Command Palette
Search for a command to run...
InfiniDepth:基于神经隐式场的任意分辨率与细粒度深度估计
InfiniDepth:基于神经隐式场的任意分辨率与细粒度深度估计
Hao Yu Haotong Lin Jiawei Wang Jiaxin Li Yida Wang Xueyang Zhang Yue Wang Xiaowei Zhou Ruizhen Hu Sida Peng
摘要
现有的深度估计方法本质上局限于在离散图像网格上预测深度值。这类表示方式限制了其在任意输出分辨率下的可扩展性,并阻碍了几何细节的恢复。本文提出InfiniDepth,将深度表示为神经隐式场(neural implicit fields)。通过一个简单而高效的局部隐式解码器,我们能够在连续的二维坐标上查询深度,从而实现任意分辨率和细粒度的深度估计。为更全面地评估本方法的性能,我们从五款不同游戏构建了一个高质量的4K合成基准数据集,涵盖多样化的场景,具有丰富的几何与外观细节。大量实验表明,InfiniDepth在合成数据和真实世界数据的相对深度与度量深度估计任务中均达到当前最优性能,尤其在细粒度区域表现突出。此外,该方法在大视角变化下的新视角合成任务中也展现出显著优势,能够生成高质量结果,同时减少孔洞与伪影。
一句话总结
浙江大学、理想汽车与深圳大学的研究团队提出 InfiniDepth,一种基于神经隐式场的深度表示方法,支持任意分辨率和细粒度的深度估计,在合成与真实场景下均优于以往基于网格的方法,尤其在大视角变化下的新视角合成任务中表现显著提升。
主要贡献
- InfiniDepth 提出一种基于神经隐式场的新颖深度表示方法,可在任意二维坐标上实现连续且局部化的深度查询,克服了传统离散网格方法在分辨率与细节上的局限性。
- 该方法在相对深度与度量深度估计的合成与真实世界基准上均达到最先进性能,尤其在细粒度区域表现显著提升,其有效性在新构建的高频率深度掩码的 Synth4K 4K 基准上得到验证。
- InfiniDepth 通过引入一种按表面面积比例分配亚像素查询预算的深度查询策略,显著提升大视角变化下的新视角合成效果,实现空间均匀的三维点分布,减少孔洞与伪影。
引言
研究团队利用神经隐式场表示深度,实现连续且任意分辨率的深度估计——解决了以往依赖离散二维网格方法的关键局限。此类网格方法将输出分辨率限制在训练图像尺寸,并因上采样平滑或局部建模不足而损失精细几何细节。InfiniDepth 通过轻量级、局部化的隐式解码器,结合视觉 Transformer 的多尺度特征,在任意连续二维坐标上查询深度,实现高频率细节的精确恢复。该方法还引入一种深度查询策略,按表面面积比例分配亚像素查询预算,生成空间均匀的三维点云,显著提升大视角变化下的新视角合成质量,减少孔洞与伪影。为严格评估高分辨率与细粒度性能,研究团队构建了 Synth4K,一个包含多样化场景与真实深度标签的 4K 合成基准,展示了在相对与度量深度估计任务上的最先进结果。
数据集

- 数据集包含 Synth4K,一个从五款视频游戏构建的高分辨率合成基准:《赛博朋克2077》(Synth4K-1)、《漫威蜘蛛侠2》(Synth4K-2)、《迈尔斯·莫拉莱斯》(Synth4K-3)、《死亡岛》(Synth4K-4)和《看门狗》(Synth4K-5)。
