Command Palette
Search for a command to run...
置信度二分法:工具使用Agent中误校准问题的分析与缓解
置信度二分法:工具使用Agent中误校准问题的分析与缓解
Weihao Xuan Qingcheng Zeng Heli Qi Yunze Xiao Junjue Wang Naoto Yokoya
摘要
基于大规模语言模型(LLMs)的自主智能体正迅速发展,以应对多轮交互任务,但确保其可信性仍是关键挑战。可信性的核心支柱之一是校准(calibration),即智能体表达信心的能力应与其实际性能保持一致。尽管校准在静态模型中已有充分研究,但在集成工具的智能体工作流中,其动态特性仍鲜有探索。本文系统性地研究了工具使用型智能体中的语言化校准(verbalized calibration),揭示了由工具类型驱动的根本性信心二分现象。具体而言,我们的初步研究发现:证据类工具(如网络搜索)由于检索信息固有的噪声,会系统性地引发严重过度自信;而验证类工具(如代码解释器)则可通过确定性反馈来支撑推理过程,有效缓解校准偏差。为在不同工具类型间实现稳健的校准提升,我们提出一种强化学习(RL)微调框架,该框架联合优化任务准确率与校准性能,并辅以全面的奖励设计基准进行评估。实验结果表明,经训练的智能体不仅在校准能力上表现更优,还展现出从局部训练环境到噪声较多的网络环境,以及在数学推理等不同领域中的强泛化能力。研究结果强调,针对不同应用场景,需采用领域特定的校准策略。更广泛而言,本工作为构建具备自我意识的智能体奠定了基础,使其能够在高风险、真实世界部署中可靠地表达不确定性。
一句话摘要
东京大学、理化学研究所AIP、西北大学、早稻田大学和卡内基梅隆大学的作者提出了一种强化学习框架,用于提升工具集成型大语言模型代理的口头校准能力,解决了噪声证据工具与确定性验证工具之间的置信度矛盾,使代理在多样化的现实场景中实现自我意识且可信赖的性能。
主要贡献
-
我们识别出工具使用型代理中的根本性置信度矛盾:如网络搜索等证据工具因信息噪声大、不确定性高,导致严重过度自信;而代码解释器等验证工具提供确定性反馈,能夯实推理过程并减少校准偏差。
-
我们提出校准代理强化学习(CAR),一种通过综合奖励设计(包括新颖的边际分离校准奖励(MSCR))联合优化任务准确率与口头校准的强化学习框架,显著提升置信度可靠性。
-
我们的方法在不同环境与领域中展现出稳健的泛化能力,在本地训练设置和噪声型网络场景下均实现更优校准效果,同时在数学推理任务中表现优异,验证了领域感知校准策略的有效性。
