Command Palette
Search for a command to run...
对齐文本、代码与视觉:一种用于文本到可视化生成的多目标强化学习框架
对齐文本、代码与视觉:一种用于文本到可视化生成的多目标强化学习框架
Mizanur Rahman Mohammed Saidul Islam Md Tahmid Rahman Laskar Shafiq Joty Enamul Hoque
摘要
文本到可视化(Text-to-Visualization, Text2Vis)系统旨在将针对表格数据的自然语言查询转化为简洁的文本回答和可执行的可视化图表。尽管闭源大语言模型(LLM)能够生成功能性的代码,但生成的图表往往在语义对齐性和清晰度方面表现不足,而这些质量特征仅能在代码执行后才能评估。相比之下,开源模型面临更大挑战,常产生不可执行或视觉效果差的输出。虽然监督微调(Supervised Fine-Tuning, SFT)可提升代码的可执行性,但其无法有效改善整体可视化质量,因为传统SFT损失函数无法捕捉代码执行后的反馈信息。为填补这一空白,我们提出RL-Text2Vis,这是首个用于Text2Vis生成的强化学习框架。该框架基于组相对策略优化(Group Relative Policy Optimization, GRPO),设计了一种新颖的多目标奖励机制,通过执行后的反馈,联合优化文本准确性、代码有效性与可视化质量。在Qwen2.5模型(7B与14B参数规模)上进行训练后,RL-Text2Vis在Text2Vis基准测试中相较GPT-4o实现了22%的相对图表质量提升,并将代码执行成功率从零样本基线的78%显著提高至97%。我们的模型显著优于强大的零样本及监督微调基线,并在跨领域数据集(如VIS-Eval与NVBench)上展现出优异的泛化能力。上述结果表明,GRPO是一种在可视化生成任务中实现结构化、多模态推理的有效策略。相关代码已开源,访问地址为:https://github.com/vis-nlp/RL-Text2Vis。
一句话总结
来自约克大学、Salesforce AI研究机构和南洋理工大学的研究人员提出了RL-Text2Vis,这是一种基于组相对策略优化(GRPO)的强化学习框架,采用多目标奖励机制,联合优化文本准确性、代码有效性与可视化质量,用于文本到可视化生成任务。通过利用执行后的反馈,该方法显著提升了图表质量和代码执行成功率,相较于零样本和监督基线,在Text2Vis基准上实现了22%的图表质量相对提升和97%的代码执行成功率,展现出对域外数据集的强大泛化能力。
主要贡献
- 文本到可视化(Text2Vis)系统面临的核心挑战在于生成既可执行的代码,又能语义对齐且视觉清晰的图表;传统监督微调无法优化执行后的质量指标,如图表可读性和查询一致性。
