Command Palette
Search for a command to run...
观看、推理与搜索:面向智能体视频推理的开放网络视频深度研究基准
观看、推理与搜索:面向智能体视频推理的开放网络视频深度研究基准
摘要
在现实世界的视频问答场景中,视频通常仅提供局部视觉线索,而可验证的答案则分散于开放网络之中;因此,模型需要协同完成跨帧线索提取、迭代式检索以及基于多跳推理的验证任务。为弥合这一差距,我们构建了首个面向视频深度研究的基准数据集——VideoDR。VideoDR聚焦于视频条件下的开放域视频问答任务,要求模型具备跨帧视觉锚点提取能力、与网络的交互式检索能力,以及对视频与网络证据联合推理的多跳推理能力。通过严格的人员标注与质量控制,我们获得了涵盖六个语义领域的高质量视频深度研究样本。我们在工作流(Workflow)与智能体(Agentic)两种范式下,对多个闭源与开源的多模态大语言模型进行了评估。结果表明,Agentic范式并非始终优于Workflow范式:其性能提升取决于模型在长链检索过程中维持初始视频锚点的能力。进一步分析显示,目标漂移(goal drift)与长程一致性(long-horizon consistency)是当前模型面临的核心瓶颈。综上所述,VideoDR为研究开放网络环境下视频智能体提供了系统性基准,同时也揭示了下一代视频深度研究智能体所亟需突破的关键挑战。
一句话总结
来自兰州大学(LZU)、香港科技大学(广州)(HKUST(GZ))、不列颠哥伦比亚大学(UBC)、复旦大学(FDU)、北京大学(PKU)、南加州大学(USC)、新加坡国立大学(NUS)、中国科学院大学(UCAS)、香港科技大学(HKUST)以及QuantAlpha的研究者提出了VideoDR,这是首个面向视频条件下的开放域问答任务的基准,要求进行跨帧视觉锚定提取、交互式网络检索和多跳推理;该研究揭示,当代理模型无法维持长时程一致性时,其表现会劣于工作流模式,凸显目标漂移和证据连贯性是下一代视频代理模型面临的核心挑战。
主要贡献
