Command Palette
Search for a command to run...
MHLA:通过Token级多头机制恢复线性注意力的表达能力
MHLA:通过Token级多头机制恢复线性注意力的表达能力
Kewei Zhang Ye Huang Yufan Deng Jincheng Yu Junsong Chen Huan Ling Enze Xie Daquan Zhou
摘要
尽管Transformer架构在多个领域占据主导地位,但其自注意力机制所固有的二次方复杂度限制了其在大规模应用中的使用。线性注意力(Linear attention)提供了一种高效的替代方案,但其直接应用通常会导致性能下降;而现有的改进方法往往通过引入额外模块(如深度可分离卷积)来修复问题,反而重新引入了计算开销,违背了降低复杂度的初衷。在本研究中,我们识别出此类方法的关键失效模式:全局上下文坍缩(global context collapse),即模型在表示能力上丧失了多样性。为解决该问题,我们提出多头线性注意力(Multi-Head Linear Attention, MHLA),通过在分头结构中沿token维度进行注意力计算,有效保持了表示的多样性。我们理论证明,MHLA在保持线性时间复杂度的同时,能够恢复softmax注意力的大部分表达能力。在多个任务领域中,我们验证了MHLA的有效性:在ImageNet图像分类任务上提升3.6%,在自然语言处理任务中提升6.3%,在图像生成任务中提升12.6%,在视频生成任务中更是实现41%的性能增益,所有结果均在与原有方法相同的时间复杂度下达成。
一句话总结
北京大学与英伟达的作者提出多头线性注意力(MHLA),一种线性复杂度的注意力机制,通过逐标记的头划分保持表征多样性,防止全局上下文坍缩,在图像分类、自然语言处理、图像生成和视频生成任务中均优于Softmax注意力,同时保持高效性。
主要贡献
-
线性注意力机制为Transformer中的二次自注意力提供了可扩展的替代方案,但常因全局上下文坍缩而性能下降:模型将所有标记压缩为单一共享的键值摘要,导致表征多样性丧失,限制了查询特定上下文的检索能力。
-
所提出的多头线性注意力(MHLA)通过沿标记维度将标记划分为非重叠头,利用局部键值摘要和查询条件混合机制,实现查询依赖的上下文选择,同时在不引入额外模块的情况下保持 O(N) 复杂度。
-
MHLA 在多个领域均达到最先进水平:ImageNet 上提升 3.6% 准确率,自然语言处理提升 6.3%,图像生成提升 12.6%,视频生成提升 41%,所有结果均在与基线线性注意力相同的时间复杂度下实现。
引言
