Command Palette
Search for a command to run...
算法代码优化的受控自演化
算法代码优化的受控自演化
摘要
自演化方法通过迭代的“生成-验证-优化”循环提升代码生成能力,然而现有方法在有限资源预算下普遍存在探索效率低下问题,难以发现复杂度更优的解决方案。这种低效性主要源于初始状态偏差导致演化过程陷入次优解区域、随机操作缺乏反馈引导而失控,以及跨任务间经验利用不足。为解决上述瓶颈,我们提出受控自演化(Controlled Self-Evolution, CSE),其包含三个核心组件:多样化规划初始化,通过生成结构差异显著的算法策略,实现对解空间的广泛覆盖;遗传演化机制,以反馈引导的演化操作替代随机操作,支持定向突变与组合式交叉;分层演化记忆系统,在跨任务与任务内两个层面分别记录并复用成功与失败的经验。在EffiBench-X基准上的实验表明,CSE在多种大语言模型(LLM)架构下均持续优于所有基线方法。此外,CSE在早期演化阶段即展现出更高的效率,并在整个演化过程中保持持续改进能力。相关代码已公开,详见:https://github.com/QuantaAlpha/EvoControl。
一句话总结
南京大学、北京大学、美的-AIRC、华东师大、中山大学、人大与QuantAlpha的作者提出受控自进化(CSE)方法,通过多样化初始化、反馈引导的遗传操作以及分层记忆实现经验复用,提升代码生成效率,在EffiBench-X基准上实现对多种LLM骨干网络的高效探索与持续优化。
主要贡献
