Command Palette
Search for a command to run...
Benchmark^2:LLM基准测试的系统性评估
Benchmark^2:LLM基准测试的系统性评估
摘要
大规模语言模型(LLMs)评估基准的迅速涌现,催生了对系统性方法以评估基准自身质量的迫切需求。为此,我们提出 Benchmark²——一个包含三个互补指标的综合性评估框架:(1)跨基准排名一致性(Cross-Benchmark Ranking Consistency),用于衡量某一基准所生成的模型排名是否与同类基准保持一致;(2)区分度得分(Discriminability Score),量化基准区分不同模型能力的能力;(3)能力对齐偏差(Capability Alignment Deviation),用于识别在同一家族模型中,更强模型失败而较弱模型却成功的问题性样本。我们在涵盖数学、推理与知识三个领域的15个基准上开展了广泛实验,评估了来自四个模型家族的11个大型语言模型。分析结果揭示了现有基准在质量上存在显著差异,并表明基于我们提出的指标进行有选择性的基准构建,可在大幅缩减测试集规模的前提下,实现与传统方法相当的评估性能。
一句话总结
复旦大学、华盛顿大学圣路易斯分校与小红书公司联合提出 BENCHMARK²,一个包含三项指标——跨基准排名一致性(Cross-Benchmark Ranking Consistency)、可区分性得分(Discriminability Score)和能力对齐偏差(Capability Alignment Deviation)的框架,系统性评估大语言模型(LLM)基准测试,通过识别数学、推理和知识领域中高质量、低冗余的测试集,实现更可靠、高效的模型评估。
主要贡献
- 现有大语言模型基准测试存在严重缺陷,如模型排名不一致、难以区分模型性能差异,甚至出现弱模型优于强模型的反直觉现象,严重削弱其作为评估工具的可靠性。
- 本文提出 BENCHMARK² 框架,引入三项新指标:跨基准排名一致性(CBRC)、可区分性得分(DS)和能力对齐偏差(CAD),系统评估基准在排名一致性、区分能力和层级一致性方面的质量。
- 在 15 个基准和 11 个大语言模型(涵盖四个模型家族)上的实验表明,高质量基准可被有效识别,且利用这些指标进行选择性构建,仅需原始测试数据的 35% 即可达到相近的评估性能。
