Command Palette
Search for a command to run...
ArenaRL:通过基于锦标赛的相对排名实现开放式智能体的强化学习扩展
ArenaRL:通过基于锦标赛的相对排名实现开放式智能体的强化学习扩展
摘要
强化学习在可验证结果的任务上显著提升了大语言模型(LLM)智能体的性能,但在开放性任务(如复杂旅行规划)中仍面临挑战,这类任务具有庞大的解空间且缺乏客观的真值标准。由于缺乏明确的评判基准,当前的强化学习算法主要依赖于奖励模型,对单个响应分配标量分数。我们指出,这种逐点评分机制存在固有的“优势坍缩”问题:奖励模型难以区分不同轨迹之间的细微优势,导致同一组内各轨迹的得分被压缩至极窄范围。结果,有效奖励信号被奖励模型引入的噪声所主导,进而引发优化过程的停滞。为解决这一问题,我们提出ArenaRL——一种从逐点标量评分转向组内相对排序的强化学习范式。ArenaRL引入了一种过程感知的成对评估机制,采用多层级评分标准,为不同轨迹分配细粒度的相对分数。此外,我们构建了一个组内对抗性竞技场,并设计了一种基于锦标赛的排名机制,以获取稳定的优势信号。实证结果表明,所构建的种子单淘汰赛制在仅需O(N)复杂度的情况下,即可达到与全成对比较(O(N²)复杂度)几乎相当的优势估计精度,实现了效率与精度之间的最优平衡。为进一步弥补开放性智能体缺乏全周期评估基准的不足,我们构建了两个高质量基准数据集:Open-Travel与Open-DeepResearch。这两个基准均具备覆盖监督微调(SFT)、强化学习训练及多维度评估的完整流程。大量实验表明,ArenaRL显著优于标准强化学习基线方法,使LLM智能体能够生成更稳健、更可靠的解决方案,有效应对复杂现实任务。
一句话总结
通义实验室与阿里地图(Amap)团队提出ArenaRL,一种新颖的强化学习框架,通过过程感知的成对评估与基于锦标赛的方案,将点对点标量奖励替换为组内相对排名,在实现高效 O(N) 优势估计的同时,克服了复杂旅行规划等开放任务中的判别崩溃问题,并在新提出的Open-Travel与Open-DeepResearch基准上展现出卓越性能。
主要贡献
-
开放式大语言模型(LLM)代理任务(如复杂旅行规划)缺乏客观的真值奖励,迫使现有强化学习方法依赖LLM裁判给出的点对点标量评分,但该方法易出现判别崩溃——即相似轨迹获得几乎相同的分数,因奖励噪声过高而掩盖了有意义的性能差异。
