Command Palette
Search for a command to run...
思维的分子结构:长链思维推理拓扑结构的映射
思维的分子结构:长链思维推理拓扑结构的映射
摘要
大型语言模型(LLMs)在模仿人类或非长链思维(Non-Long-CoT)LLM的推理过程时,往往难以习得有效的长链思维(Long CoT)推理能力。为深入理解这一现象,我们提出:有效的、可学习的Long CoT推理轨迹在统一视角下呈现出类似分子的稳定结构,这些结构由三种相互作用类型共同构成:深度推理(类共价键)、自我反思(类氢键)与自我探索(类范德华力)。对提炼出的推理轨迹进行分析表明,此类结构源于Long CoT微调过程,而非简单的关键词模仿。我们引入“有效语义异构体”(Effective Semantic Isomers)概念,并发现唯有促进熵快速收敛的连接关系才能支撑稳定的Long CoT学习,而结构间的竞争关系则会损害训练效果。基于上述发现,我们提出Mole-Syn——一种基于分布迁移图(distribution-transfer-graph)的方法,用于引导生成高效的Long CoT结构,在多个基准测试中显著提升了模型性能与强化学习(RL)的稳定性。
一句话总结
字节跳动种子中国、哈尔滨工业大学LARG、北京大学及合作机构提出MOLE-SYN,一种分布转移图方法,通过三种交互类型——深度推理、自我反思和自我探索——合成稳定、类分子的长链思维(Long CoT)推理结构,实现更快的熵收敛速度,并在多个基准测试中提升推理性能与强化学习稳定性。
主要贡献
-
大型语言模型(LLM)中的长链思维(Long CoT)推理难以从人类或较弱LLM有效迁移,尽管输出格式表面相似,但推理结构不稳定且不可学习,凸显了超越简单模仿的深层结构理解的必要性。
-
作者引入分子类比,指出稳定的Long CoT推理源于三种交互类型——深度推理(类共价键)、自我反思(类氢键)和自我探索(类范德华力),并识别出“有效语义异构体”,其键分布可实现快速熵收敛与鲁棒学习,而结构不兼容则导致不稳定。
-
MOLE-SYN是一种分布转移图方法,通过上述原则引导键的形成,合成有效的Long CoT结构,在GSM8K和AQuA-RAT等基准测试中表现出更优性能与强化学习稳定性,其有效性通过从强教师模型蒸馏验证。
引言
