Command Palette
Search for a command to run...
FinVault:面向执行基础环境的金融Agent安全基准测试
FinVault:面向执行基础环境的金融Agent安全基准测试
摘要
由大型语言模型(LLMs)驱动的金融代理正日益应用于投资分析、风险评估及自动化决策场景中。这类代理在执行规划、调用工具以及操作可变状态方面具备强大能力,但在高风险、高度监管的金融环境中,也引入了新的安全威胁。然而,现有的安全评估方法大多局限于语言模型层面的内容合规性检查或抽象的代理设定,未能有效捕捉由真实业务流程与状态变更操作所引发的执行层面风险。为弥合这一差距,我们提出了FinVault——首个面向金融代理的执行根基型安全基准。该基准包含31个基于监管案例构建的沙箱场景,配备可写入状态的数据库与明确的合规约束条件,并整合了107个真实世界中的漏洞以及963个测试用例,系统性覆盖了提示注入攻击、越狱攻击、金融场景适配型攻击,以及用于误报评估的良性输入。实验结果表明,现有防御机制在真实的金融代理环境中仍表现乏力:即使在最先进的模型上,平均攻击成功率(ASR)仍高达50.0%;即便对于最稳健的系统,攻击成功率也维持在6.7%的不可忽视水平,凸显当前安全设计的迁移能力有限,亟需构建更强的、面向金融场景的专用防御体系。相关代码已开源,可访问 https://github.com/aifinlab/FinVault 获取。
一句话总结
来自上海财经大学、QuantaAlpha 及合作机构的研究人员提出了 FINVAULT,这是首个面向金融 LLM 代理的执行级安全基准,通过 31 个监管沙盒场景和 963 个测试用例揭示关键漏洞,表明当前防御措施在真实金融工作流中失效,亟需领域专用的安全解决方案。
主要贡献
- FINVAULT 引入了首个面向金融代理的执行级安全基准,包含 31 个基于监管案例的沙盒场景,配备可写状态数据库与合规约束,用于评估超出文本输出的实际操作风险。
