Command Palette
Search for a command to run...
GlimpRouter:通过窥视一个思维token实现高效协同推理
GlimpRouter:通过窥视一个思维token实现高效协同推理
Wenhao Zeng Xuteng Zhang Yuling Shi Chao Hu Yuting Chen Beijun Shen Xiaodong Gu
摘要
大型推理模型(Large Reasoning Models, LRMs)通过显式生成多步思维链,实现了卓越的性能表现,但这一能力也带来了显著的推理延迟和计算开销。协作式推理(Collaborative Inference)提供了一种有前景的解决方案,通过在轻量级模型与大型模型之间选择性地分配任务,实现效率与性能的平衡。然而,一个根本性挑战依然存在:如何准确判断某一推理步骤是需要大型模型的强大能力,还是可由轻量级模型高效完成。现有的路由策略要么依赖局部词元概率,要么采用事后验证机制,均引入了较大的推理开销。在本研究中,我们提出了一种关于分步协作的新视角:推理步骤的难度可从其首个词元中直接推断。受大型推理模型中“顿悟时刻”(Aha Moment)现象的启发,我们发现初始词元的熵值能够成为步骤难度的强预测指标。基于这一洞察,我们提出了 GlimpRouter——一种无需训练的分步协作框架。GlimpRouter 仅使用轻量级模型生成每个推理步骤的第一个词元,并在该初始词元的熵值超过预设阈值时,才将该步骤路由至大型模型进行后续处理。在多个基准测试上的实验结果表明,该方法在显著降低推理延迟的同时,仍能保持较高的准确性。例如,在 AIME25 数据集上,GlimpRouter 相较于独立使用的大型模型,实现了 10.7% 的准确率提升,同时将推理延迟降低了 25.9%。这些结果表明,一种简单而高效的推理机制已然可行:通过观察思维的“一瞥”(glimpse),而非完整评估每一步推理,即可实现计算资源的智能分配。
