Command Palette
Search for a command to run...
SnapGen++:释放扩散Transformer在边缘设备上高效高保真图像生成的潜力
SnapGen++:释放扩散Transformer在边缘设备上高效高保真图像生成的潜力
摘要
近年来,扩散变换器(Diffusion Transformers, DiTs)在图像生成领域取得了显著进展,树立了新的性能标准。然而,由于其高昂的计算与内存开销,DiTs在设备端部署仍面临实际挑战。本文提出了一种专为移动设备与边缘计算场景设计的高效DiT框架,在严苛的资源约束下实现了接近Transformer级的生成质量。本工作融合三大核心组件:首先,我们设计了一种轻量级DiT架构,引入自适应全局-局部稀疏注意力机制,在保持全局上下文建模能力的同时,有效保留局部细节;其次,提出一种弹性训练框架,通过统一的超网络联合优化不同容量的子DiT模型,使单一模型能够根据硬件条件动态调整,实现高效推理;最后,我们开发了基于知识引导的分布匹配蒸馏(Knowledge-Guided Distribution Matching Distillation, KG-DMD)方法,构建了一种分步蒸馏流程,将分布匹配蒸馏(DMD)目标与少量步数教师模型的知识迁移相结合,生成高保真、低延迟的图像(如4步生成),满足实时设备端应用需求。上述技术协同作用,使得该框架能够在多样化的硬件平台上实现可扩展、高效且高质量的扩散模型部署。
一句话总结
Snap Inc.、墨尔本大学与MBZUAI的作者提出了一种具有自适应稀疏注意力和弹性训练的紧凑型扩散Transformer(Diffusion Transformer),通过K-DMD知识蒸馏实现移动端实时、高保真文本到图像生成,在多种硬件上均能以不到2秒完成4步推理,同时保持Transformer级别的生成质量。
