Command Palette
Search for a command to run...
Atlas:面向多领域复杂推理的异构模型与工具编排
Atlas:面向多领域复杂推理的异构模型与工具编排
Jinyang Wu Guocheng Zhai Ruihan Jin Jiahao Yuan Yuhao Shen Shuai Zhang Zhengqi Wen Jianhua Tao
摘要
大型语言模型(LLMs)与外部工具的融合显著拓展了AI智能体的能力边界。然而,随着LLMs和工具种类的日益多样化,如何选择最优的模型-工具组合已成为一个高维优化难题。现有方法通常依赖单一模型或固定的工具调用逻辑,难以充分挖掘异构模型-工具组合之间的性能差异。本文提出ATLAS(Adaptive Tool-LLM Alignment and Synergistic Invocation),一种面向跨领域复杂推理任务的动态工具使用双路径框架。ATLAS采用双路径机制:(1)无需训练的基于聚类的路由策略,利用经验先验实现领域特定的模型-工具对齐;(2)基于强化学习的多步路由机制,通过自主探索轨迹实现分布外(out-of-distribution)的泛化能力。在15个基准测试上的大量实验表明,本方法在性能上超越了闭源模型GPT-4o,在分布内任务(+10.1%)和分布外任务(+13.1%)上均显著优于现有路由方法。此外,通过协调专用的多模态工具,本框架在视觉推理任务中也展现出显著性能提升。
一句话总结
清华大学与浙江大学的作者提出ATLAS,一种用于自适应工具-大语言模型对齐的双路径框架,结合免训练的基于聚类的路由与基于强化学习的多步优化,实现跨多样化领域的动态、高性能工具选择,在分布内和分布外推理任务上均优于GPT-4o,包括通过专用多模态工具实现的视觉推理。
主要贡献
- 本文解决了在复杂跨领域推理任务中动态选择最优模型-工具组合的挑战,现有方法因固定调用逻辑或孤立优化而无法有效利用异构大语言模型(LLMs)与外部工具之间的协同效应。
- 提出了ATLAS,一种双路径框架,结合免训练的基于聚类的路由——利用经验性领域先验实现高效分布内对齐——与基于强化学习的多步路由,实现自主探索与分布外泛化能力。