- 每个子集包含数百对 4K 分辨率(3840×2160)的 RGB-D 图像,涵盖多样化的室内外环境,具有高保真图形与真实光照效果。
- 深度图通过 ReShade 提取,该工具可访问游戏渲染管线,在游戏运行时捕获高质量深度缓冲区。
- 为支持细粒度评估,研究团队基于深度数据计算多尺度拉普拉斯能量图,构建高频率(HF)掩码。
- 对每个深度图,使用不同尺度的高斯模糊生成多个平滑版本,并通过四邻域模板计算绝对拉普拉斯响应。
- 最终能量图通过各尺度像素最大值取值获得,并以第 98 百分位数进行归一化,以降低异常值影响。
- 采用基于温度的锐化步骤调整能量图对比度,较低温度可增强几何细节的突出表现。
- 高频率像素的采样概率由锐化后的能量图决定,通过多项式采样选取 n 个候选位置。
- HF 掩码用于聚焦几何丰富区域的评估,实现对细粒度深度估计的精准衡量。
- 训练阶段使用包括 MatrixCity、MVS-Synth、Blend-mvs、CREStereo、FSD 和 DynamicReplica 在内的多种数据集混合,此外还包含主论文中提及的数据。
- 训练混合数据采用特定比例平衡,以确保在多样化场景与几何结构上的鲁棒泛化能力。
- 训练与评估过程中均未进行图像裁剪,所有数据均以原生 4K 分辨率使用。
- 保留场景类型、游戏来源与深度分辨率等元数据,用于指导数据选择与分析。
方法
研究团队采用神经隐式场框架,将深度表示为二维图像坐标上的连续函数,以输入 RGB 图像为条件。该方法将深度估计建模为 dI(x,y)=Nθ(I,(x,y)),其中 Nθ 是一个神经网络,将图像平面上任意连续坐标 (x,y) 映射为深度值。网络以多尺度局部隐式解码器的形式实现,通过重新组装并聚合视觉 Transformer(ViT)编码器多个层级的特征,预测任意查询点的深度。整体框架如以下示意图所示。
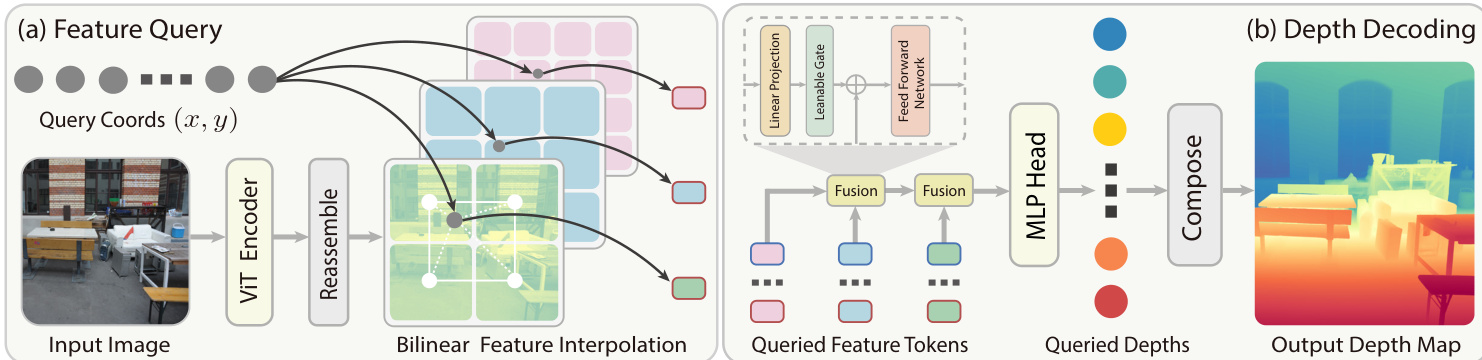
解码器包含两个主要模块:特征查询与深度解码。在特征查询阶段,输入图像经 ViT 编码获得一组特征 token。一个重组装模块从多个 ViT 层提取特征,并将其投影至不同隐藏维度。浅层特征被上采样至更高空间分辨率,以捕捉精细局部细节;深层特征则保留其原始分辨率,以保持全局语义。该过程构建特征金字塔 {fk}k=1L,其中 fk∈Rhk×wk×Ck。对于连续查询坐标 (x,y),在每个尺度 k 上对应的坐标为 (xk,yk)=(x⋅wk/W,y⋅hk/H)。在每个尺度上,定义局部网格邻域 Nk(xk,yk),并使用双线性插值聚合特征,生成查询坐标的特征 token f(x,y)k。
在深度解码阶段,多尺度局部描述符 {f(x,y)k}k=1L 从浅层到深层进行分层融合。融合从最浅层特征 h1:=f(x,y)1 开始。对于每个尺度 k=1,…,L−1,残差门控融合模块将 hk 与下一尺度特征 f(x,y)k+1 结合,生成融合特征 hk+1。该模块定义为 hk+1=FFNk(f(x,y)k+1+gk⊙Linear(hk)),其中 Linear(⋅) 负责特征维度投影,gk 为可学习的通道门控,⊙ 表示逐元素乘法。FFN 由两层前馈网络构成,包含非线性激活函数。该分层融合过程最终在最深层生成融合特征 hL,随后通过 MLP 头预测深度值 dI(x,y)。
