Command Palette
Search for a command to run...
Ministral 3
Ministral 3
摘要
我们推出Ministral 3系列,这是一组专为计算资源和内存受限场景设计的参数高效密集型语言模型,提供三种模型规模:30亿(3B)、80亿(8B)和140亿(14B)参数。针对每种规模,我们发布三个版本:一个适用于通用任务的预训练基础模型、一个经过指令微调的版本,以及一个用于复杂问题求解的推理模型。此外,我们介绍了通过“级联蒸馏”(Cascade Distillation)技术构建Ministral 3系列模型的方法,该技术结合了迭代剪枝与持续蒸馏训练,有效提升模型效率。所有模型均具备图像理解能力,且全部采用Apache 2.0许可证开源发布。
一句话摘要
作者提出Ministral 3,一个参数高效的密集语言模型系列(3B–14B),具备图像理解能力,通过级联蒸馏技术在计算和内存受限环境中实现,提供预训练、指令微调和推理三种变体,采用Apache 2.0许可。
主要贡献
-
Ministral 3系列引入了9个参数高效的密集语言模型——3B、8B和14B三种规模,每种均提供预训练基础版、指令微调版和推理版,全部支持图像理解及最高256k token的上下文长度,专为计算和内存受限环境部署而设计。
-
模型通过级联蒸馏(Cascade Distillation)技术生成,这是一种迭代剪枝与蒸馏方法,逐步将强大24B父模型(Mistral Small 3.1)的知识迁移至更小的子模型,相比从零训练的模型,显著降低了训练所需的计算资源和数据量。
-
评估结果表明,Ministral 3模型在标准基准测试中表现具有竞争力,性能可与Gemma 3和Qwen 3等同规模的开源模型比肩或超越,其中14B基础模型在效率上优于其更大的父模型,同时保持了强大的推理与指令遵循能力。
引言
本研究处于大语言模型开发的技术背景下,该领域的发展依赖于来自不同专家的协作贡献。以往工作常面临贡献者归属不一致、知识共享碎片化以及个体贡献者角色与影响透明度不足等问题。作者通过提供一份全面且结构化的核心研究人员与贡献者名单,解决了这些局限,实现了更清晰的信用分配、更高的可复现性,并为未来协作研究提供了更好的协调基础。
方法
Ministral 3模型采用分层训练框架构建,从一个大型父模型出发,通过称为“级联蒸馏”的过程迭代生成更小、更高效的变体。该方法实现了三种模型规模——3B、8B和14B参数——每种均提供基础版、指令遵循版和推理版,全部源自Mistral Small 3.1模型。整体训练流程包括预训练阶段,以及后续两个独立的后训练阶段,分别用于指令遵循和推理能力的增强。
Ministral 3系列的核心架构基于仅解码器的Transformer,所有模型共享共同基础,但规模可扩展。如附表所示,3B、8B和14B模型分别包含26、34和40层。关键架构组件包括:32个查询头与8个键值头的分组查询注意力(Grouped Query Attention)、RoPE位置嵌入、SwiGLU激活函数和RMSNorm归一化。为支持长上下文处理,模型采用YaRN和基于位置的softmax温度缩放。3B变体使用输入输出嵌入共享以减少参数开销,所有模型均采用131K词表大小,并支持最高256K token的上下文长度。为实现多模态能力,每个模型集成一个410M参数的ViT视觉编码器,直接从Mistral Small 3.1复制并保持冻结,仅针对每个模型训练一个新投影层,将视觉特征映射至语言模型空间。
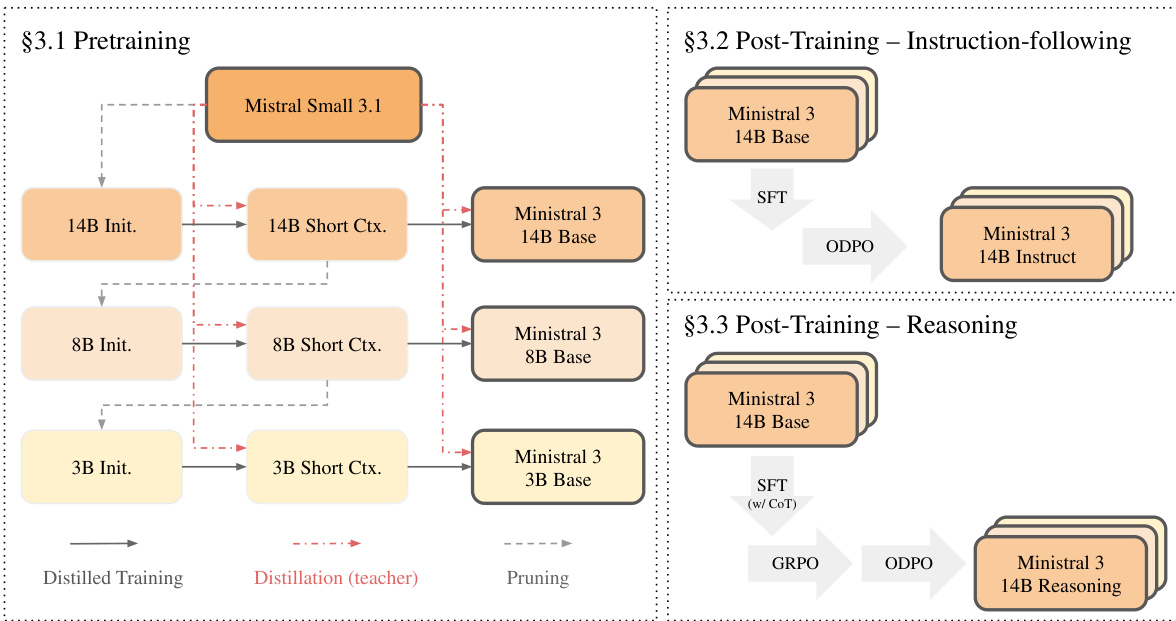
如图所示,预训练阶段从Mistral Small 3.1模型开始,通过迭代的“剪枝-蒸馏-重复”循环生成更小的模型。过程始于对父模型进行剪枝,以初始化目标规模的子模型,随后通过蒸馏训练恢复性能。该流程对每种模型规模重复进行,前一阶段的输出作为下一阶段的输入。具体而言,14B模型首先被剪枝生成14B Init.模型,再在短上下文数据上进行蒸馏训练,利用父模型的logits作为教师信号,生成14B Short Ctx.模型。该模型进一步通过第二阶段蒸馏扩展为长上下文版本(14B Base),使用更长上下文数据。随后,14B Short Ctx.模型被剪枝以初始化8B Init.模型,相同流程用于推导8B Base模型。该级联流程同样用于生成3B Base模型。这种结构确保每个更小的模型均受益于更大父模型的知识,同时避免各阶段间重复的数据处理。