引言
由大语言模型(LLMs)驱动的自主代理正迅速发展,通过集成外部工具(如网络搜索或代码解释器)来处理复杂、多轮任务。然而,其可信度取决于是否具备恰当的校准能力——即准确反映自身表现的置信度,而这一问题在工具增强的工作流中仍缺乏深入理解。先前研究显示,工具使用常加剧过度自信,但此类现象主要局限于网络搜索等狭窄场景,尚不清楚该问题是否具有普遍性或依赖于具体工具类型。作者揭示了一个关键的置信度二分现象:证据工具(如网络搜索)引入噪声且缺乏明确的正确性反馈,导致严重过度自信;而验证工具(如代码解释器)提供确定性反馈,能夯实推理过程并改善校准。为应对这一挑战,作者提出校准代理强化学习(CAR)框架,通过一种新颖的边际分离校准奖励(MSCR)联合优化任务准确率与校准能力。该方法使代理在保持高准确率的同时显著提升置信度可靠性,从受控环境稳健泛化至噪声型现实场景,并跨越数学推理等不同领域。本工作表明,校准策略必须针对工具类型进行定制,为具备可信不确定性表达能力的自我意识代理在高风险应用中的实现奠定了基础。
数据集

- 数据集由两个主要来源构成:NQ(Natural Questions)和HotpotQA,用作工具使用代理策略优化的训练数据。
- NQ与HotpotQA以混合比例结合用于模型训练,具体比例未详述,但旨在支持稳健的推理与工具使用行为。
- 检索组件基于本地搜索引擎构建,知识库采用2018年维基百科数据集,使用E5作为密集检索器,确保证据检索的一致性与可复现性。
- 策略网络采用指令微调的大语言模型:Qwen2.5-3B-Instruct、Qwen2.5-7B-Instruct 和 Qwen3-4B-Instruct-2507,因其出色的指令遵循能力与可靠的置信度报告性能而被选中。
- 训练采用分组相对策略优化(GRPO)算法,该强化学习方法在多步工具使用场景中能有效实现策略学习。
- 模型在Search-R1框架内进行评估,该框架作为研究基于证据工具使用中校准偏差的主要测试平台。
- 未描述显式裁剪或元数据构建;数据以原始形式用于训练,处理仅限于标准分词与指令微调及强化学习训练所需的格式化。
方法
作者利用强化学习(RL)框架训练一个代理模型,使其在任务执行中实现稳健且校准良好的性能。整体架构如框架图所示,包含一个与外部工具(如证据工具,例如网络搜索;验证工具,例如代码解释器)交互的代理模型,以解决任务。代理生成推理、动作与观察结果,并被训练为输出既准确又具备良好置信度校准的响应。训练过程由一个结合结构完整性与校准感知评分的联合奖励函数引导。
