Command Palette
Search for a command to run...
你的组相对优势存在偏差
你的组相对优势存在偏差
摘要
基于验证器奖励的强化学习(Reinforcement Learning from Verifier Rewards, RLVR)已成为在推理任务上对大型语言模型进行后训练的广泛应用方法,其中基于群体的方法(如GRPO及其变体)已获得广泛采纳。这类方法依赖于群体相对优势估计来避免使用学习型价值函数(critic),但其理论性质至今仍缺乏深入理解。在本工作中,我们揭示了基于群体的强化学习存在一个根本性问题:群体相对优势估计器相对于真实(期望)优势而言本质上是存在偏差的。我们首次提供了理论分析,表明该方法会系统性地低估困难提示(hard prompts)的优势,而高估简单提示(easy prompts)的优势,从而导致探索与利用之间的失衡。为解决此问题,我们提出了一种历史感知的自适应难度加权机制(History-Aware Adaptive Difficulty Weighting, HA-DW),该方法通过动态调整难度基准和训练过程中的动态特性,对优势估计进行自适应重加权。理论分析与在五个数学推理基准上的实验结果均表明,将HA-DW集成至GRPO及其变体中,能够持续提升模型性能。我们的研究结果表明,纠正优势估计中的偏差对于实现稳健且高效的RLVR训练至关重要。
一句话总结
北京航空航天大学、加州大学伯克利分校、北京大学与美团的研究人员提出 HA-DW,一种历史感知的自适应难度加权方法,用于纠正基于验证器奖励的 GRPO 强化学习中组内相对优势估计的固有偏差,改善探索与利用的平衡,并在五个数学推理基准上显著提升性能。
主要贡献
- 基于组的验证器奖励强化学习(RLVR)方法(如 GRPO)依赖组内相对优势估计以避免使用学习到的评论家,但该方法存在固有偏差:对困难提示系统性地低估优势,对简单提示则高估优势,导致探索与利用失衡。
