Command Palette
Search for a command to run...
RubricHub:通过自动化粗粒度到细粒度生成的全面且高区分度的评分标准数据集
RubricHub:通过自动化粗粒度到细粒度生成的全面且高区分度的评分标准数据集
Sunzhu Li Jiale Zhao Miteto Wei Huimin Ren Yang Zhou Jingwen Yang Shunyu Liu Kaike Zhang Wei Chen
摘要
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)在数学等需要复杂推理的任务领域中取得了显著进展。然而,由于缺乏真实标签(ground truth),在开放生成任务上的优化仍然面临挑战。尽管基于评分量规(rubric-based)的评估提供了一种结构化的验证代理,但现有方法普遍存在可扩展性瓶颈和判别标准粗略的问题,导致监督能力受限,形成“监督天花板”效应。为解决上述问题,我们提出一种自动化的“粗粒度到细粒度评分量规生成”框架(Coarse-to-Fine Rubric Generation)。该框架通过融合原则引导的合成机制、多模型聚合策略以及难度演化机制,生成全面且高度区分性的评分标准,能够精准捕捉生成结果中的细微差异。基于该框架,我们构建了RubricHub——一个大规模(约11万条)、跨领域的评分量规数据集。为验证其有效性,我们设计了一套两阶段后训练流程:首先采用基于评分量规的拒绝采样微调(Rubric-based Rejection Sampling Fine-Tuning, RuFT),随后结合强化学习进行优化(Rubric-based Reinforcement Learning, RuRL)。实验结果表明,RubricHub显著提升了模型性能:经后训练的Qwen3-14B在HealthBench基准上达到69.3分,超越了包括GPT-5在内的多种专有前沿模型,实现了当前最优(SOTA)水平。相关代码与数据集将于近期开源。
一句话总结
来自理想汽车、香港中文大学(深圳)、浙江大学和南洋理工大学的作者提出了 RubricHub,一个通过新颖的粗到细评分框架生成的大规模、多领域数据集,该框架融合了原则引导合成与难度演化机制,实现了对开放式推理任务的细粒度、可扩展评估;该方法在 RuFT 和 RuRL 后训练中达到最先进性能,使 Qwen3-14B 在 HealthBench 上取得 69.3 的 SOTA 结果,超越了 GPT-5 等专有模型。
主要贡献
- 现有的基于评分的开放式生成评估方法存在可扩展性问题和粗粒度标准,导致监督上限,限制了模型性能的提升。