- 作者提出RL-Text2Vis,首个用于Text2Vis的强化学习框架,采用组相对策略优化(GRPO)与新颖的多目标奖励机制,基于执行后反馈联合优化代码有效性、可视化质量和文本准确性。
- 在Text2Vis基准及域外数据集(如VIS-Eval和NVBench)上评估,RL-Text2Vis相较于GPT-4o实现22%的图表质量相对提升,并将代码执行成功率从78%提升至97%,优于其零样本基线。
引言
文本到可视化(Text2Vis)系统旨在弥合自然语言查询与表格数据的可执行、语义准确可视化之间的差距——这对非技术用户从数据中获取洞察至关重要。然而,先前方法存在关键局限:监督微调(SFT)虽提升代码可执行性,却无法优化执行后的质量,如视觉清晰度和查询一致性;而闭源模型虽能生成功能代码,却常产生语义错误的图表。开源模型在执行可靠性与输出质量方面表现更差。
作者提出RL-Text2Vis,首个利用执行后反馈联合优化文本准确性、代码有效性与可视化质量的强化学习框架。该框架基于组相对策略优化(GRPO),采用由大语言模型(LLM)与视觉-语言模型(VLM)对文本、代码与渲染图表进行评估所生成的新型多目标奖励。该方法实现了可扩展的无评判器训练,直接针对多模态输出质量进行优化。
通过训练Qwen2.5模型(7B与14B),RL-Text2Vis在Text2Vis基准上相较GPT-4o实现22%的图表质量相对提升,并将代码执行成功率从78%提升至97%。同时,该方法在域外数据集上展现出强大泛化能力,为专有模型提供了一种实用且保护隐私的替代方案。
数据集

- 数据集包含从真实用户查询中提取的图表生成任务,数据来源包括公开网络论坛、学术数据集以及使用语言模型生成的合成查询。
- 数据集划分为三个子集:
- Web-Query子集:12,000个样本,来自数据可视化平台的用户问题,经筛选仅保留意图明确且具备真实标注数据的条目。
- 合成子集:8,000个样本,通过提示工程生成,覆盖多种图表类型、复杂度水平及多步推理任务。
- 学术子集:5,000个样本,来自已发表的研究论文与数据集,选取标准为高数据保真度与复杂分析任务。
- 作者使用该数据集训练图表正确性评分模型,训练集占80%(12,000个样本),验证集占10%(1,500个),测试集占10%(1,500个)。
- 训练过程中混合比例设定为50% Web-Query、30% 合成、20% 学术,以平衡现实多样性与可控复杂度。
- 每张图表均采用裁剪策略,将可视化区域从周围文本或布局元素中分离,确保聚焦于图表本身。
- 构建元数据,包含图表类型、数据系列数量、查询复杂度等级以及缺失数据存在性,作为评分模型的辅助输入。
- 正确性评分基于六项标准,采用0–5分制:查询一致性、数据完整性、洞察表达、缺失数据处理、复杂度处理与整体清晰度。
方法
