Command Palette
Search for a command to run...
RelayLLM:通过协作解码实现高效推理
RelayLLM:通过协作解码实现高效推理
Chengsong Huang Tong Zheng Langlin Huang Jinyuan Li Haolin Liu Jiaxin Huang
摘要
大型语言模型(LLMs)在复杂推理任务中常受限于高昂的计算成本与延迟,而资源高效的小型语言模型(SLMs)则普遍缺乏足够的推理能力。现有的协同方法,如级联或路由机制,通常以粗粒度方式将整个查询任务卸载至LLM,当SLM能够独立完成大部分推理步骤时,这种策略会导致显著的计算资源浪费。为解决该问题,我们提出RelayLLM——一种基于token级协同解码的高效推理新框架。与传统路由机制不同,RelayLLM使SLM能够作为主动控制器,仅在关键token生成时通过特殊指令动态调用LLM,从而实现生成过程的“接力”式协作。我们设计了一种两阶段训练框架,包括预热阶段与组相对策略优化(Group Relative Policy Optimization, GRPO),以教会模型在自主推理与策略性求助之间取得平衡。在六个基准测试上的实证结果表明,RelayLLM平均准确率达到49.52%,有效弥合了SLM与LLM之间的性能差距。尤为关键的是,该框架仅在总生成token中调用LLM占比1.07%,相比性能相当的随机路由机制,实现了98.2%的计算成本降低。
一句话总结
华盛顿大学圣路易斯分校、马里兰大学和弗吉尼亚大学的作者提出 RelayLLM,一种基于 token 级别的协作解码框架,使小型语言模型仅在关键 token 处通过特殊命令动态调用大型语言模型,从而在六个基准测试上实现 49.52% 的平均准确率,同时将 LLM 使用率降低至仅 1.07% 的 token——相比性能匹配的随机路由器节省 98.2% 的成本。
主要贡献
- 现有的小型与大型语言模型之间的协作方法因粗粒度、全有或全无的卸载方式而效率低下,导致即使小型模型能独立处理大部分推理步骤,仍产生大量计算浪费。
- RelayLLM 引入 token 级别的协作解码机制,小型模型作为主动控制器,仅通过特殊 命令在关键 token 处动态调用大型模型,实现精准且高效的专家干预。
- 在六个基准测试上评估,RelayLLM 将平均准确率从 42.5% 提升至 49.52%,同时仅使用大型模型处理 1.07% 的 token——相比性能匹配的随机路由器实现 98.2% 的成本降低。
引言