- 作者提出了一种自动化的粗到细评分生成框架,结合原则引导合成、多模型聚合与难度演化,生成细粒度、高区分度的评估标准。
- 由此产生的 RubricHub 数据集(约 110k 条目,覆盖多个领域)支持两阶段后训练流程(RuFT 与 RuRL),使 Qwen3-14B 在 HealthBench 上达到 SOTA 表现(69.3),甚至超越 GPT-5 等专有模型。
引言
作者针对在开放式、不可验证领域中对大语言模型(LLMs)进行对齐的挑战,提出将基于评分的评估作为可扩展的监督代理。尽管基于可验证奖励的强化学习(RLVR)在数学和编程任务中表现优异,但在现实世界中的主观任务中却失效。现有评分方法受限于人工成本、领域覆盖狭窄以及粗粒度、低区分度的标准,无法有效区分高质量响应,造成监督上限。为克服这一问题,作者提出一种自动化的粗到细评分生成框架,融合原则引导合成、多模型聚合与难度演化,生成细粒度、高区分度的评估标准。该框架支持构建 RubricHub,一个大规模(约 110k)、多领域数据集,具备丰富而细腻的评估标准。通过两阶段后训练流程——基于评分的拒绝采样微调(RuFT)与强化学习(RuRL)——该框架使 Qwen3-14B 模型在 HealthBench 上实现 SOTA 性能(69.3),超越 GPT-5 等专有模型。
数据集

- 作者通过整合五个领域中的查询构建了 RubricHub:科学(RaR-science, ResearchQA, MegaScience)、指令遵循(IFTRAIN)、写作(LongWriter, LongWriter-Zero, DeepWriting-20K, LongAlign)、医学(II-medical)和对话(WildChat-1M, LMSys-1M)。
- 在去除长度异常或格式问题的样本后,最终数据集包含约 110k 个问题-评分对。
- 领域分布显示,医学和科学各占数据集的 27.1%,其次为指令遵循(20.9%)和写作(15.9%)。
- 对于写作和医学等复杂领域,评分平均包含超过 30 项细粒度评估标准,支持细致而严格的评估。
- 如图 4 所示,该数据集在不同模型规模下表现出高评分密度和强区分能力,顶级模型如 Qwen3-235B 的平均得分仅为约 0.6,表明仍有巨大提升空间。
- 作者利用 RubricHub 进行模型训练与评估,借助其多样化的领域覆盖和细粒度标准,确保性能评估的稳健性。
- 未明确描述裁剪策略,但通过长度与格式过滤保障了数据质量。
- 元数据通过领域标签和评分结构隐式构建,支持下游分析与模型训练,并提供清晰的评估标准。
方法
作者提出一种粗到细评分生成框架,旨在为模型评估合成高质量、高区分度的评估标准。整体流程如图 2 所示,分为三个阶段:基于响应与原则引导的生成、多模型聚合、难度演化。该框架以约 11 万条跨多领域的开放式查询为初始语料库,作为评分合成的基础。