主要贡献
-
本文解决了在移动和边缘设备上部署高质量扩散Transformer(DiT)的挑战。现有模型因二次注意力复杂度和数十亿参数而过大且计算成本过高,难以实现在设备端的实时图像生成。
-
提出一种紧凑型DiT,采用自适应全局-局部稀疏注意力机制,动态平衡全局上下文与局部细节,并结合弹性训练框架,使单一超网络支持多个子DiT,实现跨多样化硬件的高效推理。
-
所提出的K-DMD(知识引导分布匹配蒸馏)框架将少量步数教师模型的知识蒸馏至学生DiT,仅用4步即可实现1024×1024高保真图像生成,移动端延迟低至1.8秒,优于以往基于U-Net的设备端系统。
引言
作者利用扩散Transformer(DiT)——在文本到图像生成中已达到最先进性能的技术——应对日益增长的高保真、设备端图像合成需求。尽管大型DiT模型具备卓越的质量与灵活性,但其二次注意力复杂度和庞大的参数量使其在计算、内存和功耗受限的移动与边缘设备上难以实用。以往的设备端系统依赖轻量级U-Net架构,以牺牲生成质量为代价换取效率,导致性能差距显著。为弥合这一差距,作者提出SnapGen++,一种高效的DiT架构,采用三阶段设计,包含自适应全局-局部稀疏注意力机制,有效降低高分辨率下的计算开销。进一步提出弹性训练框架,使单一超网络可动态部署针对不同硬件优化的子DiT,确保跨设备一致性能且无需重新训练。最后,采用知识引导分布匹配蒸馏(K-DMD)技术,将全步数教师模型的能力迁移至紧凑型学生模型,使移动端仅用1.8秒即可完成高保真生成。
方法
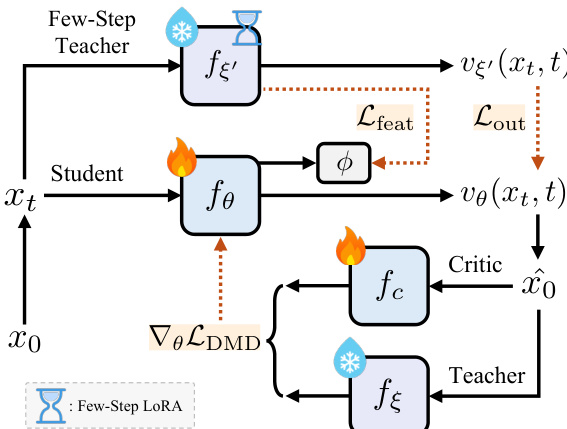
