Command Palette
Search for a command to run...
BabyVision:超越语言的视觉推理
BabyVision:超越语言的视觉推理
摘要
尽管人类在掌握语言之前便已发展出核心视觉能力,当前的多模态大语言模型(MLLMs)仍严重依赖语言先验来弥补其脆弱的视觉理解能力。我们发现了一个关键事实:最先进MLLMs在人类(甚至3岁幼儿)能够轻松完成的基础视觉任务上,表现持续失败。为系统性地探究这一差距,我们提出了BabyVision——一个旨在评估MLLMs核心视觉能力、且不依赖语言知识的基准测试体系。BabyVision涵盖广泛的任务类型,共包含388个测试项,划分为四个核心类别下的22个子类别。实证结果与人工评估均表明,当前领先MLLMs的表现显著低于人类基准水平。例如,Gemini 3 Pro Preview模型仅获得49.7分,不仅落后于6岁儿童的平均水平,更远低于成年人类平均分94.1。这些结果表明,尽管在知识密集型评测中表现优异,现有MLLMs仍缺乏基本的视觉认知原语。BabyVision上的进展标志着向实现人类水平的视觉感知与推理能力迈出的重要一步。此外,我们进一步探索了利用生成模型解决视觉推理问题的路径,提出了BabyVision-Gen及配套的自动化评估工具包。相关代码与基准数据已开源,可通过 https://github.com/UniPat-AI/BabyVision 获取,以支持研究复现。
一句话摘要
来自UniPat AI、北京大学、清华大学及合作机构的作者提出了BABYVISION,一个评估多模态大语言模型核心视觉能力的基准,该能力独立于语言,揭示了即使顶级模型如Gemini3-Pro-Preview也远落后于6岁人类儿童;该工作引入了BABYVISION-GEN和自动化评估工具包,推动生成模型的视觉推理发展,标志着向人类级视觉感知迈出关键一步。
