Command Palette
Search for a command to run...
大语言模型在持续预训练过程中如何学习概念?
大语言模型在持续预训练过程中如何学习概念?
Barry Menglong Yao Sha Li Yunzhi Yao Minqian Liu Zaishuo Xia Qifan Wang Lifu Huang
摘要
人类主要通过概念(如“狗”)来理解世界,这些概念是抽象的心理表征,能够组织感知、推理与学习过程。然而,大型语言模型(LLMs)在持续预训练过程中如何获取、保留以及遗忘这些概念,目前仍缺乏深入理解。在本研究中,我们系统探讨了单个概念的习得与遗忘机制,以及多个概念之间通过干扰与协同作用所产生的交互关系。我们将这些行为动态与模型内部的“概念电路”(Concept Circuits)相联系——即与特定概念相关的计算子图,并引入图论度量方法来刻画电路的结构特征。我们的分析揭示了以下关键发现:(1)LLMs中的概念电路能够提供非平凡且具有统计显著性的概念学习与遗忘信号;(2)在持续预训练过程中,概念电路呈现出阶段性的时间演化模式,表现为初期增长、随后逐步下降并趋于稳定;(3)在后续训练中,学习增益较大的概念往往表现出更显著的遗忘现象;(4)语义上相近的概念之间产生的干扰效应强于语义关联较弱的概念;(5)不同概念的知识在可迁移性方面存在差异,部分概念能显著促进其他概念的学习。综上所述,本研究从电路层面揭示了概念学习的动力学机制,为设计更具可解释性与鲁棒性的概念感知型训练策略提供了理论依据。
一句话总结
加州大学戴维斯分校、弗吉尼亚理工学院、加州大学洛杉矶分校与Meta AI的作者提出了一种大语言模型中概念学习与遗忘的电路级分析,揭示了概念电路——与特定概念相关的计算子图——具有阶段式动态、语义干扰和可迁移性,通过基于图的特征刻画概念间交互,实现了可解释且稳健的训练策略。
主要贡献
-
本研究首次系统性地探讨了大语言模型在持续预训练过程中概念的获取与遗忘,将行为动态与内部的概念电路——与特定概念相关的计算子图——相联系,并证明这些电路的图度量能提供学习与遗忘的统计显著信号。
-
研究揭示了概念电路存在阶段式的时间模式:在持续训练初期先上升,随后逐渐下降并趋于稳定,表明概念巩固经历了不同阶段;同时发现学习增益较大的概念往往伴随更严重的后续遗忘。
-
识别出概念间的干扰与协同效应,发现语义相似的概念引发更强的干扰,而某些类型的概念知识(如上下位关系)能显著迁移并提升其他类型知识(如同义/反义关系)的学习效果,提示可设计干扰感知的训练调度策略。
引言
大语言模型(LLMs)正越来越多地在不断演化的数据上进行持续训练,但它们如何学习、保留并遗忘抽象概念(如“狗”或“正义”)仍知之甚少。这一点至关重要,因为概念级知识是下游任务中推理、泛化与鲁棒性的基础。以往研究多集中于孤立事实的静态探测或单个组件的局部可解释性,缺乏对概念在持续训练过程中如何演化与交互的动态、系统级视角。作者通过引入FICO数据集——一种基于ConceptNet生成的合成概念,具有真实的关系结构——填补了这一空白,以支持受控实验。他们利用机制可解释性提取概念电路,即与特定概念相关的计算子图,并使用图度量追踪其结构演化。关键发现表明,概念电路在训练过程中表现出阶段式的时间动态,初期增长后趋于稳定;更强的初始学习与更大的后续遗忘相关,揭示了获取强度与保留能力之间的权衡;语义相似的概念干扰更强,而某些知识类型可高效迁移至其他类型。这些洞见为理解概念学习动态提供了电路级框架,并为设计更稳定、高效、可解释的持续预训练流程提供了可行策略。