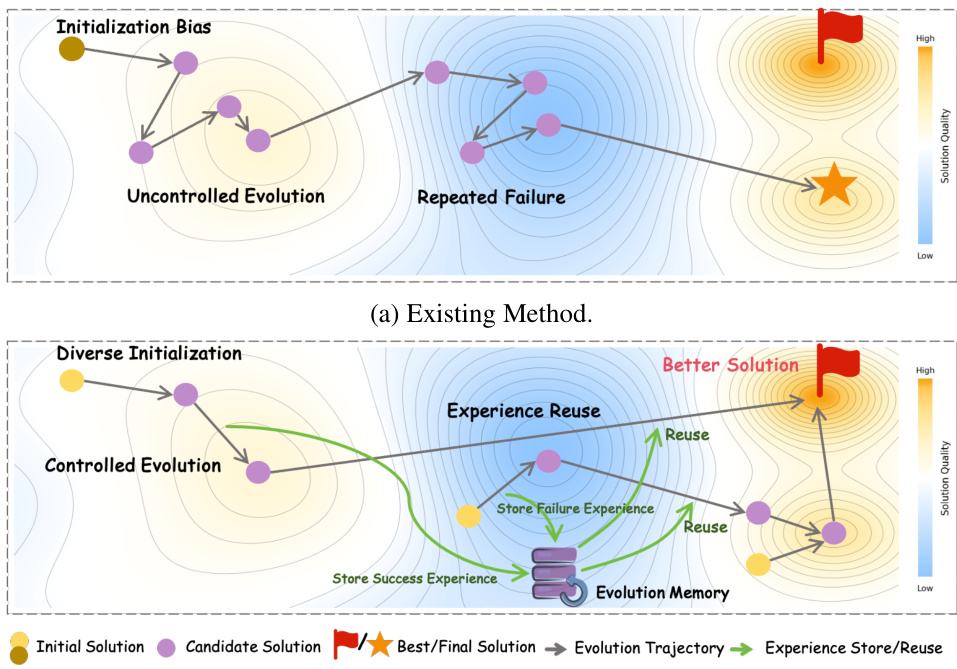
- 现有的代码生成自进化方法因初始化偏差、不可控的随机操作以及进化经验复用不足,导致探索效率低下,难以在有限计算预算内发现高质量、复杂的解决方案。
- 所提出的受控自进化(CSE)框架引入三项关键创新:多样化规划初始化,实现对解空间的广泛覆盖;反馈引导的遗传进化,通过有目标的变异与组合交叉实现精准优化;分层进化记忆,用于存储并复用任务内与跨任务的优化经验。
- 在EffiBench-X基准上,CSE在多个LLM骨干网络上均持续优于所有基线方法,从早期代次即展现出更高效率,并在整个进化过程中保持持续改进。
引言
作者针对在严格计算预算下生成高效率算法代码的挑战展开研究,这在现实世界LLM应用中至关重要,因延迟与成本均受限制。尽管先前的自进化方法通过“生成-验证-优化”循环实现迭代优化,但受限于初始化偏差、无引导的随机操作以及跨任务进化经验复用不佳,探索效率较低,难以发现时间与空间复杂度更优的最优解。为克服这一问题,作者提出受控自进化(CSE)框架,包含三大核心创新:多样化规划初始化,生成结构多样的初始策略以避开劣质解区域;遗传进化,以反馈引导的定向优化和组合交叉替代随机变异;分层进化记忆,捕获并复用任务内与跨任务的优化模式。在EffiBench-X上的实验表明,CSE在多种LLM骨干网络上均持续优于基线方法,实现更快收敛与持续提升,充分证明其在效率与解质量之间取得良好平衡的有效性。
方法