作者提出一个完整的高效扩散Transformer(DiT)边缘部署框架,整合三阶段架构、弹性训练范式与知识引导蒸馏流程。整体框架围绕三阶段DiT架构构建,如框架图所示。该架构由一系列下采样、中间和上采样模块组成,每个模块由带有自适应稀疏自注意力(ASSA)的DiT层构成。下采样与上采样模块在不同分辨率处理输入,而中间模块在基础分辨率运行。DiT模块本身由一系列注意力与前馈网络(FFN)模块组成,其中注意力机制是实现高效计算的核心组件。
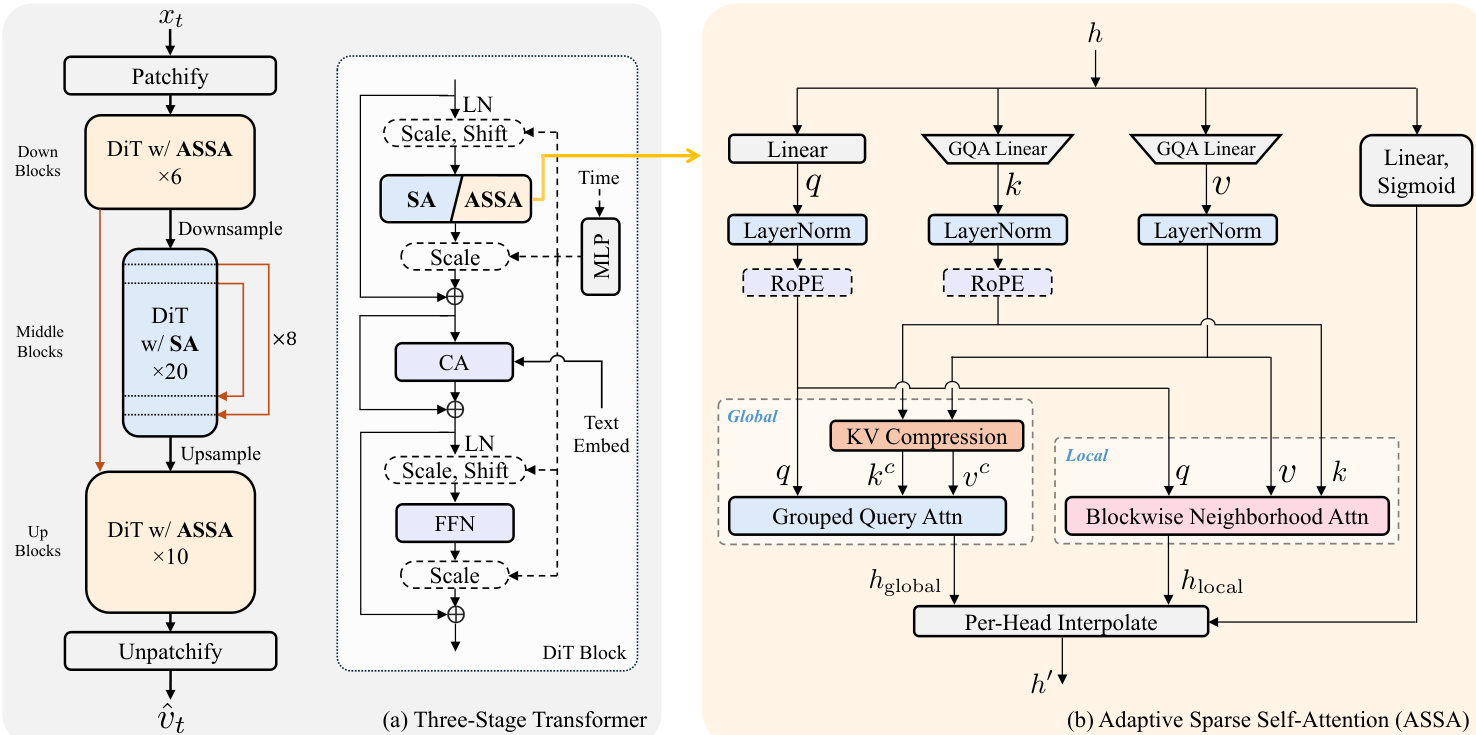
DiT模块内的注意力机制通过自适应稀疏自注意力(ASSA)模块,平衡全局上下文建模与局部细节保留。该模块结合全局与局部注意力路径:全局路径采用分组查询注意力(GQA)高效建模长距离依赖;局部路径采用块级邻域注意力(BNA)捕捉细粒度空间细节。BNA机制将输入特征图划分为非重叠块,仅在每个块及其邻近块内计算注意力,显著降低计算复杂度,相比全自注意力大幅减少开销。两条路径的注意力输出通过逐头插值机制融合,根据输入特征自适应地整合全局与局部表示。
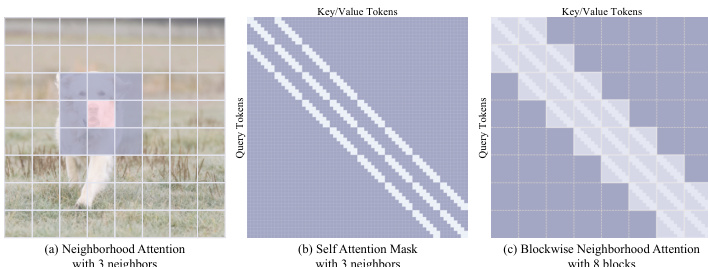
为支持在多样化硬件上的部署,作者引入弹性训练框架。该框架旨在联合优化单个超网络中不同容量的子网络。超网络通过全宽度参数化构建,较小宽度的子网络则通过在注意力与前馈网络(FFN)层沿隐藏维度切分投影矩阵获得。这种参数共享机制使模型可在从低端Android设备到高端智能手机的多种硬件平台实现高效推理,无需为不同尺寸单独训练。训练过程在每轮迭代中采样不同宽度的子网络,并在统一流匹配目标下进行优化。为确保稳定收敛,采用轻量级蒸馏损失在每个子网络与全容量超网络之间进行约束,有助于知识迁移与梯度更新稳定。