- 在15个基准测试上评估,ATLAS在分布内任务上比闭源模型GPT-4o和最先进的路由方法高出10.1%,在分布外任务上高出13.1%,在通过协调多模态工具使用实现的视觉推理方面表现尤为突出。
引言
将大语言模型(LLMs)与外部工具集成,已使AI代理具备更强能力,但随着模型与工具多样性增加,选择最优模型-工具组合成为高维挑战。先前方法要么固定工具调用逻辑,要么孤立地路由模型,无法充分利用异构模型与工具之间的协同效应,且在开放领域或分布外场景中缺乏适应性。作者提出ATLAS,一种双路径框架,通过结合免训练的基于聚类的路由——利用领域特定性能先验实现高效分布内决策——与基于强化学习的多步路由——探索最优轨迹以实现泛化——动态协调模型-工具对。该统一方法实现了跨多样化任务的自适应、可扩展协调,相比闭源模型GPT-4o和现有路由方法,在分布外基准测试上最高提升13.1%,同时在通过多模态工具集成实现的视觉推理方面也表现出显著优势。
数据集

- 数据集涵盖数学、算术、代码生成、常识、逻辑、科学及多模态推理等多个基准任务,详见表4。
- AIME 2024和2025(MAA, 2024, 2025)各包含30道高级数学题,需高水平问题求解与计算能力,面向顶尖高中生推理水平。
- AMC(Lightman等, 2023)包含40道选择题,评估基础数学推理与计算能力。
- Calculator(Wu等, 2025b)包含1,000道复杂算术题,评估模型识别何时调用外部工具及正确解释计算输出的能力。
- HumanEval(Chen, 2021)包含164道手工设计的编程题,附函数签名、文档字符串和单元测试,测试从自然语言精确合成代码的能力。
- MBPP(Austin等, 2021)包含974道众包Python题目,面向初级程序员,要求编写简短、功能正确的代码片段,涉及循环和条件等基本结构。
- Natural Questions(NQ)(Kwiatkowski等, 2019)包含来自Google搜索的真实用户查询及配对的维基百科文章,评估知识密集型信息检索与整合能力。
- Web Questions(WebQ)(Berant等, 2013)提供1,000道源自网络搜索查询的事实性问题,测试对外部知识库的推理能力。
- LogiQA2(Liu等, 2023)包含1,572道来自标准化考试的多选逻辑推理题,评估演绎、归纳与溯因推理能力。
