Command Palette
Search for a command to run...
JudgeRLVR:先判断,后生成,实现高效推理
JudgeRLVR:先判断,后生成,实现高效推理
Jiangshan Duo Hanyu Li Hailin Zhang Yudong Wang Sujian Li Liang Zhao
摘要
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)已成为大语言模型推理任务中的标准范式。然而,仅以最终答案正确性为目标进行优化,往往导致模型陷入无目的、冗长的探索过程,依赖穷举式的试错策略,而非结构化的规划来获取解。尽管可通过长度惩罚等启发式约束减少冗余输出,但这类方法常会截断关键推理步骤,造成效率与验证能力之间的艰难权衡。本文提出,判别能力是实现高效生成的前提:通过学习区分有效解与无效解,模型能够内化一种引导信号,从而有效剪枝搜索空间。为此,我们提出JudgeRLVR,一种两阶段“先判断、后生成”的新范式。在第一阶段,我们训练模型对具有可验证答案的解题过程进行判断;在第二阶段,我们以该判别模型为初始状态,采用标准生成式RLVR对其进行微调。相较于使用相同数学领域训练数据的原始RLVR方法,JudgeRLVR在Qwen3-30B-A3B模型上实现了更优的质量-效率平衡:在领域内数学任务上,平均准确率提升约3.7个百分点,同时平均生成长度减少42%;在领域外基准测试中,平均准确率提升约4.5个百分点,展现出更强的泛化能力。
一句话总结
北京大学与小米的研究人员提出 JudgeRLVR,一种两阶段强化学习框架,首先训练模型判断可验证解的有效性,从而通过剪枝搜索空间实现更高效的推理;该方法在 Qwen3-30B-A3B 上提升了准确率与生成效率,在域外数学基准测试中准确率最高提升 +4.5,同时显著降低冗余输出。
主要贡献
- 本文指出强化学习结合可验证奖励(RLVR)的一个关键局限:仅优化最终答案正确性会导致冗长、无结构的试错式探索,伴随大量回溯,损害效率且无法保证更高质量的推理过程。
- 提出 JudgeRLVR,一种两阶段范式:模型先学习判断解的有效性,再进行生成微调,从而内化判别性先验,无需显式长度惩罚即可剪枝低质量推理路径。
- 在 Qwen3-30B-A3B 上,JudgeRLVR 在域内数学任务中实现 +3.7 的平均准确率提升,生成长度减少 42%;在域外基准测试中准确率提升 +4.5,展现出更优的质量-效率权衡,并显著降低对显式回溯线索的依赖。
