Command Palette
Search for a command to run...
大规模多Agent AI系统发展与问题研究
大规模多Agent AI系统发展与问题研究
Daniel Liu Krishna Upadhyay Vinaik Chhetri A.B. Siddique Umar Farooq
摘要
多智能体人工智能系统(MAS)的迅速兴起,包括LangChain、CrewAI和AutoGen等,正在深刻影响大型语言模型(LLM)应用的开发与协同方式。然而,目前对这些系统在实际应用中的演化与维护机制仍知之甚少。本文首次开展了针对开源多智能体系统的大型实证研究,分析了八个主流系统中超过4.2万个独立提交(commits)以及超过4700个已解决的问题。我们的分析识别出三种截然不同的开发模式:持续型、稳定型和爆发驱动型。这些模式反映出生态系统成熟度存在显著差异。在所有变更中,完善性提交(perfective commits)占比达40.8%,表明系统开发更侧重于功能增强,而非纠错性维护(27.4%)或适应性更新(24.3%)。问题数据分析显示,最常见的问题类型包括:缺陷(bugs,22%)、基础设施问题(14%)以及智能体协调难题(10%)。自2023年起,所有框架中的问题报告数量均出现显著上升。问题的中位解决时间从不足一天到约两周不等,尽管多数问题响应迅速,但仍有少数问题需要长期关注与处理。研究结果揭示了当前生态系统所展现出的强大发展动力,同时也暴露出其内在脆弱性,强调亟需加强测试基础设施建设、提升文档质量,并改进维护实践,以保障系统的长期可靠性与可持续发展。
一句话总结
路易斯安那州立大学和肯塔基大学的研究人员首次对开源多智能体AI系统进行了大规模实证研究,分析了包括LangChain和AutoGen在内的八个领先框架中超过4.2万次提交和4700个已解决的问题。他们识别出三种开发模式——持续型、稳定型和爆发型,并发现完善性提交(40.8%)远超修正性(27.4%)和适应性(24.3%)变更,表明系统更侧重于功能增强。主要挑战包括缺陷、基础设施和智能体协调问题,修复时间差异显著,凸显该生态系统的快速发展与潜在脆弱性。
主要贡献
-
本研究首次对开源多智能体AI系统(MAS)进行了大规模实证分析,涵盖八个领先框架中超过4.2万次提交和4700个已解决的问题,揭示了三种不同的开发模式——持续型、稳定型和爆发型,反映了生态系统成熟度和长期维护实践的差异。
-
分析显示,完善性维护(占提交的40.8%)是主导活动,显著超过修正性(27.4%)和适应性(24.3%)变更,表明开发重点在于功能增强而非缺陷修复或系统适应,且反复出现的问题集中于缺陷、基础设施和智能体协调挑战。
-
问题修复时间普遍较快,中位数在一天以内至两周之间,但分布呈偏斜状,自2023年起问题报告量激增,凸显MAS生态系统的快速增长与内在脆弱性,强调亟需加强测试、文档和维护基础设施。
引言