- GPQA(Rein等, 2024)包含448道专家撰写的生物、物理和化学多选题,旨在挑战博士级领域知识与深层理解。
- ChartQA(Masry等, 2022)包含关于柱状图、折线图和饼图的问题,测试从视觉数据中进行数值推理的能力。
- Geometry3K(Lu等, 2021)提供3,000道带图示标注的几何题,评估视觉-几何推理与数学原理应用能力。
- TallyQA(Acharya等, 2019)包含现实图像中的复杂计数问题,需空间推理与选择性注意。
- CountBench(Paiss等, 2023)聚焦于杂乱、遮挡或相似物体场景中的精确物体计数,强调鲁棒的视觉计数能力。
- TableVQA(Kim等, 2024)包含跨领域的表格问题,测试对结构的理解、相关数据提取及表格内容推理能力。
- 作者使用这些数据集构建一个各领域比例均衡的训练混合数据集,确保覆盖多样化的推理能力。
- 训练过程中,模型暴露于多步路由过程,根据任务类型动态选择推理、工具使用或直接响应。
- 每个数据集均处理以提取任务特定元数据,包括问题类型、所需推理模式和工具依赖性。
- 对视觉数据集,图像经过预处理以确保一致的分辨率和格式,问题-答案对与图示或表格上下文对齐。
- 框架采用策略驱动的路由机制(算法2)引导模型完成推理步骤、工具调用与最终答案解析,并通过轨迹追踪提供训练反馈。
方法
ATLAS框架采用两级架构以应对多样化的查询复杂度,结合免训练的基于聚类的路由机制(实现低延迟决策)与基于强化学习的多步路由策略(适用于复杂迭代任务)。整个系统运行于混合推理引擎中,协调一组大语言模型(LLMs)与外部工具,根据查询的领域和所需推理深度动态调整策略。
第一级为免训练的基于聚类的路由,实现快速实时决策。该方法利用历史查询数据预计算查询空间的语义聚类。在训练阶段,查询通过预训练编码器投影至潜在流形,并通过最小化惯性将嵌入空间划分为K个互不相交的聚类,如以下公式定义:
{μk}k=1Kmink=1∑Kvi∈Ck∑∥vi−μk∥2,其中μk为聚类Ck的中心点。对每个聚类及每一对可能的模型-工具组合(m,t),提取经验统计数据,包括成功率(准确率)和操作成本。成本基于平均token吞吐量及输入输出token的单位价格计算。随后定义聚类级效用分数Uk(m,t),以平衡性能与成本:
Uk(m,t)=(1−α)⋅Acck(m,t)−α⋅Costk(m,t).在推理阶段,新查询被嵌入并分配至最近的聚类中心。通过最大化该聚类内的效用分数,选择最优模型-工具组合。该过程在框架图中展示:查询被嵌入、聚类,然后路由至路由池中表现最佳的组合。
第二级为基于强化学习的多步路由,专为需要迭代推理与动态工具调用的复杂任务设计。该策略将路由过程建模为序列决策任务,其中由策略πθ引导的智能体维护一个不断演化的状态,包含查询与累积上下文。智能体的动作空间包括两类:内部推理(think),即本地思维链处理;动态路由(route),即从路由池中选择一对模型-工具以获取外部信息。此迭代循环持续进行,直至生成最终答案或达到最大步数限制。策略通过近端策略优化(PPO)训练,以最大化复合奖励函数,该函数平衡结构化执行、任务正确性与路由效率。奖励函数定义如下:
rϕ=Rfmt+γRout+ξRsel,其中Rfmt强制执行语法规则,Rout提供任务正确性的二元信号,Rsel惩罚次优模型的选择。训练过程在图中展示:策略LLM通过一系列think与route动作与环境交互,奖励信号反馈至PPO更新机制。

实验
- ATLAS(cluster)在分布内任务上达到63.5%的平均准确率,比RouterDC高出10.1%,在AIME25(40.0% vs. 53.1%)和AMC(82.5% vs. 63.0%)上均优于GPT-4o,表明通过语义聚类与经验先验实现的强任务-配置对齐。
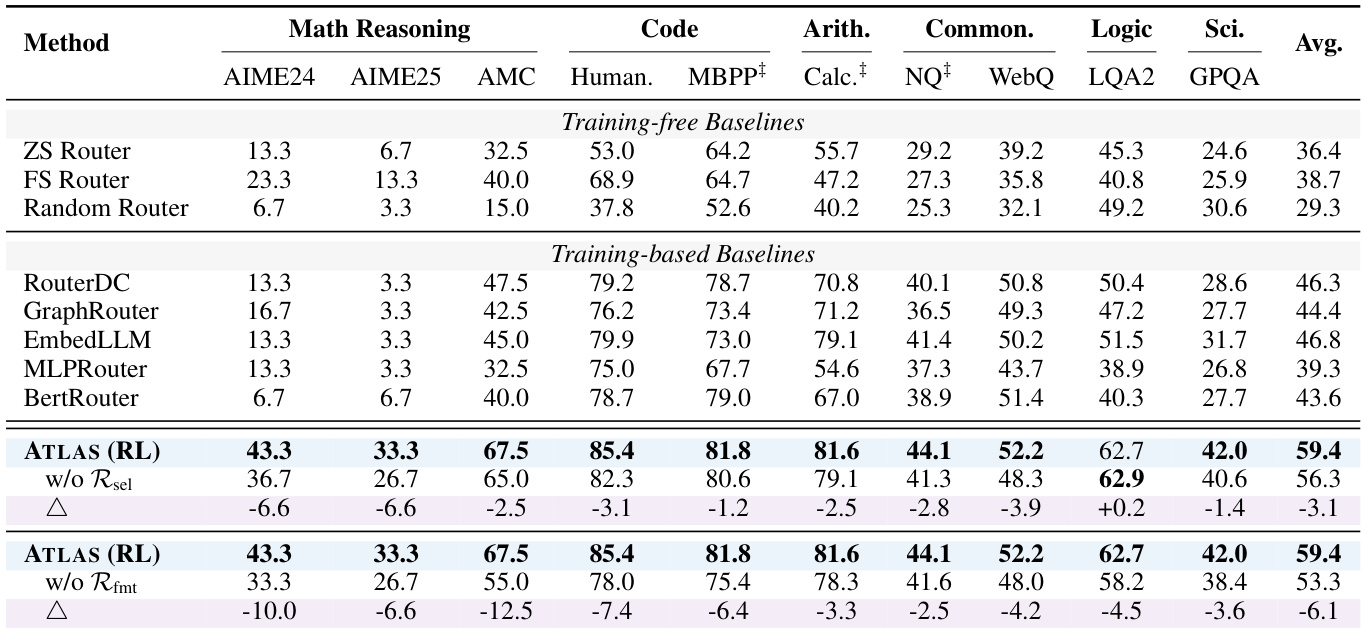
- ATLAS(RL)在分布外设置中保持59.4%的平均准确率,比ATLAS(cluster)(49.2%)高出10.2%,比RouterDC(46.3%)高出13.1%,在AIME24和AIME25上分别达到43.3%和33.3%的准确率,表明通过可迁移路由策略实现的优越泛化能力。
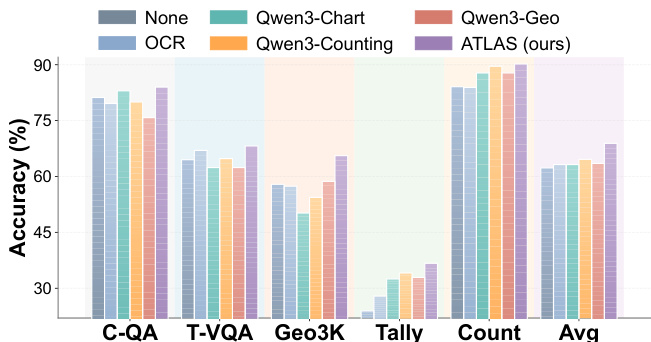
- 在多模态任务上,ATLAS达到68.9%的平均准确率,比最强的单工具基线高出4.3%,在所有类别中均超越单一工具,包括ChartQA的83.0%和Geometry3K的50.2%,验证了动态工具编排的有效性。