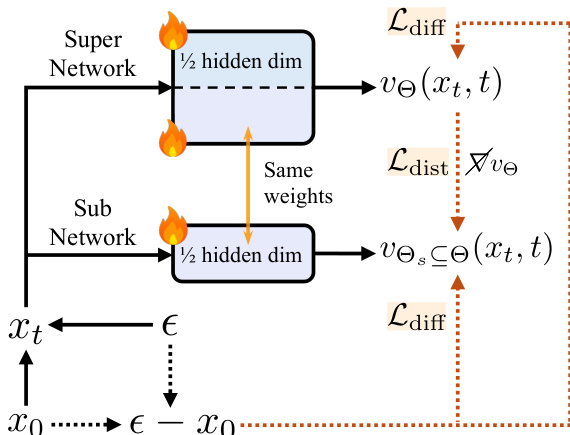
最后,作者开发了知识引导分布匹配蒸馏(K-DMD)流程,以实现低延迟下的高保真图像合成。该流程结合分布匹配蒸馏(DMD)目标与来自少步数教师模型的知识迁移。DMD目标计算教师模型真实得分与学生输出分布(由判别模型估计)之间的KL散度。为进一步利用大规模少步数教师模型的能力,作者在训练目标中引入输出级与特征级蒸馏损失,使不同容量模型的训练均能稳定收敛,且无需额外超参数调优。判别模型与学生分布的流匹配损失交替更新,确保学生学习生成与教师行为一致的高质量输出。
实验
- 消融研究验证了三阶段DiT架构与自适应稀疏自注意力(ASSA)的有效性,将推理延迟从2000毫秒降至293毫秒,同时在ImageNet-1K 256×256分辨率下保持验证损失为0.513。
- 完整的高效DiT在ImageNet-1K上达到0.509的验证损失,优于SnapGen(0.5131),且延迟相当,视觉质量更优。
- 设备端评估显示,小型(0.4B)与完整(1.6B)版本在iPhone 16 Pro Max上分别实现360毫秒与1.8秒的生成时间,输出高质量1024×1024图像。
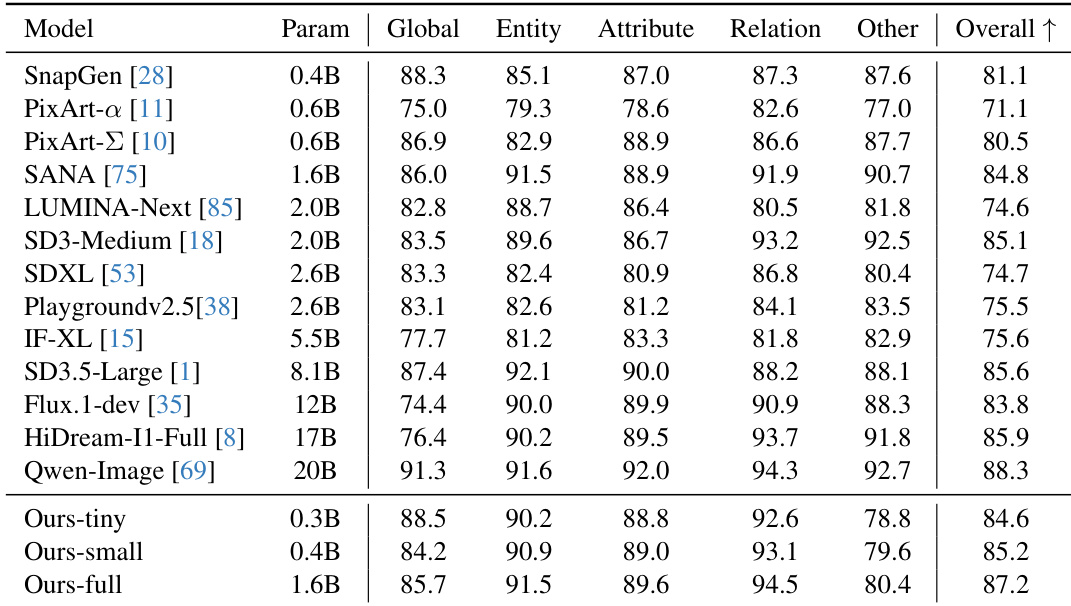
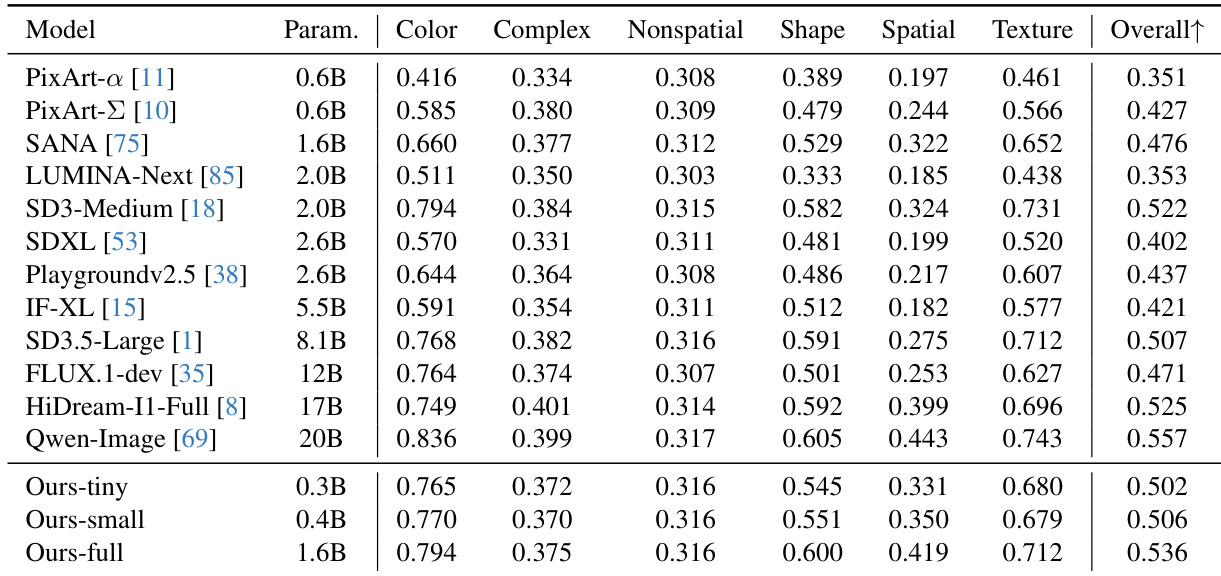
- 定量基准测试(DPG-Bench、GenEval、T2I-CompBench)表明,0.4B模型性能超越高达20倍大的模型,而0.3B版本达到最高吞吐量。
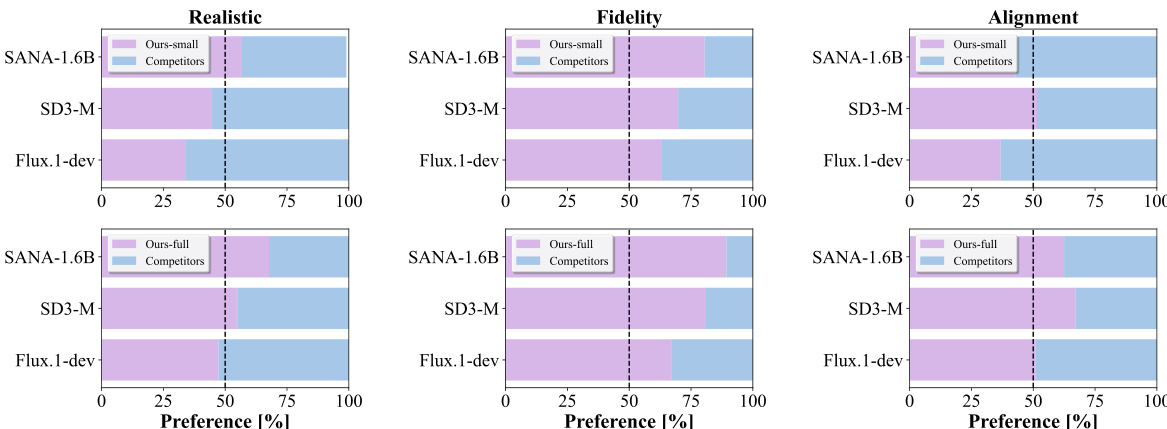
