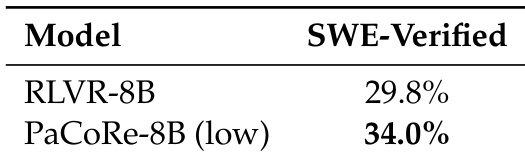Command Palette
Search for a command to run...
PaCoRe:通过并行协同推理学习在测试时扩展计算资源
PaCoRe:通过并行协同推理学习在测试时扩展计算资源
摘要
我们提出并行协同推理(Parallel Coordinated Reasoning,简称 PaCoRe),这是一种面向训练与推理的框架,旨在克服当前语言模型的一项核心局限:在固定上下文窗口下,难以将推理时计算量(Test-Time Compute, TTC)扩展至远超串行推理的水平。PaCoRe 打破了传统的串行推理范式,通过多轮消息传递架构实现大规模并行探索,从而驱动TTC的高效扩展。在每一轮中,系统同时启动大量并行推理路径,将各路径的发现结果压缩为受限于上下文长度的消息,并通过整合这些消息来指导下一轮推理,最终生成最终答案。该模型采用大规模、基于结果的强化学习进行端到端训练,掌握了PaCoRe所要求的高效信息合成能力,在不超出上下文长度限制的前提下,实现了数百万token级别的有效TTC扩展。该方法在多个领域均展现出显著性能提升,尤其在数学推理方面实现突破性进展:一个80亿参数(8B)的模型在HMMT 2025基准上达到94.5%的准确率,超越GPT-5的93.2%,其关键在于将有效TTC扩展至约两百万token。为推动后续研究,我们已开源模型检查点、训练数据及完整的推理流水线。
一句话总结
来自StepFun、清华大学和北京大学的作者提出了PaCoRe,一种并行协同推理框架,通过多轮并行推理轨迹间的消息传递实现测试时计算(TTC)的海量扩展,在HMMT 2025上以94.5%的准确率超越GPT-5(93.2%),在固定上下文限制内高效融合数百万token的推理过程,同时开源模型与数据以推动可扩展推理系统的发展。
主要贡献
- PaCoRe提出了一种新框架,通过在多轮并行推理轨迹间实现迭代式消息传递,将测试时计算(TTC)扩展能力与固定上下文窗口限制解耦,使有效TTC可在标准上下文范围内扩展至数百万token。
- 该方法依赖大规模、基于结果的强化学习训练模型进行推理合成——关键在于能够协调并整合并行分支间的冲突见解,克服了朴素聚合方法所面临的“推理独白”问题。
- 在HMMT 2025数学基准测试中,PaCoRe-8B达到94.5%准确率,超越GPT-5的93.3%,通过利用高达两百万有效token的TTC,完整资源(包括模型检查点、训练数据和推理代码)已开源供社区使用。
引言