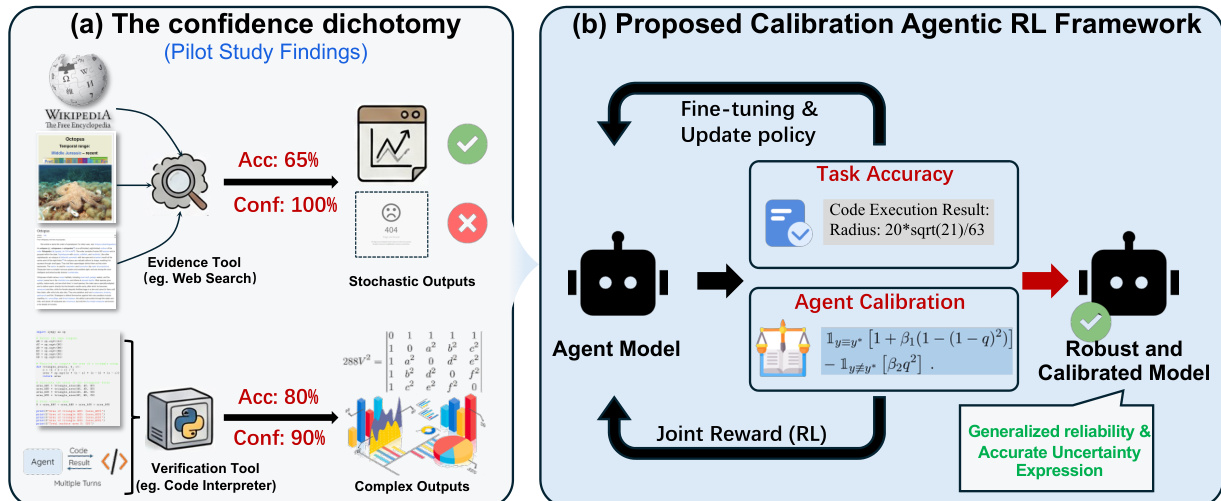
如图所示,该框架从代理模型生成一系列推理、动作与观察开始。输出结果被评估任务准确率与代理校准度。任务准确率由最终答案的正确性决定,而代理校准度则评估模型置信度与其实际表现的一致性。代理通过来自两个组件的联合奖励信号进行训练,该信号用于微调并更新策略。这一迭代过程最终生成一个具备泛化可靠性与准确不确定性表达能力的稳健校准模型。
所提出的奖励架构扩展了标准Search-R1格式,要求代理在<confidence> XML标签内输出数值型置信度分数。该结构要求通过布尔格式奖励函数 fformat(y) 强制执行,仅当所有结构约束(包括置信度标签的存在)均满足时返回True。这确保了代理遵循所需的输出格式。
校准驱动的结果奖励旨在鼓励准确预测与良好校准的置信度估计。作者实验了两种形式。第一种是加权Brier分数奖励,将准确率与置信度合并为单一标量奖励:
R(y,q,y∗)=1y≡y∗−λ(q−1y≡y∗)2.该形式对错误答案的过度自信进行惩罚,对正确答案的不足自信也进行惩罚。为缓解因激励重叠导致的优化不稳定性,作者提出边际分离校准奖励(MSCR),将正确与错误预测的校准项解耦:
RMSCR(y,q,y∗)=1y≡y∗[1+β1(1−(1−q)2)]−1y≡y∗⌈β2q2⌉,其中 β1,β2>0 控制校准强度。该形式确保严格的奖励边际:正确答案至少获得1的基准奖励,而错误答案最多获得0,并因虚假自信受到惩罚。
统一奖励函数将格式约束与校准感知评分相结合。给定模型输出 τ,总奖励 rϕ(x,τ) 定义为:
rϕ(x,τ)={Rcal(y,q,y∗)Rcal(y,q,y∗)−λfif fformat(τ)=True,otherwise.若格式被违反,则施加惩罚 λf。若无法提取置信度 q,则使用最小校准奖励作为回退,以保留正确性梯度的同时仍对格式错误进行惩罚。
实验
- 在Web Search(证据工具)和Code Interpreter(验证工具)上,使用Qwen2.5-3B-Instruct评估了直接提示、基于提示的工具使用与基于强化学习的工具使用。
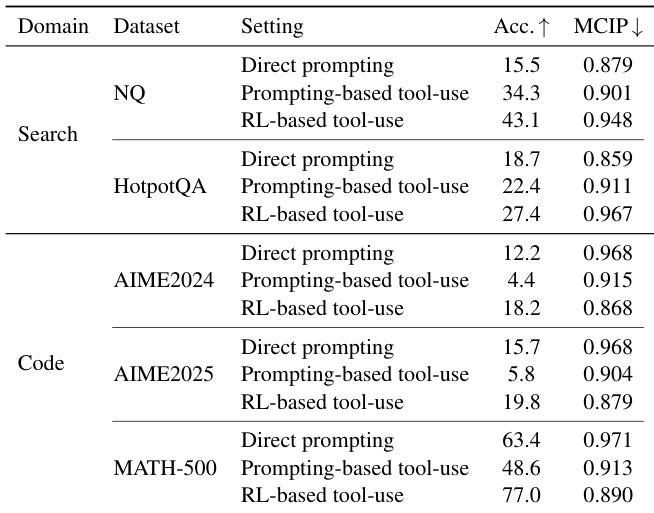
- 在NQ和HotpotQA上,基于强化学习的工具使用在Web Search中显著增加了过度自信(更高的MCIP),与直接提示相比具有统计显著差异,表明噪声检索导致校准退化。
- 在AIME2024/2025和MATH-500上,使用Code Interpreter的工具使用降低了过度自信,基于强化学习的代理达到最低MCIP,表明确定性反馈有助于改善校准。