研究人员利用对八个领先开源多智能体AI系统(如AutoGen、CrewAI和LangChain)的大规模软件挖掘,分析真实世界的开发与维护实践。这些系统通过协作调度专业化智能体来解决复杂任务,正逐步取代单体式大语言模型应用,成为更具可扩展性和模块化的AI工作流范式。然而,以往研究多集中于架构创新与基准测试,缺乏对系统实际演进过程的深入理解。本研究揭示了开发模式的显著差异——持续型、稳定型和爆发型,同时发现功能增强(占提交的40.8%)远超缺陷修复(27.4%)和适应性更新(24.3%),表明维护存在失衡。常见问题包括缺陷、基础设施不稳定以及智能体协调失败,修复时间虽以快速处理为主,但仍有相当比例需数周时间。研究的主要贡献在于首次从大规模视角对MAS生态系统进行实证刻画,揭示其系统性脆弱性,并强调亟需改进测试、文档和长期维护策略,以保障系统的可靠性与可持续性。
数据集

- 数据集包含两个主要部分:八个主流开源GitHub仓库中多智能体系统(MAS)架构的已关闭问题和提交历史。
- 问题数据通过GitHub GraphQL API收集,共获得所有仓库中10,813个已关闭问题。
- 提交数据通过克隆每个仓库并提取所有提交记录获得,初始共44,041次提交。
- 在问题分析中,仅保留与拉取请求(PR)关联的问题,最终剩余4,731个问题。其中3,793个进一步被标注,支持问题分类分析。
- 提交数据经过预处理,移除由Git操作(如樱桃 picking 和 rebase)导致的重复提交,最终得到42,267个唯一提交。
- 预处理后的数据集根据研究问题拆分为各仓库专属子集,详细划分见表II。
- 研究人员使用过滤后的问题与提交数据,分析开发与维护模式,其中问题数据支持RQ2(问题报告与修复),提交数据支持RQ1(提交活动与类型)。
- 未采用裁剪策略,而是提取并结构化元数据(如问题标签、PR链接、提交时间戳),以支持纵向与分类分析。
实验
- 识别出三种不同的开发模式:持续高强度型(LangChain)、稳定持续型(Haystack)和爆发/间歇型(SuperAGI),提交规律性差异显著(变异系数CV从48.6%到456.1%不等)。
- 完善性维护主导提交活动(40.83%),显著高于修正性(27.36%)和适应性(24.30%)类型,表明系统处于以功能驱动为主的开发阶段,混合提交实践极少(<8%)。
- 代码 churn 分析显示,SuperAGI在2023年初表现出快速原型开发(新增300万行代码),Haystack体现为有意识的重构(大量删除),LangChain则持续进行架构调整(多次出现churn高峰)。
- 生态系统层面演进显示,到2025年累计代码增长达1000万至2000万行,超过10万文件被修改,2023年后代码增删趋于平衡,表明对可维护性的关注显著提升。
- 2023年起,多数框架的问题报告量显著增加,Haystack和Semantic Kernel报告量最高(超4000个问题),而修复时间差异巨大(中位数1至超过10天),分布右偏,表明长尾问题修复周期较长。