引言
大语言模型(LLMs)的评估高度依赖于基准测试,这些基准指导着数学、推理和知识等领域的研究与部署决策。然而,基准测试的快速涌现已远超系统性质量评估的速度,导致出现模型排名不一致、区分能力差、以及弱模型表现优于强模型等反直觉现象。以往工作虽针对数据污染或统计显著性等问题提出解决方案,但缺乏统一、量化的基准可靠性评估框架。本文提出 BENCHMARK²,一个包含三项指标的系统性框架:跨基准排名一致性(CBRC)用于衡量与同类基准的一致性,可区分性得分(DS)用于量化基准区分不同模型的能力,能力对齐偏差(CAD)用于检测排名不一致的测试项。在 15 个基准和 11 个大语言模型上的评估揭示了显著的质量差异,并表明通过这些指标筛选高质量测试实例,仅使用原始数据的 35% 即可实现相当的评估性能,为基准构建提供了更高效路径。
数据集

- 数据集包含 15 个公开基准,覆盖三个领域:数学(5 个基准)、通用推理(5 个基准)和知识与理解(5 个基准),均来自权威公开来源。
- 数学领域包括 AIME 2024、OmniMath、OlympiadBench、AMC 和 MATH-500;通用推理领域包括 Big-Bench Hard、DROP、ARC、CommonsenseQA 和 SIQA;知识与理解领域包括 SuperGPQA、MMLU-Pro、IFBench、IFEval 和 EQ-Bench。
- 作者采用基于质量的筛选策略,仅保留 CAD 分数高(表明反转率低)且可区分性贡献高的测试实例,最终得到的过滤后基准包含约原始实例的 35%。
- 过滤后的基准用于模型训练与评估,混合比例由基准质量得分(BQS)决定,BQS 综合三项指标:CAD(实例级能力层级一致性)、DS(内部区分能力)和 CBRC(外部一致性)。
- 为确保各指标尺度一致,CBRC 通过线性变换从 [-1, 1] 归一化至 [0, 1],而 DS 和 CAD 本身已在 [0, 1] 范围内。
- 最终 BQS 计算为加权和:0.3 × 归一化 CBRC + 0.3 × DS + 0.4 × CAD,其中 CAD 权重最高,因其直接衡量实例级基准质量。
方法
作者提出一个全面的框架 BENCHMARK2,通过解决三个核心挑战来评估语言模型基准的质量:排名不一致与偏差、性能差距区分能力弱,以及排名不一致项的普遍存在。该框架围绕三项互补指标构建,分别评估基准可靠性的不同方面。