数据集

- 该数据集名为FICO(虚构概念),围绕1,000个概念构建——其中500个来自THINGS数据集的具象概念,500个来自Concreteness Ratings数据集的抽象概念——每个概念均关联ConceptNet中的事实知识,ConceptNet是一个包含数百万概念关系的大规模知识图谱。
- ConceptNet中原始的细粒度关系被归类为五种高层知识类型:上下位关系(分类/定义性)、同义与反义关系(相似性/对比性)、部分与整体关系(部分-整体)、属性与功能关系(属性与用途)、空间关系(位置相关)。因果与事件、词汇/词源及其他类别的关系被过滤,以聚焦于稳定、以概念为中心的知识。
- 为减少模型对预存知识的依赖,每个真实概念名称均被GPT-5生成的虚构名称替代,同时保留底层概念知识。这确保模型学习的是语义关系而非记忆现实术语。
- 训练阶段,每个知识三元组通过GPT-5生成的自然语言模板转换为多个前缀-目标样本(例如,“{概念}具有……的能力”用于CapableOf),共生成92,250个训练样本,来自3,075个三元组,总计104万token。模型训练10个epoch,共1040万训练token。
- 评估阶段,使用一组互不重叠的500个概念和独立的模板池,生成13,530个测试token,来自1,586个知识三元组,用于评估对新表面形式和潜在关系理解的泛化能力。
方法
作者采用一种将预训练大语言模型(LLM)建模为有向无环图(DAG)的框架,其中节点代表计算组件(如神经元、注意力头、嵌入层),边表示通过残差连接、线性投影等操作的交互。在此框架下,概念电路被定义为能够基于源自主语-关系对的文本前缀,忠实预测知识三元组目标对象的最小计算子图。在概念级分析中,作者将概念电路定义为负责预测与特定概念相关所有知识三元组的子图,从而作为该概念在模型参数记忆中的内部表征。
为在持续训练的不同检查点识别这些概念电路,作者采用EAP-IG方法,该方法在计算效率与归因忠实度之间取得平衡,为边分配重要性得分。电路通过选择得分最高的边构建,使得最终子图在相关概念上的性能至少保留全模型性能的70%。
这些概念电路的结构特性通过四类图论度量进行量化。节点重要性通过特征向量中心性的标准差衡量,反映节点间结构影响力分布的不均衡性;方差越高,表明结构越集中于枢纽节点。冗余性通过图密度评估,即实际边数与最大可能边数之比,值越高表示连接越冗余。信息流效率由全局效率捕捉,定义为节点对间最短路径距离的平均倒数,值越高表示信号传播越高效。鲁棒性则通过平均k-核数代理,衡量密集连接核心的深度,反映对扰动的抵抗能力。
实验设计包含两个阶段的持续预训练过程。第一阶段(概念获取):将预训练LLM π0 在FICO数据集上训练,以获取新概念,得到模型π1。第二阶段(遗忘诱导):将π1 在BIO数据集上进一步训练,诱导遗忘,生成模型π2。作者通过比较π0 与π1 分析概念学习动态,比较π1 与π2 分析遗忘动态。知识学习与遗忘程度在知识三元组层面定义为训练后目标对象logit的变化;概念层面程度则计算所有相关三元组的平均值。分析在两个开源LLM上进行:GPT-2 Large 和 LLaMA-3.2-1B-Instruct。评估时仅提供文本前缀,模型需在FICO测试集上生成目标短语。使用Spearman相关系数评估概念学习/遗忘动态与概念电路拓扑之间的关系。