- 本文提出VideoDR,首个面向视频深度研究的基准,形式化了需要跨帧视觉锚定提取、交互式网络检索以及基于视频-网络联合证据的多跳推理的开放域视频问答任务,填补了封闭上下文视频理解与真实世界开放网络事实验证之间的空白。
- 通过在六个语义领域内进行严格的人员标注与质量控制,VideoDR确保答案依赖于视频中的动态视觉线索和可验证的开放网络证据,使其成为评估多模态代理在真实研究场景中表现的系统性测试平台。
- 对主流多模态大语言模型在工作流(Workflow)与代理(Agentic)范式下的评估表明,代理方法并非始终优于工作流;性能关键在于能否在长检索链中保持初始视频锚点,目标漂移与长时程一致性被识别为主要瓶颈。
引言
研究者针对多模态AI评估中的关键空白,提出了VideoDR,这是首个面向开放网络环境下视频深度研究的基准。在真实场景中,视频内容通常仅提供部分视觉线索,而确定性答案则存在于动态的外部网络资源中——这要求模型协同完成跨帧视觉锚定、交互式网络检索以及对视频-网络证据的多跳推理。现有工作在此领域存在不足:视频基准通常假设封闭证据环境,而现有的深度研究基准则聚焦于文本查询,将视觉输入视为次要因素。本文的核心贡献在于设计了VideoDR,一个经过严格标注的基准,强制要求证据获取依赖于多帧视频线索,确保答案无法仅从视频或网络单独推导得出。研究者在主流多模态模型上评估了工作流与代理两种范式,结果表明代理方法并不始终优于工作流,其性能高度依赖于维持长时程一致性并避免目标漂移——这凸显了这些因素是未来视频推理代理的核心挑战。
数据集

- 数据集VideoDR包含100个精心筛选的视频-问题-答案三元组,通过由三位具备视频理解与网络搜索经验的专家参与的结构化标注流程构建而成。
- 视频来源覆盖多样平台,采用分层抽样策略,涵盖来源、领域与时长三个维度,以确保广泛的真实世界覆盖。
- 采用严格的负样本过滤策略,剔除:(1) 单场景、高度冗余的片段;(2) 通过文本搜索即可轻松回答的热门话题;(3) 缺乏可验证证据链的孤立网络内容。
- 初步筛选仅保留具备连贯多帧视觉线索、适合跨帧关联的视频;对较长视频则按语义划分为独立片段进行标注。