作者针对大语言模型在长周期推理任务中测试时计算(TTC)扩展的挑战展开研究,传统串行推理受限于固定上下文窗口。先前方法或通过深度思维链饱和上下文限制,或依赖缺乏泛化能力的任务特定协调机制。为克服这些局限,作者提出PaCoRe框架,通过允许多轨迹并行协同推理,将推理量与上下文容量解耦。每轮中,多个并行推理路径生成中间解,这些解被压缩为紧凑消息,并在模型上下文中合成以指导下一轮迭代。该迭代过程使有效TTC扩展至数百万token,同时运行于标准上下文限制内。关键创新在于采用大规模、基于结果的强化学习训练模型实现推理合成——核心能力在于协调并行分支间的冲突证据,而非默认采用朴素聚合。该方法在数学基准上表现达到最先进水平,甚至超越GPT-5等专有模型,并配套开源模型、数据与代码,推动社区研究发展。
数据集

- 数据集整合了来自开源仓库和历史数学竞赛的数学问题,包括AIME、HMMT、SMT、CMIMC、BRUMO、BMT、CHMMC、DMM、MNYMO、PUMAC及Girls Math Prize,均来自其官方档案。
- 开源数学数据集来源于参考文献[40, 10, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50],竞赛题目则从官方在线档案[51–61]收集。
- 为避免与MathArena基准[62]重叠,AIME 2024/2025、HMMT Feb 2025、BRUMO 2025、SMT 2025、CMIMC 2025及HMMT Nov 2025被排除在训练集之外。
- 生成13,000个合成的大整数算术问题,使用手工模板,整数A和B在10¹¹至10¹³之间均匀采样,操作包括加法、减法、乘法或模固定大素数的模幂运算。
- 每个合成问题设计为具有唯一且明确的整数答案,精确计算后作为真实标签。
- 数据质量控制包含多个阶段:基于确定性规则的过滤移除含图像、外部链接、多部分问题或开放式提示的问题;内部专家标注100个样本以识别常见问题,如错误解法或表述模糊。
- 使用微调的LLM判官(gpt-oss-120b)在四轮一致方案中对QA对进行有效/无效分类,提示持续迭代直至F1分数饱和,确保仅保留表述清晰、可验证的问题。
- 过滤后的开源与竞赛问题与合成算术集合并,再通过强提议模型进行基于准确率的筛选,以选择非平凡、非退化问题,作为课程设计的一部分。
- 对于竞赛编程数据,约29,000个问题来自TACO[63]、USACO及近期开源数据集如am-thinking-v1[64]和deepcoder[65]。
- 每个问题均经过格式验证、测试用例校验,并使用testlib库进行完整评判,必要时修改以支持64位整数比较,并通过LLM生成自定义校验器。
- 受CodeContests+ [66]启发的生成-验证流水线使用LLM生成新测试用例,通过与真实答案和错误提交对比验证其正确性。