实验
- 在FICO数据集上,500个概念的学习与遗忘程度差异显著,分布呈单峰但广泛分散,表明在相同训练条件下,不同概念的获取与保留能力存在差异。
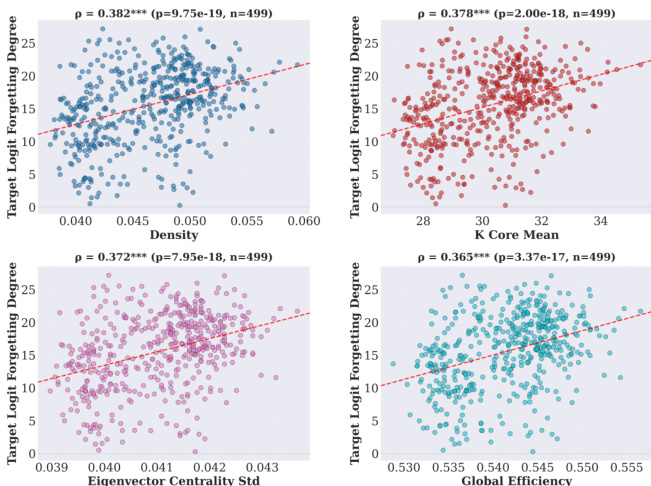
- 强Spearman相关性(p < 0.001)将概念学习/遗忘程度与电路图度量联系起来:更高的特征向量中心性、k-核、密度和全局效率虽增强学习,但也加剧遗忘,揭示了学习强度与稳定性之间的结构性权衡。
- 在持续训练过程中,概念电路表现出阶段式时间模式——图度量先上升,随后逐渐下降并趋于稳定——表明系统性重组而非简单衰减。
- 学习程度更高的概念也表现出更高的遗忘程度,表明激进获取的知识更易受干扰,尤其在以枢纽节点为主导的高集成电路中。
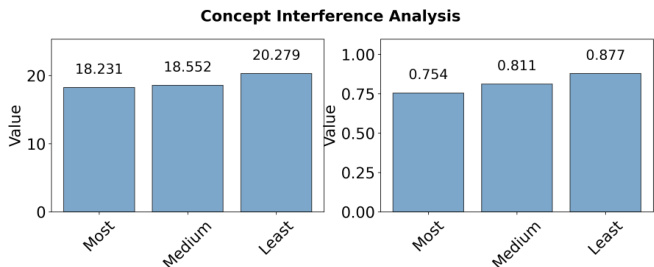
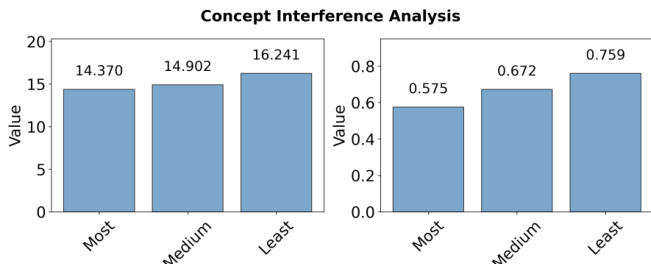
- 与高度相关概念联合训练时性能显著下降(平均logit:57.5%),低于弱相关(75.9%)或中等相关(67.2%)概念,这是由于电路重叠增加和表征竞争加剧所致,表现为边集的Jaccard相似性更高。
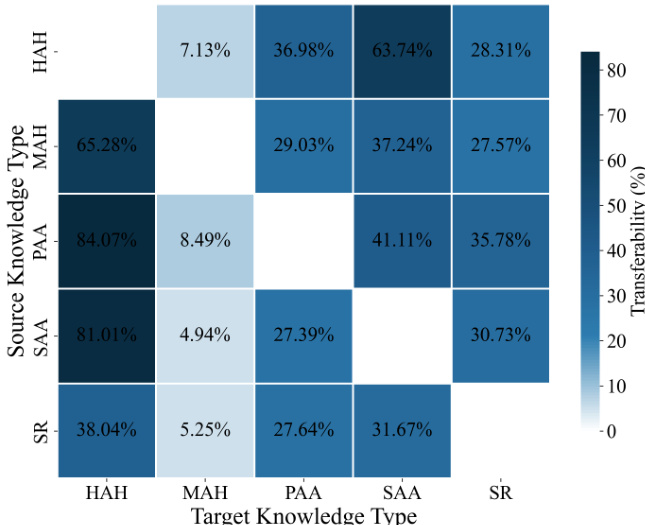
- 跨知识类型训练揭示了不对称且显著的迁移效应:在属性与功能(PAA)上预训练能显著提升上下位(HAH)和同义/反义(SAA)的学习,而反向迁移较弱,表明可通过知识类型顺序设计实现协同效应,提升学习效率。
作者通过概念干扰分析考察语义相关性对联合训练中概念学习的影响。结果表明,与高度相关概念联合训练时性能更低(平均logit:14.370,平均概率:0.575),低于与弱相关概念训练(平均logit:16.241,平均概率:0.759),表明语义相似概念间干扰更强。
作者采用成对持续训练设置,考察五类高层知识类别间的迁移效应,将成对可迁移性定义为从源知识类型过渡到目标知识类型时的性能增益或损失。结果表明存在显著且不对称的迁移效应:在属性与功能(PAA)上预训练对上下位(HAH)和同义/反义(SAA)带来显著增益,而反向迁移较弱,表明不同知识类型间存在方向性与非均衡收益。
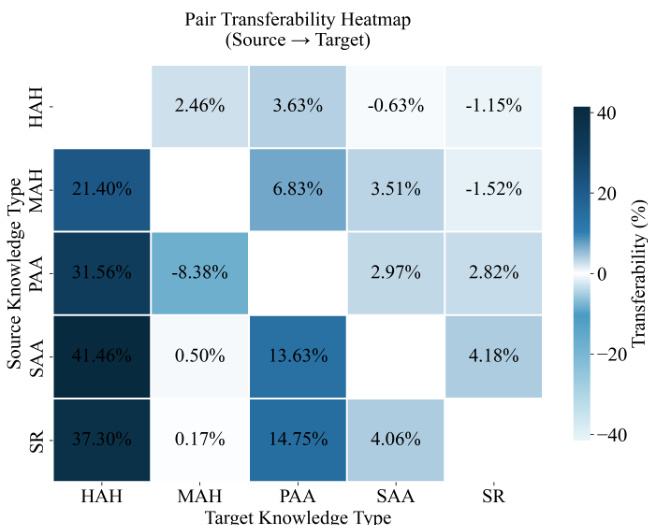
作者使用热力图可视化持续训练过程中五类高层知识类型间的成对可迁移性,显示某一类型预训练可促进或阻碍另一类型的学习。结果表明存在显著且不对称的迁移效应,某些源-目标对表现出强正向迁移,如从属性与功能到上下位,而其他对则表现出微弱或负向效应,凸显知识获取中的方向依赖性。
作者使用散点图分析多个电路图度量下概念学习程度与遗忘程度之间的相关性。结果表明学习与遗忘程度之间存在一致的正相关关系,对于密度、k-核均值、特征向量中心性标准差、全局效率等度量,均观察到统计显著的Spearman相关性,表明学习越强的概念越容易遗忘。
作者利用提供的柱状图分析联合训练中的概念干扰,显示与高度相关概念联合训练时性能低于与弱相关概念联合训练。左图显示,训练时概念间相关性最低时平均logit值最高;右图显示,平均概率在相关性最低条件下也最高,确认语义相关性对概念获取具有负面影响。