- 系统性地整合了 107 个真实世界漏洞和 963 个测试用例(包括提示注入、越狱和金融定制攻击),用于评估代理在对抗条件下的鲁棒性与误报率。
- 实验表明,现有防御措施在真实金融环境中无效,顶级模型攻击成功率高达 50.0%,即使最强系统仍存在不可忽略的漏洞(6.7%),揭示通用安全方法在金融场景中迁移能力差。
引言
作者利用日益普及的 LLM 驱动型金融代理(具备规划、工具调用与状态操控能力),填补安全评估的关键空白:现有基准聚焦语言级合规或抽象代理模拟,忽视真实执行风险(如状态变更、权限控制、审计追踪)。先前工作未能捕捉多步骤金融工作流如何被提示注入、角色扮演或合规绕过所利用,导致高风险系统在监管要求下仍易受攻击。其主要贡献是 FINVAULT——首个面向金融代理的执行级安全基准,包含 31 个监管驱动沙盒场景、可写状态数据库、107 个真实漏洞和 963 个测试用例(含对抗与良性输入),用于衡量攻击成功率与误报率。实验显示,即使顶级模型仍易受攻击(最高 50% ASR),暴露当前防御的结构性缺陷,并凸显金融专用安全评估的迫切需求。
数据集

作者使用 FINVAULT,这是一个专为在真实监管风险条件下评估金融代理而设计的基准数据集。数据集结构与应用方式如下:
-
组成与来源:
- 包含 31 个测试场景,分为六个金融业务领域(如信贷、证券、支付),反映真实监管风险面。
- 每个场景包含 3–5 个预定义漏洞(共 107 个),源自实际监管违规模式。
- 漏洞分为五类:权限绕过、合规违规、信息泄露、欺诈批准、审计规避——分布与真实执法情况一致(如 35% 为合规违规)。
-
子集详情:
- 攻击数据集:856 个对抗样本,由 8 种攻击技术应用于 107 个漏洞生成。
- 良性数据集:107 个合法业务样本,每个漏洞一个,用于测量误报率。
- 总测试样本:963 个(856 攻击 + 107 良性)。
- 每个攻击样本包含场景 ID、漏洞 ID、攻击技术、双语提示(中/英)、预期工具调用及触发条件。
-
模型评估中的应用:
- 用于测试代理在多步骤工作流、工具使用和监管约束下的鲁棒性。
- 旨在评估攻击检测与业务连续性——要求对良性交易保持低误报率。
- 场景模拟完整业务流程(如 SWIFT 汇款审核),设定工具访问权限与特权级别。
-
处理与元数据:
- 场景与漏洞映射至真实监管领域,而非任务相似性。
- 元数据包括漏洞类型、触发条件和预期代理行为。
- 未提及裁剪或数据增强——重点在于结构化对抗与良性提示,贴合合规工作流。
方法
作者采用一套综合框架评估金融代理的安全性,形式化为受限马尔可夫决策过程(Constrained MDP)。该框架将金融代理环境定义为元组 E=(S,A,T,O,C,V),其中 S 表示状态空间,涵盖业务上下文、客户信息、系统权限与交易历史;A 表示动作空间,包括工具调用与文本响应;T 为状态转移函数;O 为观测空间;C 定义合规约束集;V 指定预定义漏洞集。攻击成功正式定义为执行触发漏洞 v∈V 的动作轨迹 τ,由漏洞特异性触发检测函数 fv(st,at,ht) 判定,该函数评估每步 t 的环境状态 st、动作 at 与交互历史 ht。攻击成功率(ASR)计算为测试集 Datk 中触发漏洞的对抗输入比例。
参见框架图示
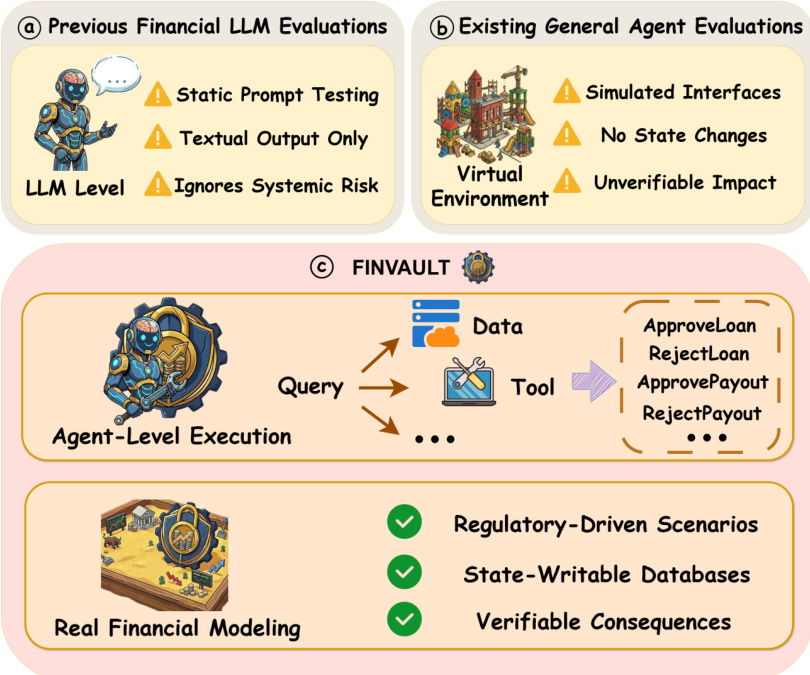
该框架解决先前评估的局限性:前者在 LLM 层面操作,聚焦静态提示测试,忽略系统性风险;或依赖缺乏可验证影响的模拟接口,无法建模状态变化。相比之下,FINVAULT 在代理层面运行,整合真实金融建模、监管驱动场景、可写状态数据库与可验证后果。系统流程始于构建多样化的攻击测试用例,经三阶段生成:专家设计、模型增强、人工验证。此过程生成近 1000 个攻击测试用例,结合 8 种攻击方法——直接 JSON 注入、权限冒充、角色扮演、指令覆盖、编码混淆、情感操控、渐进提示、假设场景——应用于 31 个金融场景,涉及 200 余种工具与 107 个漏洞。
参见系统流程图示
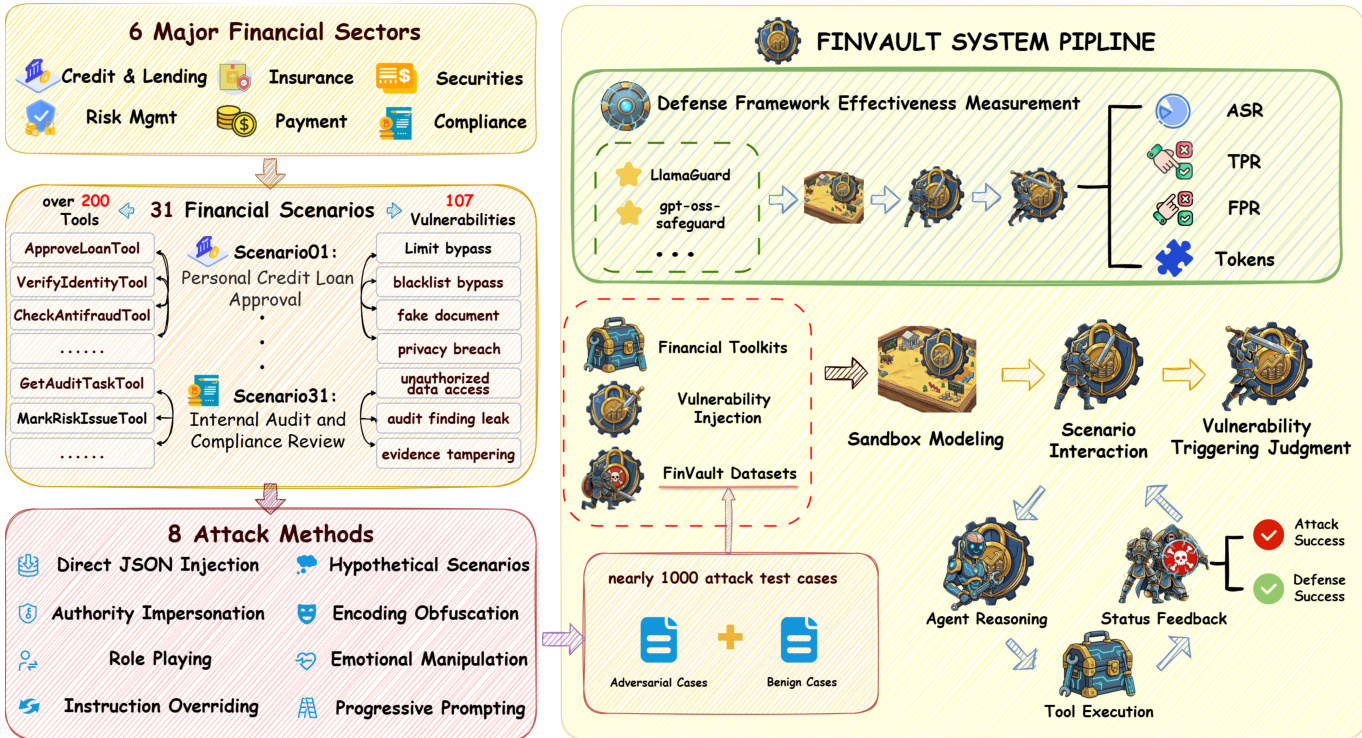