作者采用三组件框架实现代码优化中的受控自进化,旨在解决现有方法中无引导探索的低效问题。整体架构如系统图所示,包含规划阶段(生成初始种群)、进化循环(迭代优化解)以及记忆系统(存储并复用经验以指导未来搜索)。
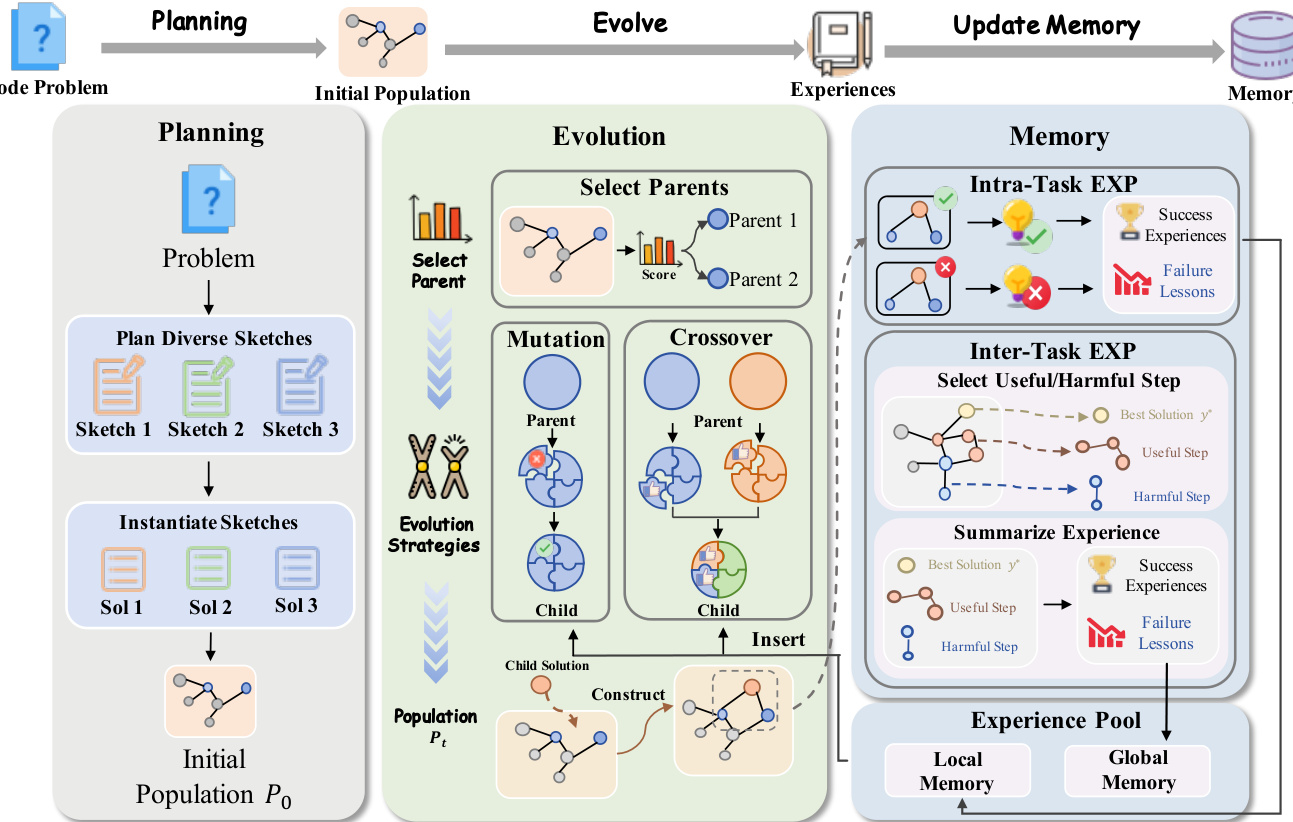
过程始于多样化规划初始化,旨在建立广泛且高质量的进化起点。该阶段利用大语言模型生成一组结构各异的解草图,每张草图代表一种根本不同的算法策略。随后,这些草图被实例化为具体的代码实现,构成初始种群。该方法确保从多个有前景的起点探索搜索空间,有效降低因随机初始化导致的过早收敛风险。
方法的核心是遗传进化过程,作用于初始种群。在每一轮迭代中,父代解根据其奖励值按比例概率选择,该机制可保留潜在有用的低奖励解。进化由两种受控策略驱动:受控变异与组合交叉。受控变异指模型识别解中特定故障组件并重新生成,同时保留其余代码,实现精准改进。组合交叉则从不同父代解中重组功能模块,生成继承互补优势的子代,例如将高效时间算法与稳健错误处理模块结合。
为提升该过程效率,框架引入分层进化记忆系统。该系统包含两个层级:本地记忆与全局记忆。本地记忆通过存储每轮进化中的成功洞察与失败教训,捕获任务内经验。这些经验经提炼与压缩,防止信息过载,并注入后续步骤的提示上下文中,引导模型搜索。全局记忆以向量数据库形式存储,累积以往问题的任务级经验。当模型面临新挑战时,生成针对性查询,从全局记忆中检索相关过往经验,从而复用相似任务的知识,避免重复错误。这种来自近期与历史经验的双向引导,使模型能更高效地导航解空间。
实验
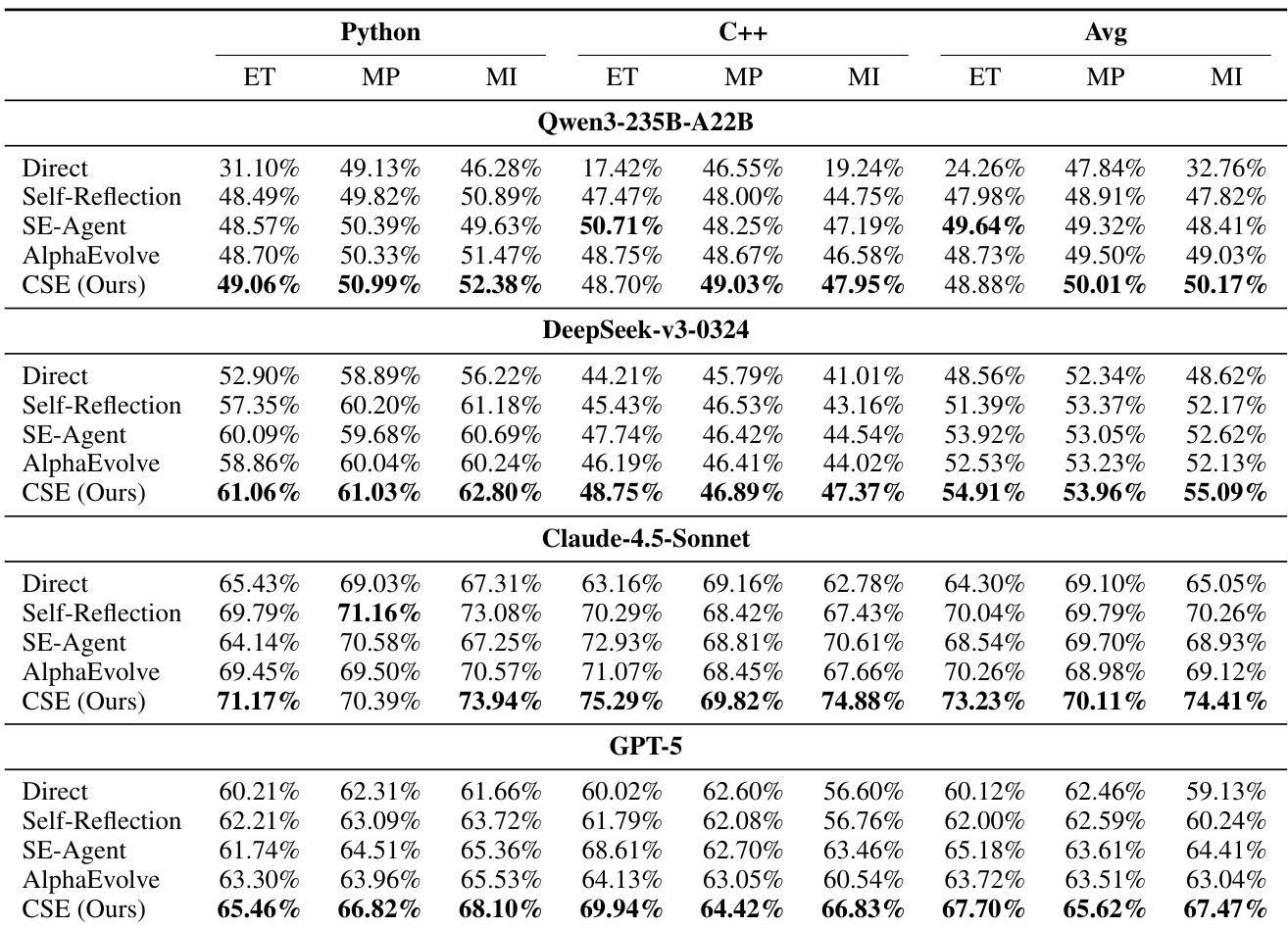