-
ArenaRL通过引入从点对点评分到组内相对排名的范式转变,采用过程感知的多层级评分标准进行成对评估,并结合基于锦标赛的排名机制,在仅 O(N) 复杂度下实现接近最优的准确性,显著优于 O(N2) 的全成对比较。
-
该框架在新基准Open-Travel与Open-DeepResearch上进行了验证,这些基准包含完整训练周期与多维度评估流程,结果表明ArenaRL能显著提升代理行为的逻辑严谨性与鲁棒性,大幅超越标准RL基线(如GRPO与GSPO)。
引言
强化学习(RL)在数学与代码等可验证结果的任务中推动了大语言模型(LLM)代理的发展,但在旅行规划或深度研究等开放现实问题中仍面临挑战,因解空间庞大且正确性具有主观性。以往方法依赖LLM作为裁判分配点对点标量奖励,但导致判别崩溃——高质量轨迹因奖励模型噪声与判别能力有限而获得几乎相同的分数,造成优化无效。为克服此问题,作者提出ArenaRL,一种基于锦标赛的强化学习框架,将点对点评分替换为组内相对排名。ArenaRL采用过程感知的成对评估机制与多层级评分标准,评估推理过程、工具使用与最终结果,并引入种子单淘汰锦标赛,仅以 O(N) 复杂度实现接近最优的排名准确率,从而实现高效稳定的优劣势估计。作者进一步提出Open-Travel与Open-DeepResearch两个全周期基准,集成SFT、RL训练与多维度评估流程,支持开放代理的可复现研究。实验表明,ArenaRL在复杂真实任务中显著优于基线,在逻辑严谨性与鲁棒性方面表现突出。
数据集

- 数据集涵盖两个领域:Open-Travel与Open-DeepResearch,通过三阶段流程构建,模拟真实业务场景。
- Open-Travel包含五个子任务:Direction(多点位路线规划)、1-Day(一日城市游)、Compare(交通方式对比)、Search(周边POI发现)与M-Day(多日行程规划),其中M-Day子任务未用于SFT训练。
- Open-DeepResearch聚焦开放研究任务,如技术文档撰写、研究创意生成与概念总结,需多轮工具调用与信息整合。
- 训练数据来源于真实业务查询及LLM生成的多样化扩展(如Qwen3、Qwen3-Max),共生成2,600个SFT样本(Open-Travel)与2,662个(Open-DeepResearch),以及1,626与2,216个RL样本。