大型语言模型(LLMs)在通过思维链(CoT)提示实现多步推理方面展现出潜力,但难以从零开始构建稳健的长链推理(Long CoT),尤其在依赖弱指令微调模型或人工生成推理路径时。先前方法如监督微调和从低质量或随机采样示例中蒸馏,往往无法在长推理轨迹中保持连贯性,也难以泛化至新任务。作者提出一种新框架,将Long CoT建模为类分子结构,其中推理步骤为概念节点,其交互为具有特定分布特性的“键”。研究证明,从高质量推理模型蒸馏能有效传递稳定的Long CoT结构,而表面相似的推理模式——作者称之为语义异构体——因键配置不兼容,可能导致性能脆弱甚至崩溃。核心贡献在于指出,有效的Long CoT学习不仅依赖正确推理步骤的存在,更依赖于自我反思与探索等推理行为的精确分布与对齐,这些必须在训练中保持,才能实现类人般的连贯性与适应性。
数据集
- 数据集源自原始SFT语料库,新增两个子集以支持自我探索任务。
- 两个子集保持与原始数据相同的底层轨迹与标签,保留问题类型、答案格式和轨迹长度的分布。
- 子集通过特定关键词和短语构建,以促进内省式推理,如“也许”、“可能”、“让我们”、“考虑”、“探索”、“假设”和“如果”,引导自主思考。
- 这些关键词用于过滤和重构提示,促进反思性与探索性对话模式。
- 作者在训练中以混合比例使用该数据集,结合其他任务特定数据,增强模型进行自我探索的能力。
- 未进行裁剪,而是保留完整轨迹以维持上下文与推理深度。
- 围绕自我探索关键词的出现频率构建元数据,支持对模型输出中内省行为的细粒度分析。
方法
作者提出一种受分子启发的框架,用于理解与合成大型语言模型(LLMs)中有效的长链思维(Long CoT)推理。该框架将Long CoT建模为由三种不同交互类型(即“键”)构成的宏观分子结构,共同确保推理稳定性。核心组件包括深度推理、自我反思与自我探索。深度推理充当共价键,通过建立连续推理步骤间的强直接依赖,形成主要逻辑主干,如延伸推理链。自我反思相当于氢键,建立长程校正连接,将推理链折叠回先前步骤以测试一致性,防止漂移。自我探索类比范德华力,实现弱而短暂的关联,使模型能探测新的逻辑可能性并分支至替代路径,而无需立即确定单一结论。该分子结构与以往以节点为中心的视图(如链式或树状结构)形成对比,后者无法捕捉这些行为之间的全局稳定交互。作者将其形式化为行为导向图 G=(V,E),其中节点代表推理步骤,边标记为三种主要行为之一:深度推理 (D)、自我反思 (R) 或自我探索 (E)。整体结构的稳定性由这些键的分布与排列决定,仅特定配置——称为“有效语义异构体”——支持稳定学习。 