- 作者提出历史感知自适应难度加权(HA-DW),一种新颖的重加权机制,通过利用长期奖励趋势和历史训练动态演化出的难度锚点,动态调整优势估计以纠正此偏差。
- 在五个数学推理基准上的实验表明,将 HA-DW 集成到 GRPO 及其变体中,能一致地提升不同模型规模下的性能,甚至优于使用更多采样轨迹的版本,证明无偏优势估计在 RLVR 中的关键作用。
引言
本文研究基于验证器奖励的强化学习(RLVR),这是大语言模型在推理任务后训练的关键范式。其中,基于组的方法(如 GRPO)因简单高效而占据主导地位。这些方法在每个提示的少量采样轨迹内估计优势,无需独立评论家,但先前工作缺乏对其底层假设的严格理论理解。本文揭示了一个根本性缺陷:组内相对优势估计存在系统性偏差——对困难提示低估真实优势,对简单提示高估优势,导致探索与利用失衡,损害训练稳定性和泛化能力。为解决此问题,作者提出历史感知自适应难度加权(HA-DW),一种动态重加权机制,利用长期奖励趋势和历史训练数据演化出的难度锚点来调整优势估计。理论分析与五个数学推理基准的实验表明,将 HA-DW 集成到 GRPO 及其变体中能持续提升性能,甚至超越使用更多采样轨迹的版本,证明纠正该偏差对鲁棒高效 RLVR 训练至关重要。
方法
所提出的方法——历史感知自适应难度加权(HA-DW),旨在解决语言模型强化学习中组内相对优势估计的固有偏差。该框架包含两个主要阶段:一个随时间演化的难度锚点,用于追踪模型能力的变化;以及一个基于历史的自适应重加权机制,根据该演化状态调整优势估计。整体架构旨在纠正 GRPO 及其变体中常见的问题:对困难提示的系统性低估和对简单提示的系统性高估。
该方法的核心是演化难度锚点,其将模型求解能力建模为一个隐式信念状态,记为 Ct。该信念通过类似卡尔曼滤波的方式在训练批次间更新。在每一步 t,观测值 yt(即批次级别的准确率,即正确响应的比例)用于将先验信念 Ct− 更新为后验信念 Ct+。更新规则为 Ct+=(1−ηt)Ct−+ηtyt,其中 ηt 为动态遗忘因子。该因子由模型稳定性调节,即前 m 个批次信念的标准差。标准差越大,表示模型不稳定或能力快速变化,ηt 越高,使模型能快速适应;标准差越小,表示模型稳定,ηt 越低,从而保留历史信息并减少噪声。该演化信念 Ct 作为后续难度自适应重加权策略的历史感知锚点。