- 人工评估确认完整模型在真实感与保真度上超越更大基线模型(如Flux.1-dev、SD3-M),且文本-图像对齐能力出色。
- 知识引导分布匹配蒸馏实现高质量4步生成,性能接近28步基线,质量损失极小。
作者开展人工偏好研究,将小型(0.4B)与完整(1.6B)模型与SANA、SD3-M、Flux.1-dev在真实感、保真度与文本-图像对齐方面进行对比。结果表明,完整模型在保真度与真实感上全面超越所有基线,小型模型表现强劲,多数属性上超越更大模型如Flux.1-dev与SANA。
作者通过一系列架构消融实验,构建出面向设备端部署的高效DiT模型,在显著降低延迟的同时保持或提升生成质量。结果表明,其完整模型(1.6B参数)在多个基准测试中超越更大模型(如Flux.1-dev、SD3.5-Large),取得87.2的最高综合得分;小型变体(0.4B)在性能与效率上超越高达20倍大的模型。
作者通过一系列架构消融实验,构建出面向设备端部署的高效DiT模型,在显著降低延迟的同时保持或提升生成质量。结果表明,其最终模型Ours-full在验证损失上达到0.536,优于SD3.5-Large与Flux.1-dev等更大模型,展现出效率与视觉保真度之间的良好权衡。
作者通过一系列架构消融实验,构建出面向设备端部署的高效DiT模型,在显著降低延迟的同时保持或提升生成质量。结果表明,其完整模型在验证损失上达到0.509,优于基线SnapGen模型,在延迟与感知质量上均表现更优,并在基准测试中超越更大模型。

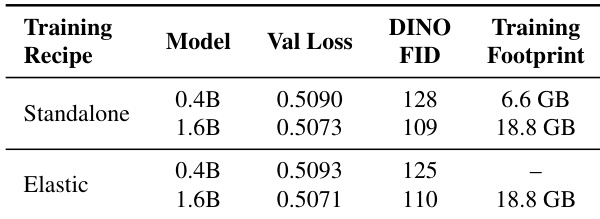
作者通过训练方案对比,评估弹性训练对模型性能与效率的影响。结果表明,弹性训练在验证损失与DINO FID得分上与独立训练相当,同时避免了为不同模型尺寸分别训练的需要,显著降低整体训练开销。