引言
作者针对通过可验证奖励强化学习(RLVR)训练的大语言模型中存在的推理低效与冗长问题展开研究,指出模型常依赖试错探索而非结构化、目标导向的思维。尽管 RLVR 能提升最终答案的准确率,却未能促进高质量推理模式的形成,导致信息密度低、生成长度过长——这一问题在使用长度惩罚等启发式修复手段时进一步加剧,以牺牲准确率为代价换取简洁性。为克服上述挑战,作者提出 JudgeRLVR,一种两阶段训练范式:首先,模型作为裁判训练以区分正确与错误的解题响应,内化有效的推理信号;其次,使用原始 RLVR 对同一模型进行生成微调,初始化权重来自裁判阶段。该方法隐式剪枝无效推理路径,无需显式约束,从而实现更直接、连贯且高效的推理。在 Qwen3-30B-A3B 上,JudgeRLVR 在域内数学任务中实现 +3.7 准确率提升,生成长度减少 42%;在域外基准测试中准确率提升 +4.5,展现出更优的质量-效率权衡及对回溯线索的更低依赖。
数据集

- 数据集包含来自多个来源的数学推理问题,每个问题配有标准答案 a∗(x),以及包含逐步逻辑推理过程并以最终答案结尾的解题响应 z=(o1,…,oT)。
- 最终答案 a(z) 通过确定性解析器从解题响应中提取,正确性通过比较 a(z) 与 a∗(x) 判定,生成二元标签 ℓ(x,z)=I(a(z)=a∗(x))。
- 模型训练目标是判断干净解题响应的正确性,而非完整推理轨迹,从而避免长篇、干扰性强的思维链(CoT)序列带来的噪声,实现更精准的错误检测。
- 训练与评估使用域内数学基准:AIME24、AIME25、MATH500、HMMT_feb_2025 和 BeyondAIME,均来自已发表文献,经筛选以确保高质量推理问题。
- 域外评估涵盖多样化能力,使用基准如 GPQA Diamond(科学推理)、IFEval(指令遵循)、LiveCodeBenchv6(编程)、MMLU-Redux(通用知识)和 ZebraLogic(逻辑推理)。
- 模型在上述数据集的混合数据上训练,采用精心平衡的比例以确保跨领域鲁棒性,未使用显式裁剪策略,数据在标准预处理后直接使用。
- 每个问题的元数据包括来源、难度等级和问题类型,于数据集构建阶段生成,以支持细粒度分析与评估。
方法