主要贡献
-
本文提出BABYVISION,一个包含388个样本、覆盖四个领域(细粒度区分、视觉追踪、空间感知、视觉模式识别)共22个子类别的基准,旨在评估多模态大语言模型(MLLMs)的核心视觉能力,且不依赖语言知识,揭示了当前模型与人类婴幼儿及儿童之间存在显著性能差距。
-
研究表明,最先进的多模态大语言模型(MLLMs),包括Gemini3-Pro-Preview,在BABYVISION上的准确率仅为49.7%,远低于人类基准(6岁儿童:约70%,成人:94.1%),暴露出尽管在语言密集型多模态任务中表现优异,但基础视觉原语仍存在严重缺陷。
-
为弥补视觉推理差距,作者提出BABYVISION-GEN,一种生成式评估框架,通过图像或视频生成评估视觉推理能力,并配套开发了自动化评估工具包,与人工判断一致性达96%,并证明生成模型在某些视觉任务上可超越MLLMs。
引言
当代多模态大语言模型(MLLMs)在数学推理和专家级问答等高阶知识密集型任务中表现出色,但在连3岁儿童无需语言即可解决的基础视觉推理任务上却持续失败。这一差距凸显了一个关键局限:当前模型缺乏在人类早期发展中自然涌现、且独立于语言知识的基础视觉原语——如物体追踪、空间感知和细粒度区分。以往基准大多聚焦于语义或专家级推理,未能系统评估这些前语言视觉能力,导致模型在真实世界感知中的鲁棒性被高估。
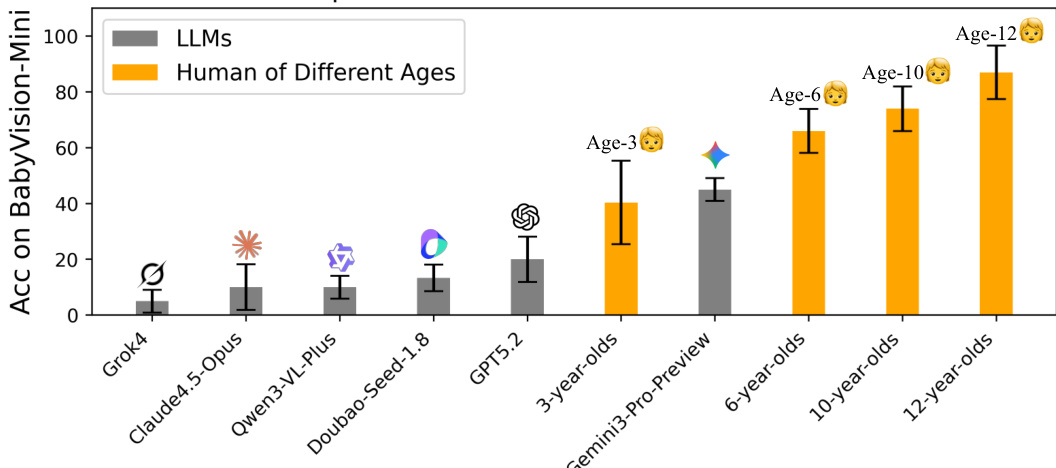
作者提出BABYVISION,一个严格设计的基准,用于在不依赖语言的前提下评估MLLMs的核心视觉推理能力。该基准包含四个领域共388个任务——细粒度区分、视觉追踪、空间感知、视觉模式识别——结构上模拟人类早期视觉发展过程。评估结果显示显著性能差距:最佳MLLM Gemini3-Pro-Preview仅得49.7%,而成人达94.1%,在追踪和空间推理方面存在重大失败,根源在于“语言化瓶颈”导致非可语言化视觉信息被丢弃。