作者提出RL-Text2Vis,一种用于文本到可视化生成的强化学习框架,利用执行后的多模态反馈优化可视化质量——该质量仅在图表渲染后才可观察。整体框架以自然语言查询与表格数据为输入,策略模型生成包含简洁文本答案与可运行可视化代码片段的结构化输出。该输出随后通过两阶段奖励机制进行评估,确保结构有效性,并在文本、代码与视觉维度上评估质量。策略更新采用GRPO(组相对策略优化),一种无评判器方法,通过组内奖励标准化计算优势,实现无需学习价值函数的高效训练。
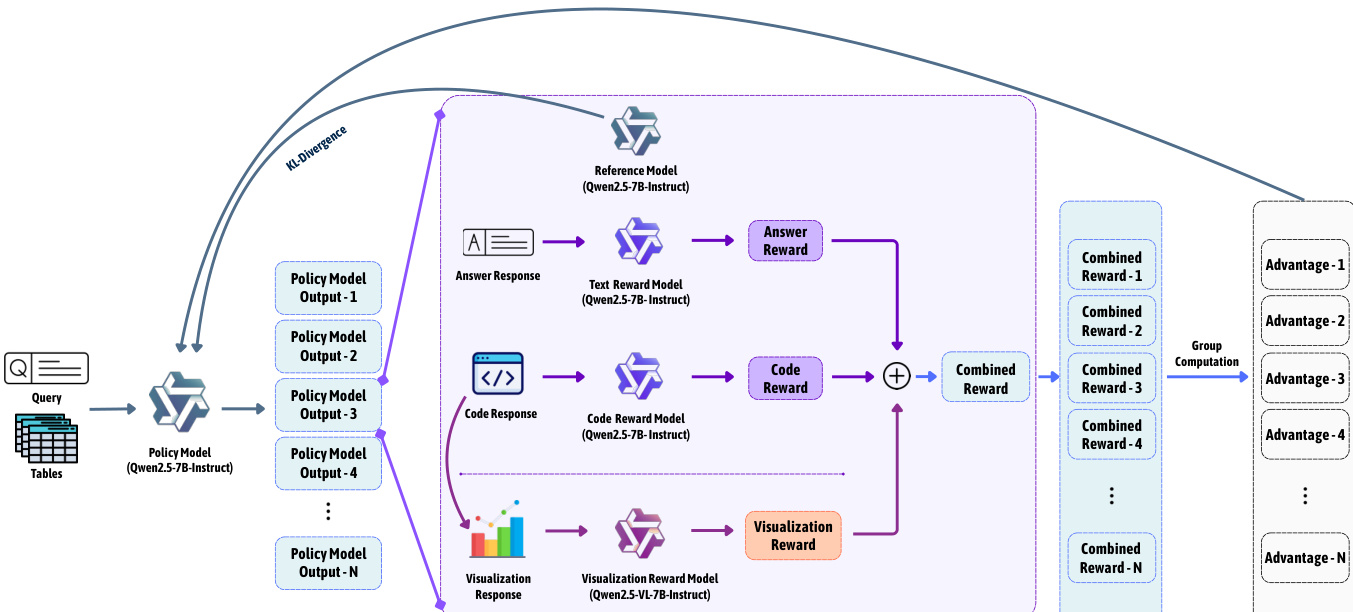
如图所示,训练过程从策略模型(Qwen2.5-7B-Instruct)为给定查询与表格生成多个候选输出开始。每个输出分别通过独立的奖励模型处理:文本奖励模型评估答案与真实答案的语义一致性,代码奖励模型评估代码可执行性与意图匹配度,可视化奖励模型评估渲染图表的可读性与正确性。各单项奖励合并为每个输出的综合奖励。随后在生成输出组内对奖励进行标准化,计算归一化优势,用于GRPO目标函数。策略更新采用裁剪的替代目标函数,引入与参考策略(Qwen2.5-7B-Instruct)的KL散度惩罚,确保更新稳定且有界。
GRPO优化目标如公式2所示,结合PPO式裁剪与KL正则化项,防止策略过度偏离。对每个提示,策略生成G个候选输出,每个输出i的优势计算为A^i=σrri−rˉ,其中ri为奖励,rˉ为组均值,σr为组标准差。当前策略与旧策略之间的重要性采样比it(θ)在由ε定义的范围内裁剪,KL惩罚项DKL[πθ∣∣πref]由β加权以控制偏离程度。该方法无需学习评判器,使其在长序列场景下具备可扩展性,其中价值估计不切实际。
多目标奖励设计分为两个阶段。第一阶段为格式奖励,通过要求输出为包含答案与代码字段的有效JSON对象来强制结构有效性;无效输出获得零奖励并被排除在优化之外。第二阶段为综合奖励,整合三个信号:文本正确性(Rtext)、代码奖励(Rcode)与可视化质量(Rvis)。文本正确性由基于LLM的评估器计算,代码奖励结合可执行性与意图匹配度,可视化质量由VLM评估。最终综合奖励为加权和R=αRtext+βRcode+γRvis,权重α=0.50、β=0.25、γ=0.25通过网格搜索确定,以平衡各维度性能。
实验
- 在Text2Vis基准(训练用test1,评估用test2)上,使用基于GRPO的RL-Text2Vis框架训练Qwen2.5-7B与Qwen2.5-14B模型,采用多模态奖励评判器(Qwen2.5-7B/VL-7B与Qwen2.5-14B/VL-32B),评判器间一致性高(皮尔逊相关系数r = 0.85–0.97)。
- 通过在相同设置下训练Llama-3.1-8B验证框架通用性,获得可比结果。
- 在四个基准上评估:Text2Vis(域内)、VisEval、NVBench与PandasPlotBench(域外),以GPT-4o为主要评估器,辅以人工人工评估以增强鲁棒性。