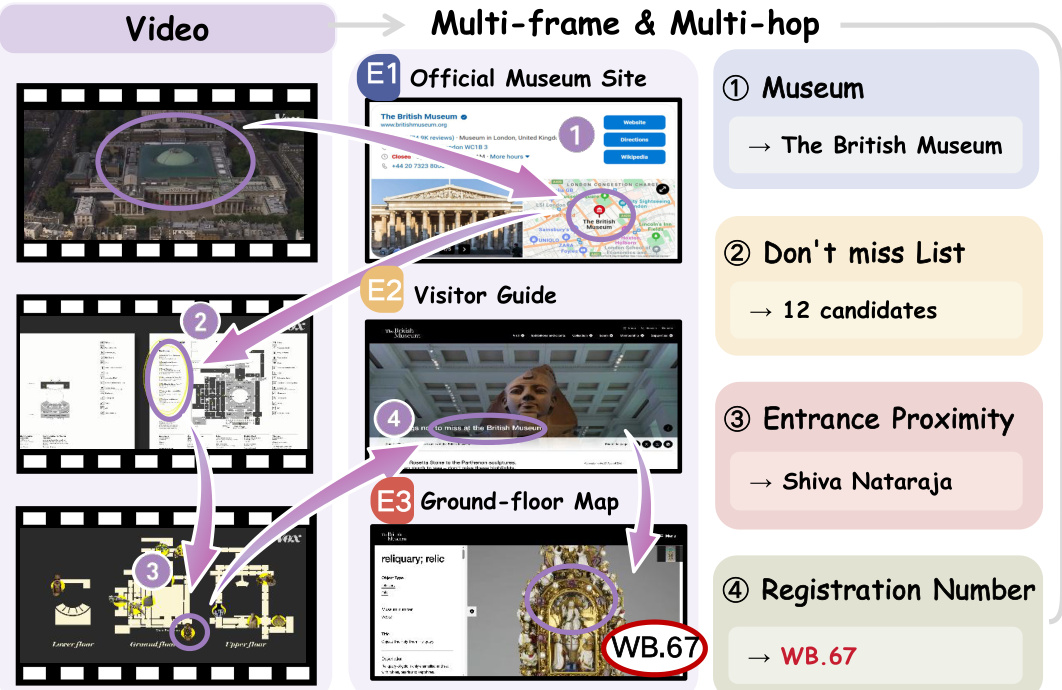
- 每个问题设计均遵循两个核心约束:(1) 多帧推理——要求证据来自多个帧,而非单张截图;(2) 多跳推理——需具备可分解的推理路径,将视频感知与外部网络搜索相连接。
- 为确保可验证性,标注过程中对支撑每个答案的关键证据网页进行了归档。
- 数据集涵盖六个领域:日常生活(33%)、经济(16%)、科技与文化(各15%)、历史(11%)和地理(10%),实现开放领域主题的均衡覆盖。
- 问题平均长度为25.54个token,95%的问题少于54个token,表明其表述简洁但信息丰富,强调推理过程而非输入复杂度。
- 视频时长呈长尾分布:多数较短,但一小部分超过10分钟,支持对快速线索检测与长距离跨段推理的评估。
- 研究者使用完整数据集进行训练,未提及显式的训练/验证/测试划分;数据被视为统一基准,用于评估多跳视频推理能力。
- 数据构建过程中未进行裁剪或帧采样——完整视频片段原样使用,保留时间上下文。
- 元数据包含领域标签、视频时长、问题长度与证据URL,支持分层分析与基准评估。
- 尽管最终答案具有客观可验证性,但中间的搜索查询与推理路径反映了标注者的主观策略,可能限制了真实用户行为多样性的捕捉。
方法
研究者构建了一套全面的数据标注流程,旨在确保高质量、多样化且语义丰富的基于视频的推理样本。流程始于通过跨多个领域(包括地理、历史、科技、文化、经济与日常生活)的分层抽样构建候选视频池,以确保真实场景的广泛覆盖。初始候选池随后进入初步筛选阶段,由人工标注者手动审查视频,仅保留适合进一步处理的样本,剔除不相关或质量不佳的视频。
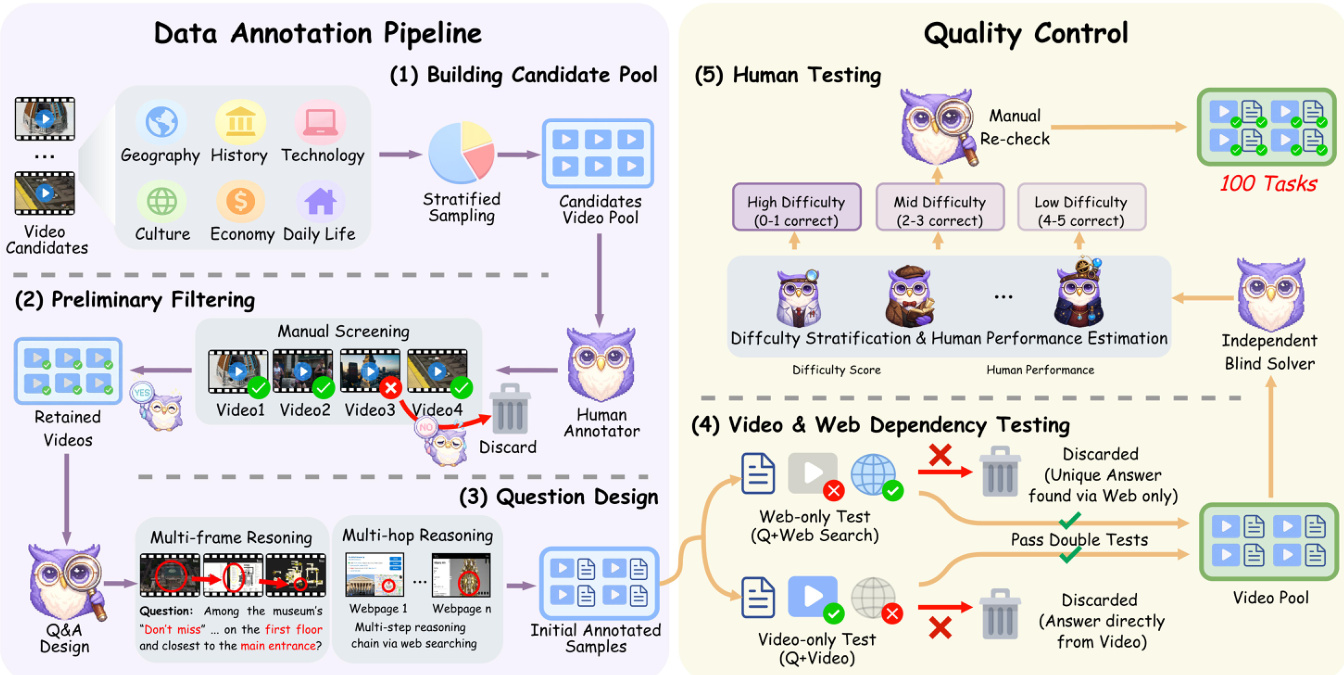
筛选后,流程进入问题设计阶段,采用两种不同的推理范式:多帧推理与多跳推理。多帧推理涉及生成需要理解视频中多帧间时间变化的问题,例如追踪物体运动或识别事件序列。多跳推理则要求整合来自视频与外部网络资源(如博物馆官网或游客指南)的信息,以回答复杂问题。这种双重方法确保了标注样本能够支持以视频为中心与以网络增强相结合的推理。