第一阶段:基于响应与原则引导的生成,旨在通过锚定具体上下文防止评分漂移。该过程将大语言模型(LLM)生成器 M 同时条件于查询 q 和参考响应 oi,确保生成的标准与特定输出相关。此外,还通过一组元原则 Pmeta 进行约束,以保证一致性、结构、清晰度与可评估性。使用特定生成提示 Pgen,合成候选评分 Rcand(i),其显式基于响应并受元原则引导。
第二阶段:多模型聚合,旨在解决单模型生成的固有偏差。为实现全面且客观的标准,框架从多个异构前沿模型中并行合成候选评分,形成统一池 Rcand。随后通过聚合提示 Pagg 将该池提炼为紧凑的基础评分 Rbase,合并冗余项并解决冲突,生成一个能有效缓解单一来源偏差的稳健标准。
第三阶段:难度演化,旨在增强评分的区分能力,以区分高性能响应。该阶段通过识别一对高质量参考响应 Aref,并应用增强提示 Paug 进行分析。该分析提取出使响应从优秀跃升至卓越的区分性细微差别,形成一组附加标准 Radd。最终评分 Rfinal 通过合并基础与演化标准获得,兼具全面覆盖与严格区分能力。
生成的评分被用于两种后训练范式。在基于评分的拒绝采样微调中,为每个查询-评分对生成候选响应池。每个响应根据评分的加权标准进行打分,低于阈值 τ 的响应被拒绝,选择得分最高的响应用于监督微调。在基于评分的强化学习中,评分定义了奖励信号。对于每项标准,统一评分器 G 生成二元评分,可验证标准由规则系统处理,语义标准由 LLM 评估器处理。最终密集奖励 r(q,o) 计算为这些二元评分的加权归一化和,为策略优化提供结构化信号。
实验
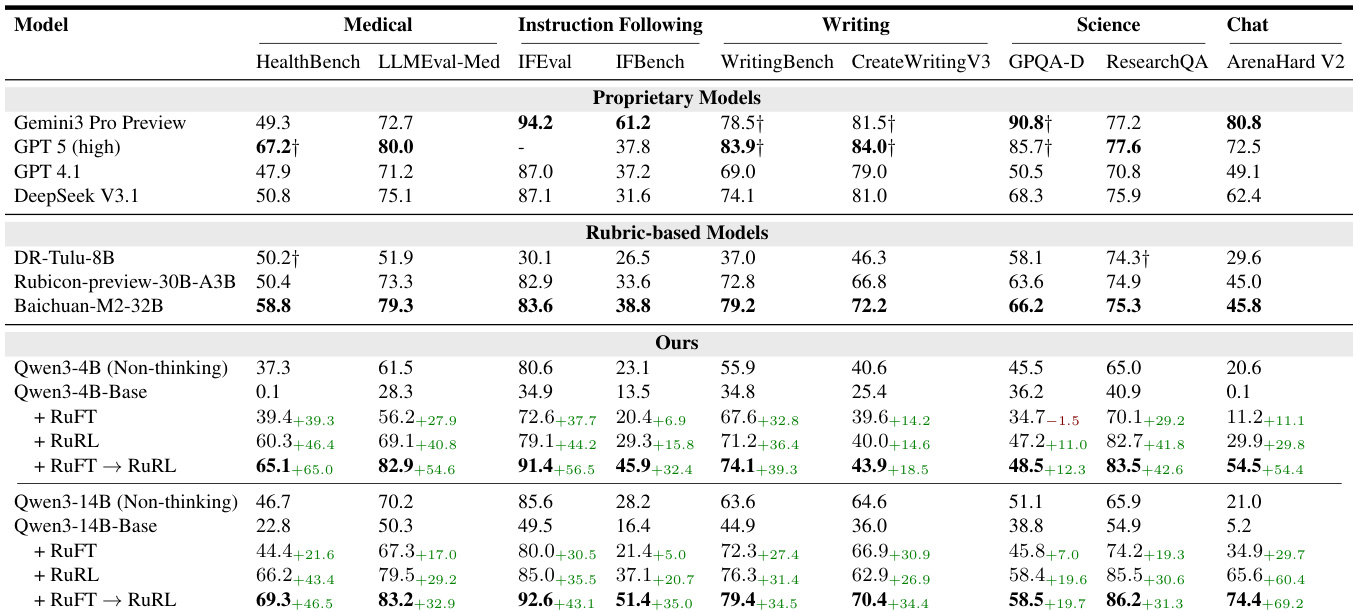
- 主实验在 Qwen3-4B 和 Qwen3-14B 基础模型上验证了两阶段后训练框架(RuFT 后接 RuRL),覆盖五个领域:科学、指令遵循、写作、医学和对话。
- 在 Arena-Hard-V2 上,Qwen3-14B 得分为 74.4,相比基础模型的 5.2 显著提升,表明在对话与多轮交互中取得显著进步。
- 在医学领域,模型在 HealthBench 上取得 SOTA 表现,得分为 69.3,超越 GPT-5(67.2),并在五个领域中的四个超越更大规模基线如 Baichuan-M2-32B。
- RuFT→RuRL 流程始终优于基础模型、仅 RuFT 或仅 RuRL 阶段,尤其在通用对话与医学推理中提升最大。
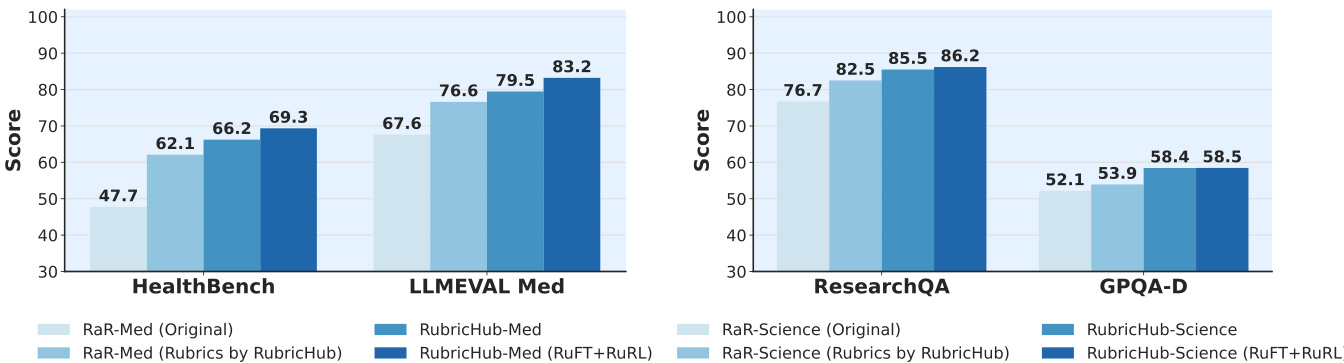