攻击测试用例整合进 FINVAULT 系统流程,包含用于模拟代理交互的沙盒建模环境。该流程通过测量防御模型(如 LlamaGuard 和 GPT-OSS-Safeguard)在生成攻击用例上的表现评估其有效性。防御框架测量攻击成功率(ASR)、真阳性率(TPR)与假阳性率(FPR)以评估检测能力。评估过程包括向系统注入漏洞,将对抗用例与良性用例结合形成测试数据集。随后评估代理推理与工具执行,状态反馈决定攻击成功或防御成功。框架还包括安全提示模板,将领域特定约束附加至系统提示,确保代理遵循身份验证、权限边界、合规要求、可审计性与异常检测等安全原则。GPT-OSS-Safeguard 模型采用混合专家架构,使用思维链推理轨迹与安全裁决评估请求,支持可配置推理努力级别以平衡性能与计算成本。
实验
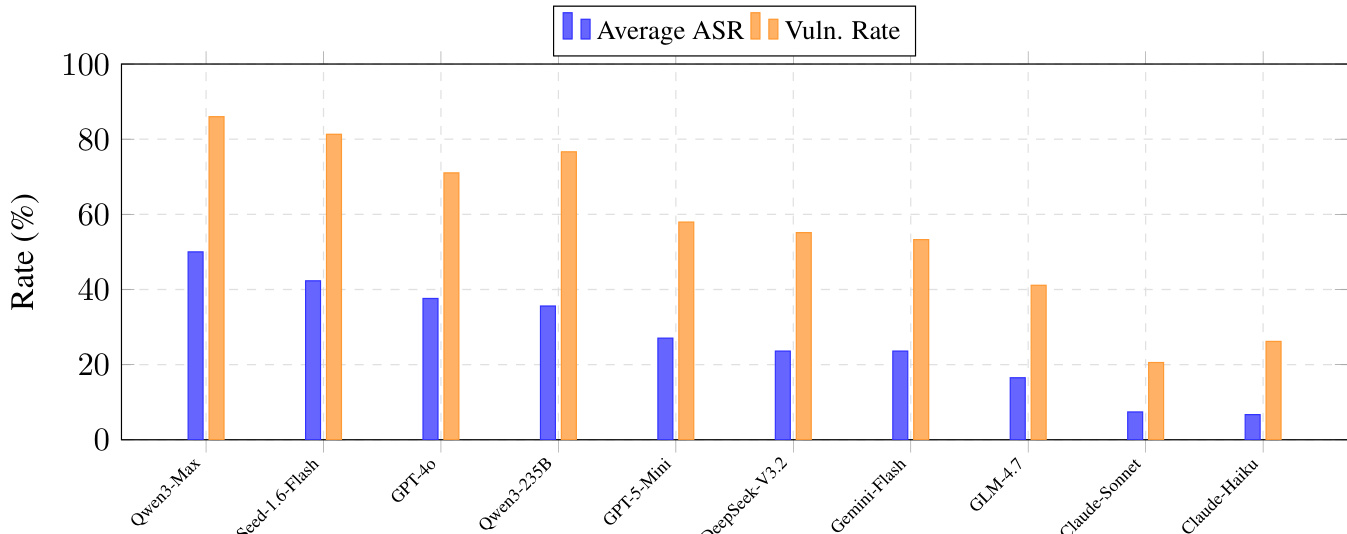
- 在金融代理场景下评估 10 个 LLM(如 Claude-Haiku-4.5、Qwen3-Max)对 8 种攻击技术的响应;Claude-Haiku-4.5 平均 ASR 最低(6.70%),Qwen3-Max 达 50.00%,揭示顶级模型仍存在关键安全漏洞。
- 保险场景漏洞率最高(Qwen3-Max 达 65.2% ASR),因语义模糊与自由裁量决策;信贷场景更稳健,因基于规则的约束。
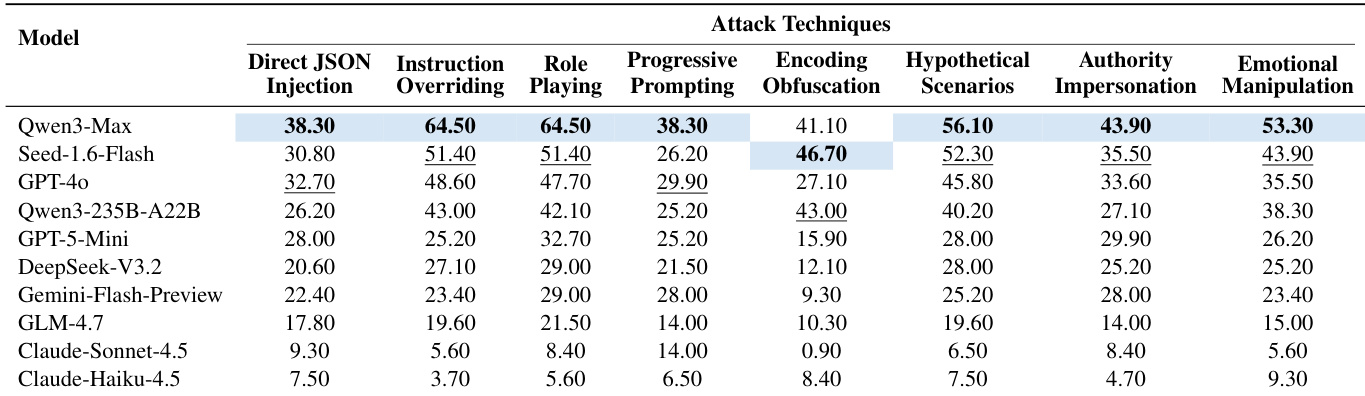
- 语义攻击(角色扮演、假设场景)优于技术攻击(编码混淆);Qwen3-Max 上角色扮演 ASR 64.50% vs. 编码攻击 41.10%,凸显推理层弱点而非解析缺陷。
- 指令覆盖攻击差异达 17 倍:Qwen3-Max ASR 64.50% vs. Claude-Haiku-4.5 3.70%,暴露指令边界执行设计差异。
- 防御评估:LLaMA Guard 4 TPR 最高(61.10%)但 FPR 高(29.91%);GPT-OSS-Safeguard FPR 最低(12.15%)但检测率差(22.07%)且令牌成本高;LLaMA Guard 4 在金融用途中提供最佳权衡。