作者采用两阶段训练范式 JudgeRLVR,通过解耦判别性错误感知与解题生成,提升推理效率。整体框架包含判别阶段与生成阶段,模型先学习评估候选解的正确性,再被优化以生成高质量输出。该顺序设计旨在使模型内化有效推理模式,从而提升生成质量并减少不必要的计算。
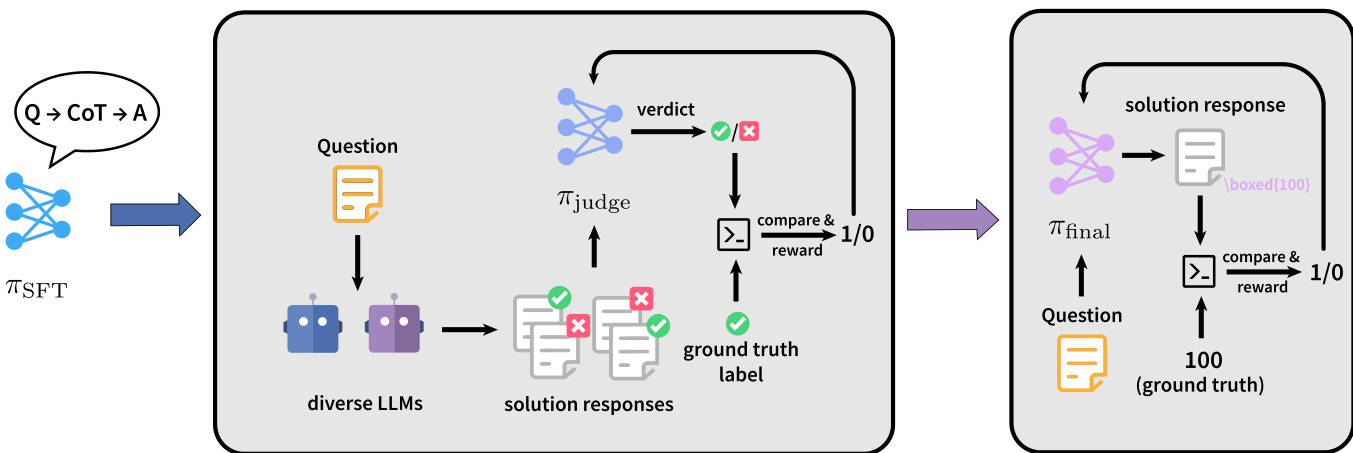
如图所示,训练流程始于一个监督微调模型 πSFT,作为两个阶段的基础。在判别阶段,模型被训练为评判者。给定问题 x 和候选解题响应 z,策略 πjudge 生成包含思维链(CoT)轨迹的评述 c,以及一个离散的判断标记 v∈{0,1},其中 0 表示错误解,1 表示正确解。模型在判别数据集 Djudge 上训练,该数据集由三元组 (x,z,ℓ) 构成,其中 ℓ 为真实标签,由比较最终答案 a(z) 与正确答案 a∗(x) 得出。数据构建过程包括从多种大语言模型(LLMs)生成推理轨迹、通过硬负样本挖掘聚焦中等难度问题,以及类别平衡以确保正确与错误解的均衡表示。该阶段奖励为二元信号,基于预测判断 vi 是否与真实标签 ℓ(x,zi) 一致,策略梯度同时优化判断结果与解释性评述。
在生成阶段,模型以判别阶段的权重初始化,采用原始的可验证强化学习(RLVR)设置进行训练。策略 πfinal 从问题 x 直接生成解题响应 z,输出思维链轨迹与最终答案 a(z)。奖励仍为稀疏的二元信号,基于最终答案的正确性,定义为 r=ℓ(x,z)=I(a(z)=a∗(x))。该阶段利用判别阶段获得的判别知识,生成更简洁、更准确的解题过程,因为模型已学会在生成早期识别并规避错误推理路径。
所用模型架构为 Qwen3-30B-A3B,一种专家混合(MoE)模型。该模型首先在精选的开源思维链(CoT)数据集上微调,得到 Qwen3-30B-A3B-SFT。训练中,作者收集了 11.3 万道带标准答案的数学问题,并在判别阶段采用严格采样策略,每道问题使用 MiMo-7B RL 与目标模型生成 16 条不同的推理路径。训练算法采用 DAPO,一种 GRPO 系列策略梯度方法,结合动态采样以过滤简单问题,批量大小为 256,滚动生成长度 n=8。训练使用 AdamW 优化器,学习率为 3×10−6,10 步预热,训练温度为 1.0;推理时温度设为 0.6。
实验