Transformer 架构在视觉、语言和生成建模领域的主导地位受限于其二次自注意力复杂度,这阻碍了其在长序列和高分辨率任务中的可扩展性。线性注意力提供了一种具有线性复杂度的有前景替代方案,但先前方法常因一个根本性问题而性能下降:全局上下文坍缩,即所有标记被压缩为单一共享的键值摘要,降低了表征多样性,并限制了注意力矩阵的秩。这导致注意力分布趋于均匀,且查询特定上下文选择能力变差,尤其在序列长度增长时更为明显。现有解决方案依赖于深度可分离卷积或门控机制等辅助模块,重新引入计算开销,且未能完全恢复表达能力。
作者提出多头线性注意力(MHLA),一种新公式,通过沿标记维度将标记划分为非重叠头,计算局部键值摘要,并在这些摘要上实现查询条件混合,从而恢复查询依赖的多样性。该设计在保持线性 O(N) 复杂度的同时,显著提高了注意力矩阵的秩,有效恢复了Softmax注意力的大部分表达能力。MHLA 仅需标准 GEMM 操作,确保与流式和状态化执行的兼容性。实验表明,MHLA 在各领域均取得一致提升:ImageNet 准确率提高 3.6%,自然语言处理提升 6.3%,图像生成提升 12.6%,视频生成提升 41%,且无额外计算成本。
方法
作者采用一种多头线性注意力机制,称为多头线性注意力(MHLA),以解决标准线性注意力的表征局限性,同时保持线性时间复杂度。该框架首先将输入标记序列划分为 M 个非重叠块,并行处理。对于每个块 b,计算局部键值摘要 Sb=∑j∈bKjVj⊤ 和归一化因子 zb=∑j∈bKj,其中 Q=ϕ(Q) 和 K=ϕ(K) 表示特征映射后的查询和键。这种分块计算方式支持高效并行处理序列。
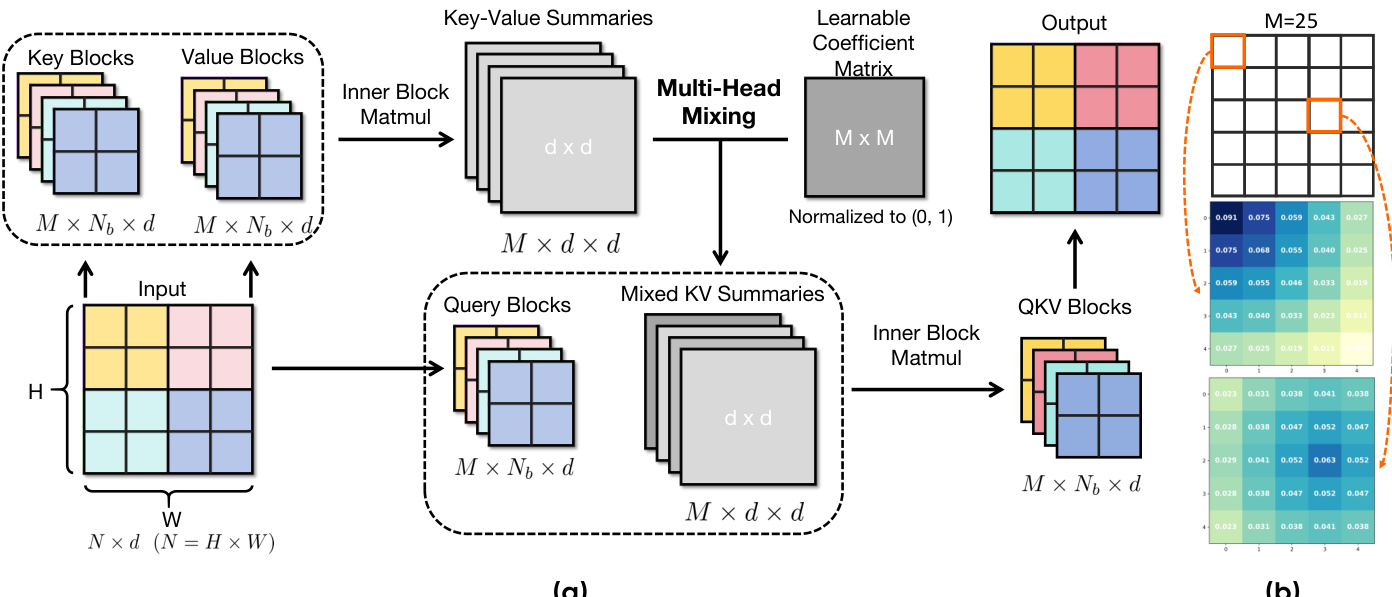
为恢复查询条件选择性,MHLA 引入一个可学习的系数矩阵 Mc∈RM×M,用于控制“多头混合”过程。该矩阵的每一行 mi 表示查询块 i 的可学习、非负混合系数,决定其如何将 M 个局部键值摘要组合成一个查询特定的混合摘要 Si=∑b=1Mmi,bSb。该机制使每个查询块能够自适应地重新加权其他所有块的贡献,有效构建查询依赖的全局上下文。对于来自块 i 的查询向量 q,输出计算为 o=q⊤ziq⊤Si,其中 zi=∑b=1Mmi,bzb 为对应的混合归一化因子。

系数矩阵 Mc 的初始化设计倾向于局部性,初始系数 mi,j(0)∝1−dist(i,j)/maxk(dist(i,k)),促进稳定且快速收敛。该局部性偏置初始化在图中可视化,系数被重塑为二维网格以展示块之间的空间关系。最终输出通过查询块与混合键值摘要之间的块内矩阵乘法生成,得到大小为 M×Nb×d 的最终输出张量。这一两阶段过程——通过混合系数进行块级选择,再通过核内积进行块内重加权——重新引入了查询条件选择性和逐标记加权,这些在全局线性注意力中已丢失。MHLA 的整体复杂度仍为序列长度 N 的线性,因为主要操作为分块摘要计算和 M 个 d×d 矩阵的线性组合。
实验
