Command Palette
Search for a command to run...
编排一个动态物体的世界
编排一个动态物体的世界
Yanzhe Lyu Chen Geng Karthik Dharmarajan Yunzhi Zhang Hadi Alzayer Shangzhe Wu Jiajun Wu
摘要
在我们所处的物理四维(三维空间+时间)世界中,动态物体不断演化、形变,并与其他物体相互作用,从而呈现出丰富多样的四维场景动态。本文提出了一种通用的生成式流程——CHORD(CHOReographing Dynamic objects and scenes),用于建模与合成此类动态现象。传统的基于规则的图形生成流程依赖于特定类别启发式方法,虽能生成动态效果,但耗时费力且难以扩展。近年来的基于学习的方法通常需要大规模数据集,而这些数据集往往无法覆盖所有感兴趣的物体类别。相比之下,我们的方法借鉴了视频生成模型的通用性,提出了一种基于知识蒸馏的流程,从二维视频的欧拉(Eulerian)表征中提取隐藏的丰富拉格朗日(Lagrangian)运动信息。所提方法具有通用性、多功能性与类别无关性。通过大量实验,我们验证了其在生成多样化多体四维动态方面的有效性,展示了其相较于现有方法的显著优势,并进一步证明了其在生成机器人操作策略中的实际应用潜力。项目主页:https://yanzhelyu.github.io/chord
一句话摘要
斯坦福大学、剑桥大学和马里兰大学联合提出 CHORD,这是一种通用的、类别无关的生成式流程,能够从欧拉视频表示中提炼拉格朗日运动,以合成复杂的多体4D动态,实现可扩展、数据高效的动画与机器人操控策略生成,无需依赖类别特定规则或大规模数据集。
主要贡献
- 现有生成4D场景动态的方法受限于对类别特定规则的依赖或稀缺、范围狭窄的数据集,导致难以扩展,无法建模跨类别的多样化物体交互与形变。
- CHORD 引入了一种新颖的4D运动表示,具有分层空间结构和受芬威克树启发的累积时间设计,通过从视频模型中蒸馏实现稳定、连贯且多样的运动生成。
- 该框架通过生成物理基础的拉格朗日轨迹,实现零样本机器人操控,并在多样动态场景(包括多体交互与可变形物体)上表现优于先前方法。
引言
作者致力于解决生成真实、场景级4D动态——即随时间演化的3D物体运动——的挑战,其中多个物体发生形变并相互作用,这是具身人工智能与机器人技术的关键需求。现有方法受限于对类别特定规则的依赖、稀缺的4D交互数据,或无法在多样化物体类型间扩展。现有基于学习的方法难以处理高维、时间不规则的形变,且与现代视频生成模型存在不兼容问题。作者提出 CHORD,一种通用生成流程,通过将视频模型视为高层编舞者,从2D视频模型中蒸馏4D运动。其核心创新包括一种结合分层双层空间控制与受芬威克树启发的累积时间结构的新型4D运动表示,以强制平滑性与连贯性;以及一种针对基于流的视频模型的新蒸馏策略,通过得分蒸馏采样(Score Distillation Sampling)实现有效引导。该框架在无需类别特定先验的情况下生成物理上合理的多物体交互,并通过生成拉格朗日形变轨迹实现零样本机器人操控。
数据集