作者针对将大型语言模型(LLMs)用于复杂推理任务时面临的高计算成本挑战,以及小型语言模型(SLMs)缺乏有效处理此类任务的推理能力问题。以往的协作方法依赖粗粒度路由或级联机制,当判断查询较难时,将整个查询卸载至 LLM——导致显著的计算浪费,因为 SLM 通常能独立完成大部分推理步骤。为克服这一问题,作者提出 RelayLLM,一种 token 级别的协作解码框架,其中 SLM 作为主动控制器,仅在关键 token 处通过特殊 命令动态调用 LLM。这实现了高效、交错生成,且专家干预最小化。该方法采用两阶段训练流程——监督预热以掌握命令语法,以及基于组相对策略优化(GRPO)的战略求助学习,平衡独立性与辅助性。实验表明,RelayLLM 在六个基准测试上实现 49.52% 的平均准确率,比基线提升 7%,同时仅使用 LLM 处理 1.07% 的 token——相比性能匹配的随机路由器降低 98.2% 的成本。值得注意的是,SLM 在无需外部帮助的情况下,对简单任务的性能也有所提升,表明其已内化有效的推理模式。
数据集

- 数据集由从更大池中抽取的查询组成,重点关注大型模型干预可能带来收益的实例。
- 每个查询通过大型模型生成 10 个响应进行评估,仅保留通过率不低于 50% 的查询。
- 此过滤确保训练数据始终处于大型模型的能力范围内,避免包含过于困难的实例,这些实例无法带来性能提升。
- 经过滤后的子集构成主要训练数据,用于训练模型,其包含多种推理路径及由大型模型生成的反馈。
- 除基于通过率的过滤外,不进行裁剪或元数据构建;重点在于保留高质量、可解的实例以实现有效训练。
方法
RelayLLM 框架采用混合推理架构,协调资源高效的小型语言模型(SLM)与强大大型语言模型(LLM)之间的协作,以在最小化计算成本的同时实现高质量响应。SLM,记为 MS,在整个生成过程中作为主要推理引擎和中心控制器。它以自回归方式运行,根据当前上下文生成 token。然而,它被增强了一个专用控制机制,使其在需要时可动态向 LLM,ML,请求帮助。这通过生成特定命令模式 Ccmd(n)=<call>⊕n⊕</call> 实现,其中 n 是 SLM 预期需要从 LLM 获取的 token 数量。该命令作为干预触发器。
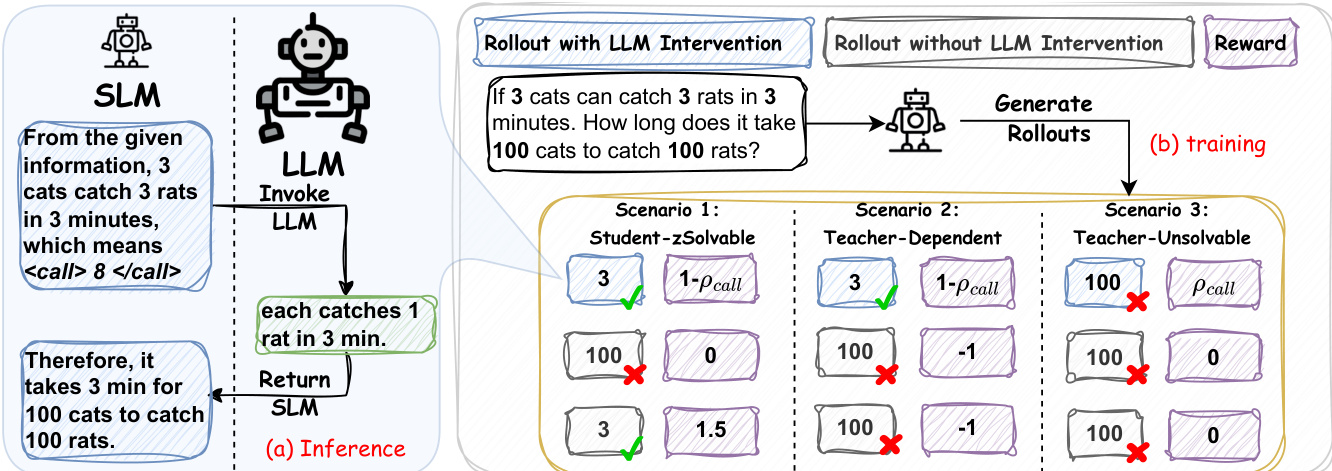
如图所示,推理过程是一个交错生成循环。当 SLM 生成命令模式时,其生成暂停,当前上下文(包括初始查询及 SLM 到该点为止生成的所有 token)被转发至 LLM。为确保与 LLM 的标准输入格式兼容,发送前会从上下文中移除特殊命令 token。随后,LLM 生成接下来的 n 个 token(或在生成结束符时提前停止),提供高质量的延续或推理步骤。控制权随后交还给 SLM,其在更新后的上下文(包含 LLM 生成的 token)上继续生成。SLM 保留完整历史,包括其自身的命令 token,从而能够追踪其委托决策,并将专家指导整合进持续的推理中。