一句话总结
上海交通大学的作者提出 GlimpRouter,一种无需训练的框架,通过初始 token 的熵来预测推理步骤的难度,使轻量级模型能够以极低开销将复杂步骤路由至大型模型;该方法在 AIME25 上将推理延迟降低 25.9%,同时将准确率提升 10.7%,展示了面向大型推理模型的高效、基于“瞥见”的协作机制。
主要贡献
- 大型推理模型(LRMs)通过多步推理实现高准确率,但面临高推理延迟和计算成本,促使人们需要高效协作推理策略,智能分配轻量级与大型模型之间的任务。
- 作者提出 GlimpRouter,一种无需训练的框架,通过分析首个生成 token 的熵来预测推理步骤的难度,利用“顿悟时刻”现象,在初始不确定性超过阈值时才将步骤路由至大型模型。
- 在 AIME25、GPQA 和 LiveCodeBench 等基准上的实验表明,GlimpRouter 相比独立运行的大型模型,推理延迟降低 25.9%,准确率提升 10.7%,展现出优异的效率-准确率权衡。
引言
大型推理模型(LRMs)通过生成多步思维链在复杂任务上取得优异表现,但代价是高推理延迟和高计算开销。协作推理——即轻量级模型与大型模型协同工作——为降低这一开销提供了可能,然而现有方法存在效率瓶颈:基于 token 的策略依赖细粒度、重复性验证,而基于 step 的方法通常需要完整步骤评估或事后验证,引入显著开销。作者识别出一个关键洞察:推理步骤的难度可基于其首个 token 的熵实现早期预测。借鉴“顿悟时刻”现象,他们发现初始 token 的不确定性与步骤复杂度高度相关——低熵表示常规步骤,适合小型模型;高熵则表明需要大型模型介入。