模型的学习过程通过注意力能量进行分析,该能量源自Transformer的注意力机制。作者将令牌对的注意力能量 Eij 定义为预Softmax logits的负值,即 Eij=−sij=−dkqi⊤kj。该能量值与注意力权重呈反比,即能量越低,连接越强、越可能。通过分析不同键类型下的能量分布,作者发现一致的排序:深度推理键能量最低,其次为自我反思,自我探索键能量最高。该排序得到实证分析与理论证明支持,后者基于旋转位置编码(RoPE)假设,表明键的期望能量是其所连接令牌间相对距离的函数。这一能量层级至关重要,因为注意力机制遵循玻尔兹曼分布,天然偏好低能量跃迁。因此,依赖深度推理与自我反思键的路径被指数级更可能被选择,有效引导模型偏向稳定、低能量的推理结构。 
为合成这些有效的Long CoT结构,作者提出MOLE-SYN,一种分布转移图方法。该框架首先从强推理教师模型估计行为转移图。不同推理行为间的转移概率 P(b′∣b) 从高质量Long CoT轨迹语料库中计算得出。该图随后用于引导新推理轨迹的合成。合成过程是在该转移图上的随机游走,模型根据当前推理状态生成步骤,提示中明确指定行为(如“你现在应进行探索行为”)。该方法将结构行为分布的迁移与文本表面形式解耦,实现从零生成匹配目标行为模式的Long CoT数据。该方法专为指令微调LLM设计,可在无需直接从强大教师模型蒸馏的情况下诱导复杂推理结构。 
每种键的塑造作用进一步通过语义空间中的几何与动态指标进行分析。深度推理被证明能密化核心逻辑结构,相比基线,嵌入空间中最小覆盖球体积减少22%,表明形成了紧密、稳定的逻辑主干。自我反思作为稳定器,通过“折叠”结构,巩固疏水核心并抑制不一致分支,使系统体积从35.2降至31.2。自我探索则扩展搜索空间,体积从23.95增至29.22,允许更广泛探索,但以即时稳定性为代价。该过程类比于蛋白质折叠:深度推理形成一级结构,自我探索探索构象空间,自我反思驱动系统向稳定、低能量的天然态演化。作者还通过分析信息流与元认知振荡量化该过程动态,模型在高熵探索与低熵验证状态间交替,不同推理键的出现频率对应于这些状态。 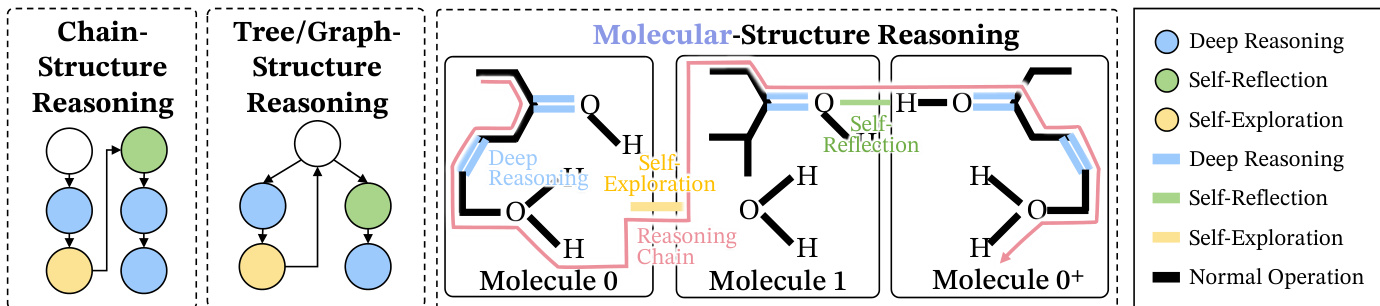