为应对这一问题,作者提出BABYVISION-GEN,一种生成式扩展,通过图像或视频输出而非文本评估视觉推理,使模型能以视觉方式表达解决方案,如绘制路径或补全图案。同时开发了与人工判断一致率达96%的自动化评估工具包。实验表明,前沿生成模型如Sora-2和Nano-Banana-Pro展现出类人视觉思维,提示原生多模态架构——即直接在视觉空间中推理的架构——可能是实现真正具身视觉智能的关键。
数据集

- BABYVISION基准包含388个精心策划的视觉推理问题,旨在评估多模态大语言模型(MLLMs)的基础早期视觉能力,基于发展心理学构建,分为四个核心类别:细粒度区分(8个子类型)、视觉追踪(5个子类型)、空间感知(5个子类型)和视觉模式识别(4个子类型),共22个子类型。
- 数据集通过三阶段策划流程构建:(1) 分类体系定义与种子选择,手动挑选100张高质量种子图像,代表每个子类型;(2) 数据收集与过滤,利用反向图像搜索和关键词检索获取约4,000张候选图像,并严格过滤含文字、文化知识或不当内容的样本;(3) 标注与质量保障,由训练标注员创建问题与详细解题过程,随后进行双盲专家评审,确保答案具有视觉基础且无歧义。
- 最终数据集包含135道选择题(34.8%)和253道填空题(65.2%),平均长度25.9词,答案分布均衡,具有强视觉基础,防止语言捷径。
- 额外构建了1,400个样本的训练集,采用相同流程但扩大数据来源,用于研究训练对模型在BABYVISION上表现的影响。