- 主实验验证 MHLA 通过在保持线性时间复杂度的同时保留查询条件的标记级多样性,缓解了线性注意力中的全局上下文坍缩问题。
- 在 ImageNet-1K 上,MHLA 在 DeiT 和 VLT 模型中均实现图像分类的最先进准确率,超越基线且参数开销极小。
- 在图像生成任务中,MHLA 在 DiT 和 DiG 模型上达到或超过自注意力性能,在 512 分辨率下推理速度比 FlashAttention 快达 2.1 倍,同时提升 FID 分数。
- 在包含 31,500 个标记的视频生成任务中,MHLA 超越原始线性注意力,性能与 FlashAttention 相当,且实现 2.1 倍加速,展现出在超长上下文中的鲁棒性。
- 在自然语言处理中,MHLA 在常识推理和 MMLU 上实现有竞争力的困惑度和零样本准确率,在 LongBench 长上下文任务中领先,尤其在 Mult-Doc QA 和摘要任务中表现突出。
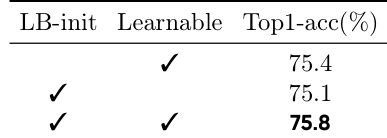
- 消融研究证实,MHLA 的局部性偏置初始化和可学习混合系数均能提升性能,且当 M ≤ √N 时可实现最优效率与可扩展性。
作者在 DeiT-T 上比较了不同变体,评估其初始化策略和可学习参数对多头混合的影响。结果表明,仅使用局部性偏置初始化即可获得强性能,加入可学习系数后进一步提升准确率,两者结合时达到最佳效果。
作者在 DiT-XL/2 上将 MHLA 与自注意力进行对比,用于类别到图像生成。结果显示,MHLA 在保持竞争力的 IS 和精度的同时,FID 和 sFID 分数更低。在无分类器引导下,MHLA 仍与自注意力表现相当,证明其在高分辨率图像生成中的有效性。

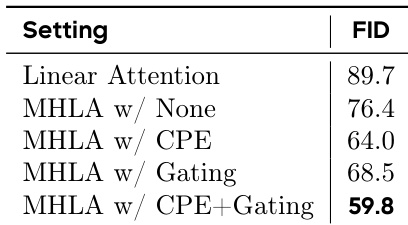
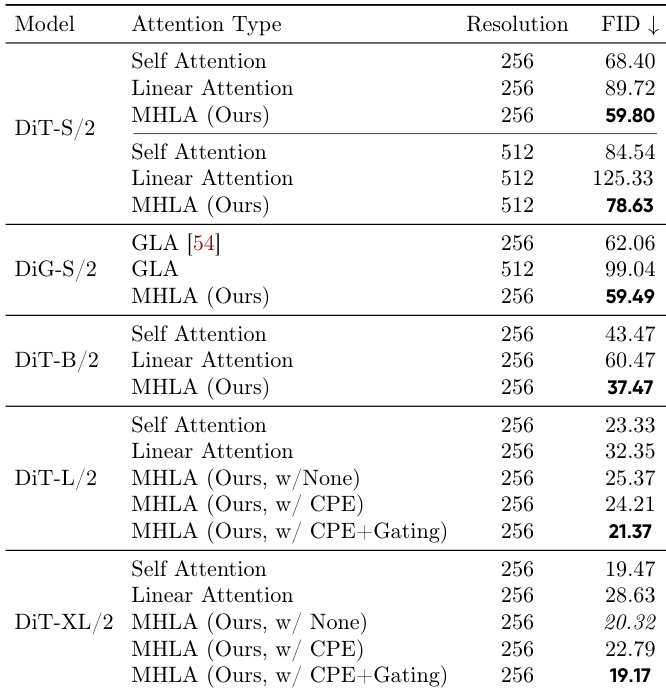
作者评估了在类别到图像生成中额外模块对 MHLA 的影响,结果表明结合 CPE 和门控机制可将 FID 降低至 59.8,优于所有其他变体。这表明包含两个模块的完整 MHLA 配置实现了最佳生成质量。
作者在 DiT 和 DiG 模型上评估了所提出的 MHLA 方法在图像生成任务中的表现,与自注意力和线性注意力基线进行对比。结果表明,MHLA 在所有模型规模和分辨率下均取得最佳 FID 分数,持续优于线性注意力,同时保持高吞吐量,并在更大规模下匹配或超越自注意力性能,无需依赖 CPE 等额外模块。
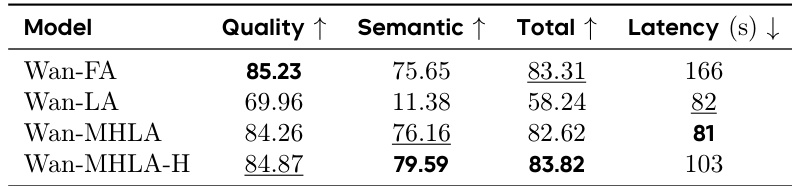
作者通过微调预训练的 Wan2.1-1.3B 模型评估 MHLA 在视频生成中的表现,将其 FlashAttention 替换为 MHLA。结果表明,MHLA 在保持相同延迟的前提下,显著优于原始线性注意力,恢复了与原模型相当的性能,并实现 2.1 倍的推理加速。