作者还研究了监督微调(SFT)的学习过程。他们认为SFT并非学习表面关键词,而是学习底层推理结构。这通过稀疏自编码器分析得以证明,显示Long CoT行为集中于少数话语控制结构中,由连接词如“也许”或“但是”激活的特征专门用于管理特定推理行为。关键词操控实验进一步支持该观点,显示在关键词被替换或移除的训练数据上,只要底层推理行为保持完整,模型仍能达到与原始数据训练相当的推理性能。这表明模型能力由推理行为的分布决定,而非特定词汇线索。 
推理步骤的标注过程通过一组定义与提示进行形式化。一条Long CoT轨迹为步骤序列 τ=(u1,…,uT),其中每个步骤 ut 为文本单元。作者定义三种主要行为:深度推理 (D) 是通过非平凡推理扩展推理链的转移;自我反思 (R) 是对模型自身推理过程进行评论或审计的转移;自我探索 (E) 是分支至替代假设的转移。最后一类为常规操作 (N),涵盖常规推进。为实现自动化标注,作者提供详细提示与专家标注员的决策规则,根据行为风格而非正确性将当前步骤归入上述类别之一。输出格式严格定义以确保一致性。
Long CoT过程的分析被框架化为寻找稳定、低能量配置。作者假设学习过程旨在最小化整体注意力能量。该过程通过将轨迹级平均能量分解为各行为平均值的加权和来形式化,权重为各行为的平稳频率。在温和遍历性假设下,各行为的经验频率收敛至其平稳概率。模型的注意力机制遵循玻尔兹曼分布,指数偏好低能量跃迁。因此,若深度推理与自我反思行为的平均能量与自我探索行为之间存在足够差距,模型将天然偏向稳定、低能量的推理结构。这为某些键配置可学习且稳定,而其他配置不可行提供了机制性解释。
实验
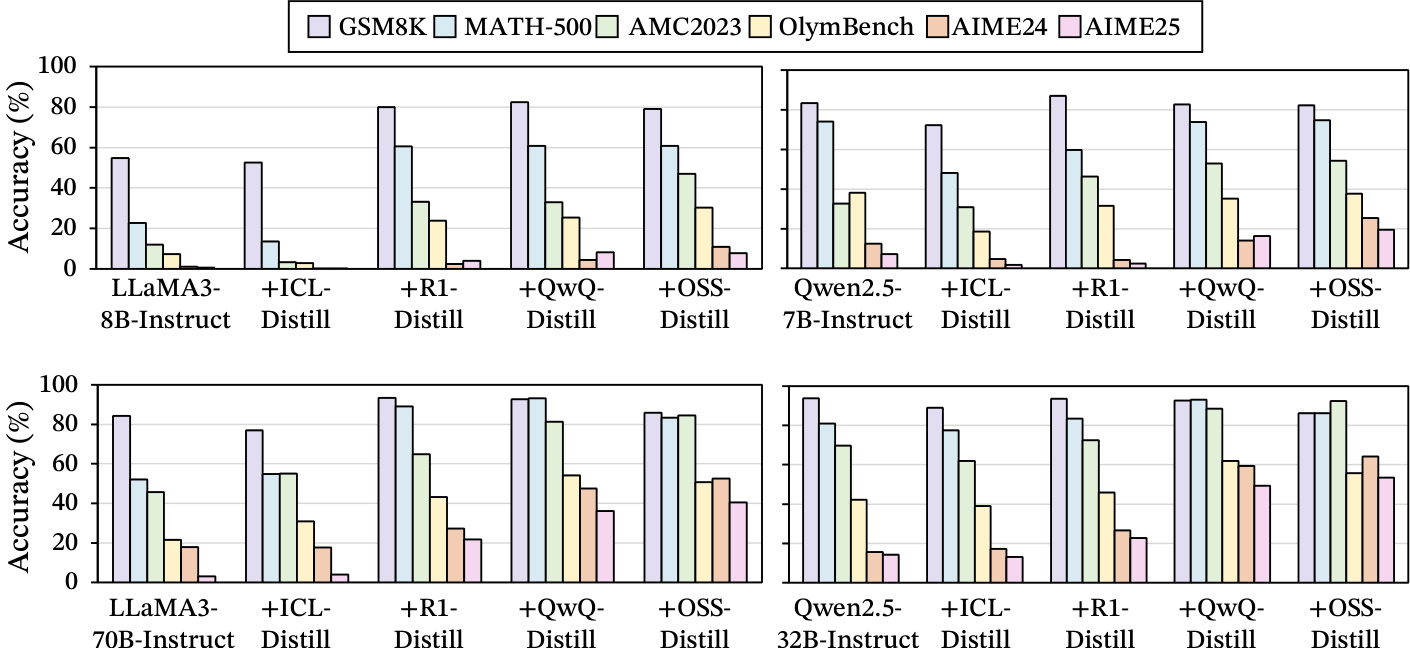
- 从强推理LLM蒸馏可实现有效的Long CoT学习,在GSM8K、MATH-500和AIME2024等基准测试中取得显著性能提升;而通过ICL或在人工标注轨迹上微调弱指令LLM的蒸馏则无法再现长链推理优势。
- 在多个模型与任务中观察到稳定、类宏观分子的推理键分布,皮尔逊相关系数超过0.9(p < 0.001),在充分采样后稳定高于0.95,表明推理拓扑具有鲁棒性与可迁移性。
- Long CoT表现出“逻辑折叠”结构:深度推理充当共价键(72.56%的步骤保持在相近语义距离内),自我反思模拟氢键(81.72%的反思重新连接至先前聚类),探索则发挥范德华力作用,通过更长轨迹连接远距离语义聚类。
- 从强推理LLM衍生的结构良好语义异构体支持一致性能提升(相关性~0.9),但微小分布变化即导致性能大幅下降(>10%),凸显脆弱性,强调ICL蒸馏中需精确对齐。