为确保标注数据的可靠性和有效性,实施了严格的两阶段质量控制流程。第一阶段为“视频与网络依赖性测试”,评估问题答案是否可仅从视频中得出,或是否必须依赖外部网络信息。仅允许需借助网络推理的视频保留,而可直接从视频提取答案的样本被剔除,从而确保数据集强调多跳推理。第二阶段为“人工测试”,由人工标注者评估每项任务的难度并预估人类表现。任务按预期正确回答数分为高、中、低三个难度等级,阈值分别为0–1、2–3、4–5个正确答案。该分层机制支持构建复杂度均衡的数据集。此外,对100个任务样本进行了人工复核,进一步验证标注质量与一致性。
实验
- 视频与网络依赖性测试:确认有效样本需同时依赖视频与网络证据,过滤后保留100个样本,剔除可通过仅视频或仅网络解决的样本。
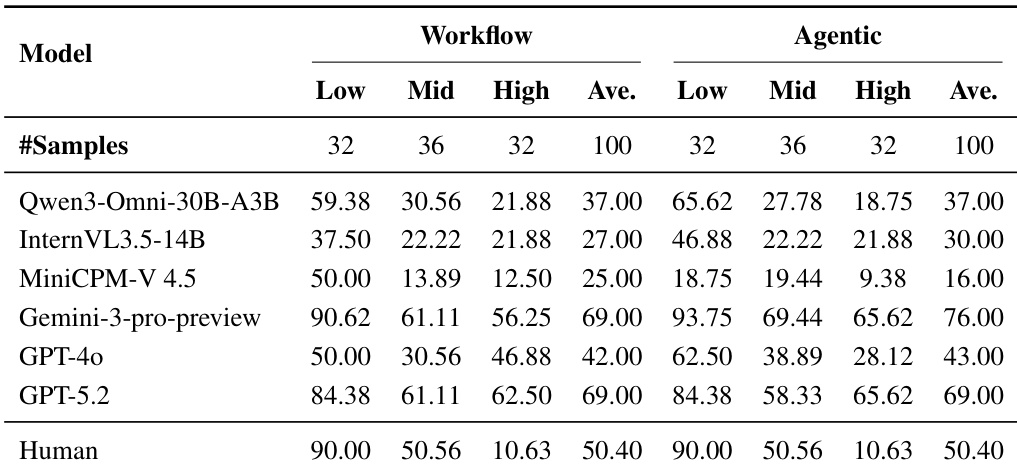
- 人工测试:人类参与者在所有样本上的平均成功率为50.4%,其中低难度为90.0%,中等难度为50.6%,高难度为10.6%,验证了难度分层与标注正确性。
- 主要结果:Gemini-3-pro-preview在工作流(69%)与代理(76%)设置下均领先,代理模式在中/高难度任务上对强模型有提升,但对中等模型(如GPT-4o)在高难度任务上造成性能下降。
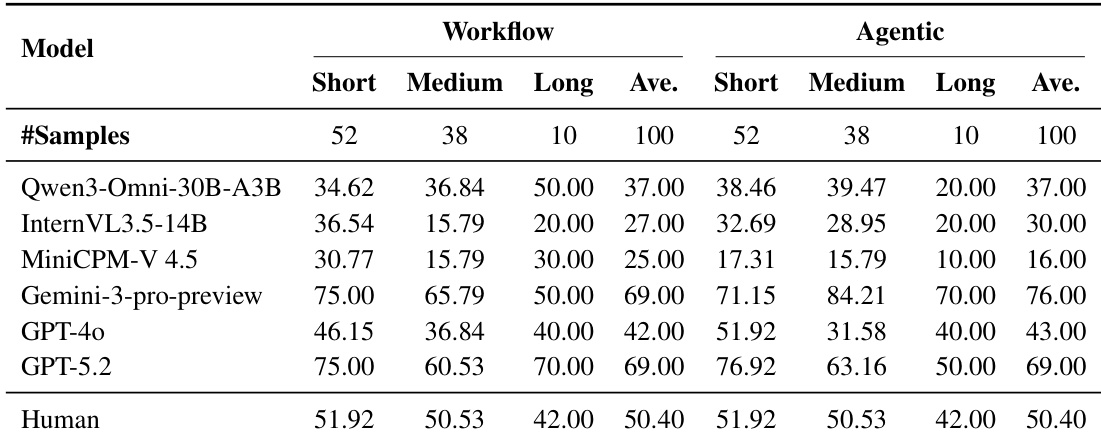
- 视频时长分层:更长视频放大了范式间的权衡——代理模式对强模型有益(如Gemini-3-pro-preview在长视频上从50%提升至70%),而弱模型(如Qwen3-Omni-30B-A3B)则显著下降(50%降至20%)。
- 领域分层:代理模式在科技领域表现优于工作流(64.29% → 85.71%),但在地理领域表现较差,表明稳定视觉锚点对模糊领域至关重要。
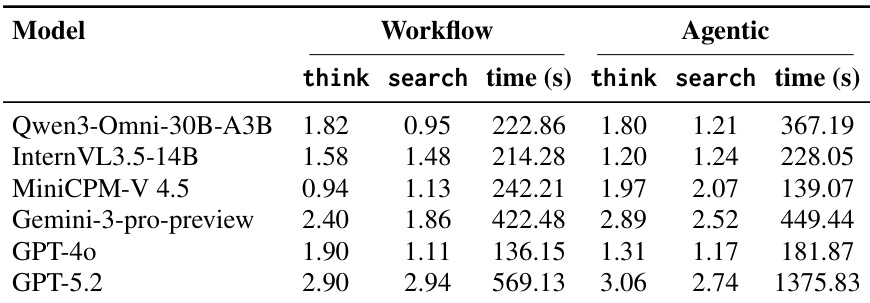
- 工具使用分析:工具调用频率与准确率无相关性;Gemini-3-pro-preview更高效地使用工具,而弱模型(如MiniCPM-V 4.5)工具使用增加但准确率下降,表明其证据过滤能力差。