- 缺陷报告(22%)、基础设施(14%)、数据处理(11%)和智能体相关问题(10%)是最常见的问题类型,技术实现挑战远超社区或用户体验问题。
- 对智能体问题的主题建模显示,58.42%聚焦于智能体能力(如规划、协调、集成),32.51%集中于技术操作(如评估、模型训练、函数调用),凸显创新与部署稳定性之间的张力。
- 在分析数据集(42,266次提交,4,700个已解决的问题)上,生态系统自2023年后呈现快速增长,由大语言模型的普及驱动,开发优先考虑功能增强而非缺陷修复,项目成熟度与维护效率存在显著差异。
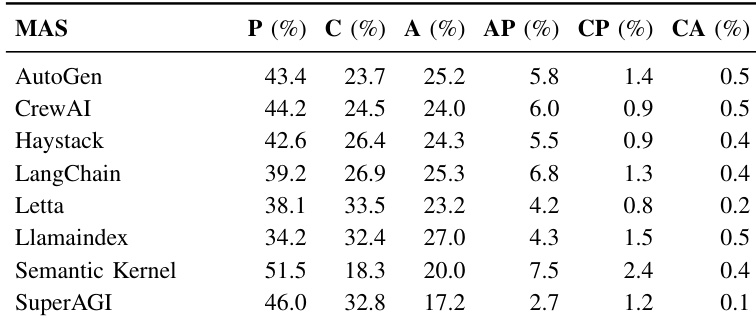
研究人员使用微调后的DistilBERT模型对提交进行维护类型分类,并分析其在MAS框架中的分布。结果显示,完善性维护占主导,Semantic Kernel的比率最高(51.5%),修正性维护最低(18.3%);而SuperAGI的修正性比率较高(32.8%),表明其架构稳定性较差。
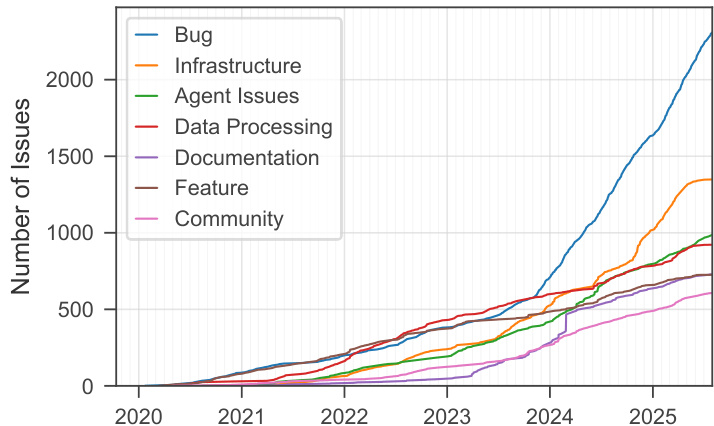
结果显示,多智能体AI框架中的问题活动自2023年后显著增强,缺陷报告增长最快,到2025年已超过2000个。基础设施、智能体问题和数据处理问题也持续上升,而文档和社区相关问题在整个期间保持较低水平。
研究人员使用微调后的DistilBERT模型对42,266次提交进行维护类型分类,结果显示完善性提交占所有变更的40.83%,显著高于修正性(27.36%)和适应性(24.30%)提交。结果表明,单一维护类型提交占总数的92.49%,而复合维护类型仅占7.51%,表明开发任务高度偏好原子化、聚焦型工作。
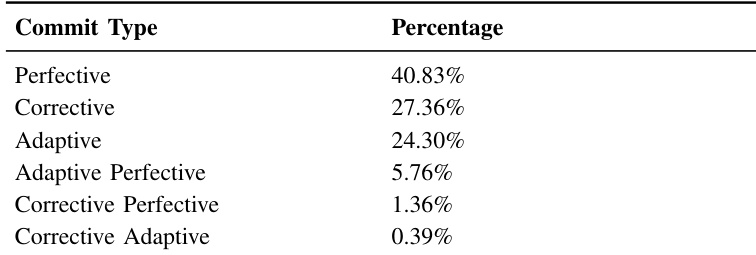
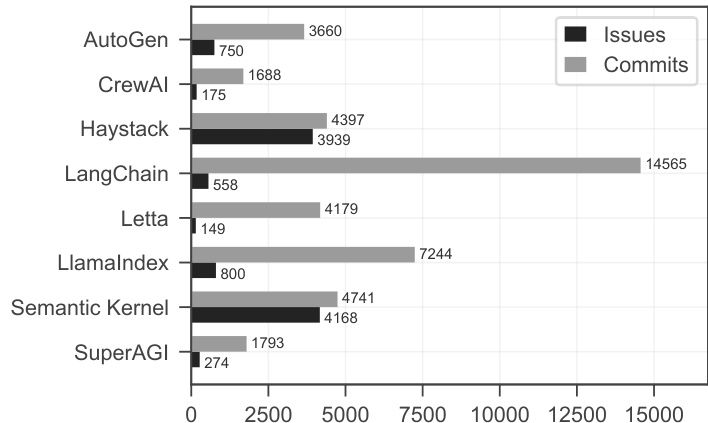
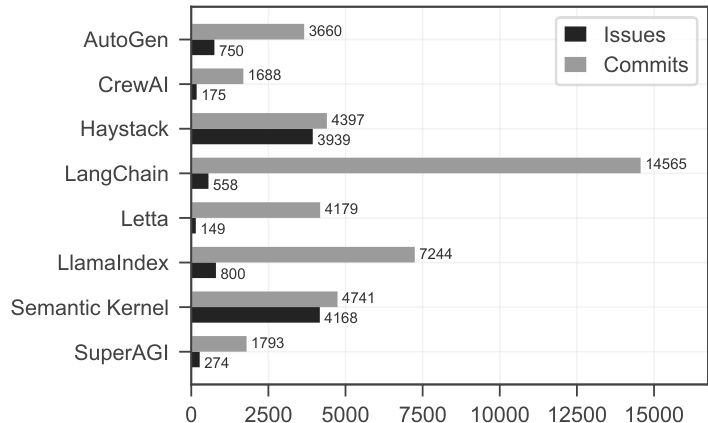
研究人员对多个多智能体AI框架的问题与提交数据进行分析,结果显示Haystack和Semantic Kernel的问题数量最多,分别为3,939和4,168个,而SuperAGI最少,仅274个。提交数量也呈现相似趋势,Haystack和LangChain分别拥有最多提交(4,397和14,565次),SuperAGI最少,仅1,739次。
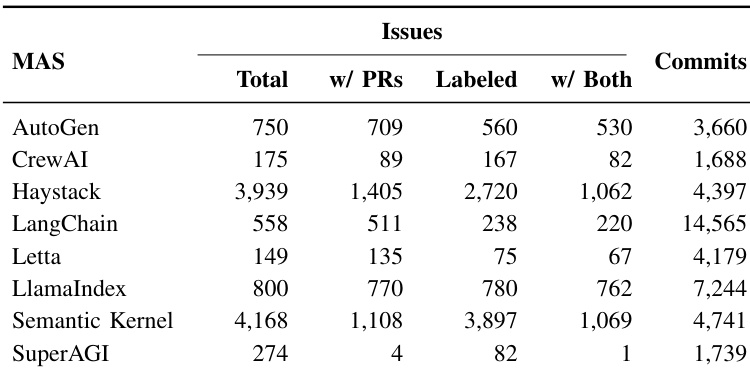
研究人员使用柱状图比较七个多智能体AI框架的问题与提交数量,结果显示LangChain提交数最多(14,565次),而Haystack在问题数量上领先(4,397个)。数据揭示了开发活动的显著差异,部分框架如AutoGen和CrewAI在两项指标上均较低,表明其社区参与度和项目成熟度存在差异。