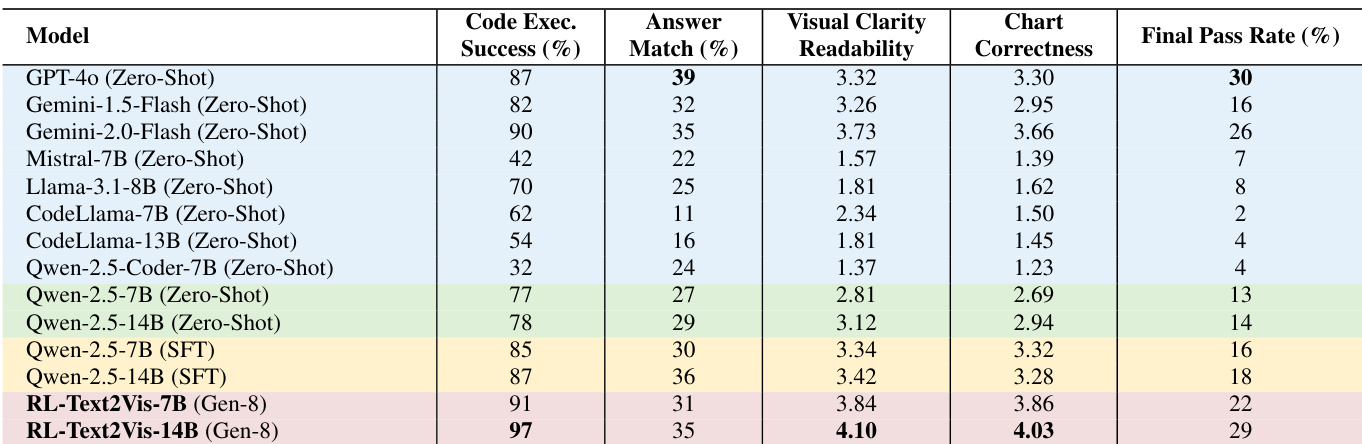
- RL-Text2Vis在Text2Vis上显著优于零样本与SFT基线:14B模型在可读性上达4.10,正确性达4.03(零样本为3.12与2.94),代码可执行率达97%(零样本为78%),答案匹配率达35%(零样本为29%);在图表可读性(4.10 vs. 3.32)与正确性(4.03 vs. 3.30)上超越GPT-4o。
- 展现出强大域外泛化能力:在VisEval上,7B模型可读性从1.50提升至2.50,正确性从0.69提升至1.37;在NVBench上,代码执行率从75%升至93%,可读性从2.64升至3.47,正确性从2.34升至3.28。
- 消融研究证实多模态奖励优化是关键;增加每输入的生成数量可提升稳定性与性能。
- 扩展性分析显示,Qwen2.5-3B与Llama-3.1-8B均获得一致提升,验证框架的模型无关性与可扩展性。
- 人工评估确认与自动评分高度一致(r = 0.88–0.91),验证所报告改进的有效性。
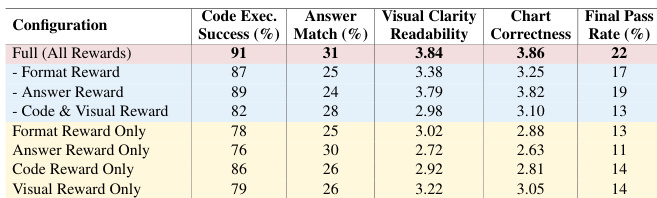
作者通过消融研究评估RL-Text2Vis框架中各奖励组件的贡献。结果表明,结合代码执行、答案匹配与视觉质量信号的完整多模态奖励,在所有指标上均取得最高性能,最终通过率22%,显著优于任一单一奖励组件。
作者使用RL-Text2Vis在Text2Vis基准上微调小型模型,包括Qwen2.5-3B与Llama-3.1-8B。结果表明,RL-Text2Vis在两类模型上均显著提升代码可执行性、视觉清晰度与图表正确性,证明该框架具备可扩展性与架构无关性能。

作者使用RL-Text2Vis框架在Text2Vis基准上训练Qwen2.5-7B与Qwen2.5-14B模型,相较于零样本与监督微调基线取得显著提升。结果表明,RL-Text2Vis-14B在关键指标上超越所有开源模型,并与GPT-4o等专有模型持平或超越,最终通过率29%,在视觉清晰度(4.10)与图表正确性(4.03)上得分极高。
作者使用RL-Text2Vis框架在Text2Vis基准上训练Qwen2.5模型,评估其在域外数据集(包括VIS-Eval、NVBench与PandasPlotBench)上的表现。结果表明,相较于零样本与监督微调基线,RL-Text2Vis在所有基准上显著提升代码执行成功率、视觉清晰度与图表正确性,14B模型在多数类别中取得最高分。

作者使用RL-Text2Vis训练7B模型,表明将每输入采样完成数从4增加至8可提升所有指标性能。采用8次采样的RL-Text2Vis-7B模型最终通过率达22%,优于4次采样版本(17%),并在代码执行成功率、答案匹配率、视觉清晰度与图表正确性上均表现更优。
