视频生成模型,尤其是基于扩散的模型,高度依赖训练数据来学习真实世界的运动动态,如物体轨迹、形变和交互。与关注静态外观的图像生成不同,视频模型必须捕捉时序一致性与物理合理性——这些特性深深植根于训练数据之中。然而,现有的数据归因方法主要针对静态图像设计,难以分离出运动特异性影响,常将时序结构坍缩为帧级外观。这限制了其解释特定训练片段如何塑造运动的能力,尤其是在复杂、长距离序列中。
作者提出了Motive,一种面向运动的数据归因框架,通过使用动态运动掩码计算梯度,强调时序一致的区域而非静态背景。通过将光流等运动先验整合到归因过程中,Motive实现了运动与外观的解耦,并能追溯生成动态背后的高影响力训练片段。该方法支持针对性的数据筛选与微调,提升运动质量的同时提供对运动模式如何从数据中涌现的可解释性。它解决了关键挑战:运动定位、跨序列扩展以及捕捉速度和轨迹一致性等时序关系。尽管仍存在局限性,如对运动追踪精度敏感、难以区分相机运动与物体运动,Motive仍提供了一种可扩展、原理清晰的方法,用于理解和控制视频扩散模型中的运动。
数据集

- 数据集包含一组精心筛选的合成查询视频,旨在隔离特定的运动基元,数据来源为Veo-3 [Google DeepMind, 2025],一个视频生成模型。
- 查询集包含10种运动类型——压缩、弹跳、滚动、爆炸、漂浮、自由落体、滑动、旋转、拉伸和摆动,每类5个高质量样本,总计50个查询视频。
- 每个视频均通过精心设计的提示生成,并经过严格的生成后筛选,确保物理合理性和视觉真实感,最大限度减少纹理背景或不受控相机运动等混淆因素。
- 合成查询不用于训练,而是作为归因分析和多查询聚合的目标刺激,实现对模型行为中运动特异性影响的精确测量。
- 数据集专为受控评估设计,规模虽小但具有代表性,支持可处理的归因计算,同时覆盖研究中使用的完整运动分类体系。
- 查询视频未进行裁剪或元数据构建,以原始形式使用,作为标准化、接近真实的刺激。
方法