- 数据集包含从 Sketchfab 和 BlenderKit 获取的3D资产,静态场景快照在 Blender 中生成。
- 使用 gsplat 进行3D-GS渲染以初始化网格,并进行4D优化,视频生成由 Wan 2.2(14B)图像到视频模型驱动。
- 所有训练在 832 × 464 分辨率下进行,形变序列在41帧上优化。
- 控制点通过物体网格的有符号距离场(SDF)初始化,通过基于网格的占据检查提取物体内部的体素中心。
- 采用最远点采样结合K均值聚类确定控制点位置,初始尺度设为到最近三个邻居的平均距离;旋转初始化为单位矩阵。
- 训练过程中控制点位置固定,仅优化协方差矩阵(尺度与旋转)。
- 采用分阶段训练策略:在第100次迭代时,将第30帧之后的形变重新初始化为第30帧的状态,以提升稳定性。
- 学习率遵循对数线性衰减:形变与尺度参数从0.006衰减至0.00006,旋转从0.003衰减至0.00003,CFG尺度从25衰减至12,时间正则化权重从9.6衰减至1.6,空间正则化权重从3000衰减至300。
- 体素大小通过二分搜索自动确定,以确保每个物体表面附近约有7,500个体素中心。
- 每个资产训练2,000次迭代,批量大小为4,在NVIDIA H200 GPU上耗时约20小时。
- 对于机器人操控任务,直接扫描“捡香蕉”和“降灯”场景中的真实物体并用于流程。
- 对于难以精确扫描的情况,使用Blender创建与真实物体尺寸匹配的数字复制品。
方法
作者利用分层4D表示,从静态3D网格中蒸馏动态4D场景,采用针对修正流(RF)视频生成模型定制的改进得分蒸馏采样(SDS)框架。整体框架从输入网格开始,首先将其转换为3D高斯点云(3D-GS)表示,以促进平滑梯度计算。该3D-GS模型作为标准形状,用于初始化捕捉时间运动的4D表示。4D表示通过采样相机位姿、渲染对应视频并将其输入视频生成模型以获取优化梯度,进行迭代优化。该过程由为RF模型设计的新SDS目标引导,使优化目标与模型训练损失对齐。如图所示,该框架整合空间与时间正则化,以稳定优化过程并确保运动连贯性。
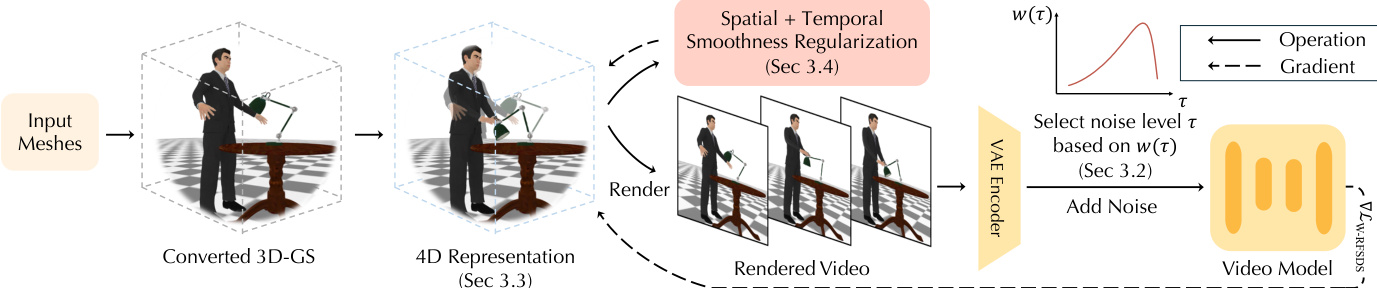
该方法的核心在于分层4D表示,旨在稳定复杂形变的优化。该表示由标准3D-GS几何结构和随时间变形的标准形状的4D运动分量组成。形变场通过一种新颖的分层控制点结构表示,降低高维空间形变场的维度。如图所示,该结构使用粗粒度控制点捕捉大尺度形变,细粒度控制点细化局部细节。每个控制点由均值位置和协方差矩阵定义,决定其影响半径。高斯点的形变通过线性混合皮肤法(linear blend skinning)对邻近控制点的变换进行加权混合计算。混合权重基于高斯点到控制点距离的高斯核确定。
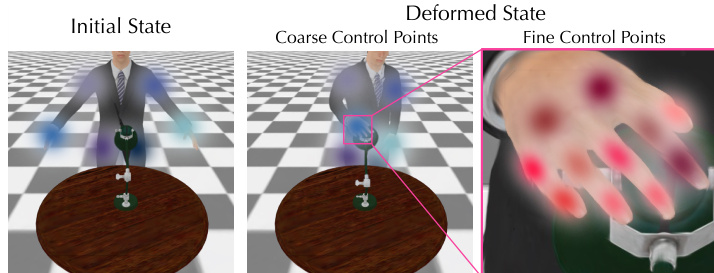
控制点的优化采用粗到细的方式,与噪声调度同步。在优化初期,噪声水平较高时,仅优化粗粒度控制点以生成显著运动。随着噪声水平降低,引入细粒度控制点以添加残差形变,从而细化局部细节。这种两阶段优化策略与SDS梯度的内在特性一致:在高噪声水平下梯度噪声较大,但在低噪声水平下更稳定。