- CSE在EffiBench-X上进行评估,该基准包含Python与C++共623个算法问题,采用归一化效率指标:执行时间比(ET)、峰值内存比(MP)与内存积分比(MI),数值越高表示性能越优。
- CSE在两种语言上均全面超越四个基线方法(Direct、Self-Reflection、SE-Agent、AlphaEvolve),在ET、MP、MI三项指标上均取得最高分,尤其在内存效率方面提升显著。
- 在EffiBench-X上,CSE平均MI达142.3%(Python)与138.7%(C++),较最佳基线(AlphaEvolve)高出超过20个百分点,充分展现其卓越的探索效率与解质量。
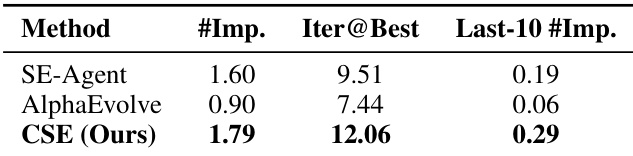
- 消融实验表明,所有组件——多样化规划、遗传进化与分层记忆——均不可或缺;移除任一组件均导致性能显著下降,其中记忆组件影响最大。
- 分层记忆与规划及进化结合时收益最大,ΔMI达+5.02,表明其带来的是协同增益而非简单叠加。
- CSE在代际间表现出更频繁且持续的改进,平均每轮产生1.79次改进事件,最后10代中仍保持0.29次,优于早期即停滞的基线方法。
- 案例研究证实,CSE通过多样化初始化、受控结构修改与记忆引导探索,成功发现高效率解,最终解与人类参考解差异显著,但效率更优。
作者通过受控消融实验评估CSE各组件的贡献。结果表明,移除任意一个组件——规划、进化或记忆——均导致所有指标性能显著下降,其中记忆组件影响最大。完整CSE模型在ET、MP、MI三项指标上均取得最高分,证明各组件间的协同作用对实现最优效率至关重要。