- 测试集包含250个人工精心筛选的Open-Travel样本与100个Open-DeepResearch样本,选样标准为清晰性、多样性与难度,并经领域专家验证。
- 基线轨迹通过高性能闭源模型生成,作为胜率比较的参考基准。
- 所有轨迹均通过LLM驱动的质量控制流程,结合规则增强检查,评估工具使用有效性、对话正确性与答案一致性,失败案例进行迭代优化。
- Open-Travel中六项工具被标注:search_poi、around_search、get_navigation、universal_search、search_flights与search_train_tickets,通过高德地图API实现并辅以模拟航班/火车数据。
- Open-DeepResearch中使用Google API进行网络搜索,内容超过2,500字符时自动由Qwen3-Max摘要,以控制上下文长度。
- 作者利用SFT数据训练模型掌握工具调用、意图理解与多步推理能力,而RL样本用于在真实约束下优化开放代理行为。
- 数据集覆盖旅行之外的多个领域,包括体育、医疗与专业场景,支持通用代理能力的评估。
方法
作者提出一种新颖的强化学习框架ArenaRL,以应对开放任务中点对点标量奖励的不稳定性。该方法核心在于用组内相对排名机制替代传统的标量奖励信号,通过评估组内轨迹的相对质量,缓解判别崩溃问题。整体框架如图所示,包含两个主要阶段:冷启动阶段,代理通过与环境交互生成轨迹;ArenaRL驱动的在线相对排名优化阶段,迭代优化策略。
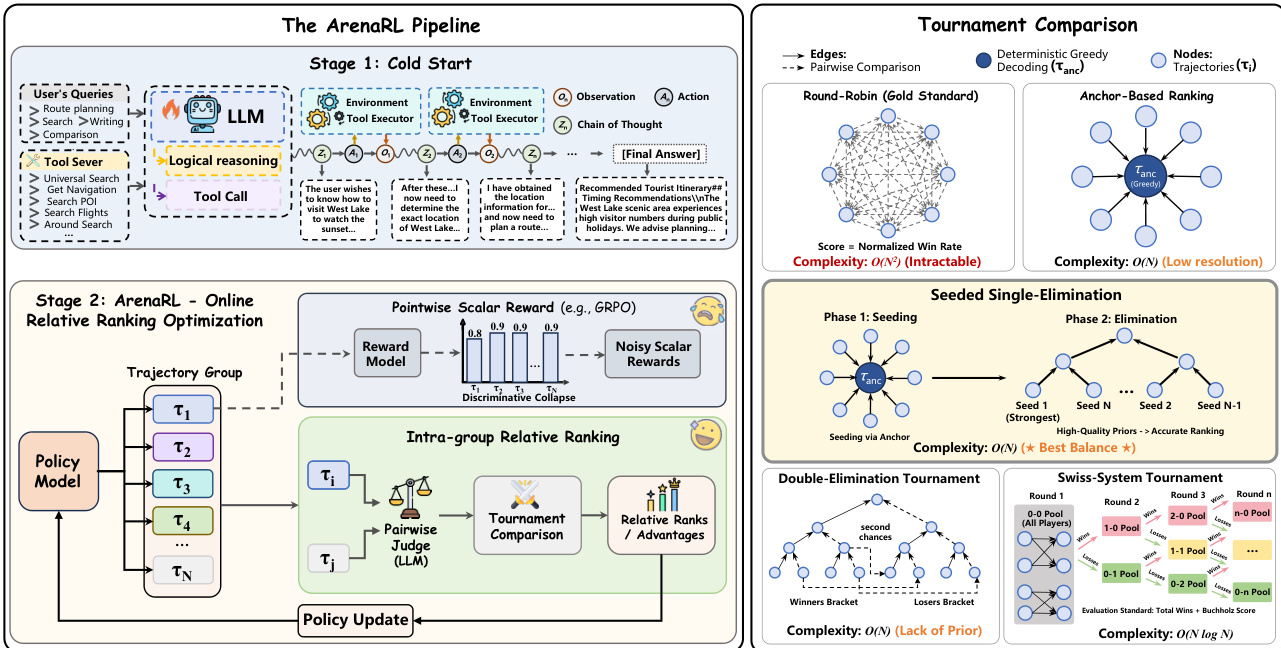
在ArenaRL中,首先从当前策略 πθ 中采样一组轨迹 G={τ1,τ2,…,τN}。这些轨迹的质量通过一个过程感知的成对评估机制进行评估,该机制由基于LLM的Arena裁判实现。该裁判联合评估两条轨迹 τi 与 τj,依据全面评分标准,审查思维链的逻辑一致性、工具调用的精确性以及最终答案的可靠性。为缓解位置偏差,采用双向评分协议:轨迹在两种顺序下分别评估,得分相加。