- CAR(校准感知奖励)训练在所有骨干模型的ID与OOD设置下,将ECE降低了高达68%,同时保持与仅关注正确性的奖励基线相当的准确率。
- CAR在AUROC上实现最高达17%的提升,表明其不仅实现置信度重标定,更显著增强了区分正确与错误预测的能力。
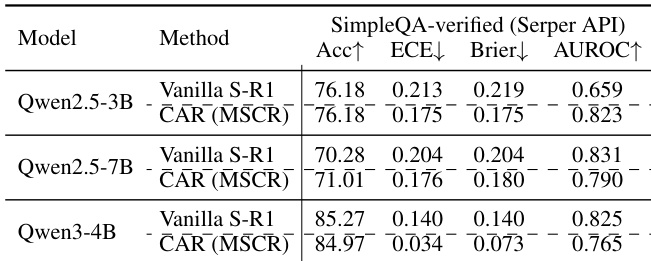
- CAR的校准收益在真实世界API环境(Serper API)中稳健迁移,CAR(MSCR)在校准与准确率上均优于原始Search-R1。
- 在工具集成推理(TIR)中,CAR降低了ECE与Brier分数,并在AIME2024/2025与MATH-500上提升了AUROC,但校准性能仍劣于纯推理模型,尤其在更复杂的AIME任务上ECE更高。
作者使用Qwen2.5-3B-Instruct评估三种工具使用配置——直接提示、基于提示的工具使用与基于强化学习的工具使用——在证据(Web Search)与验证(Code Interpreter)领域中的表现。结果显示,在搜索领域,工具使用增加了过度自信,基于强化学习的工具使用虽达到最高准确率,但也带来最高MCIP;而在代码领域,工具使用降低了过度自信,基于强化学习的工具使用实现最低MCIP与最高准确率。
作者使用Qwen2.5-3B-Instruct评估集成代码解释器的工具集成推理,将Vanilla SimpleTIR与作者的CAR(MSCR)方法在AIME2024/2025与MATH-500基准上进行对比。结果表明,CAR显著改善了校准性能,降低了ECE与Brier分数,同时提升了AUROC,但绝对校准水平仍低于纯推理模型,且在复杂问题上更具挑战性。

作者使用Qwen2.5-3B-Instruct与Qwen2.5-7B在证据与验证工具领域评估不同校准策略,结果显示CAR(MSCR)在所有模型规模下均持续降低期望校准误差(ECE)并提升AUROC,同时保持竞争力的准确率。结果表明,校准改进在模型规模上稳健,并可泛化至分布外设置与噪声API环境,尽管工具集成推理中的校准性能仍受限于任务复杂度。
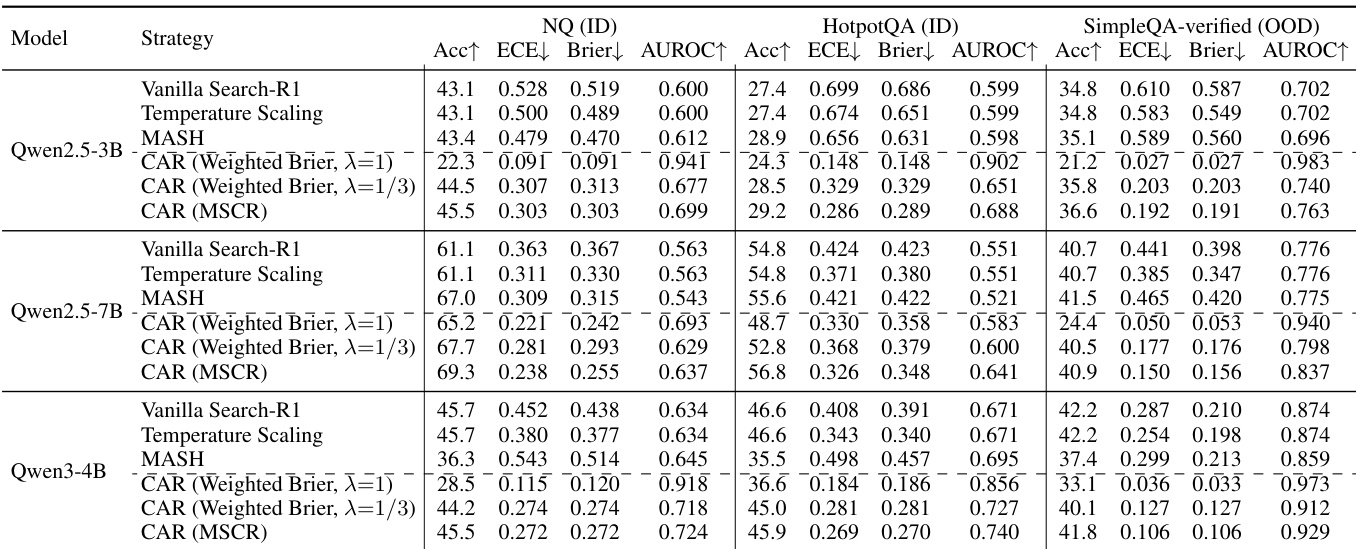
作者使用模拟检索环境与真实世界API驱动的检索器,评估搜索代理的校准性能。结果显示,CAR(MSCR)在ECE与Brier分数等校准指标上实现显著提升,同时在准确率上与原始基线保持竞争力,证明其在噪声型真实检索条件下的稳健泛化能力。