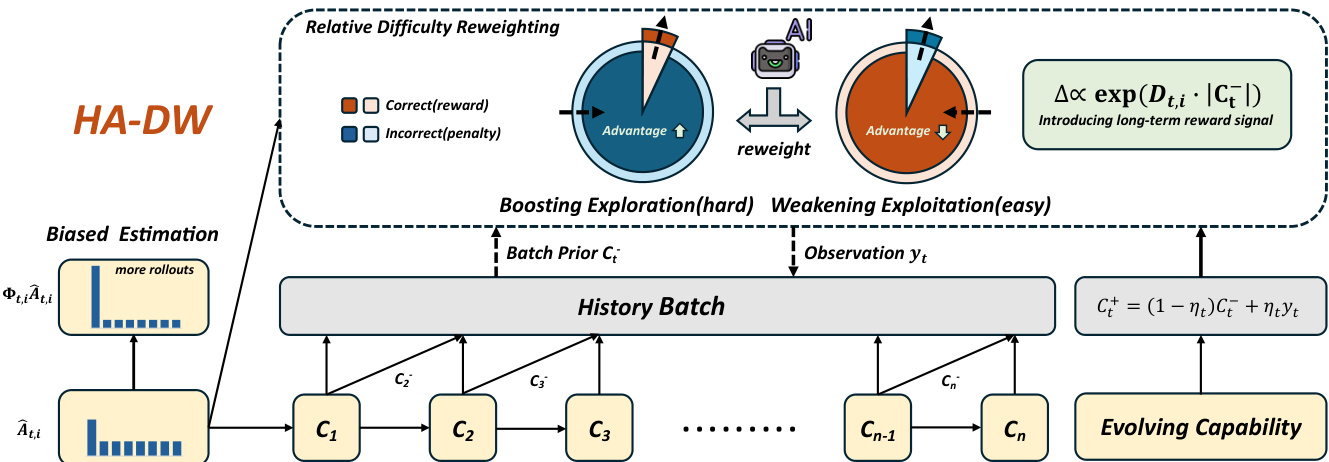
第二阶段为历史感知自适应难度加权,利用演化难度锚点校正有偏的优势估计。基于历史的提示难度定义为 diffthis=p^t−Ct−,其中 p^t 为经验组基线。该值捕捉当前提示难度与模型当前能力的偏差。调整方向由估计优势符号与历史难度符号的乘积符号决定,即 Dt,i=−sgn(A^t,i)⋅sgn(diffthis)。这确保对困难提示(A^t,i 可能被低估)放大优势,对简单提示(A^t,i 可能被高估)抑制优势。调整幅度由绝对历史难度 Mt=∣diffthis∣ 衡量。最终的历史感知重加权因子定义为 Φt,i=λscale⋅exp(Dt,i⋅Mt),这是一个平滑的乘法因子,应用于策略目标中的优势项。该重加权目标 LHA-DW(θ) 用于策略更新,有效缓解了理论分析中识别出的偏差。
实验
- 在 Qwen3-4B-Base、Qwen3-8B-Base 和 LLaMA-3.2-3B-Instruct 上,对 GRPO、GSPO 和 DAPO 五个 RLVR 基准进行 HA-DW 评估,结果表明其在所有方法中均一致提升性能。
- 在 MATH500 上,GRPO+HA-DW 在 Hard 级别提示上准确率比 GRPO 提高 3.4%,验证了在挑战性任务上探索能力的增强。
- 训练动态显示,HA-DW 使准确率达到更高平台,训练奖励增加,推理链更长,表明推理能力显著提升。
- 对动态阈值 Ct 的消融实验确认其优于固定阈值,移除后性能下降,凸显其捕捉长期奖励信号的关键作用。
- 对 MATH 和 DAPO-Math-17k 的实证分析显示,在低采样数(8)时正确响应被低估,证实困难提示上存在优势估计偏差。