基于此,作者提出 GlimpRouter,一种无需训练、按 step 进行协作的框架,利用轻量级模型仅生成每个步骤的首个 token,并在初始 token 的熵超过阈值时,将该步骤路由至大型模型。该方法实现了高效、实时的决策,开销极小。实验表明,GlimpRouter 在 AIME25 上相比独立运行的大型模型,推理延迟降低 25.9%,准确率提升 10.7%,展示了通往高效推理的实用且可扩展路径。
方法
作者采用一种协作推理框架,协调一个大型高容量推理模型(LLM)与一个小型计算高效模型(SLM),在保持解题质量的同时加速推理过程。该框架以 step 为单位运行,将推理过程 T={s1,…,sK} 分解为独立步骤,每个步骤均基于前序上下文 ck 进行条件生成。系统核心 GlimpRouter 是一种无需训练、面向 step 的策略,通过一次低成本探测,动态决定将每个推理步骤路由至 SLM 或 LLM。该“探测-分发”机制旨在通过将常规步骤卸载至 SLM,同时保留 LLM 处理复杂高不确定性步骤,从而最小化推理延迟。
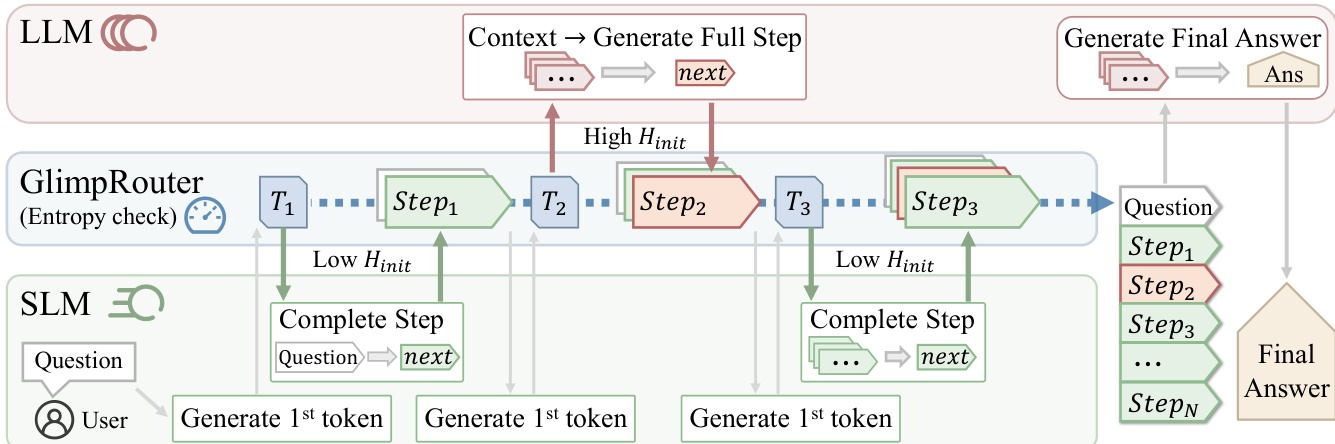
如图所示,系统从用户提供的问题开始。在每个推理步骤 k 的起始阶段,调用 SLM 仅生成该步骤的第一个 token,条件为上下文 ck。此初始 token 生成操作极小,计算成本等价于解码单个 token。该首个 token 的词汇表概率分布用于计算初始 token 熵 Hinit(sk),作为后续步骤认知不确定性或难度的代理指标。该熵值随后与预设阈值 τ 比较,以做出路由决策。若 Hinit(sk)≤τ,则该步骤被判定为常规步骤,由 SLM 负责生成其余 token;反之,若 Hinit(sk)>τ,则判定为复杂步骤,上下文将移交 LLM 以生成完整步骤。最终答案始终由 LLM 生成,以确保正确性。该设计确保 LLM 的高计算成本仅在需要其卓越推理能力的步骤中被触发,而 SLM 处理绝大多数常规步骤,从而带来显著效率提升。该框架的 step 级粒度使其可与其它加速技术(如推测解码)结合,进一步提升性能。
