Command Palette
Search for a command to run...
Dr. Zero:无需训练数据的自演化搜索Agent
Dr. Zero:无需训练数据的自演化搜索Agent
Zhenrui Yue Kartikeya Upasani Xianjun Yang Suyu Ge Shaoliang Nie Yuning Mao Zhe Liu Dong Wang
摘要
随着高质量数据的获取日益困难,无数据自演化(data-free self-evolution)逐渐成为一种极具前景的新范式。该方法使大型语言模型(LLMs)能够自主生成并求解复杂问题,从而提升其推理能力。然而,多轮搜索代理在无数据自演化场景中面临挑战,主要受限于问题多样性不足,以及多步推理与工具使用所带来巨大的计算开销。在本工作中,我们提出 Dr. Zero,一个使搜索代理在无需任何训练数据的情况下仍能有效自演化的框架。具体而言,我们设计了一种自演化反馈循环:由一个提议者(proposer)生成多样化的问题,用于训练一个基于相同基础模型初始化的求解器(solver)。随着求解器的不断进化,它会激励提议者生成越来越具有挑战性但依然可解的任务,从而构建出自动化的课程体系,持续优化两个代理。为提升训练效率,我们进一步引入了分跳分组相对策略优化(Hop-Grouped Relative Policy Optimization, HRPO)。该方法通过将结构相似的问题聚类,构建群体层面的基线,有效降低评估每个查询个体难度与可解性的采样开销。结果表明,HRPO在不损害性能或稳定性的前提下,显著降低了求解器训练的计算需求。大量实验结果表明,无数据的 Dr. Zero 在性能上可达到甚至超越完全监督的搜索代理,证明了复杂推理与搜索能力完全可以通过自演化过程自发涌现。
一句话总结
Meta Superintelligence Labs 与伊利诺伊大学厄本那-香槟分校的作者提出 Dr. Zero,这是一种无需数据的自我进化框架,使搜索代理能够通过提议者与求解者之间的协同进化循环,自主提升推理与搜索能力,利用外部搜索引擎提供监督信号;其核心创新在于跳跃分组相对策略优化(HRPO),该方法将结构相似的问题聚类,消除昂贵的嵌套采样,降低计算开销,同时保持性能,使系统在无需任何训练数据的情况下,即可在复杂开放域问答基准上达到或超越监督基线。
主要贡献
- Dr. Zero 通过消除对人工标注问题或答案注释的依赖,实现了搜索代理的无数据自我进化,转而利用外部搜索引擎通过难度引导奖励提供监督信号,鼓励生成复杂、多跳查询。
- 该框架引入跳跃分组相对策略优化(HRPO),将结构相似的问题聚类以建立稳健的组级基准,从而避免标准方法所需的计算成本高昂的嵌套采样,同时保持训练稳定性和性能。