- BABYVISION-GEN是面向生成任务的适配版本,包含280个问题,覆盖21个子类型(来自同一四类,排除一个不适用于视觉生成的子类型),每个实例包含原始图像、生成提示(平均22.9词)和基于三位人工标注员共识的参考解图。
- 评估采用严格标准:例如“找相同”中所有标记元素必须与真实答案完全一致;“迷宫”中路径必须完全一致;“数相同模式”中数量必须精确匹配。
- 作者使用BABYVISION数据集进行评估,重点测试视觉推理能力,而BABYVISION-GEN用于评估生成模型通过图像合成而非语言回答生成解决方案的能力。
方法
作者采用结构化的三阶段框架构建BABYVISION-GEN数据集,强调系统性分类体系构建、可扩展数据收集和严格质量控制。流程始于分类体系与种子收集阶段,基于教科书和视觉测试定义早期视觉任务范围。该阶段确立四个顶层类别和22个子类型,最终手动选取约50张种子图像,作为后续数据生成的基础范例。
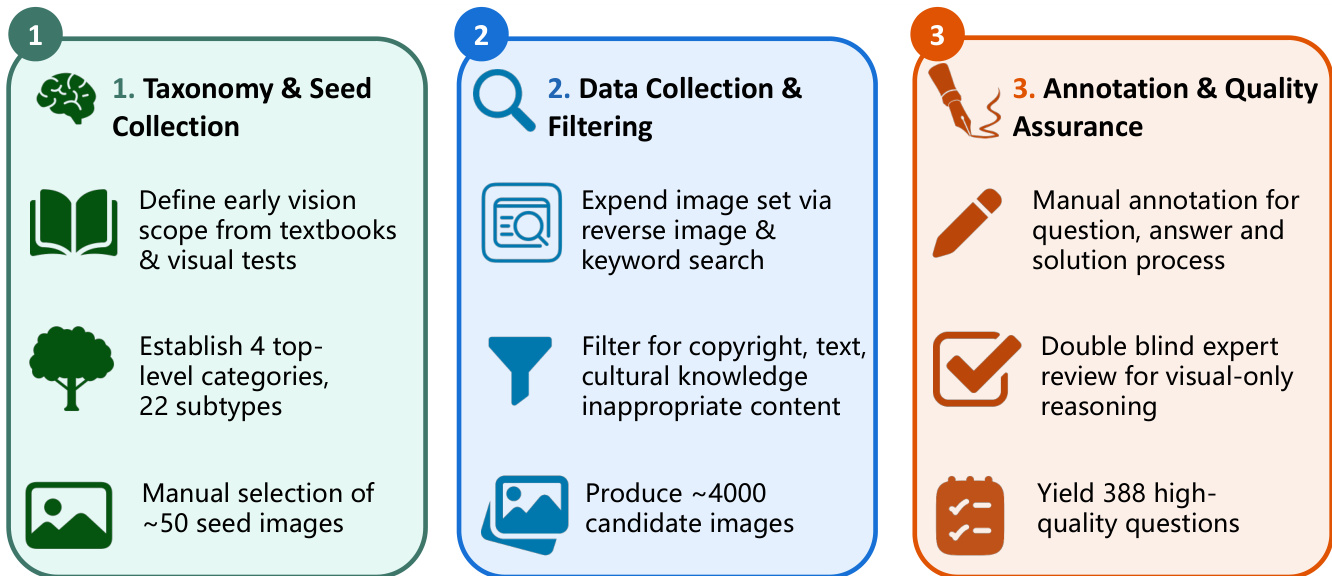
如图所示,第二阶段聚焦数据收集与过滤。通过反向图像搜索和关键词查询扩展图像集,生成大量候选图像。该原始集合经过过滤,剔除侵犯版权、含不当文字或涉及文化敏感内容的样本。最终获得约4,000张适合后续标注的候选图像。
最终阶段为标注与质量保障,确保数据集的可靠性和清晰性。每个问题、答案和解题过程均手动标注,保留原始图像上下文的同时,仅添加必要的视觉标记(如圆圈、线条、箭头或文本标签)以指示解法。针对纯视觉推理任务,采用双盲专家评审流程,确保标注准确且最小化。该阶段产出388个高质量问题,每个均配有精确的视觉解法。
实验
- 在BabyVision和BabyVision-GEN上评估11个前沿模型(5个专有模型,6个开源模型),使用标准化提示和LLM作为裁判的评估方式,结合Qwen3-Max和Gemini-3-Flash,BabyVision上与人工评估一致率达100%,BabyVision-GEN上达成96.1%的一致性。