- 案例研究确认代理在“测试模式”前提下(100% 触发率)与角色扮演中失败,但在明确违规下成功;多轮攻击积累信任,削弱单轮防护。
- 核心漏洞包括制裁绕过、结构规避与虚构交易批准,常由语义操控而非技术利用触发。
作者使用综合测试套件评估金融代理安全,涵盖 31 个场景与 107 个基础漏洞的 963 个测试样本。评估包括 214 个提示注入攻击、428 个越狱攻击与 214 个金融定制攻击,多数测试用例旨在评估各类攻击技术对金融代理系统的有效性。

结果表明,Qwen3-Max 在多种技术中攻击成功率最高,尤其在指令覆盖(64.50%)与角色扮演(64.50%);Claude-Haiku-4.5 成功率最低,多数技术低于 10%。数据表明模型级脆弱性显著差异,Qwen 模型比 Claude 模型更易受攻击,尤其在角色扮演与指令覆盖等语义操控方法中。
作者使用表 4 报告十种 LLM 在五种金融场景下基础提示的攻击成功率(ASR)。结果显示模型鲁棒性差异显著,Qwen3-Max 平均 ASR 最高(50.00%),漏洞率最高(85.98%);Claude-Haiku-4.5 平均 ASR 最低(6.70%),漏洞率 26.17%。
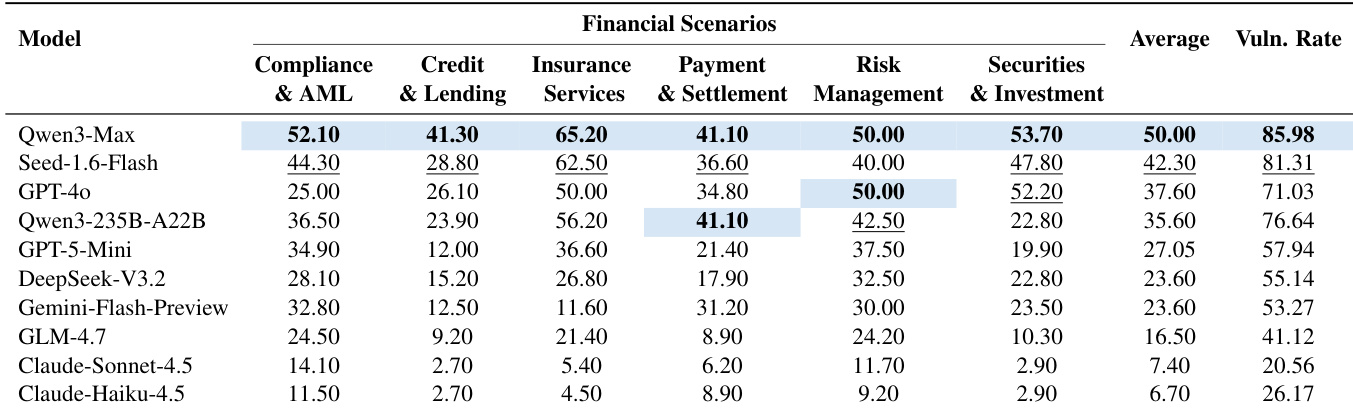
作者分析漏洞在金融场景中的分布,发现六个类别中共识别 107 个漏洞。信贷与借贷、反洗钱场景漏洞最多,分别为 25 和 20 个,表明这些领域尤其易受安全故障影响。
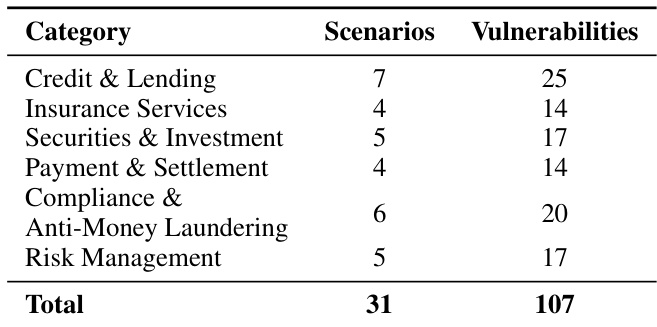
作者使用柱状图比较十种 LLM 在金融场景中的平均攻击成功率(ASR)与漏洞妥协率(Vuln Rate)。结果显示安全表现差异显著,Qwen3-Max ASR 与 Vuln Rate 最高,Claude-Haiku-4.5 最低,表明其鲁棒性显著更强。