- 大量实验表明,Dr. Zero 的自我进化代理在复杂问答基准上的表现可达到或超过完全监督基线,最高提升达 14.1%,证明了先进推理与搜索能力可仅通过自主自我进化产生,无需任何训练数据。
引言
作者利用外部搜索引擎,在无数据环境下实现搜索代理的自我进化,使大语言模型(LLMs)能够自主生成并解答复杂、开放域问题,而无需依赖人工标注数据或注释。这对于在高质量训练数据稀缺或获取成本高昂的真实应用场景中扩展推理与搜索能力至关重要。先前的自我进化 LLM 研究面临两大关键挑战:提议者生成的问题多样性有限——往往偏好简单的一跳查询;而标准训练方法如组相对策略优化(GRPO)需要计算成本高昂的嵌套采样,使其在多步推理和工具使用场景中难以实用。为解决这些问题,作者提出 Dr. Zero,该框架结合优化的多轮工具使用流程与难度引导奖励,驱动提议者生成越来越复杂、可验证的问题。此外,作者提出跳跃分组相对策略优化(HRPO),通过将结构相似的问题聚类,建立稳定的组级基准用于优势估计——消除嵌套采样需求,同时保持训练效率与性能。实验表明,Dr. Zero 在复杂问答基准上达到或超过完全监督基线,证明了先进推理与搜索能力可纯粹通过自我进化产生。
数据集

- 数据集包含多个开放域问答基准,包括三个一跳数据集:Natural Questions (NQ)、TriviaQA 和 PopQA,以及四个多跳数据集:HotpotQA、2WikiMultihopQA (2WikiMQA)、MuSiQue 和 Bamboogle。
- 这些数据集来源于公开的学术出版物,涵盖广泛的搜索与推理挑战,支持在单轮与多跳问题场景下的评估。
- 作者在所有实验中均使用 Qwen2.5 3B/7B Instruct 作为基础语言模型,包括 Dr. Zero 与基线方法。
- Dr. Zero 与多种基线方法进行对比:少样本方法(标准提示、IRCoT、Search-o1、RAG)和监督方法(SFT、R1、Search-R1)。
- 所有模型在相同条件下使用精确匹配(EM)进行评估:采用 E5 基础模型作为搜索引擎,使用英文维基百科数据作为语料库。
- 一个关键区别在于,所有基线方法依赖人工标注的示范或训练数据,而 Dr. Zero 完全不依赖此类数据,属于无数据方法。
- 评估设置通过在所有方法中使用一致的搜索与检索基础设施,确保公平比较。
方法
作者采用提议者-求解者自我进化框架,其中两个模型均作为能够通过搜索引擎 R 利用外部知识的搜索代理。提议者 πθ 与求解者 πϕ 被训练以最大化各自的期望奖励。提议者的任务是生成多样且具有挑战性的问题,而求解者的任务是生成正确答案。提议者的奖励基于预测答案分布 {y^i}i=1n,惩罚那些过于简单(所有预测均正确)或过于困难(无预测正确)的问题。求解者的奖励基于结果,使用指示函数评估正确性。这形成了一种共生循环:提议者根据求解者反馈学习生成越来越复杂的问题,而求解者通过解决这些问题提升其推理能力,从而形成持续演进的课程体系。