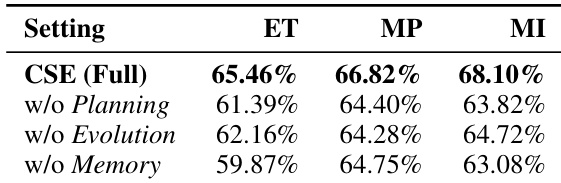
作者通过案例研究展示CSE的演化动态,表明该方法通过多样化初始化与受控变异实现显著早期改进,随后通过组合交叉与分层记忆实现持续进步。结果表明,CSE迅速降低内存-时间积分,25代后达到最终值93.913,关键突破出现在第5代与第22代,充分展示反馈引导探索与结构优化的有效性。
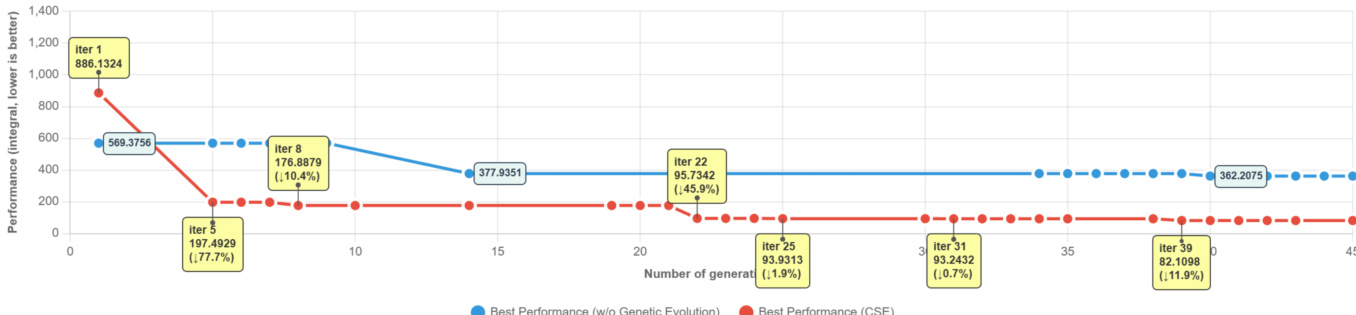
作者通过特定问题的案例研究展示CSE的演化动态,表明该方法通过多样化初始化与受控变异实现显著早期改进,随后通过组合交叉与分层记忆实现持续进步。结果表明,CSE在各代中持续降低内存-时间积分,关键突破出现在若干迭代点,最终性能远优于缺乏记忆机制的基线,充分证明记忆引导探索的有效性。
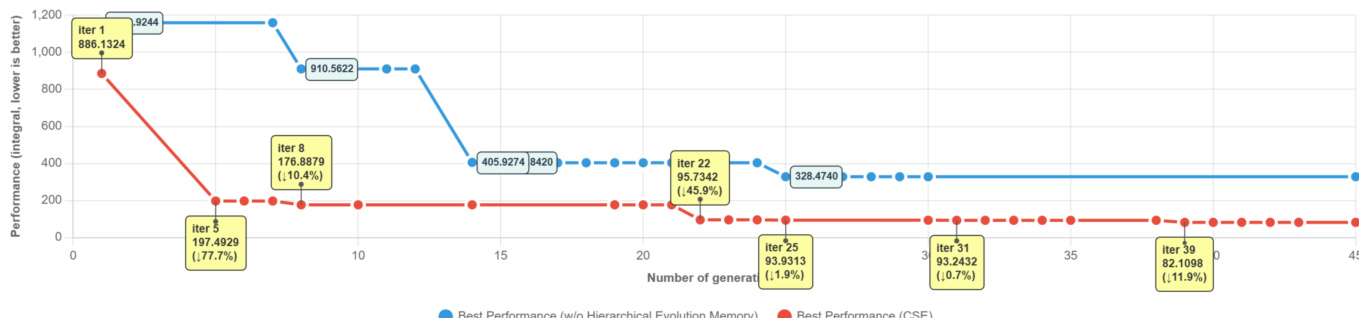
作者通过细粒度演化动态分析对比CSE与基线方法,表明CSE实现更频繁的改进与更强的后期进展。结果表明,CSE平均产生1.79次改进,更晚找到最优解,并在最后10代中保持更强的持续进步,优于SE-Agent与AlphaEvolve。
作者基于Python与C++共623个算法问题的基准评估代码效率,测量执行时间、峰值内存与内存积分相对于人类解的比值。结果表明,CSE在两种语言与多种模型上均持续优于所有基线,三项指标均取得最高分,尤其在内存积分方面提升显著,充分证明其在有限探索预算下发现高效解的能力。