实验
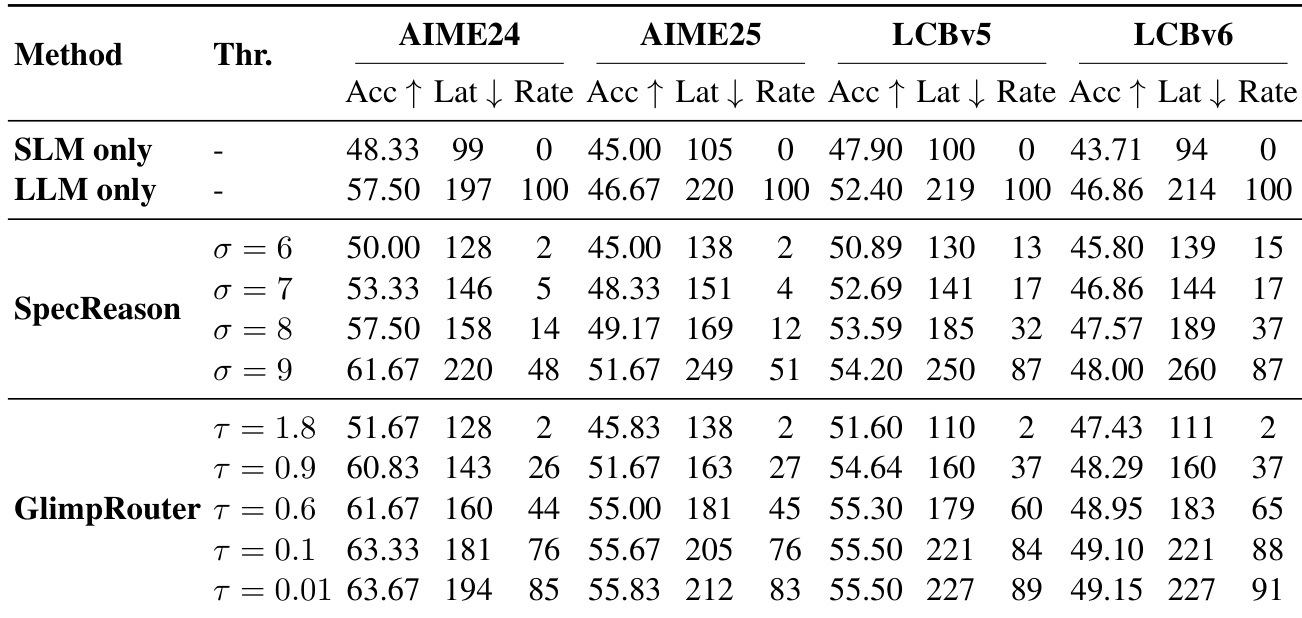
- GlimpRouter 验证了初始 token 熵 (Hinit) 作为推理步骤难度的高灵敏度判别器,表现出清晰的双峰分布,能有效区分常规与复杂步骤,而 PPLstep、Hstep 和 LLM-as-a-Judge 等方法则因信号稀释或饱和而表现不佳。
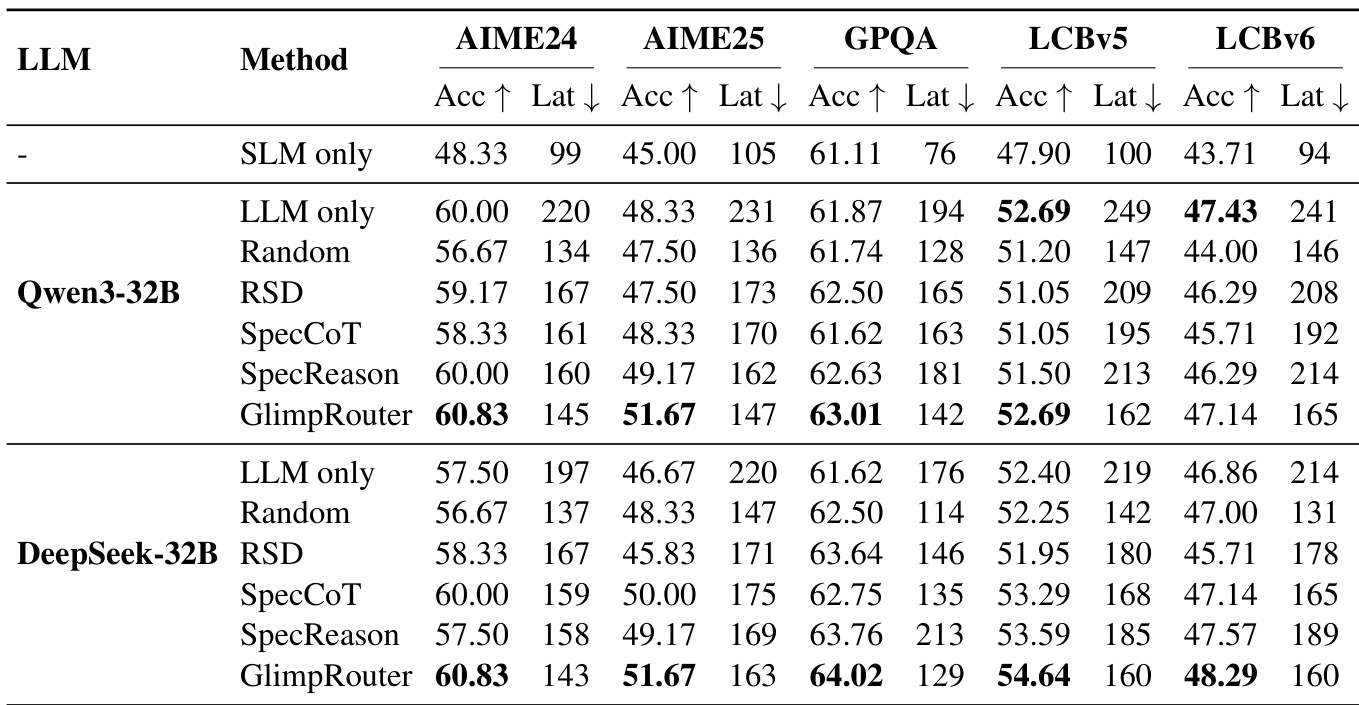
- 在 AIME24、AIME25、GPQA-Diamond 和 LiveCodeBench 上,GlimpRouter 实现了更优的效率-性能权衡,使用 Qwen3-4B(SLM)与 DeepSeek-R1-Distill-Qwen-32B(LLM)的组合,在准确率上超越独立运行的 LLM(如 AIME25 上达 51.67% vs. 46.67%),同时延迟降低 25.2%–27.4%。
- GlimpRouter 通过基于 Hinit 的“探测-分发”机制,优于反应式基线(RSD、SpecCoT、SpecReason),避免了完整步骤生成后的沉没成本;例如,SpecReason 在 GPQA 上的延迟为 213s,高于独立 LLM 的 176s,而 GlimpRouter 保持更低延迟。
- 消融实验表明,Hinit 显著优于 step 级指标(Hstep、PPLstep),在 AIME25 上实现 10.7% 的相对准确率提升,并因主动路由而降低延迟。
- GlimpRouter 与推测解码具有正交性,结合后在所有基准上实现最低端到端延迟,得益于粗粒度路由与细粒度 token 级加速的复合加速效应。