框架系统性地研究了五种不同的锦标赛拓扑结构,以平衡计算效率与优势估计的准确性。循环赛(Round-Robin)对每条轨迹与其他所有轨迹进行比较,是排名保真度的黄金标准,但具有 O(N2) 的计算复杂度,难以处理。为实现线性复杂度 O(N),作者引入基于锚点的排名机制(Anchor-Based Ranking),即用一条确定性参考轨迹(锚点)与所有其他探索轨迹比较。然而,该方法在次优解之间的排名分辨率较低。为弥合这一权衡,作者提出种子单淘汰锦标赛(Seeded Single-Elimination),一种混合拓扑结构,分两阶段运行。第一阶段使用基于锚点的排名生成高质量初始种子,对防止高质量轨迹过早碰撞至关重要;第二阶段基于这些种子构建二叉锦标赛树,合理安排对战顺序以确保公平竞争。最终排名由在淘汰赛中的存活深度决定,同层级平局则通过前序比赛的累积平均分解决。

种子单淘汰拓扑被确定为最优选择,在准确率与效率之间取得最佳平衡。每条轨迹的排名被转换为归一化的优势信号用于策略优化。该过程包括:将离散排名映射为基于分位数的奖励,对组内奖励进行标准化,再使用裁剪目标函数更新策略。最终优化目标包含KL散度惩罚项,防止策略过度偏离参考策略,确保稳定有效的策略更新。种子单淘汰锦标赛的详细流程见算法1,形式化描述了种子生成、淘汰、排名与优势计算步骤。
实验
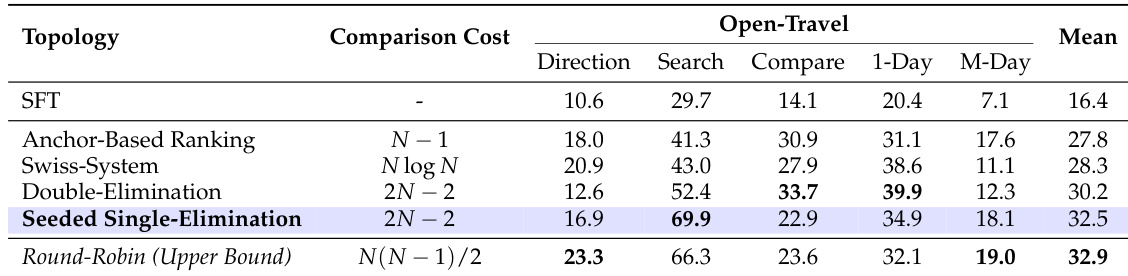
- 在Open-Travel上评估五种锦标赛拓扑(种子单淘汰、循环赛、瑞士制、双淘汰等),结果显示种子单淘汰平均胜率32.5%,与循环赛(32.9%)相当,但仅需 O(N) 复杂度,验证其高效性与有效性。
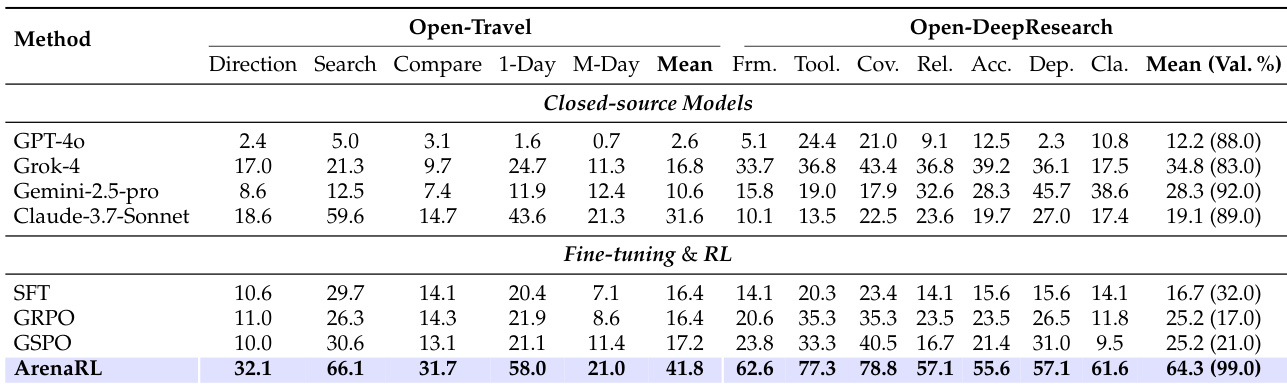
- 在Open-Travel上,ArenaRL平均胜率达41.8%,超越GPT-4o、Grok-4、Gemini-2.5-pro、Claude-3.7-Sonnet、GRPO(16.4%)与GSPO(17.2%)。
- 在Open-DeepResearch上,ArenaRL胜率64.3%,有效生成率达99%,显著优于基线(SFT模型仅32%有效生成率),凸显其在长周期、上下文敏感任务中的鲁棒性。
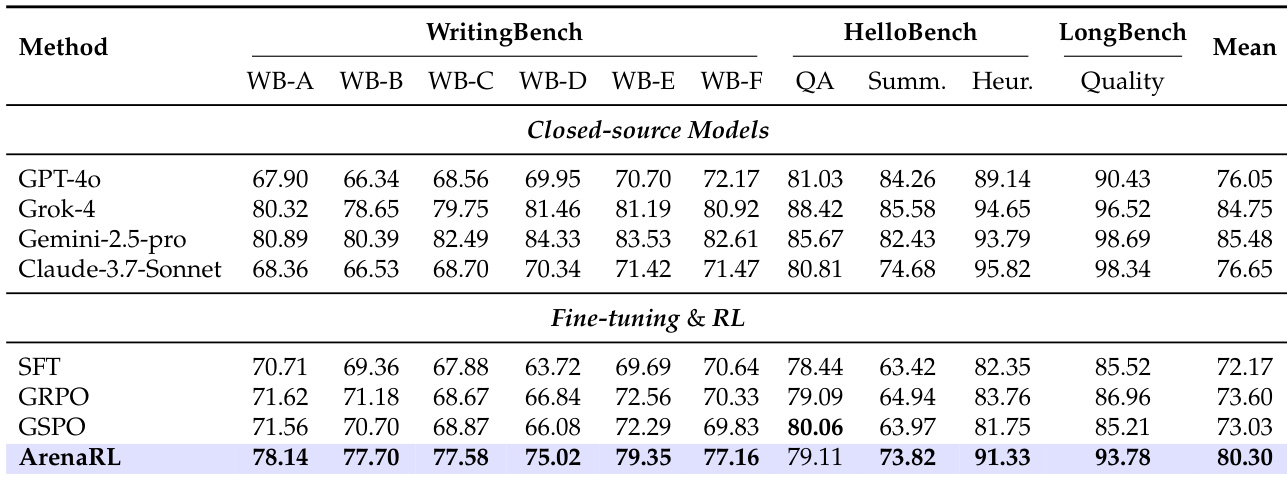
- 在三个公开开放写作基准(WritingBench、HelloBench、LongBench-write)上,ArenaRL胜过GRPO 6.70%、GSPO 7.27%,并超越GPT-4o与Claude-3.7-Sonnet,证明其在非代理任务中的广泛适用性。