- 最终代码数据集包含约5,000个精选自CodeForces[64]的问题,基于测试用例质量及在强化学习实验中的表现筛选,其中细粒度测试用例通过率奖励优于二元奖励。
方法
作者提出并行协同推理(PaCoRe)框架,旨在通过并行探索与多轮间协同消息传递,突破固定上下文窗口对测试时计算(TTC)的限制。该框架的核心是其迭代推理流程,通过一系列协调推理轮次运行。在每轮 r,系统接收前一轮的紧凑消息集 Mr−1,作为先前推理努力的合成摘要。这些消息与原始问题实例 x 结合,构成当前轮次的输入上下文。模型随后并行生成 Kr 条独立推理轨迹,每条轨迹代表一条完整的推理链,最终得出结论。这种并行生成是提升有效TTC的主要机制,因为所有轨迹的总token数显著增长,而每轮输入上下文仍受限于固定上下文窗口。
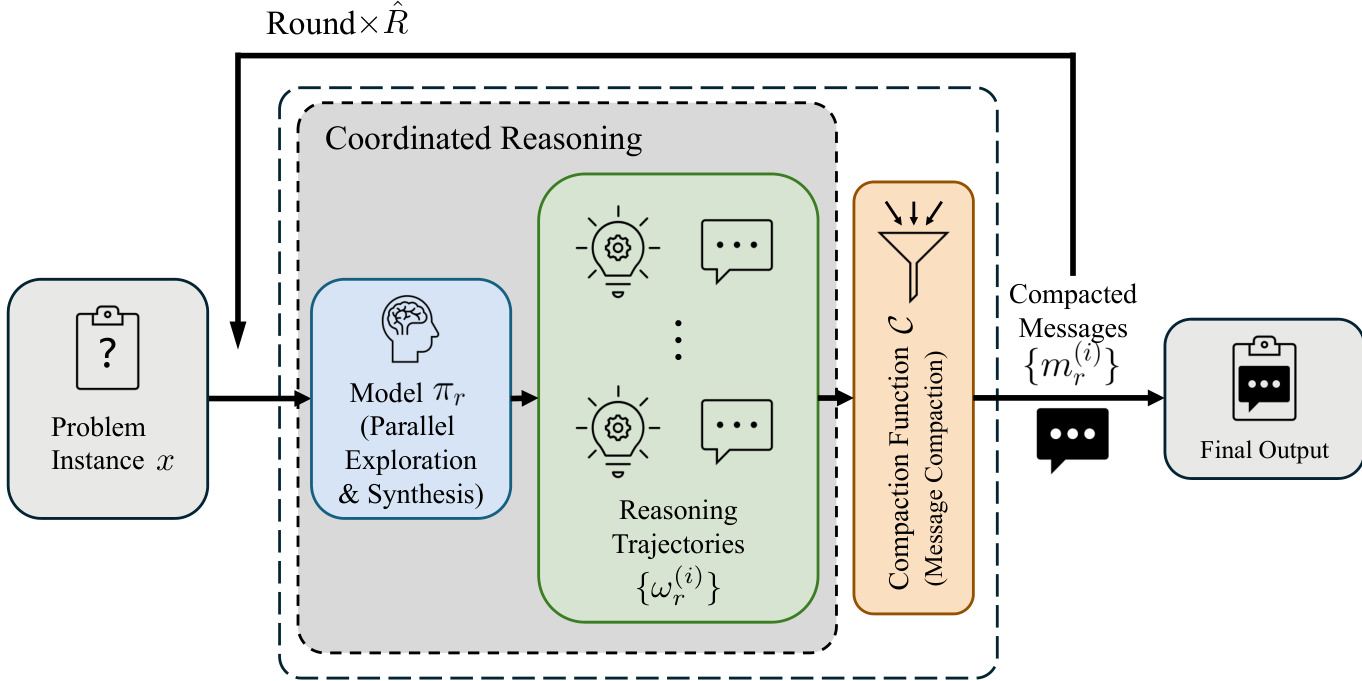
如图所示,每轮过程分为两个主要阶段:合成与并行探索,随后是消息压缩。第一阶段,模型 πr(所有轮次使用相同权重以简化操作)被调用,从输入 P(x,Mr−1) 生成轨迹集 Ωr={ωr(i)}。提示函数 P 将问题与消息序列化为结构化自然语言输入,详见表6,将消息呈现为“参考回答”,以鼓励批判性评估与合成。第二阶段通过压缩函数 C 将完整轨迹 Ωr 压缩为一组新的紧凑消息 Mr。实现中,该函数仅提取每条轨迹的最终结论,丢弃中间推理步骤,从而确保下一轮输入长度保持在上下文窗口内。此迭代过程重复 R 轮,最后一轮使用单条轨迹(KR=1)生成最终输出 y=mR(1),即模型的答案。
PaCoRe模型的训练采用大规模、基于结果的强化学习,以赋予模型必要的合成能力。训练过程将PaCoRe推理的一轮视为一个回合式强化学习环境,策略 πθ 被优化以从给定问题和消息集生成高质量推理轨迹。策略根据生成轨迹中提取消息的正确性获得稀疏终端奖励。为确保模型发展出真正的合成能力而非依赖简单启发式,训练实例中若输入消息集的平均准确率超过阈值则被丢弃。该方法迫使模型协调冲突信息,生成超越任一输入质量的新策略,有效训练其在隐式多智能体环境中运作。
实验
- PaCoRe-8B通过大规模强化学习在竞赛级数学与编程任务上训练,采用两阶段数据过滤流程以促进合成而非朴素聚合。训练过程演化出交叉验证行为与涌现正确性,使模型即使从完全错误的输入消息中也能生成正确解。
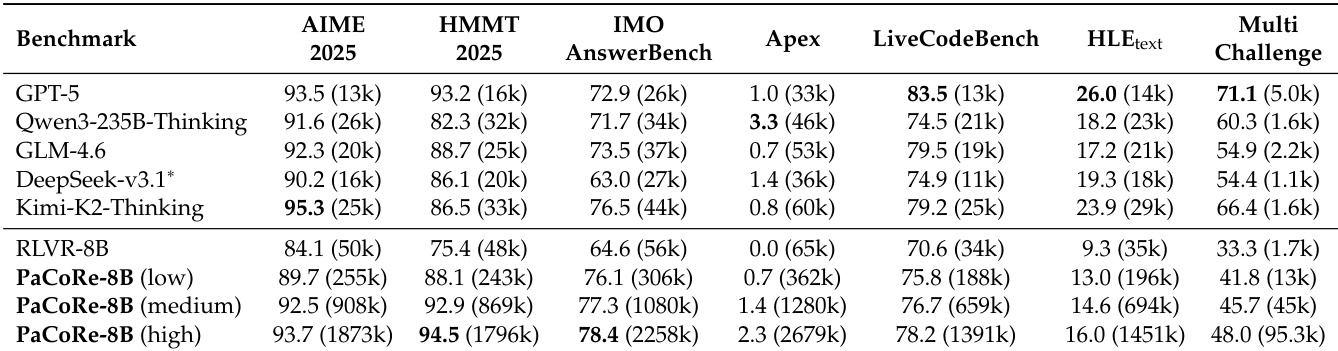
- 在HMMT 2025上,PaCoRe-8B在高推理设置(K = [32, 4])下达到94.5% pass@1,超越GPT-5,并显著优于Qwen3-235B-A22B-Thinking-2507和DeepSeek-V3.1-Terminus等更大模型。