- 错误分析:类别错误在各模型中占主导,尤其在代理模式下更为显著,源于早期感知错误未被纠正;数值错误在所有模型中持续存在,代理模式未带来显著改善。
研究者分析了各模型与设置下的错误类型,发现类别错误是主要失败模式,部分模型在代理设置下错误率上升。这表明,当模型无法回溯视频时,初始视觉感知错误更容易在下游推理中传播,导致更大程度的漂移。
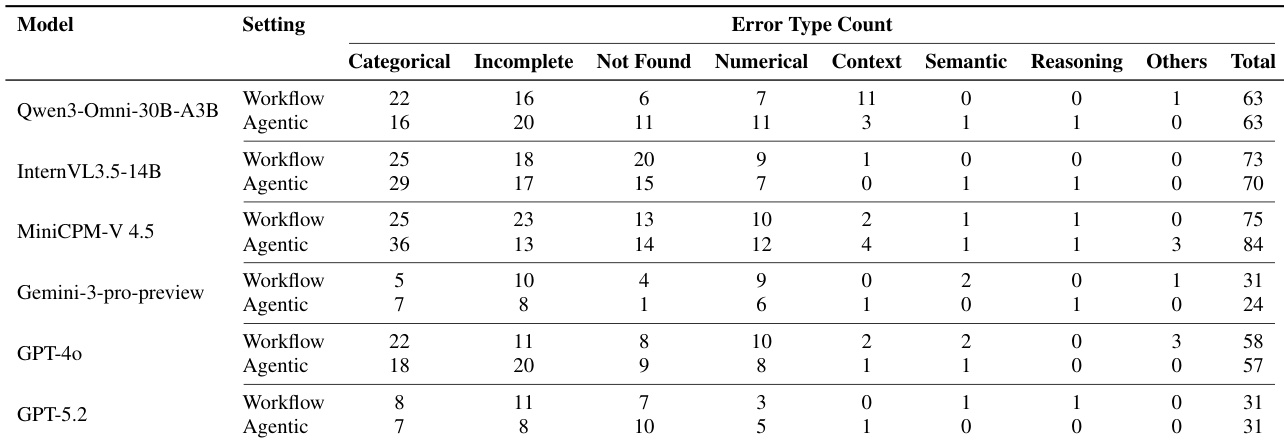
研究者分析了工作流与代理范式中的工具使用情况,发现工具调用次数更高并不必然带来更好性能。Gemini-3-pro-preview展现出更高效的工具使用,以适中的思维与搜索调用次数达到最高准确率,而其他模型即使增加工具使用,性能也未提升甚至下降。
结果表明,在工作流与代理范式下,模型性能随视频时长变化显著,Gemini-3-pro-preview在所有类别中均取得最高准确率。代理模式在长视频上普遍优于工作流,尤其对Gemini-3-pro-preview而言,其在长视频上的准确率从50.00%提升至70.00%,而开源模型如Qwen3-Omni-30B-A3B与MiniCPM-V 4.5在代理模式下长视频上的准确率则大幅下降。
研究者通过领域特定性能对比,评估了模型在不同问题类别下于工作流与代理设置中的表现。结果显示,Gemini-3-pro-preview在两种设置下多数领域均取得最高准确率,尤其在科技领域实现显著提升(64.29% → 85.71%),并在所有领域保持稳定高水平表现,而其他模型则表现出依赖领域与范式的强弱差异。

结果表明,对于Gemini-3-pro-preview与GPT-5.2等顶级模型,代理范式性能优于工作流范式,准确率分别提升7%与0%;而Qwen3-Omni-30B-A3B与MiniCPM-V 4.5等表现较弱的模型在代理模式下未见提升,甚至出现性能下降。两种范式下,随着难度增加,性能均显著下降,且人类表现始终高于所有模型,尤其在高难度样本上差距明显。