作者提出了Motive,一种面向视频生成模型中运动为中心的数据归因框架,旨在分离并量化训练数据对时序动态的影响。整体架构包含两个核心组件:运动归因与高效梯度计算。运动归因过程首先通过AllTracker算法检测视频中的运动,提取光流图以表示连续帧间的像素位移。这些光流图随后用于生成运动幅度块,经归一化和下采样后与生成模型的潜在空间对齐。该运动掩码随后应用于扩散损失,生成强调动态区域而弱化静态内容的运动加权损失。由此产生的运动加权梯度被计算并用于推导影响分数。
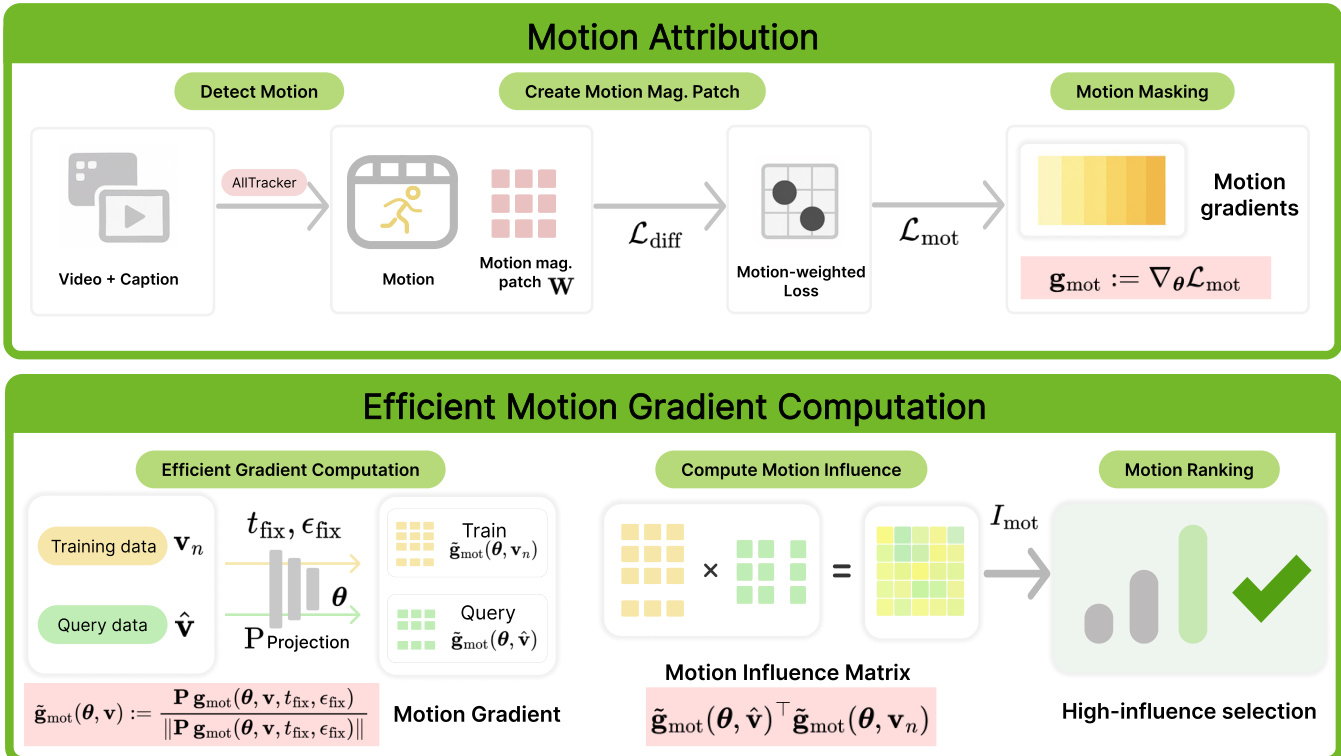
如图所示,该框架高效地计算梯度。通过单样本变体实现,所有训练和查询数据均使用固定的采样时间步 tfix 和共享的噪声样本 ϵfix,显著降低计算成本。随后,梯度通过Fastfood投影映射到低维空间,实现可处理的存储与计算。训练片段的影响分数通过查询数据与训练数据投影后归一化梯度之间的余弦相似度计算得出。该过程对多个查询视频重复执行,并通过多数投票机制聚合影响分数,以选出在不同运动模式下均具影响力的微调子集。最终输出为一个按影响力排序的训练片段列表,选取前K个样本用于针对性微调,以提升运动质量。
实验
- 主实验验证了基于梯度归因与负向过滤的运动感知数据选择,展示了在多种运动类型(压缩、旋转、滑动、自由落体、漂浮、行星旋转)下运动保真度与时序一致性的提升。
- 在VBench评估中,Motive达到47.6%的动态程度,超过随机选择(41.3%)和全视频归因(43.8%),同时保持96.3%的主体一致性与46.0%的美学质量,仅使用10%的训练数据即优于全微调模型(42.0%动态程度,95.9%主体一致性)。
- 人类评估显示,相较于基线模型胜率为74.1%,相较于全微调模型胜率为53.1%,证实了感知运动质量的提升。
- 消融研究确认:在t=751的单时间步归因与多时间步平均具有高相关性(ρ=66%),帧长归一化使虚假长度相关性降低54%,512维梯度投影在保持排名相关性(ρ=74.7%)的同时实现最优效率。
- 该方法可泛化至更大模型(Wan2.2-TI2V-5B),在不同架构上均保持强劲性能。
- 运动分布分析显示,高影响力视频覆盖完整的运动谱系——前10%与后10%的平均运动幅度差异仅为4.3%,表明该方法选择的是运动特异性影响,而非仅运动丰富性。