参见框架图 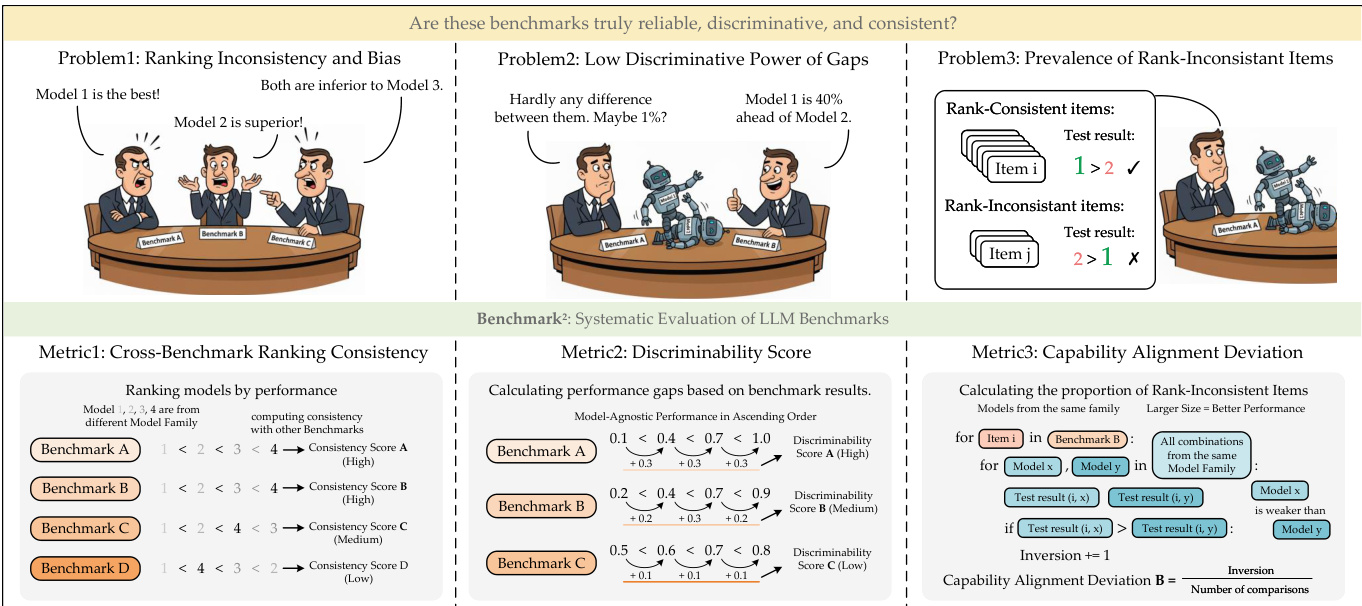 以了解三项问题及其对应指标的概览。第一项指标为跨基准排名一致性(CBRC),用于评估不同基准间模型排名的一致性。其通过比较模型在各基准上的相对表现,为每个基准计算一致性得分,得分越高表示模型排名越一致。
以了解三项问题及其对应指标的概览。第一项指标为跨基准排名一致性(CBRC),用于评估不同基准间模型排名的一致性。其通过比较模型在各基准上的相对表现,为每个基准计算一致性得分,得分越高表示模型排名越一致。
第二项指标为可区分性得分,量化基准区分不同性能水平模型的能力。如图所示,该得分通过分析模型间的性能差距计算,得分反映这些差距的大小。可区分性得分越高,表明基准越能有效区分模型,尤其在性能差异较小时。
第三项指标为能力对齐偏差(CAD),在实例层面识别可能因违反预期能力层级而存在问题的测试题。作者基于同一模型家族内的参数量定义模型层级,即大模型应优于小模型。对于给定基准,反转率通过统计强模型未能正确回答而弱模型成功回答的实例数计算。该比率经指数函数变换后生成 CAD 得分,得分越高表示与预期能力层级越一致。CAD 公式为 CAD(Bi)=e−λ⋅inv_rate(Bi),实验中取 λ=12 以确保有效区分。
最后,通过加权聚合归一化后的 CBRC、可区分性得分和 CAD,得到综合的基准质量得分(BQS),权重分别为 α、β 和 γ,从而实现对基准质量的全面评估。
实验
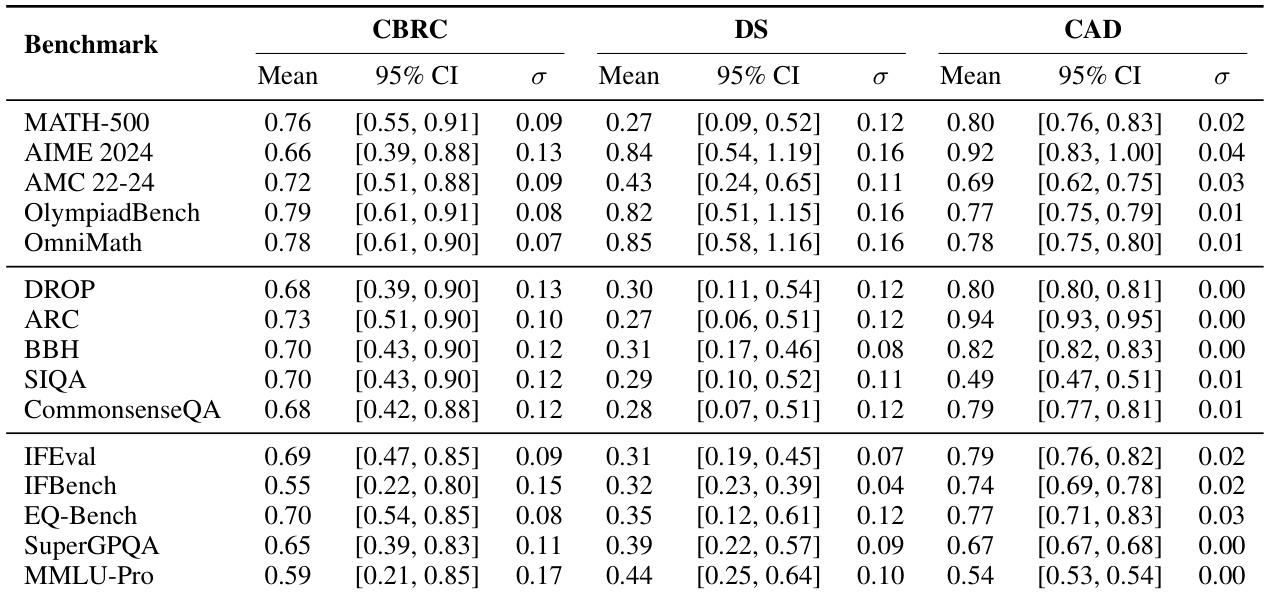
- AIME 2024 在可区分性(DS = 0.74)和能力对齐(CAD = 0.85)方面表现优异,验证其在数学领域区分模型能力的有效性。
- BBH 展现出较强的可区分性(DS = 0.25),但对齐性较低(CAD = 0.66),凸显通用推理中两项指标间的权衡。
- IFEval 和 SuperGPQA 在各领域表现一致,跨基准一致性高(CBRC > 0.75),表明其评估可靠性强。
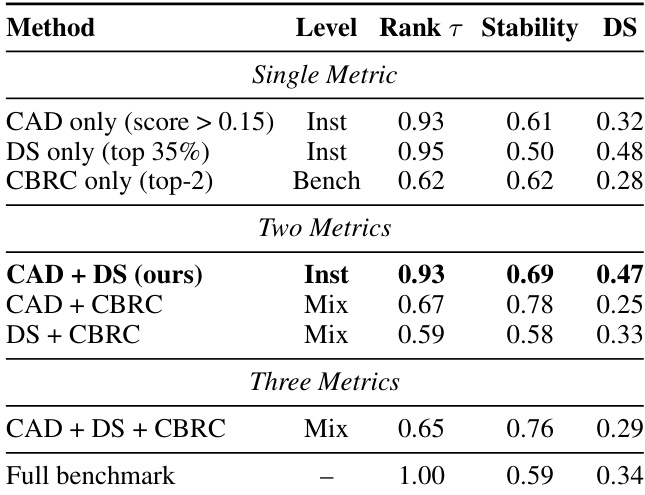
- 仅使用 35% 实例进行选择性评估,仍保持高排名一致性(Kendall’s τ = 0.93)和更高稳定性(0.69),优于完整基准(0.59),验证实例选择的高效性。