初始化阶段采用的剪枝策略旨在保留父模型中最关键的组件。其包含三项关键技术:基于输入与输出激活范数比值的层剪枝、利用注意力与前馈归一化层拼接激活的主成分分析(PCA)进行隐藏维度剪枝,以及针对SwiGLU结构的前馈维度剪枝,通过选择激活表达式平均绝对值较大的维度实现。剪枝完成后,模型通过logits蒸馏训练,以父模型作为教师。预训练阶段分为两个阶段:第一阶段为短上下文阶段,窗口大小为16,384 token;第二阶段为长上下文阶段,通过YaRN和基于位置的温度缩放将上下文扩展至262,144 token。
预训练完成后,每个基础模型进入后训练阶段,生成指令遵循和推理变体。指令遵循模型采用两阶段流程:监督微调(SFT)后接在线直接偏好优化(ODPO)。相比之下,推理模型则从预训练检查点出发,采用三阶段流程:使用思维链数据进行SFT、组相对策略优化(GRPO),再进行ODPO。这种结构化方法确保每种变体在满足其特定用途的同时,保持底层基础模型的高效性与高性能。
实验
- 使用fp8量化和来自Mistral Medium 3的logits蒸馏进行监督微调(SFT),验证了高效的参数高效训练,其中视觉编码器冻结,适配器可训练,实现了强大的下游性能。
- 通过两阶段GRPO强化学习——STEM RL(数学、代码、视觉推理)和General RL(指令遵循、对话、开放式推理)——验证了推理与对齐能力的提升,更长的生成长度(最高80K)支持复杂推理链的完成,显著提升性能。
- 在MMLU、MATH、GPQA Diamond和MMMU基准测试中,Ministral 3 14B优于Qwen 3 14B,并显著超越Gemma 12B;Ministral 3 8B在多数任务上超过Gemma 12B,展现出极高的参数效率。
- Ministral 3 Instruct模型在通用、数学、代码和多模态基准测试中与Qwen 3和Gemma 3系列表现相当,Ministral 3 Reasoning模型在STEM任务上与Qwen 3对应模型持平或超越。
- 在预训练阶段使用经过后训练和偏好调优的Mistral Small 3.1教师进行蒸馏,相比使用更大但未经优化的教师,显著提升了STEM和多模态性能,验证了教师质量优于规模的重要性。
- 在GRPO检查点上进行ODPO后训练,显著提升了Ministral 3 14B和8B模型在对齐基准测试中的对话质量,3B模型虽在公开基准上提升有限,但在内部人类评估中表现出增益。
作者将Ministral 3 Instruct模型与Qwen 3和Gemma 3模型在后训练基准上进行对比,结果显示Ministral 3 14B在AIME 2024和AIME 2025上优于Qwen 3 14B,同时在其他任务上也表现具有竞争力。在较小规模下,Ministral 3 8B和3B模型相对于其Qwen 3对应模型表现出强劲性能,8B模型在多个基准上与Qwen3-VL 8B持平或超越。
作者将Ministral 3 Instruct模型与Qwen 3和Gemma 3系列的指令微调基线进行对比,结果显示Ministral 3 14B在Arena Hard、WildBench和MATH上优于Qwen3 14B(Non-Thinking)和Gemma3-12B-Instruct,同时在多数基准上高于Qwen3-VL-8B-Instruct。在较小规模下,Ministral 3 8B和3B模型与Qwen3-VL变体具有竞争力,尤其在MATH和MM MTBench上表现突出。
作者将Ministral 3 Base模型与教师模型Mistral Small 3.1 24B在多个基准上进行对比,结果显示性能随模型规模平滑增长,而剪枝后的Ministral 3变体在大幅减少参数后仍保留了教师模型的大部分能力。14B模型在MMLU-Redux和ARC-Challenge上优于24B教师模型,8B和3B模型在多数通用和数学基准上表现具有竞争力,表明其具有极强的参数效率。
作者将Ministral 3 14B和8B模型与同规模的Qwen 3和Gemma 3模型在预训练基准上进行对比。结果显示,Ministral 3 14B在TriviaQA和MATH上优于Qwen 3 14B,其他任务上表现相当;Ministral 3 8B在多数评估中超越更大的Gemma 12B,仅在TriviaQA上略逊。
作者在Ministral 3模型中采用一致架构,仅在层数、隐层维度和前馈网络维度上变化,同时保持固定的256k token上下文长度。3B变体包含共享嵌入,而更大的8B和14B模型未采用;所有模型共享相同的Q/KV头配置(32/8)。