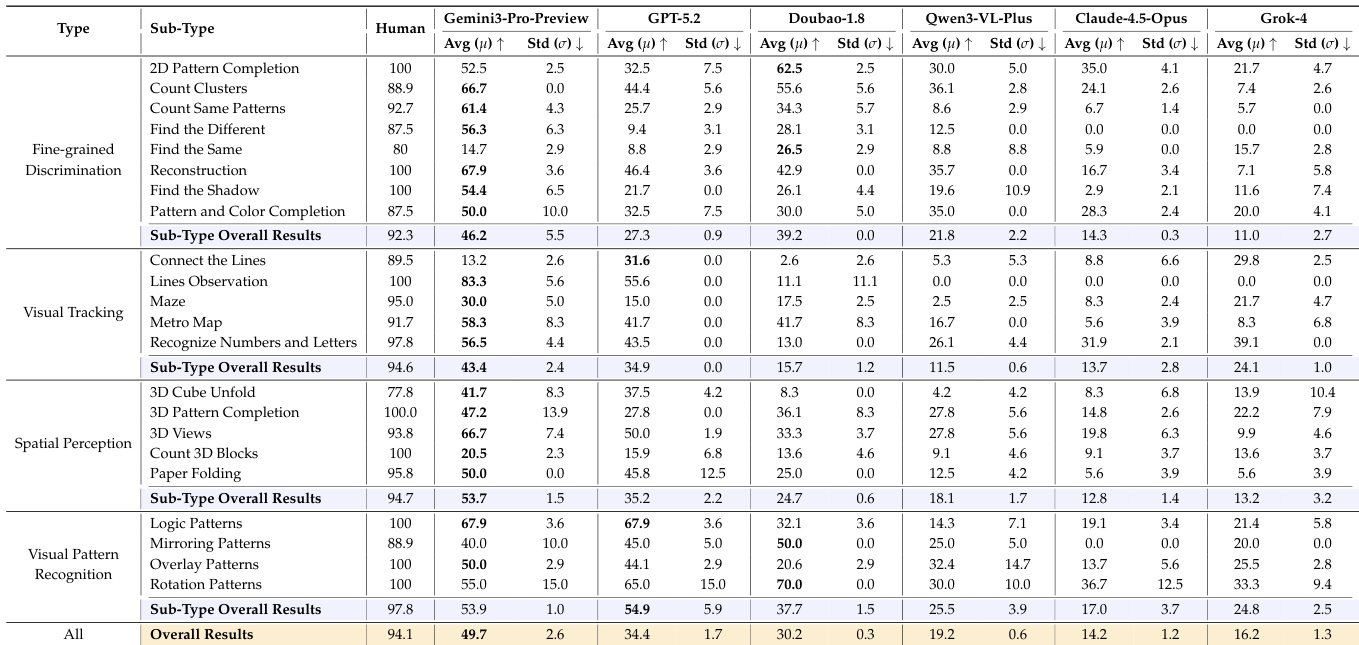
- 在BabyVision上,专有模型最高达49.7% Avg@3(Gemini3-Pro-Preview),远低于人类基准(94.1%),在细粒度区分(最佳:Find the Same任务中26.5%)、视觉追踪(Lines Observation任务中接近零)和3D空间感知(Count 3D Blocks任务中最佳20.5%)方面持续失败。
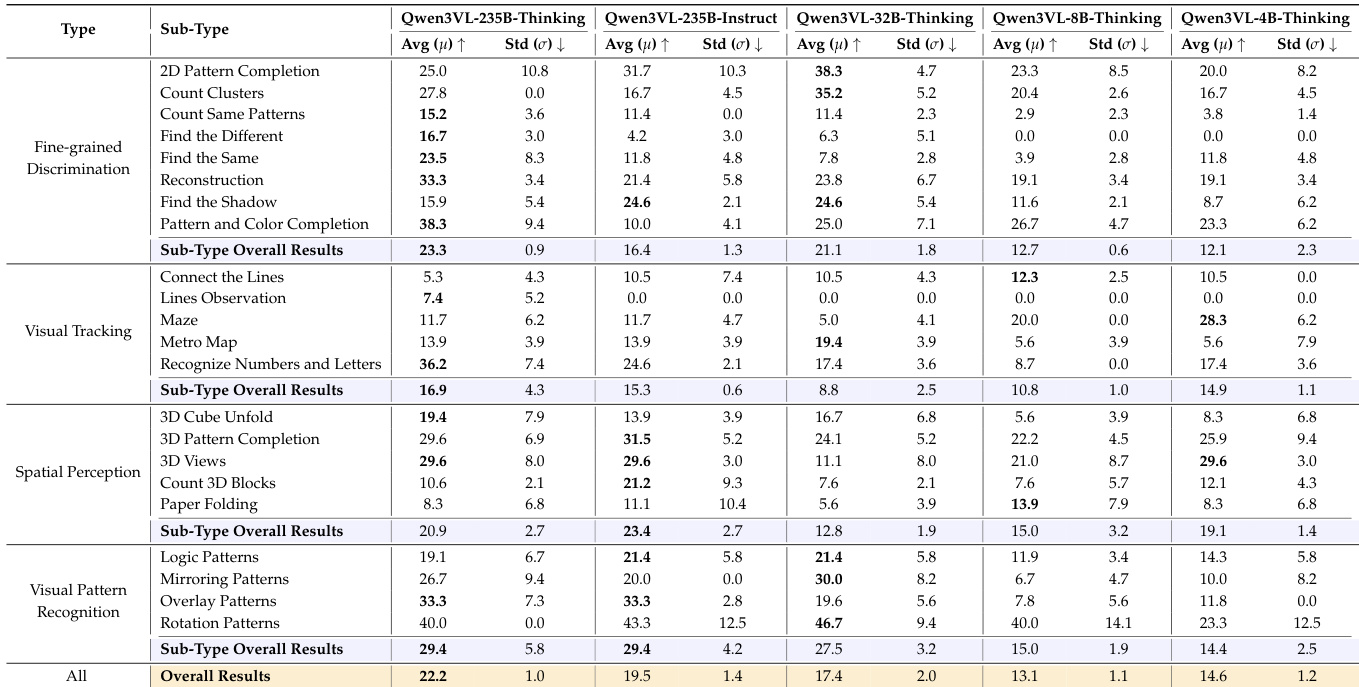
- 开源模型表现更低(最佳:Qwen3VL-235B-Thinking为22.2%),测试时思维(test-time thinking)相比Instruct变体带来可测量提升,但仍显著落后于专有模型。
- 模型规模扩展在Qwen3VL系列中提升性能(235B-Thinking:22.2% vs. 4B-Thinking:14.6%),但提升非单调,表明单纯扩大规模对早期视觉任务存在局限。
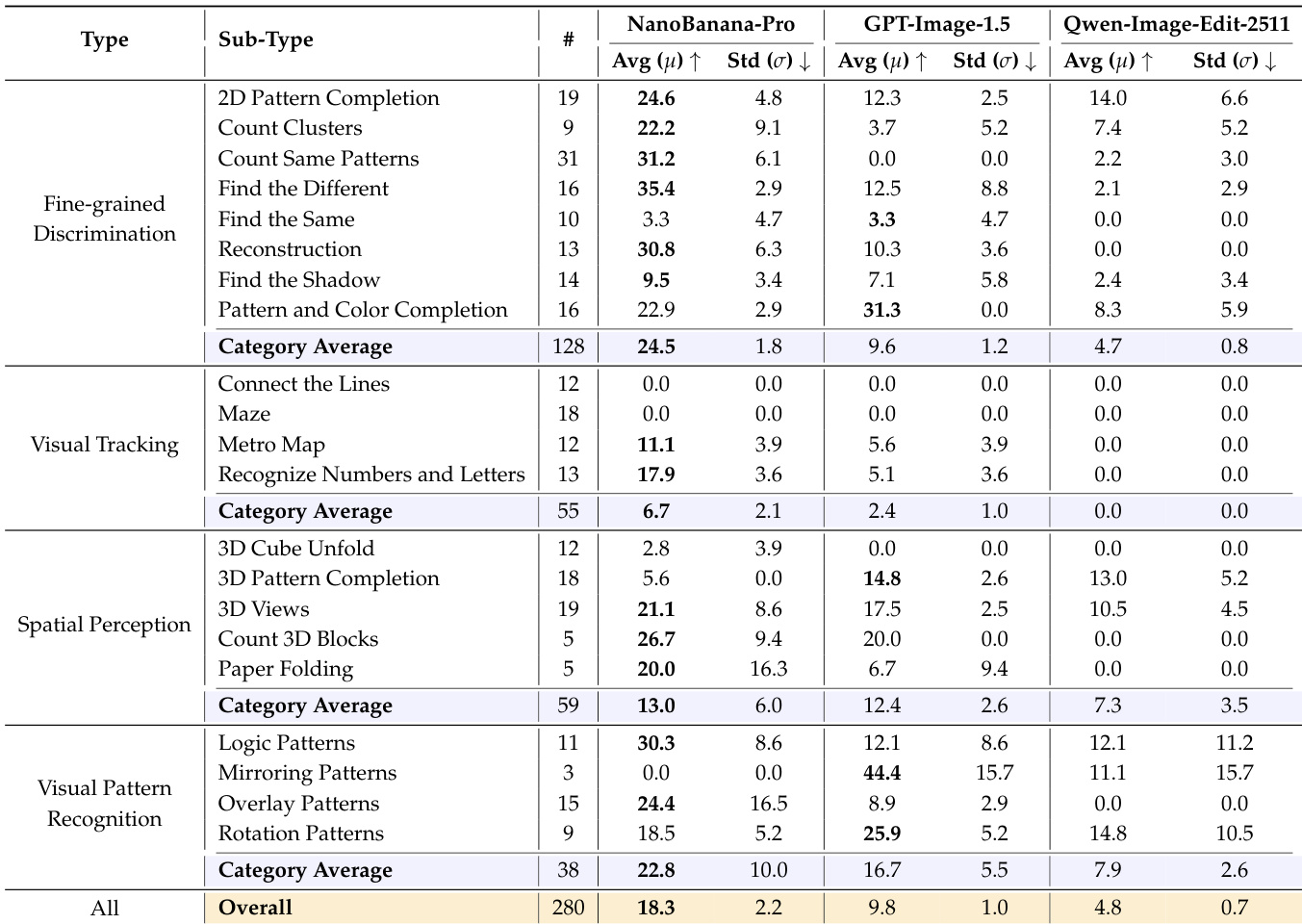
- 在BabyVision-GEN上,NanoBanana-Pro达到18.3%准确率,优于GPT-Image-1.5(9.8%)和Qwen-Image-Edit(4.8%),在细粒度区分(24.5%)和视觉模式识别(22.8%)上表现良好,但在视觉追踪任务(Maze、Connect the Lines)上准确率接近零。
- 对Qwen3-VL-8B-Thinking进行RLVR微调后,BabyVision整体准确率提升+4.8分,多数子类型均有增益,但视觉追踪提升有限,凸显基于语言推理中连续感知追踪的挑战。