- CAD + DS 组合在实例选择中表现最佳,兼具高排名一致性(0.93)、稳定性提升(0.69)和良好可区分性(0.47)。
- 在 Qwen2.5-Base 模型上的留出验证确认了泛化能力,数学领域排名几乎完全保留(Avg |ΔRk| = 0.0),各模型家族表现一致。
- Llama 模型在多个基准上表现出近乎完美的 CAD(如 AIME:1.00),而 Qwen3 变化较大,SIQA 始终得分低(CAD = 0.20–0.27),表明其设计存在缺陷。
- 采用客观评估标准的基准获得更高 CAD 分数,高质量基准(如 AIME 2024,BQS = 0.79)在可区分性、对齐性和一致性之间取得良好平衡。
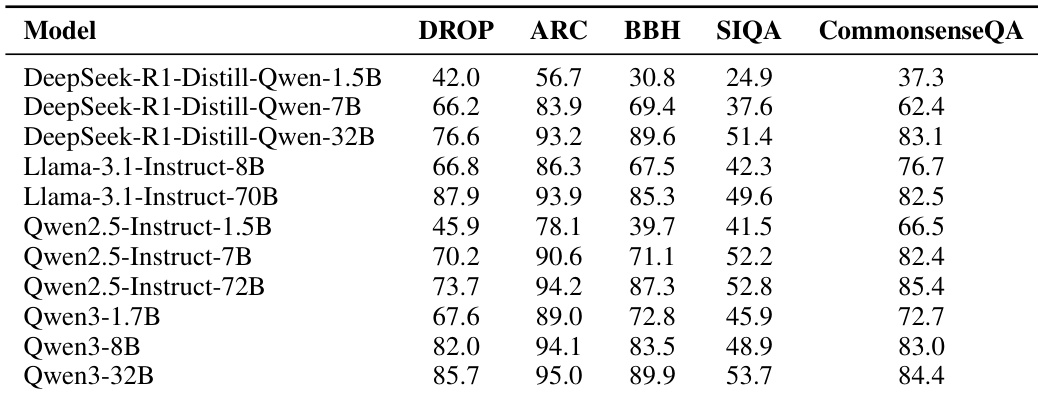
作者利用所提供表格分析模型在五个通用推理基准上的表现,显示各模型家族内部存在清晰的能力层级。结果表明,大模型始终优于小模型,Qwen3-32B 在多数基准上取得最高分,表明各家族均呈现显著的规模扩展行为。
结果表明,AIME 2024 基准在可区分性得分(DS = 0.84)和能力对齐偏差(CAD = 0.92)方面均达到最高,表明其能有效区分模型并高度契合家族内能力层级。相比之下,SIQA 和 BBH 等基准的可区分性和对齐性较低,反映出其在各模型家族中整体质量较弱。
作者通过多指标组合评估选择性基准构建的有效性。结果表明,CAD + DS 组合在排名一致性(τ = 0.93)和稳定性(0.69)方面表现最优,同时保持良好可区分性(DS = 0.47),优于单一指标方法及其他多指标组合。
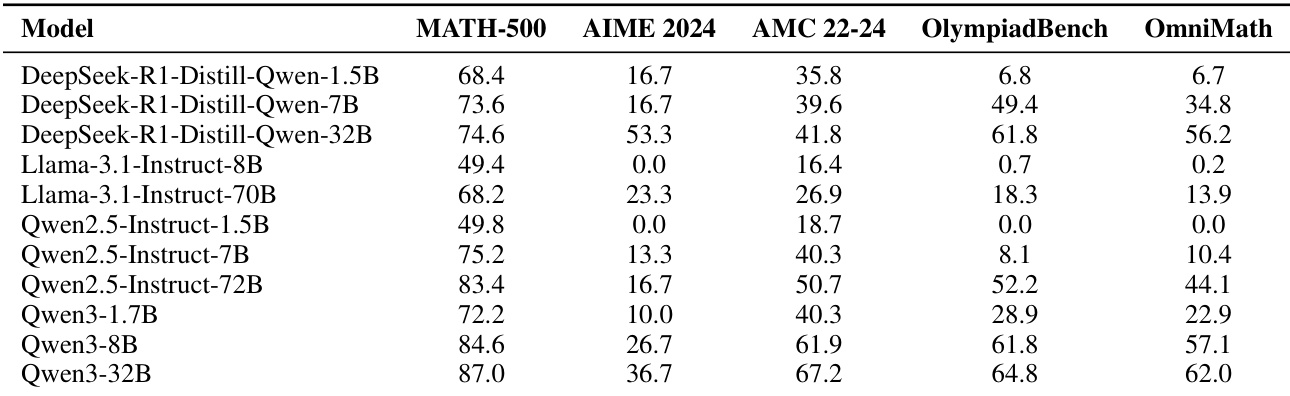
作者利用所提供表格分析模型在五个数学基准上的表现,显示各模型家族内部存在清晰的能力层级。结果表明,大模型始终优于小模型,Qwen3-32B 在多数基准上取得最高分,性能趋势与预期的模型规模扩展行为一致。
作者通过系统性分析确定能力对齐偏差(CAD)指标中 λ 参数的最优值,基于中位映射、质量分离和动态范围保持等五项标准评估候选值。结果表明,λ = 12 获得最高总分 0.68,实现强质量分离、对优秀基准的完美奖励以及对劣质基准的完全惩罚,是将原始反转率转化为可解释 CAD 得分的最佳选择。