Command Palette
Search for a command to run...
主动上下文压缩:LLM Agents 中的自主内存管理
主动上下文压缩:LLM Agents 中的自主内存管理
Nikhil Verma
摘要
由于“上下文膨胀”(Context Bloat)的存在,Large Language Model (LLM) agents 在处理长程软件工程任务时面临巨大挑战。随着交互历史的不断增长,计算成本会呈爆炸式增长,延迟增加,且由于无关的过往错误产生的干扰,模型的推理能力也会随之下降。现有的解决方案通常依赖于被动的、外部的摘要机制,而 agent 无法对其进行控制。本文提出了 Focus,一种受多头绒泡菌(Physarum polycephalum,又称粘菌)生物探索策略启发、以 agent 为中心的架构。Focus Agent 可以自主决定何时将关键学习成果整合进一个持久化的“Knowledge”模块中,并主动撤回(剪枝)原始的交互历史。我们使用符合行业最佳实践的优化脚手架(persistent bash + 字符串替换编辑器),并利用 Claude Haiku 4.5 在 SWE-bench Lite 的 5 个上下文密集型实例上对 Focus 进行了评估。通过鼓励频繁压缩的激进 prompting 策略,Focus 在保持准确率不变(两个 agent 均为 3/5 = 60%)的情况下,实现了 22.7% 的 token 缩减(从 14.9M 降至 11.5M tokens)。Focus 平均每个任务执行 6.0 次自主压缩,在单个实例上的 token 节省率最高可达 57%。我们的研究表明,当获得适当的工具和 prompting 时,能力强大的模型可以自主调节其上下文,这为开发在不牺牲任务性能的前提下具备成本意识的 agentic 系统开辟了新路径。
一句话总结
Nikhil Verma 提出了 Focus,这是一种受多头绒泡菌(Physarum polycephalum)生物探索策略启发、以 Agent 为中心的架构。该架构使 LLM Agent 能够通过主动整合与修剪来自主管理上下文。在使用 Claude Haiku 4.5 时,Focus 在保持 60% 准确率的同时,在 SWE-bench Lite 实例上实现了 22.7% 的 token 减少。
核心贡献
- 本文引入了 Focus,这是一种受黏菌生物探索策略启发的以 Agent 为中心的架构,能够实现轨迹内的上下文管理。该方法允许 Agent 自主决定何时将关键学习内容整合到持久的知识块中,同时主动修剪原始交互历史。
- 该工作利用行业最佳实践实现了一个优化的脚手架,例如持久化的 bash 接口和字符串替换编辑器,以促进上下文的自主自我调节。这种方法使 Agent 能够在单个任务期间将最近的轨迹总结为高层级的见解,并物理删除冗余日志。
- 在上下文密集型 SWE-bench Lite 实例上的评估表明,与标准 Agent 相比,Focus Agent 在保持相同任务准确率的同时,实现了 22.7% 的总 token 减少。结果显示,该方法在每个任务中平均执行 6.0 次自主压缩,单个实例的 token 节省量最高可达 57%。
引言
随着大语言模型(LLM)Agent 开始处理复杂的、长程的软件工程任务,面临着被称为上下文膨胀(context bloat)的重大障碍。盲目使用大上下文窗口会导致成本呈二次方增长、延迟增加以及上下文中毒(context poisoning),即无关的试错日志会分散模型对主要任务的注意力。虽然现有解决方案使用了外部记忆层级或独立的压缩模型,但它们通常依赖于 Agent 在连续任务轨迹中无法控制的被动机制。本文提出了 Focus,一种受黏菌生物探索策略启发的以 Agent 为中心的架构。这种方法使 Agent 能够通过自主将关键学习内容总结为持久的知识块,并主动修剪原始交互历史以保持精简、有效的上下文,从而实现轨迹内的压缩。