为使 SLM 学会何时以及多长时间调用 LLM,采用两阶段训练框架。第一阶段为监督预热,作为冷启动,为模型初始化生成命令模式所需的结构知识。通过从原始 SLM 直接采样基础序列构建合成数据集 Dwarm,以避免分布偏移。在这些序列的随机位置插入命令 token,模拟各种调用场景。模型在该数据集上使用标准交叉熵损失进行微调,专注于学习输出有效命令模式。
第二阶段为基于强化学习的策略优化。作者在可验证奖励强化学习(RLVR)范式中采用组相对策略优化(GRPO)。该框架为每个查询从当前策略中采样一组输出,并相对于组平均值进行评估。训练目标被设计为在最大化生成响应性能的同时最小化协作成本。该框架的关键组件是难度感知奖励设计,根据采样组的集体表现将每个查询划分为三种场景:学生可解、教师依赖、教师不可解。这使得奖励信号更加精细,鼓励 SLM 在可能时独立解决问题,必要时寻求帮助,并避免高成本错误。
实验
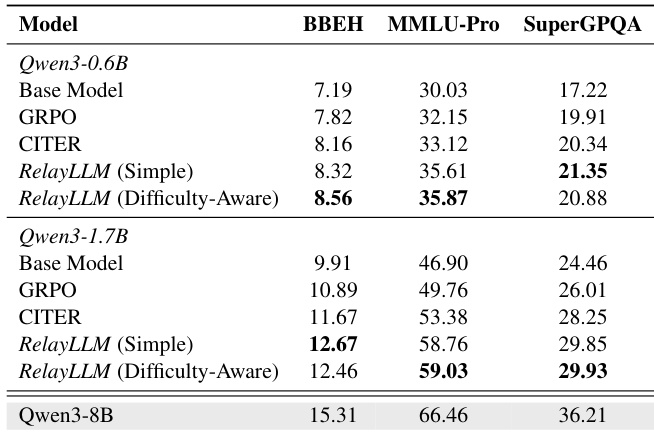
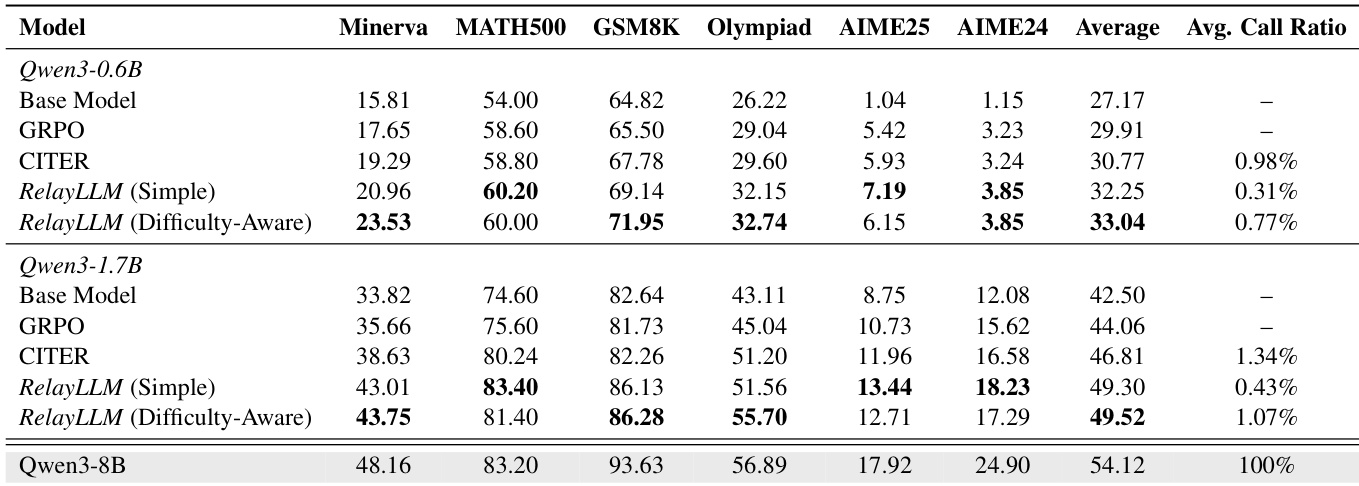
- 使用 Qwen3-0.6B 和 Qwen3-1.7B 作为学生模型,Qwen3-8B 作为教师模型,评估 RelayLLM,在六个推理基准测试上表现出色,同时保持低于 1% 的 token 开销。
- 在 Minerva 上,Qwen3-0.6B 准确率提升至 23.53%(从 15.81% 提升),相对提升 48.8%,教师调用仅占 0.77% 的 token,优于 CITER,尽管 CITER 的计算成本更高。
- 难度感知奖励使 Qwen3-1.7B 准确率提升至 49.52%(对比简单奖励的 49.30%),调用比例略有上升(1.07% vs. 0.43%),表明在复杂场景中具有更好的求助能力。
- RelayLLM 使 Qwen3-1.7B 恢复了基础 SLM(42.50%)与专家模型(54.12%)之间约 60% 的性能差距,证明稀疏、策略性干预极为有效。
- 在未见领域上的泛化能力:RelayLLM 在 MMLU-Pro(59.03% vs. 49.76% GRPO)、Big-Bench Hard 和 SuperGPQA 上均优于基线,表明其具备稳健的求助行为。
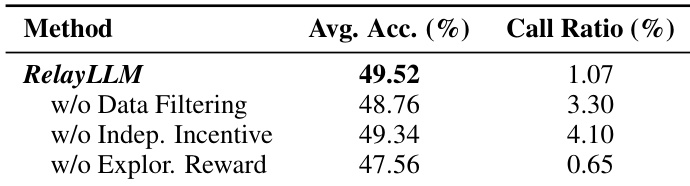
- 消融研究证实,数据过滤使调用比例降低 3 倍并提升准确率;独立性激励防止过度依赖(调用比例从 4.10% 降至 1.07%);探索奖励对准确率至关重要(无探索奖励时为 47.56%)。