提议者训练面临挑战,因为为单个提示生成多个响应的计算成本很高,而评估查询难度又需要多个求解者预测,进一步加剧了成本。为解决此问题,作者提出跳跃分组相对策略优化(HRPO)。该方法根据跨跳复杂度(记为跳数 h∈H)对生成的问答对进行分组,并通过在所有 h-跳问题上标准化求解者的奖励得分来计算优势。这种跳数特定的归一化方法在避免每提示采样多个候选问题的计算成本的同时,产生低方差的优势估计。HRPO 被形式化为一个策略优化目标,通过加权相对优势最大化生成问答对的对数似然,并加入 KL 散度正则项。优势 Ai,h 通过在所有 h-跳问题上对奖励 ri 进行标准化计算,确保提议者学习生成既可验证又具挑战性的问题。

对于求解者训练,作者从提议者 πθ 中采样数据对 (x,y),并通过组相对策略优化(GRPO)优化 πϕ。GRPO 从求解者预测的经验组统计中计算优势,强化有效轨迹,无需独立的价值函数即可提升模型的搜索与推理能力。优化目标由基于结果的奖励驱动,评估最终预测与合成真实标签 y 的正确性。优势通过奖励标准化计算,对批次内每个预测的正确性进行归一化。该方法使求解者在面对提议者生成的日益复杂的问题时,持续优化其搜索与推理能力,形成动态课程,确保在多样化问题领域中求解者性能持续提升。
综上所述,Dr. Zero 框架利用无数据自我进化,迭代提升提议者与求解者。在每轮迭代中,提议者合成一批具有异构跳结构的问答对。利用求解者反馈,提议者通过 HRPO 优化,生成可验证、多样且具挑战性的问题。与此同时,求解者通过 GRPO 利用生成数据,优化其搜索与推理能力。这种交替优化循环形成共生反馈机制:随着求解者能力提升,简单问题带来的奖励递减,迫使提议者探索更复杂的推理路径以最大化回报。反之,日益复杂的问题防止求解者训练奖励趋于饱和,使其能持续拓展推理技能。两个模型均从同一基础 LLM 初始化,无需任何训练数据,仅依赖外部搜索引擎驱动性能提升。
实验
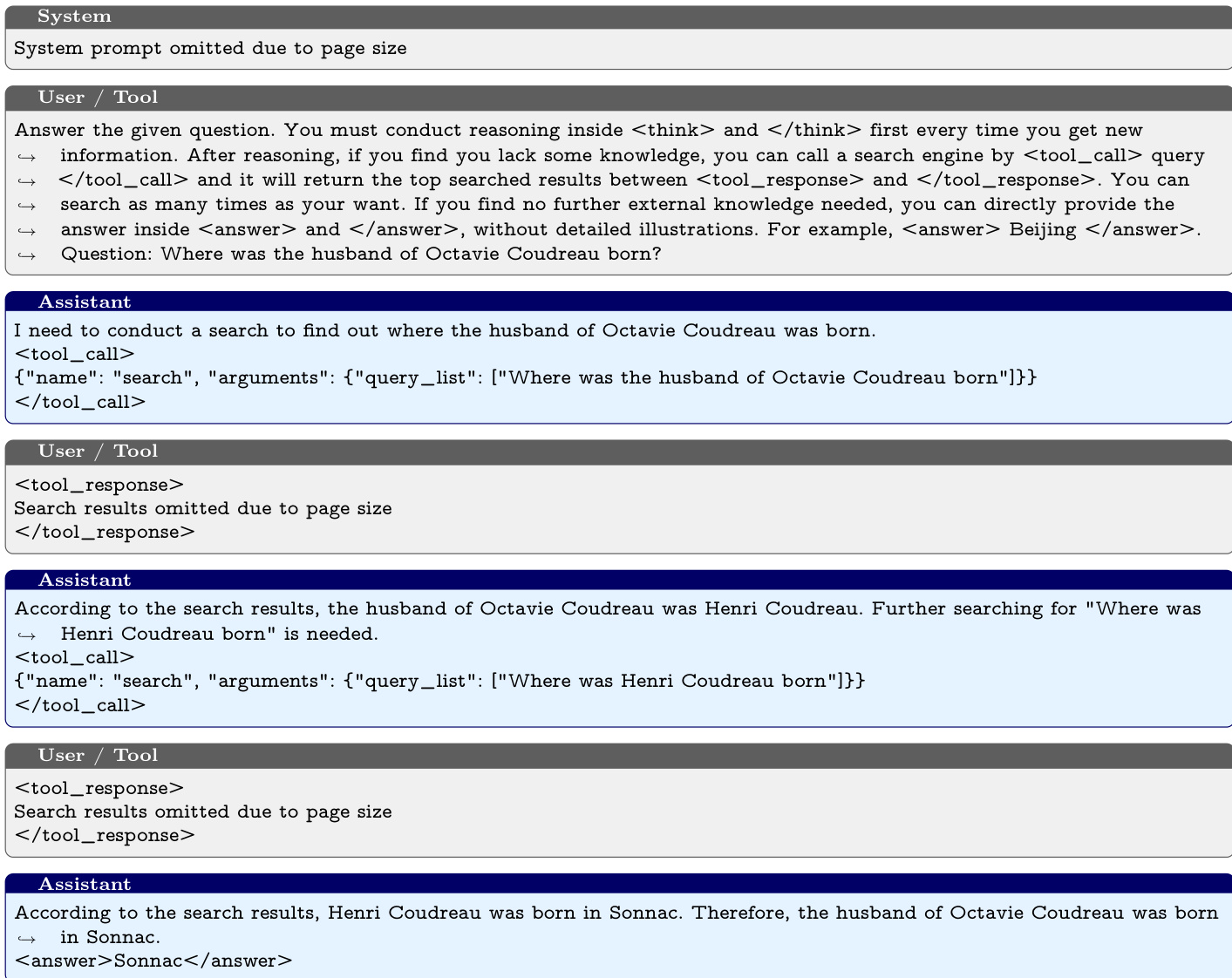
- Dr. Zero 在无数据搜索与推理任务中达到最先进性能,在单跳(NQ、TriviaQA、PopQA)和多跳(2WikiMQA)基准上均超越监督基线,且无需任何训练数据。在使用 Qwen2.5-3B 的 NQ 上,其 EM 达到 0.397,超过少样本提示(0.106)、IRCoT(0.111)和 Search-o1(0.238)。