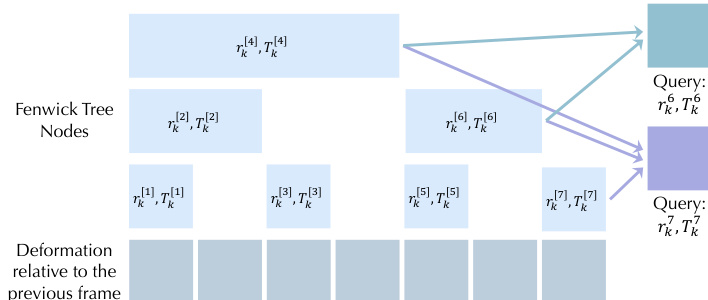
为进一步提升时间连贯性,作者引入基于芬威克树数据结构的时间层次结构。如图所示,每个控制点的形变序列被表示为芬威克树中的一组节点,每个节点编码特定帧范围内的累积形变。这种基于范围的分解允许不同帧的形变通过重叠区间共享参数,极大提升时间连贯性,并支持长时程运动学习。给定帧的最终形变通过组合芬威克树中所有相关节点获得。
优化过程通过两个正则化项进一步稳定。时间正则化损失通过从同一视角渲染3D光流图视频来定义,用于衡量运动的时间平滑性。空间正则化损失基于均匀分布于每个物体表面附近的点云,采用“尽可能刚性”(As-Rigid-As-Possible, ARAP)公式计算,以鼓励形变的局部空间一致性。这些正则化项被整合进整体优化框架,确保生成的运动在时间上连贯且在空间上合理。
实验
- 在包含多个相互作用物体的多样化动态场景上进行评估,与最先进基线方法对比:Animate3D、AnimateAnyMesh、MotionDreamer,以及基于TrajectoryCrafter的4D重建方法。
- 在六个场景动画中,使用VideoPhy-2进行定量评估,获得最高的语义一致性(SA)得分和第二高的物理常识性(PC)得分,99名参与者在用户研究中更倾向于我们的方法在提示对齐与运动真实感方面表现更优。
- 定性结果展示出出色的提示对齐与自然运动,优于存在错位、伪影或时间不一致问题的基线方法。
- 通过迭代帧传播扩展至长时程运动生成,使用真实视频训练模型实现真实物体动画,并基于密集物体光流指导刚体、关节体与可变形物体的机器人操控。
- 消融研究证实,噪声水平采样、芬威克树用于形变建模、分层控制点及正则化损失对防止伪影、闪烁与畸变至关重要。
- 在单物体动画任务中,50名参与者的用户研究显示,提示对齐偏好度达89.6%,运动真实感偏好度达84%,完整结果见补充表格。
- 失败案例主要源于底层视频生成器的局限性,以及无法生成初始静态场景中不存在的物体,导致运动缺失或不完整。
结果表明,所提方法 CHORD 在用户研究的两项指标——对齐度与真实感——上均取得最高分,全面超越所有基线。在VideoPhy-2评估中,CHORD在物理常识性上取得第二高分,在语义一致性上取得最高分,展现出优于现有方法的提示对齐能力与自然运动生成性能。
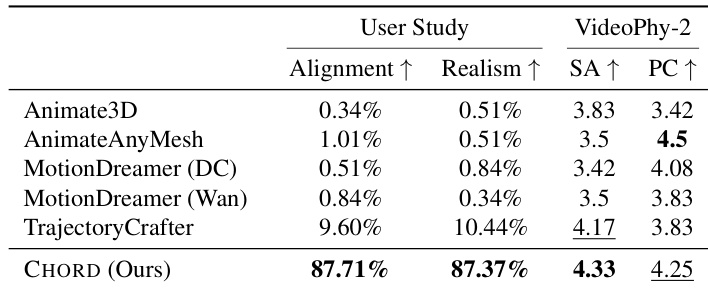
作者开展用户研究以评估提示对齐与运动真实感,与 Animate3D、AnimateAnyMesh、MotionDreamer 和 TrajectoryCrafter 等多个基线方法进行对比。结果表明,其方法在提示对齐方面获得最高平均分,在运动真实感方面获得第二高平均分,两项指标均优于大多数基线。
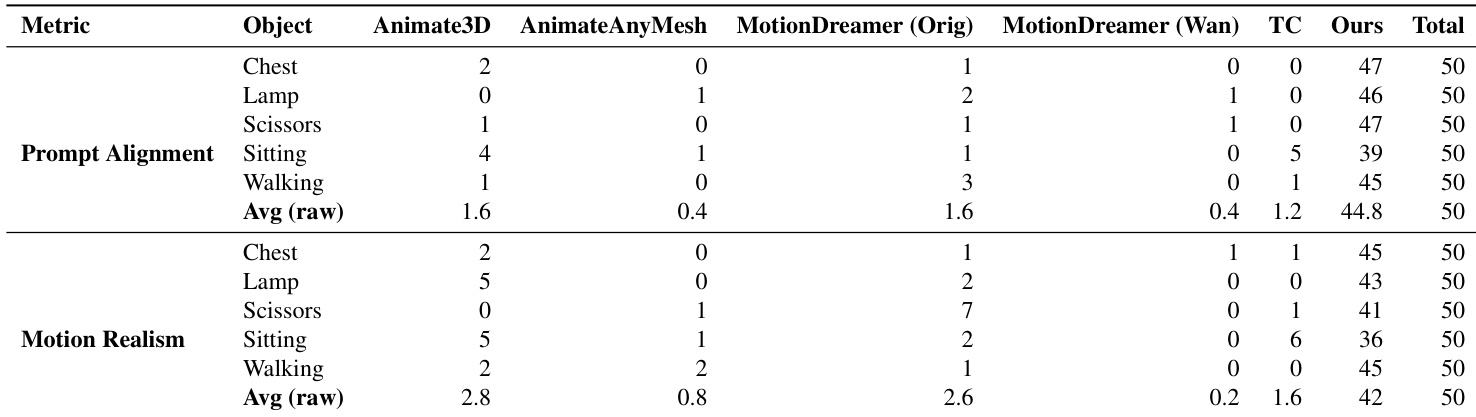
结果表明,所提方法在所有评估场景中均在提示对齐与运动真实感两项指标上取得最高平均分,全面超越所有基线。作者通过99名参与者的用户研究评估各方法,数据显示其方法在两项指标上均获得最多投票,且两项指标的平均分均最高。