- 基于评分的拒绝采样与粗到细评分生成流程显著提升性能:HealthBench 得分从原始 RaR 的 47.7 提升至 RubricHub 的 62.1,进一步通过完整流程提升至 69.3。
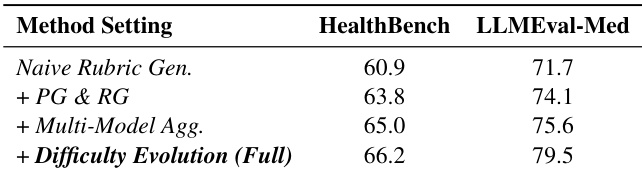
- 消融研究证实了每个组件的附加价值:原则引导与响应锚定约束、多模型聚合、难度演化。
- 增加拒绝采样中的候选样本数,使训练集得分从 63.45 提升至 79.51,HealthBench 性能从 43.61 提升至 48.81。
- 敏感性分析显示,仅含正向标准的评分优于包含负向惩罚的标准,且 gpt-oss-120B 被选为在准确率与速度间平衡最优的评分器。
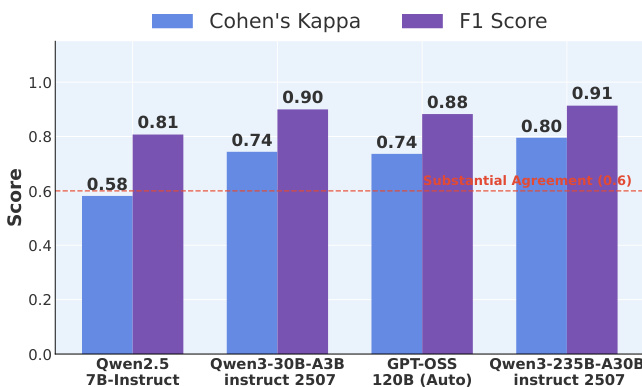
- 人-LLM 一致性分析表明,30B 以上规模的 LLM 达到显著一致性(F1: 0.90, κ: 0.74),性能在 30B 后趋于饱和。
- 训练动态显示各评分维度稳步、均衡提升,表明整体能力增强且无过度优化。
结果表明,随着模型规模增大,人类与 LLM 评估的一致性提升,Qwen3-235B-A30B instruct 2507 模型达到最高评分者间可靠性(Cohen's Kappa: 0.91)与 F1 分数(0.91),超越实质性一致阈值。
作者采用多阶段对齐策略 RuFT 后接 RuRL,以提升模型在医学与科学领域的性能。结果表明,该方法显著优于基线方法,RuFT→RuRL 流程在 LLMEval-Med 上达到 83.2,在 ResearchQA 上达到 86.2,超越原始与评分增强基线。
作者对粗到细评分生成流程进行消融研究,结果表明每增加一个组件均能提升性能。从朴素评分生成开始,引入原则引导与响应锚定约束(+ PG & RG)后,HealthBench 与 LLMEval-Med 得分均提升,进一步加入多模型聚合与难度演化后,LLMEval-Med 得分达到最高 79.5。
作者通过敏感性分析评估评分标准构成对模型性能的影响,比较仅使用正向加权标准与正负向惩罚结合的训练效果。结果表明,仅正向标准的设定在 HealthBench 与 LLMEval-Med 上始终优于正负结合方案,得分更高,表明负向惩罚因评分器在负向标准上准确率较低而阻碍优化。
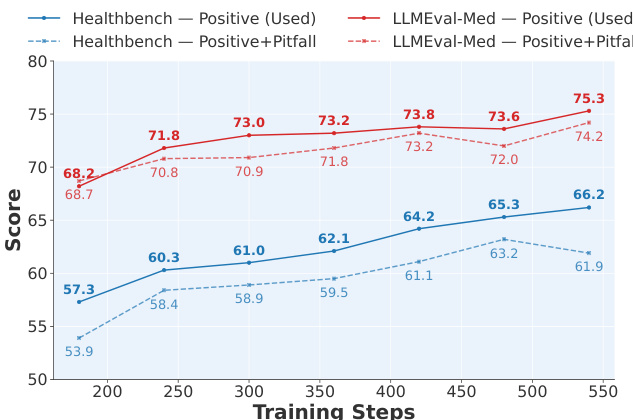
作者采用多阶段后训练方法 RuFT 与 RuRL,对 Qwen3 模型在五个领域进行对齐,结果表明从基础模型到 RuFT 再到 RuRL,性能持续提升。Qwen3-14B 模型在医学领域取得 SOTA 表现,HealthBench 得分为 69.3,超越 GPT-5,并在其他基准测试中表现出强劲竞争力,尤其在对话与指令遵循任务中表现突出。