- 联合训练两个高度相关但结构迥异的推理框架(如R1与OSS)导致结构混乱,性能显著下降,自相关低于0.8,表明推理系统共存由结构兼容性决定,而不仅是统计相似性。
- MOLE-SYN成功从指令级数据合成Long CoT结构,无需完整推理轨迹,达到接近蒸馏性能,并在MATH与AIME基准测试中实现更优且持续的强化学习增益。
- 对Long CoT轨迹进行摘要与令牌压缩会破坏推理键分布,降低蒸馏有效性,压缩超过45%时准确率下降,表明此类方法可保护模型结构免于模仿。
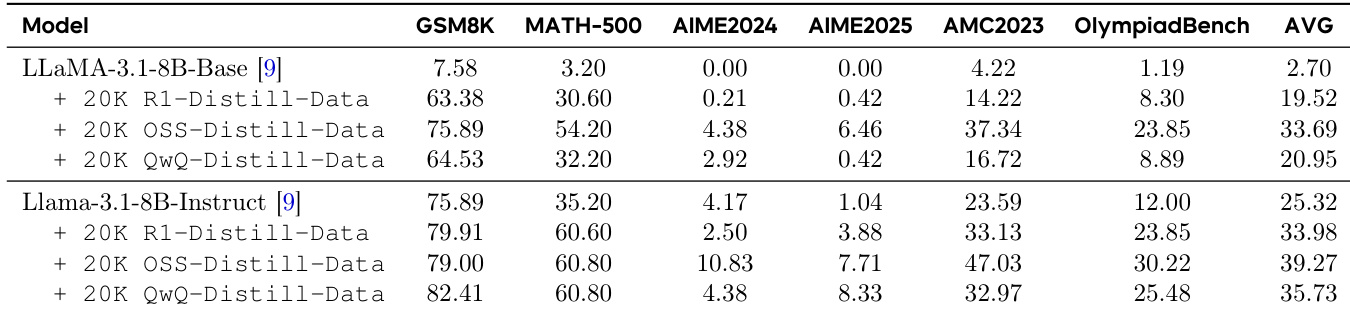
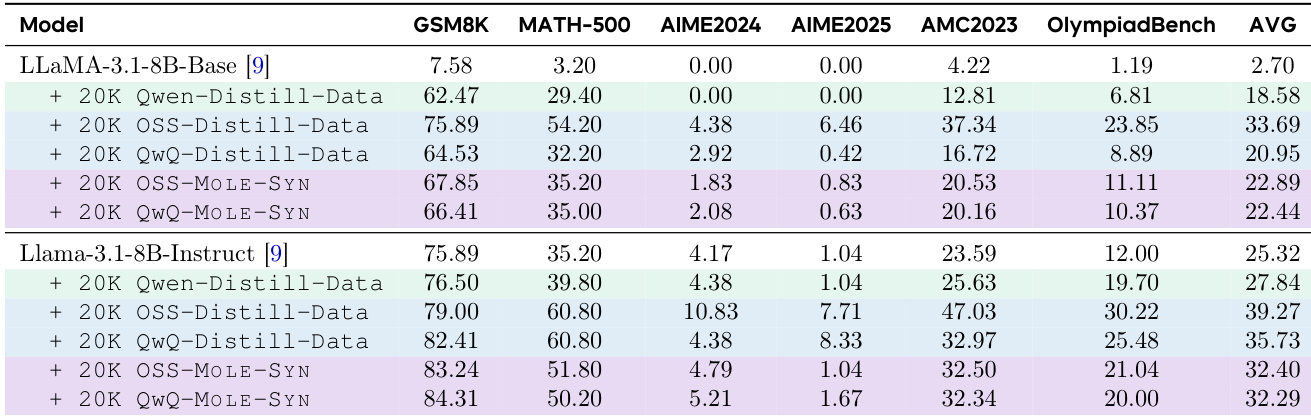
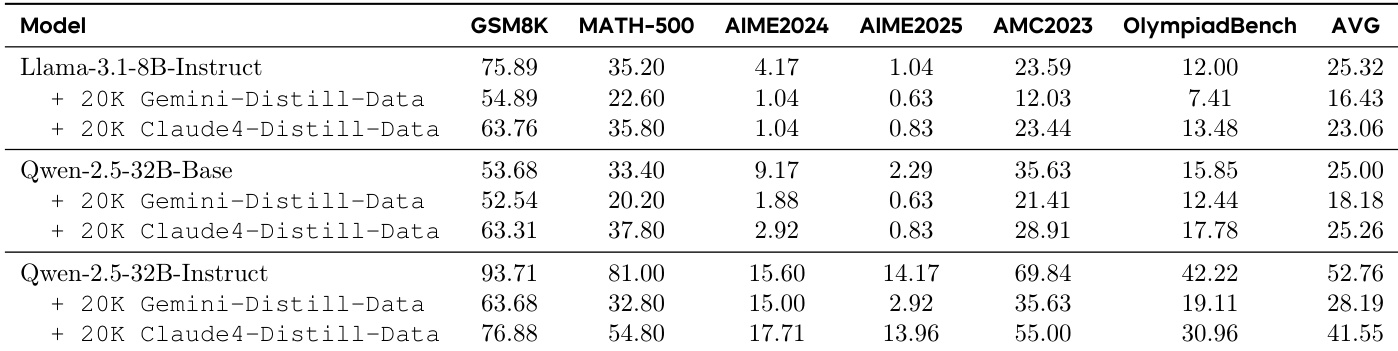
作者使用表格比较不同模型与训练数据类型在六个基准测试中的表现。结果表明,从强推理LLM蒸馏,特别是使用Qwen与OSS数据,显著优于基线模型与指令微调模型。MOLE-SYN方法合成Long CoT数据,性能可媲美从强推理模型蒸馏,表明有效推理结构可在无直接高质量教师数据情况下生成。
作者通过一系列实验比较不同数据源在训练语言模型长链思维(Long CoT)推理方面的有效性。结果表明,从强推理LLM蒸馏在所有基准测试中始终带来最高性能,而通过上下文学习或在人工标注轨迹上微调弱指令LLM的蒸馏则显著降低准确率。这表明,只有来自先进模型的高质量、结构化推理轨迹才能有效教授Long CoT,性能提升与底层推理结构的保真度密切相关。
作者使用MOLE-SYN从弱指令模型合成Long CoT数据,在六个基准测试中实现与从强推理模型蒸馏相当的性能。加入强化学习进一步提升结果,最佳性能在训练35K合成样本后进行RL微调时获得。

作者使用表格比较不同模型与训练数据配置在六个基准测试中的表现。结果表明,从强推理LLM(如Gemini与Claude)蒸馏显著提升模型性能,优于在指令微调LLM或人工标注轨迹上训练。最佳结果在模型训练于高质量推理LLM的蒸馏数据时取得,其中Qwen-2.5-32B-Instruct模型达到52.76的最高平均分。
作者使用从强推理LLM蒸馏的方法训练模型处理Long CoT数据,相比基线模型在多个基准测试中显著提升性能。结果表明,从高质量推理轨迹(如R1与QwQ)蒸馏带来显著增益,而从指令微调模型或人工标注轨迹蒸馏则性能大幅下降,表明只有结构良好的推理数据能有效支持Long CoT学习。