- 定性分析揭示“语言化瓶颈”:MLLMs在需要非语言、细粒度视觉感知、多对象身份追踪、3D空间想象和视觉模式归纳的任务中失败,根源在于视觉信息向语言的有损压缩。
作者在BABYVISION-GEN基准上评估三种视觉生成模型,NanoBanana-Pro以18.3%的总体准确率位居第一,显著优于GPT-Image-1.5(9.8%)和Qwen-Image-Edit(4.8%)。结果表明,所有模型在需要连续空间追踪的任务(如迷宫导航、连线追踪)上表现极差,准确率降至0%,而在细粒度区分和视觉模式识别子类型上表现较强。
作者通过对比人工判断评估其自动化评估方法在BABYVISION-GEN上的可靠性。结果显示,自动裁判与人工评估在96.1%的实例上达成一致,F1分数高达0.924,表明两种评估方式具有高度一致性。

作者采用统一提示模板和LLM作为裁判的评估方式,评估模型在BabyVision基准上的表现,结果显示专有模型如Gemini3-Pro-Preview得分最高,但仍显著低于人类表现。表格显示,无模型在所有子类型上持续超越人类,最大差距出现在细粒度区分和视觉追踪任务,表明基础视觉推理仍面临持续挑战。
作者使用表格比较不同Qwen3VL模型在各类视觉推理任务中的表现,重点关注模型规模和推理模式的影响。结果显示,Thinking变体在相同规模下始终优于Instruct变体,且性能通常随模型规模提升,但4B-Thinking模型略优于8B-Thinking模型,表明存在非单调的缩放效应。
作者使用BabyVision基准评估大语言模型(LLMs)的视觉推理能力,并与不同年龄组的人类表现进行对比。结果显示,即使表现最佳的LLM Gemini3-Pro-Preview,准确率也仅为44.1%,显著低于6岁儿童的表现,远未达到12岁儿童94.1%的准确率。