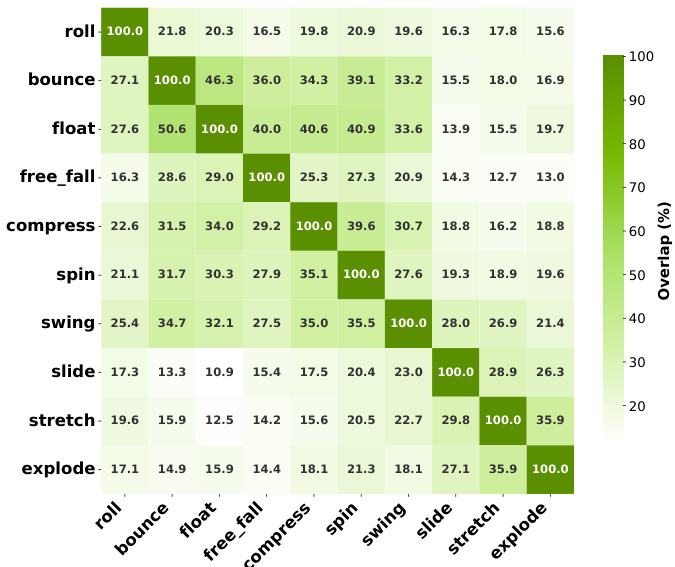
- 跨运动影响模式显示,不同数据集间存在一致重叠(如弹跳-漂浮:44.4%/46.3%),反映出模型表征中基本动态的相似性。
- 运行时间分析表明,一次性的梯度计算(在1张A100上约150小时)可分摊至多个查询,新增查询仅需约54秒,支持可扩展的数据筛选。
结果表明,所提出的Motive方法在所有评估方法中取得了最高的动态程度得分(47.6%)和主体一致性(96.3%),在关键运动保真度指标上优于随机选择与全微调,同时在其他质量维度上保持强劲表现。作者通过运动感知归因选择训练数据,相比基线方法显著提升了运动动态与时序一致性,即使仅使用10%的训练数据亦可实现。
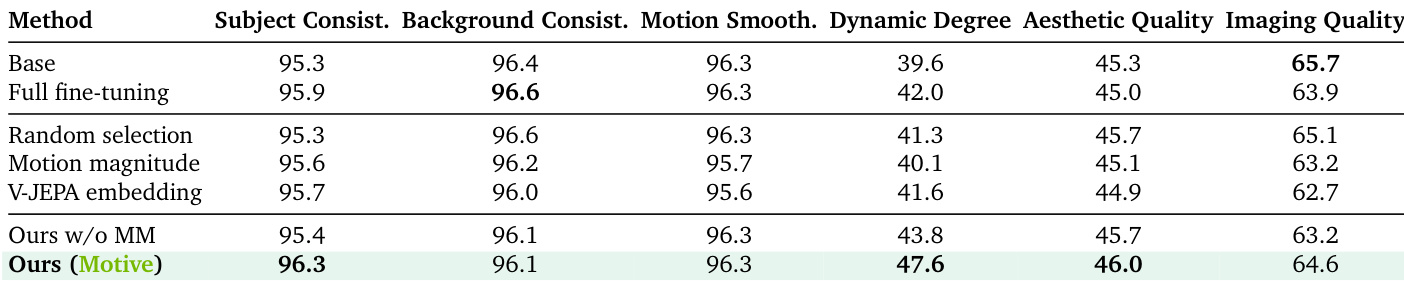
作者通过运动感知归因选择微调训练数据,相比基线方法实现了更高的运动保真度与时序一致性。结果表明,其方法Motive在动态程度与主体一致性等关键指标上优于随机选择与全微调,同时在美学与成像质量方面保持优异表现。

作者进行了人类评估,将该方法与基线进行对比,结果显示在与基线模型的两两比较中,参与者偏好该方法的比例达到74.1%,与全微调模型相比为53.1%。结果表明,其运动感知数据选择带来了感知上更优的运动质量,所有比较中胜率更高、失败率更低。
作者将该方法的计算运行时间与多个基线方法在单GPU上处理10k训练样本的性能进行对比。结果显示,该方法总计算耗时约150小时,显著长于随机选择(<1秒)、运动幅度(~5.5小时)、光流(~5.7小时)和V-JEPA(~3小时)等基线。这一高成本源于训练数据的一次性梯度计算,但该成本可分摊至所有查询,并可通过并行化进一步降低。

结果表明,Motive在不同运动类别间识别出具有高度重叠的高影响力训练数据,尤其在语义相似的运动如弹跳与漂浮之间重叠显著(44.4%和46.3%),而差异较大的运动如自由落体与拉伸则重叠较低(12.8%和12.7%)。不同数据集间的一致模式表明,该方法捕捉到了基本的运动关系,反映了视频生成模型中共享的动态特性。