- 理论分析证明组内相对优势估计存在系统性偏差:对简单提示(pt>0.75)高估,对困难提示(pt<0.25)低估,当 G∈[2,8] 时偏差概率超过 78%。
- 扩展至非二值奖励(Beta 和截断高斯)确认类似偏差模式,且偏差幅度随提示难度偏离 0.5 而增大。
- 对组大小 G 的消融实验表明,HA-DW 在低样本场景下优于更大采样数,为扩大采样提供了一种计算高效的替代方案。
- 对 λscale 的消融实验识别出最优值(1.3–1.5),可在不同难度间平衡调整,最大化性能。
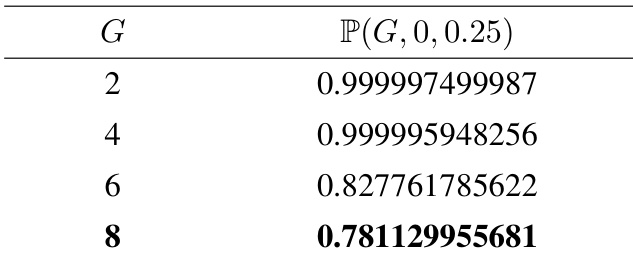
作者使用表格量化组内相对强化学习中困难提示的偏差优势估计概率,显示随着组大小 G 增大,基线高估概率降低。结果表明,当 G=2 时概率超过 0.999,而 G=8 时降至 0.781,表明更大的组大小可降低偏差可能性。
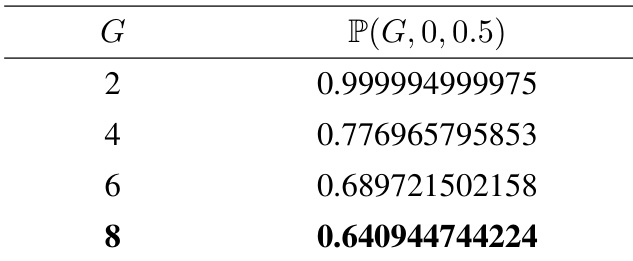
作者使用表格分析组内相对强化学习算法中偏差优势估计概率随组大小 G 增加的变化。结果显示,概率 P(G,0,0.5) 随 G 增大显著下降,表明随着组大小增加,优势估计偏差的可能性降低。
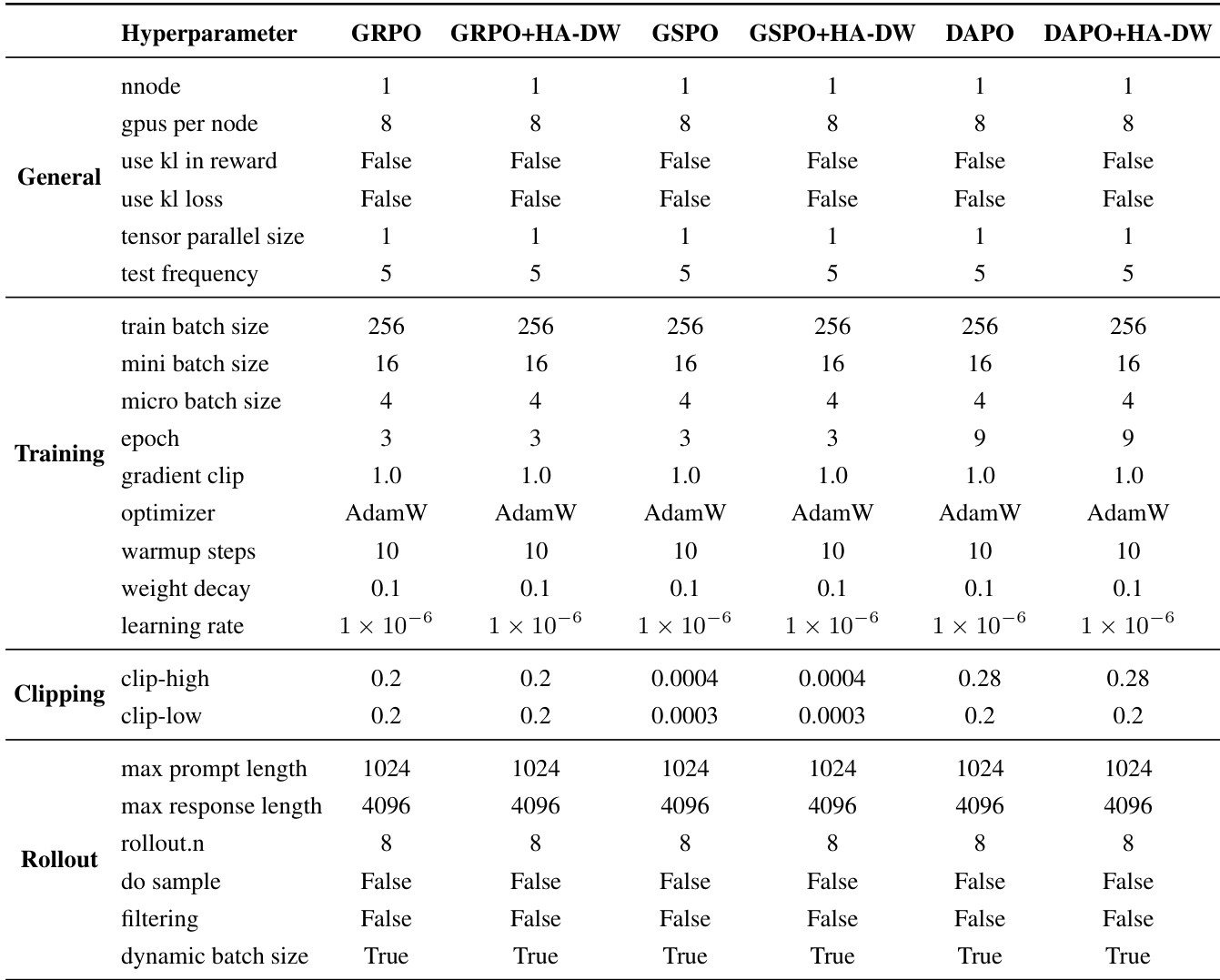
作者在所有实验中使用一致的超参数设置,主要区别在于 HA-DW 在 GRPO、GSPO 和 DAPO 上的应用。表格显示,HA-DW 引入的唯一修改是学习率和裁剪阈值,其余所有设置保持一致,确保公平比较。
作者使用表格量化组内相对强化学习算法中偏差优势估计概率,显示随着组大小 G 增大,对困难提示的优势高估概率和对简单提示的低估概率均上升。结果显示,组大小越大,偏差越明显,当 G=6 时概率达 0.781,表明大组加剧了估计偏差。

结果表明,将 HA-DW 应用于组内相对强化学习算法可提升五个基准上的性能,使用 HA-DW 训练的模型在准确率和奖励上均优于原始方法。训练动态显示,HA-DW 增强了对困难提示的探索能力,并鼓励更长的推理链,从而带来整体性能提升。