- 主实验:JudgeRLVR 与原始 RLVR 及基础 SFT 在推理质量与效率上的对比。JudgeRLVR 在多个基准上实现更高或相当的准确率,同时生成长度显著缩短,展现出更优的质量-效率权衡。在 AIME24/25、HMMT_feb_2025 和 BeyondAIME 上,JudgeRLVR 提升准确率并减少推理冗余;在 MATH500 上,保持准确率的同时实现长度大幅缩减。在域外任务(GPQA Diamond、LiveCodeBenchv6、MMLU-Redux)上,JudgeRLVR 提升准确率并减少长度,表明错误感知推理具备良好泛化能力。在 IFEval 与 ZebraLogic 上,准确率提升但长度增加,反映出任务对显式验证的特定需求。
- 消融实验:仅判别训练(Judge Only)在域内数学任务中导致准确率下降、长度增加,表明仅判别无法提升生成质量。混合策略(交替判别/生成训练)稳定性较差,常产生更长输出,表明顺序阶段对清晰策略学习与高效推理至关重要。
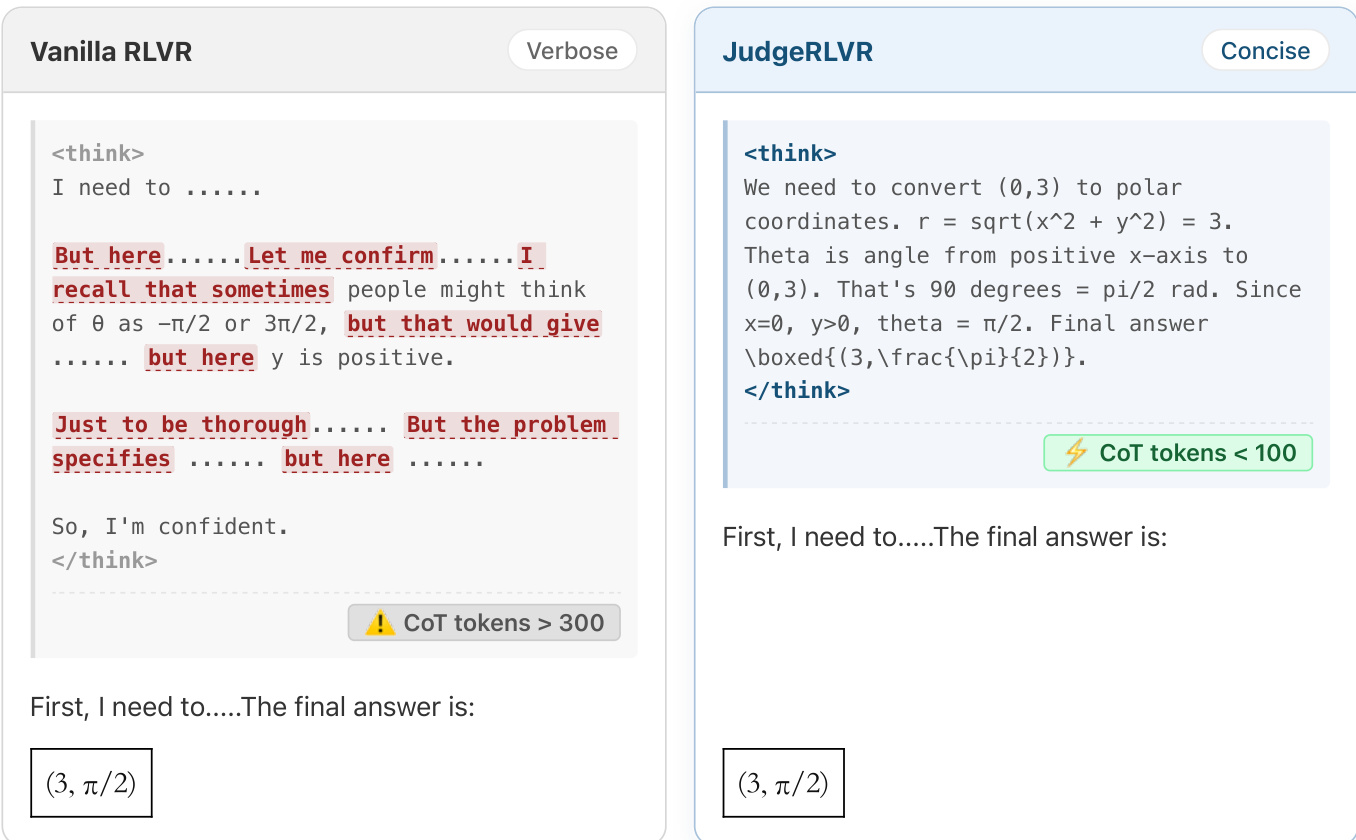
- 机制验证:困惑度(PPL)分析显示,Base SFT 在 JudgeRLVR 输出上的 PPL 显著上升,证实其推理风格向错误敏感型转移。过渡词统计显示,JudgeRLVR 生成阶段中回溯标记(如 but, however, wait)显著减少,表明显式自我修正减少,验证机制已内化。
作者使用表格对比 Base SFT、Vanilla RLVR 与 JudgeRLVR 在多个基准上的表现,结果显示 JudgeRLVR 在多数情况下实现更高或相当的准确率,同时显著降低生成长度。结果表明,JudgeRLVR 通过支持更简洁的推理,改善了质量-效率权衡,尤其在数学领域表现突出,并在多样化任务中持续提升准确率与效率。
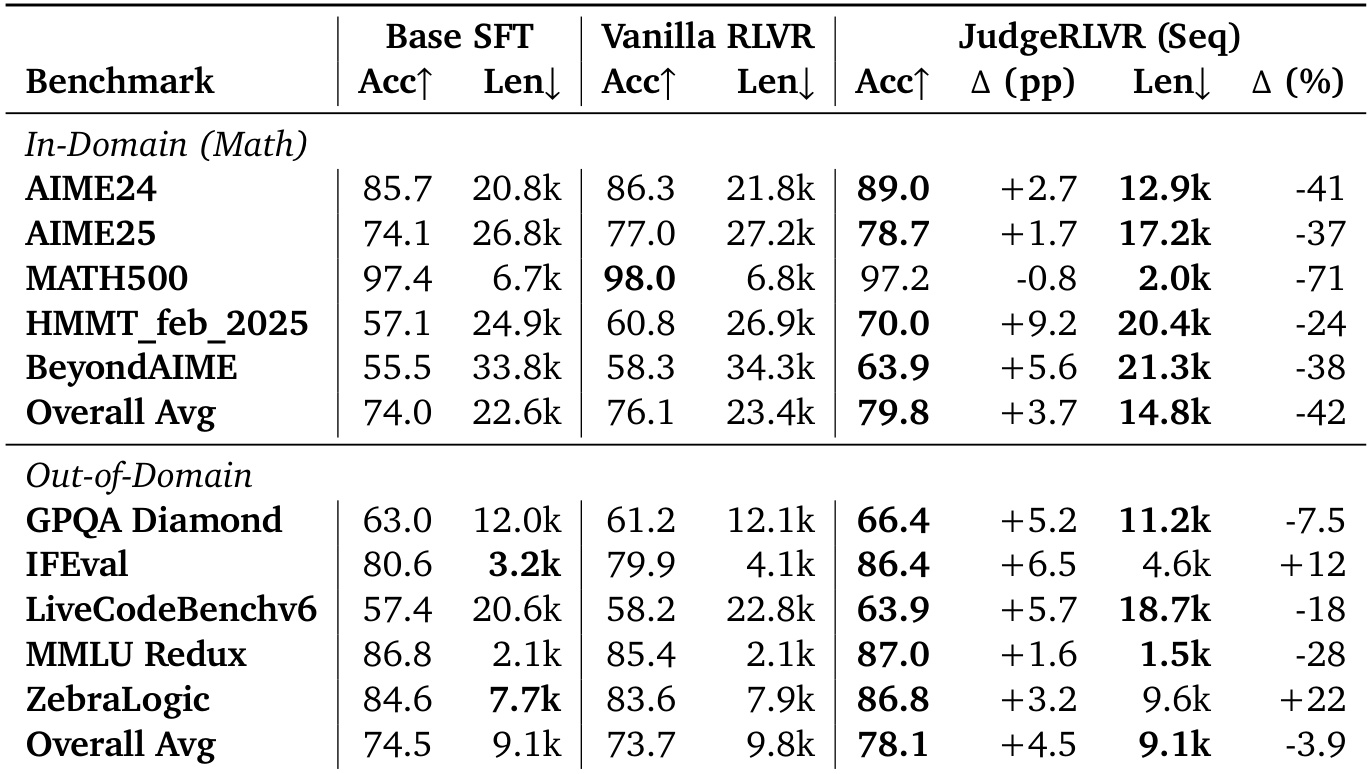
作者采用两阶段“先判别后生成”的 JudgeRLVR 方法,相比 Vanilla RLVR 显著提升了推理任务中的质量-效率权衡。结果表明,JudgeRLVR 在多数基准上实现更高或相当的准确率,同时显著减少生成长度,体现出更高效、更聚焦的推理能力。
作者在 JudgeRLVR 中采用两阶段“先判别后生成”范式,相比 Vanilla RLVR 显著改善了质量-效率权衡,实现更高或相当的准确率,同时在多数基准上显著减少生成长度。结果表明,JudgeRLVR 在域内数学任务中持续优于 Vanilla RLVR,准确率提升显著且输出更短;在域外任务上保持竞争力,展现出更强的推理效率与泛化能力。