- 案例研究显示,高 Hinit 与认知转折点(如解题规划)相关,LLM 的介入可实现逻辑错误的自我修正,显著提升推理保真度,超越单纯文本延续。
结果表明,GlimpRouter 在所有基准上均优于 SpecReason,持续在准确率上领先的同时降低延迟。其“探测-分发”机制基于初始 token 熵路由步骤,避免在验证前生成完整步骤的沉没成本,从而实现比反应式基线更低的延迟和更高的准确率。
作者使用 GlimpRouter 对比其与采用 step 级熵和 step 级困惑度进行路由决策的变体性能。结果表明,GlimpRouter 在所有基准上均持续实现更高准确率和更低延迟,证明初始 token 熵优于对整个推理步骤平均不确定性的度量。
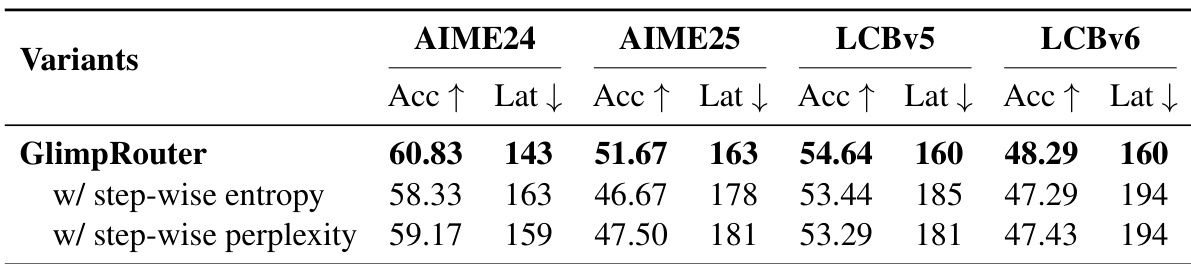
结果表明,使用初始 token 熵的 GlimpRouter 在准确率最高、延迟最低方面优于使用 step 级熵或困惑度的变体。优异表现证明,初始 token 熵为路由决策提供了比对整个推理步骤平均不确定性的度量更有效、更高效的信号。

结果表明,GlimpRouter 在多个基准上均优于独立模型和协作基线,实现更高准确率和更低延迟。与推测解码结合后,GlimpRouter 进一步降低延迟,同时保持卓越性能,展现出其高效性与可扩展性。
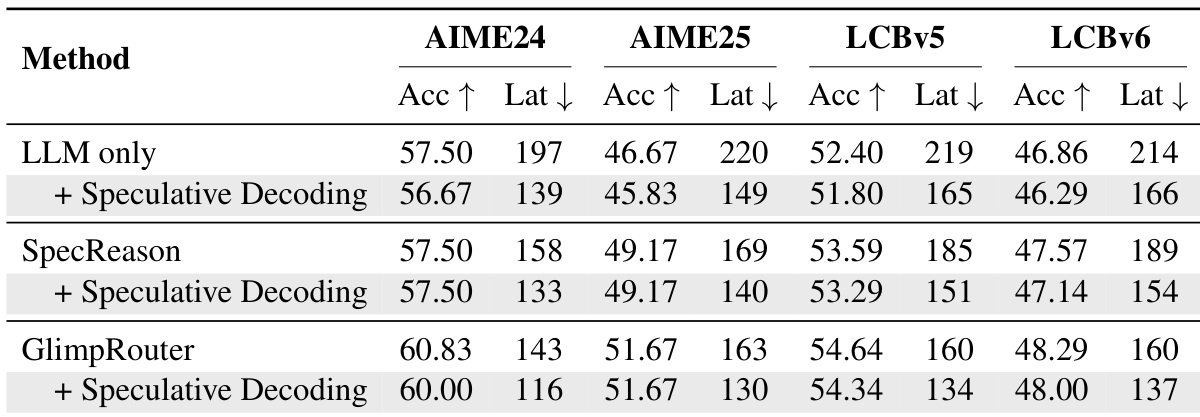
作者使用 GlimpRouter 根据初始 token 熵 Hinit 动态在小型模型(SLM)与大型模型(LLM)之间路由推理步骤。结果表明,GlimpRouter 在所有基准上均实现了最佳的准确率与延迟权衡,显著降低延迟的同时保持或提升准确率,优于独立模型和现有协作方法。