- 在LiveCodeBench上,PaCoRe-8B达到78.2% pass@1,优于RLVR-8B,并与GLM-4.6和Kimi-K2-Thinking等前沿模型保持竞争力。
- 在具有挑战性的Apex基准上,PaCoRe-8B在高设置下达到2.3% pass@1,而RLVR-8B为0.0%,展现出在基线模型失败时解决问题的能力。
- 消融研究证实,带消息传递的并行协同推理至关重要:它实现了对测试时计算(TTC)的稳健扩展,而串行或未压缩方法在高TTC下趋于饱和或退化。
- PaCoRe在新领域上具有强泛化能力:在SWE-Verified上,PaCoRe-8B(低)达到34.0%解决率,优于RLVR-8B的29.8%;在MultiChallenge上,高TTC下从33.3%提升至48.0%。
- 仅使用PaCoRe训练数据进行标准RLVR训练,即可在AIME 2025和LiveCodeBench上带来显著性能提升,且所需计算极少,表明其作为推理训练基底具有高密度与强泛化性。
结果表明,PaCoRe-8B在所有基准上持续优于RLVR-8B基线及多个更大模型,最高性能出现在高测试时扩展设置下。模型在HMMT 2025上达到94.5%,在IMOAnswerBench上达到78.4%,超越GPT-5,并展现出在Apex及软件工程场景等挑战性任务上的强泛化能力。
作者使用PaCoRe数据训练RLVR模型,在AIME 2025和LiveCodeBench上均显著优于SFT基线。结果显示,使用PaCoRe数据训练的RLVR模型在AIME 2025上达到83.2%,在LiveCodeBench上达到74.0%,分别优于SFT模型1.8和8.0个百分点。

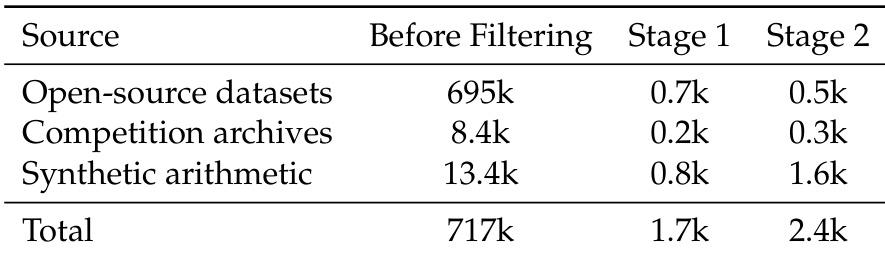
作者采用两阶段过滤流程对PaCoRe-8B的训练数据分布进行精炼,将总数据集规模从717k缩减至2.4k,覆盖三个来源。第一阶段过滤低消息集准确率与低质量样本,第二阶段进一步筛选,仅保留合成准确率在0至1之间的实例,形成更聚焦、高效的训练语料。
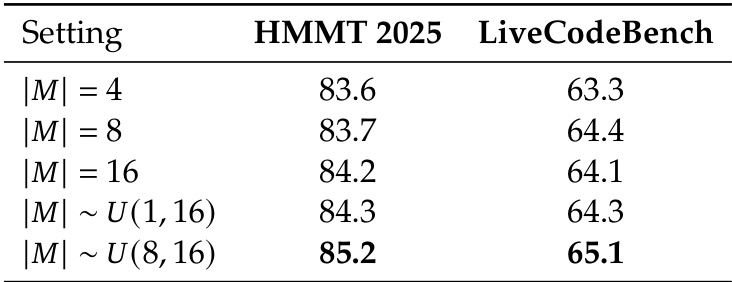
作者使用表格分析消息集大小对模型性能的影响,结果显示推理过程中调整消息集大小可提升结果。实验表明,在HMMT 2025和LiveCodeBench上,采用8至16之间的均匀采样消息集大小可获得最高准确率,优于固定大小设置。
作者对比RLVR-8B与PaCoRe-8B(低)在SWE-Verified基准上的表现,结果显示PaCoRe-8B(低)达到34.0%的解决率,显著优于RLVR-8B的29.8%。该结果表明,PaCoRe框架可在无需任务特定调优的情况下实现对软件工程任务的强泛化能力。