方法
本文引入了一种名为 Focus Loop 的新颖架构,它通过两个专门的原语 start_focus 和 complete_focus 增强了标准的 ReAct Agent 循环。与依赖外部定时器或固定启发式方法来管理上下文长度的传统方法不同,该架构赋予 Agent 完全的自主权来决定何时启动和结束一个 focus 周期。
当 Agent 调用 start_focus 来声明特定的调查目标(例如调试数据库连接)时,流程开始。此操作在对话历史中建立了一个正式的检查点。在此检查点之后,Agent 进入探索阶段,利用读取、编辑和执行代码等标准工具来执行任务。
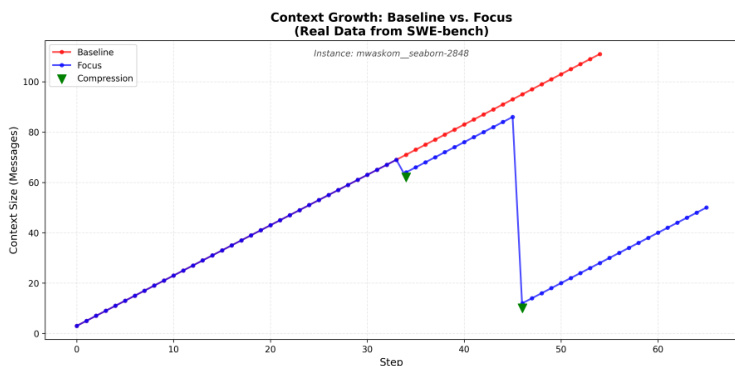
当 Agent 对子任务达到自然结论或遇到死胡同时,会调用 complete_focus。在此整合阶段,Agent 会生成一个结构化摘要,捕捉尝试过的操作、学到的事实或 bug 以及最终结果。随后系统执行撤回过程:生成的摘要被追加到位于上下文顶部的持久“Knowledge”块中,并且初始检查点与当前步骤之间的所有中间消息都会被删除。这种机制将上下文从单调递增的日志转变为“锯齿状”模式,即上下文在探索期间扩展,在整合期间收缩。这使得模型能够根据任务的内在结构而非任意的步骤计数来管理自身的上下文。
为了支持这一循环,本文实现了一个专为软件工程任务设计的优化脚手架。该脚手架由两个主要工具组成:持久化 Bash 会话和字符串替换编辑器。持久化 Bash 工具提供了一个有状态的 shell 环境,工作目录和环境在多次调用中保持一致,模拟了真实的开发者终端。为了确保精确的文件操作,字符串替换编辑器允许通过精确的字符串替换进行针对性编辑,包括查看、创建、替换和插入文本等操作。这种方法避免了与全文件重写相关的常见错误。系统提示词引导 Agent 广泛使用这些工具(最高限制为 150 步),并鼓励在尝试解决主要问题之前实施测试。
实验
Focus 架构在五个上下文密集的 SWE-bench Lite 实例上进行了评估,通过 A/B 测试来确定激进的上下文压缩是否能在不牺牲任务准确率的情况下减少 token 使用量。实验表明,强制执行频繁且结构化压缩阶段的指令式提示(directive prompting)能够在保持与基准 Agent 相同成功率的同时,实现显著的 token 节省。虽然该架构对于探索密集型任务非常有效,但结果也表明,在需要持续迭代优化的任务中,压缩开销偶尔会超过其带来的收益。
本文将基准 Agent 与 Focus 架构在上下文密集的软件工程任务上进行了对比。结果显示,Focus Agent 在保持与基准水平相同的任务成功率的同时,实现了显著的 token 减少。与基准相比,Focus Agent 大幅降低了总 token 消耗。基准与 Focus 架构之间的任务成功率保持一致。Focus 方法利用频繁的压缩和消息丢弃来管理上下文效率。
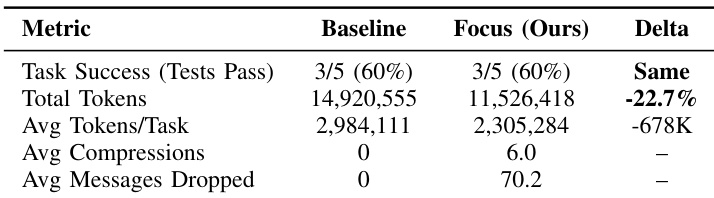
本文在上下文密集的软件工程任务上将 Focus 架构与基准 Agent 进行对比,以测试其管理上下文效率的能力。通过利用频繁的压缩和消息丢弃,Focus 方法显著降低了总 token 消耗。最终,该架构在保持与基准相同水平的任务成功率的同时,运行效率更高。