- 无教师评估显示,RelayLLM 保留了较强的内在推理能力(简单任务上达 61.12%),但在困难任务上性能下降(如 15.00% → 11.93%),确认其对复杂问题仍依赖专家帮助。
- 动态长度预测优于固定长度策略:RelayLLM 以 1.07% 的调用比例达到与 Fixed-100 相当的准确率(MATH500 上为 81.40%),而 Fixed-100 为 2.87%;在 Minerva 上超越 Fixed-20(43.75% vs. 39.71%),且成本更低。
- 跨 LLM 评估显示,匹配训练教师(Qwen3-8B)可最大化性能,但即使使用较弱教师(0.6B/1.7B)也优于无教师基线,表明其能适应外部协助。
- RelayLLM 在计算成本可忽略的情况下达到与更大模型相当的准确率,证明其具备高效的按需卸载能力,并有效学习了求助行为。
作者使用 Qwen3-0.6B 和 Qwen3-1.7B 作为学生模型,评估 RelayLLM,与 GRPO 和 CITER 基线在六个推理基准测试上进行比较。结果表明,RelayLLM 在基线模型上实现显著性能提升,并优于 CITER,其中难度感知奖励变体在保持低于 1% 的平均调用比例的同时达到最高准确率。
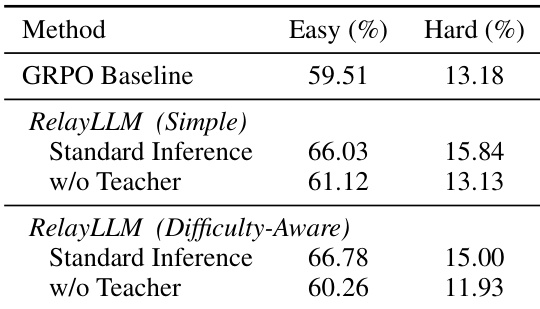
作者采用无教师评估,以评估 RelayLLM 的内在推理能力,结果显示,即使在无法访问教师的情况下,学生模型仍保留了改进的推理技能。结果表明,RelayLLM(简单奖励)在简单数据集上的准确率高于 GRPO 基线,表明知识转移有效;而在困难数据集上性能下降,表明其对复杂任务仍持续依赖教师。
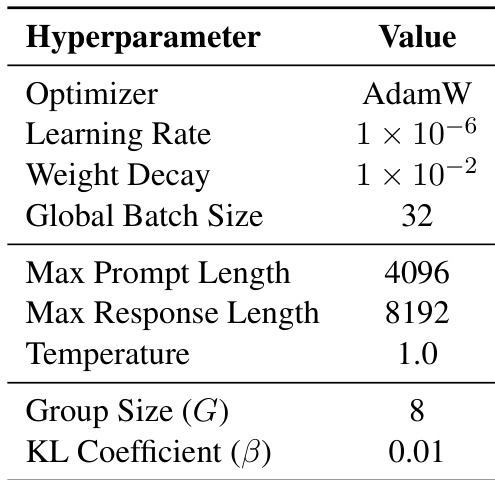
作者在后训练阶段使用 GRPO 算法,采用 AdamW 作为优化器,学习率为 1×10−6,权重衰减为 1×10−2。模型以全局批量大小 32、组大小 8、KL 系数 0.01 进行训练,以确保稳定性,采样时使用温度 1.0。
作者通过消融研究评估 RelayLLM 中关键组件的影响,结果显示,移除数据过滤会降低准确率并增加调用比例,表明其在避免浪费性交互中的重要性。移除独立性激励会导致调用比例升高,表明鼓励自立可提升效率。移除探索奖励会显著降低准确率,凸显其在不确定情境下触发求助的关键作用。
作者使用 Qwen3-0.6B 和 Qwen3-1.7B 作为学生模型,在推理基准测试上与基线对比评估 RelayLLM,Qwen3-8B 作为教师模型。结果表明,RelayLLM(难度感知)在两种学生模型上均在 MMLU-Pro 和 SuperGPQA 上达到最高准确率,优于所有基线,同时保持低调用比例,证明其在未见领域上具有优异的泛化能力。