- 在动态扩展模型-工具池(增加医疗、数学与验证工具)后,ATLAS(RL)准确率从59.4%提升至61.7%,在AIME24和AIME25上分别提升+6.7%,而基线模型表现有限或下降,证实无需重训练即可实现稳健适应性。
- ATLAS(RL)在pass@1上达到59.4%的准确率,比零样本路由(36.4%)提升23.0%,在pass@16时达到63.1%,表明接近最优的推理能力与高效探索,训练动态中奖励收敛更快、熵更低。
- 强化学习训练使API调用模式具备任务自适应性:复杂任务(AIME25、GPQA)调用次数高,简单检索任务(WebQ、NQ)调用次数极少,有效平衡性能与推理成本。
作者使用ATLAS在五个视觉推理数据集上评估多模态工具编排,结果表明动态路由优于单工具基线。结果显示,ATLAS在所有任务中达到最高平均准确率68.9%,比最佳单工具基线高出4.3%,在每个任务类别中均超越所有单一工具。
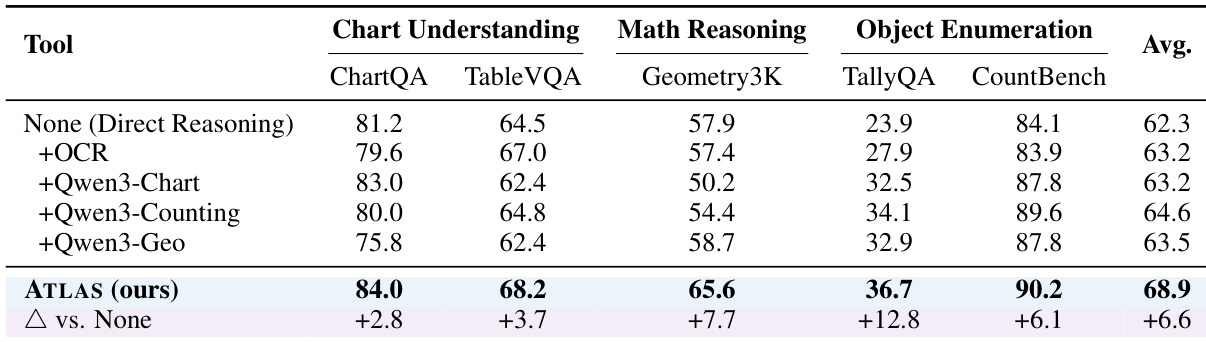
结果表明,ATLAS(RL)在多样化基准测试中表现出强大的推理性能,随着自洽性采样增加,Pass@1准确率显著提升,在SC@16时于AIME24上达到70.0%。该框架展现出接近最优的推理能力,即使在高采样数下,性能增益仍持续存在,表明高效探索与高质量解的快速收敛。
作者使用ATLAS(cluster)在分布内设置中实现63.5%的平均准确率,比最强基线RouterDC高出10.1%,并在多个任务上优于GPT-4o。在分布外设置中,ATLAS(RL)保持59.4%的平均准确率,显著高于ATLAS(cluster)的49.2%,证明其卓越的泛化能力。
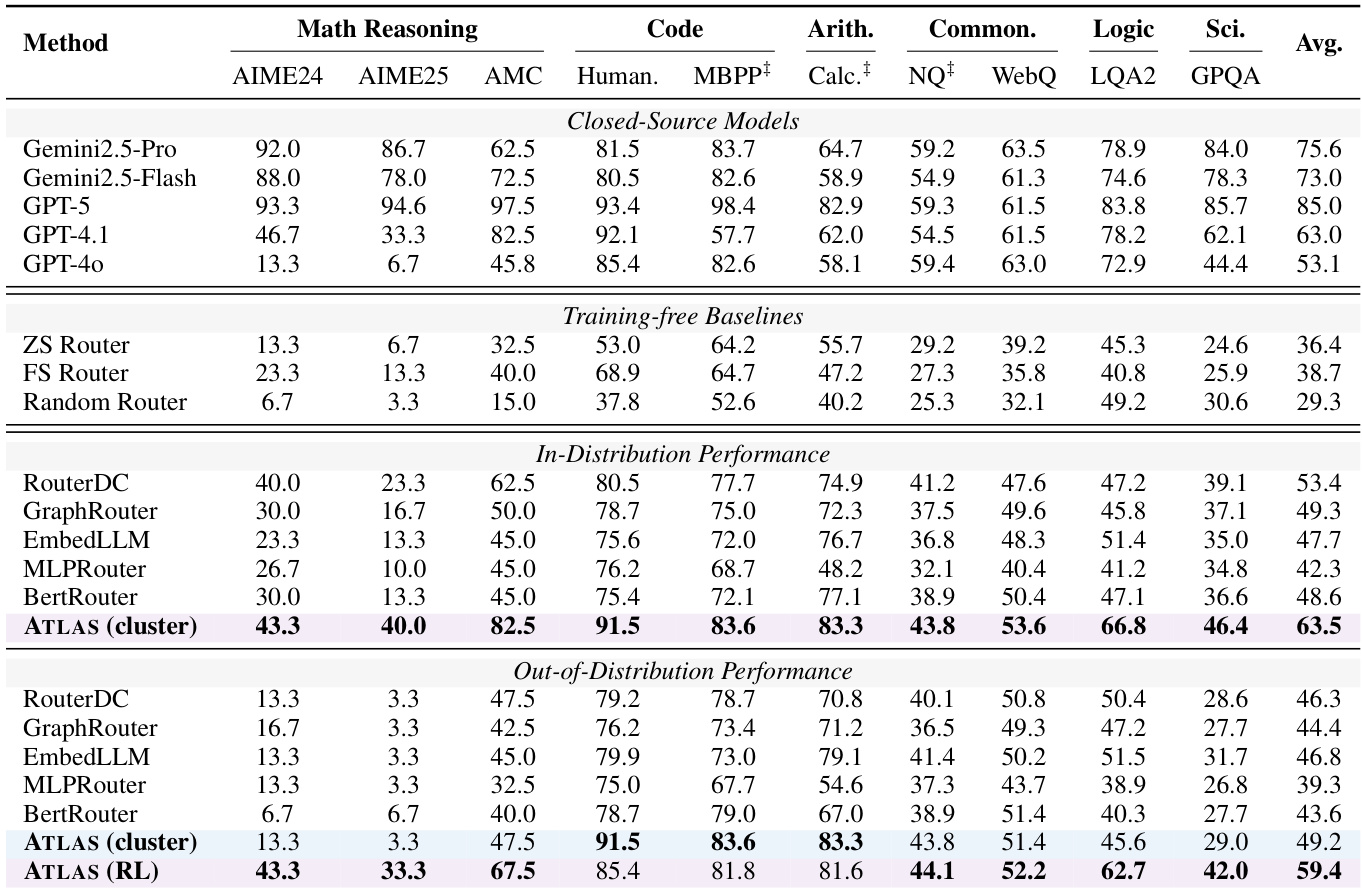
结果表明,ATLAS(RL)在所有任务上达到最高平均准确率59.4%,显著优于所有免训练与训练型基线。消融研究显示,选择奖励与格式奖励对最优性能至关重要,其移除导致准确率大幅下降,尤其在数学与代码生成任务上。
作者使用ATLAS在多模态推理任务中动态路由查询至多个工具与模型,相比单工具基线在所有基准测试中均取得最高准确率。结果表明,ATLAS在每个任务类别中持续优于单一工具,验证了自适应模型-工具编排在融合内部推理与外部工具增强方面的有效性。