- 3B 版本在 NQ、TriviaQA 和 PopQA 上分别超过监督 Search-R1 22.9%、6.5% 和 18.4%;7B 版本达到 Search-R1 性能的约 90%,并在 2WikiMQA 上表现更优。
- Dr. Zero 在无数据基线(SQLM*、R-Zero*)上平均分别高出 39.9% 和 27.3%,在多跳基准上提升达 83.3%,得益于改进的奖励设计与基于跳数的聚类。
- 训练动态显示,性能在 50 步内迅速提升,3B 模型在 2 轮后达到峰值,7B 模型在 3 轮后趋于平稳,表明自我进化高效,每模型仅需 150 步总训练。
- HRPO 将计算成本降至 GRPO 的四分之一,同时平均性能更高(0.326 vs. 0.320),证明其在无数据自我进化中的高效性与有效性。
- 消融研究确认格式与难度奖励的关键作用,移除初始上下文导致性能下降 20.7%,而更长训练无额外收益。
- 定性分析显示,模型具备强多跳推理、自适应检索与结构化分解能力,但长上下文生成仍是局限,偶有指令偏离或截断现象。
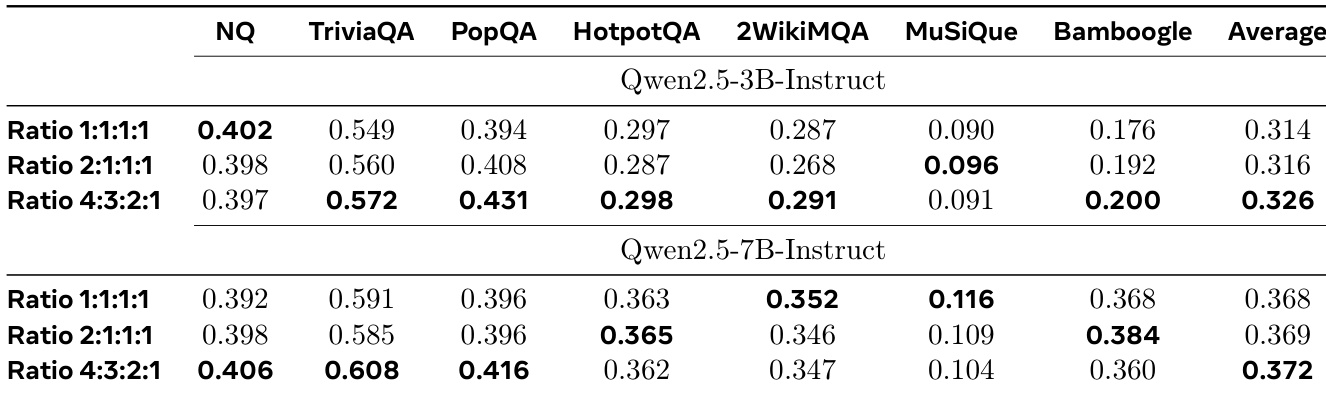
作者研究了不同跳数比例对 Dr. Zero 性能的影响,测试了 1:1:1:1、2:1:1:1 和 4:3:2:1 的一、二、三、四跳问题分布。结果表明,4:3:2:1 比例在 3B 与 7B 模型上均取得最高平均性能,表明包含更多多跳问题的平衡课程有助于整体推理能力提升。7B 模型从更高比例的多跳数据中获益更多,在复杂基准上表现优于 3B 模型,而 3B 模型在更均衡分布下表现最佳。
作者使用 Dr. Zero 在多个基准上与无数据基线 SQLM* 和 R-Zero* 进行对比,采用 3B 模型。结果表明,Dr. Zero 的平均性能高于两者,平均得分为 0.326,而 SQLM* 为 0.233,R-Zero* 为 0.256,证明其在生成高质量合成数据用于搜索与推理任务方面的有效性。

结果表明,3B 与 7B 求解者的奖励在第一轮迅速上升,约在第 50 步达到峰值,随后在后续轮次中趋于稳定或略有下降。提议者奖励呈现类似趋势,7B 提议者表现优于 3B,奖励更高且更稳定,表明大模型具有更强的自我进化能力。
作者使用 Dr. Zero 在单跳与多跳基准上评估性能,与监督与无数据基线进行对比。结果表明,Dr. Zero 表现具有竞争力或更优,3B 模型在单跳任务上超越监督 Search-R1,7B 版本在多跳任务上达到 Search-R1 约 90% 的性能,证明其在无训练数据下实现有效自我进化。
作者使用 Dr. Zero 评估迭代训练对模型性能的影响。结果表明,3B 与 7B 模型在第二轮即达到峰值性能,7B 模型在多跳任务上保持更高得分,而后续迭代仅带来微小提升。