- 在高德地图(Amap)真实数据上的评估显示,ArenaRL在确定性POI任务中搜索准确率提升75–83%,核心业务指标从69%提升至80%,证实其实际有效性。
- 消融实验表明,增大组大小(N)可单调提升性能,N=16时在Open-Travel上达到41.8%胜率;无冷启动的直接RL训练从0%迅速提升至71%(Search子任务),证明其自进化能力。
- LLM评估与人类判断的一致性达73.9%,表明性能提升可靠且符合人类认知。案例研究显示,ArenaRL生成连贯、约束感知且个性化的旅行计划,而基线模型输出则趋于通用或偏离需求。
作者使用ArenaRL在Open-Travel与Open-DeepResearch基准上评估其性能,对比闭源模型与强化学习基线。结果表明,ArenaRL在Open-Travel上取得最高平均胜率41.8%,在Open-DeepResearch上胜率64.3%、有效生成率99%,两项指标均全面超越其他方法。
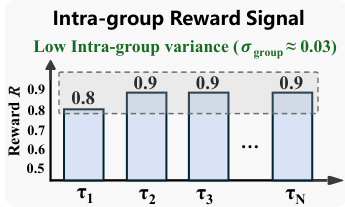
作者采用基于锦标赛的框架评估组内奖励信号的稳定性,结果显示不同组间的奖励方差始终保持极低(σ_group ≈ 0.03)。结果表明,奖励值在初始组后稳定在约0.9,说明排名机制为策略优化提供了可靠且一致的反馈。
作者使用Open-Travel与Open-DeepResearch数据集评估ArenaRL,训练集包含SFT与RL数据,测试集分别为250与100个样本。数据集设计支持多语言旅行规划与通用开放研究评估,其中Open-DeepResearch支持中文与英文双语。

作者采用基于锦标赛的评估框架,在Open-Travel基准上比较五种不同锦标赛拓扑,通过子任务与整体平均胜率衡量性能。结果表明,种子单淘汰方案取得最高平均胜率32.5%,优于其他格式,接近计算成本高昂的循环赛表现,同时大幅减少成对比较次数。
作者使用ArenaRL在三个公开开放写作基准上评估其性能。结果表明,ArenaRL取得最高平均分80.30,超越所有闭源模型与微调基线,在多数子任务中表现优异,尤其在HelloBench-Heur与LongBench-Quality类别中提升显著。