研究团队引入无限深度查询策略,以解决像素级深度预测中固有的密度不平衡问题,该问题源于透视投影与表面朝向。核心思想是将亚像素查询预算按每个像素对应的三维表面面积进行分配。自适应权重 w(x,y) 定义为 w(x,y)=dI(x,y)2/∣n(x,y)⋅v(x,y)∣+ε,其中 dI(x,y) 为查询深度,n(x,y) 为表面法向量,v(x,y) 为单位视图方向。表面法向量通过隐式深度场的可微性,从反投影三维点 X(x,y) 的雅可比矩阵计算得出。权重 w(x,y) 近似于微分表面面积 ΔS(x,y),从而生成均匀分布的点云。基于 w(x,y) 选择亚像素查询坐标的详细过程见补充材料。
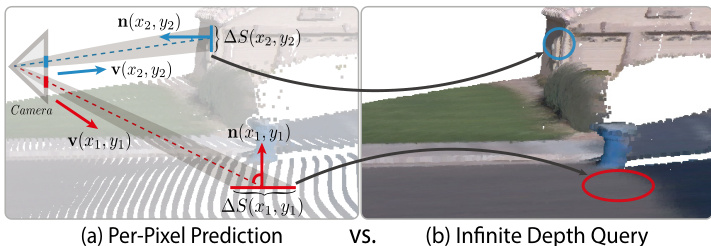
由无限深度查询生成的均匀三维点云随后由高斯点绘(GS)头处理。该头为每个点注入来自输入图像的颜色与普吕克射线特征,结合 ViT 编码器特征形成点级 token,并通过 MLP 处理每个 token。输出送入多个独立的线性头,预测高斯属性,包括位置偏移、颜色偏移、尺度、不透明度与旋转,从而实现高质量的新视角合成。训练过程包含深度归一化,将真实深度值转换至对数空间后进行仿射不变归一化。InfiniDepth 模型通过从原始真实深度图中每张图像采样 10 万组坐标-深度对进行训练,GS 头使用 1×10−4 学习率,基于 l1 重建损失与感知 LPIPS 损失进行训练。
实验
- 在五个真实世界数据集(KITTI、ETH3D、NYUv2、ScanNet、DIODE)和 Synth4K 上进行零样本相对深度估计,于 Synth4K 上达到最先进性能,δ0.5、δ1 与 δ2 指标均显著提升,尤其在全 4K 分辨率与细粒度预测方面表现突出。
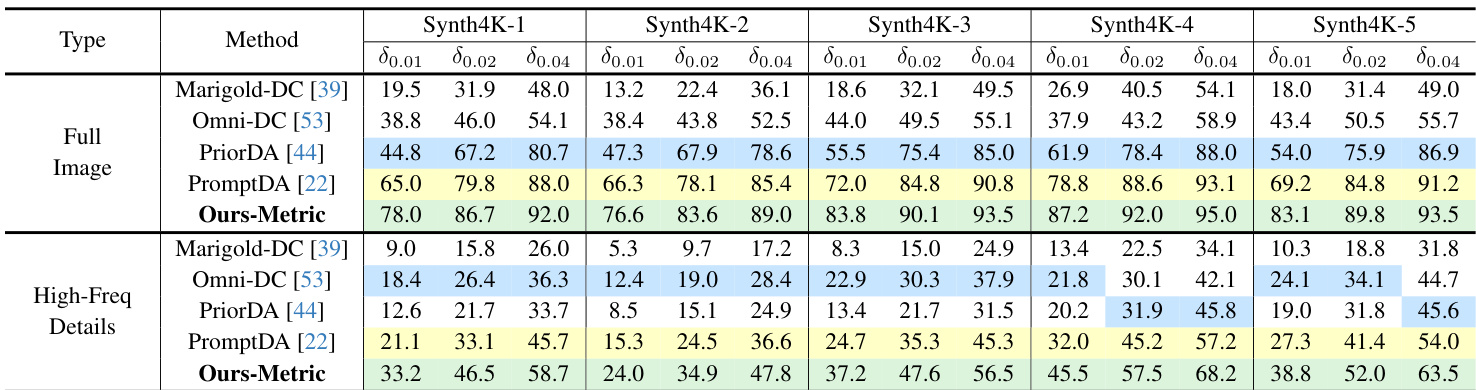
- 在稀疏深度输入(Ours-Metric)下实现度量深度估计的有效性,优于现有方法,在 Synth4K 与真实世界数据集上均显著提升 δ0.01、δ0.02 与 δ0.04 准确率。
- 消融实验表明,神经隐式深度表示显著提升度量深度估计与细粒度细节恢复能力,而隐式解码器中的多尺度特征查询与双线性插值在极低开销下实现最优性能。
- 通过结合 InfiniDepth 与轻量级高斯点绘头,实现大视角变化下更优的单视图新视角合成,生成更完整、伪影更少的重建结果,优于 ADGaussian。
- 保持计算效率,采用轻量级解码器,在速度与细节质量上均优于其他细粒度深度方法,尽管推理速度略慢于部分轻量级基线。
研究团队对比了亚像素监督与像素级监督在度量深度估计中的效果,结果表明亚像素监督在所有数据集上均持续提升性能。结果显示,亚像素监督精度更高,其中 DIODE(97.6 vs. 97.2)与 Synth4K-4(81.5 vs. 80.6)提升最为显著。

研究团队采用神经隐式场表示进行深度估计,结果表明该方法在所有数据集上均显著优于无隐式场的基线模型,尤其在高分辨率与细粒度深度预测方面表现突出。完整模型在相对与度量深度估计中均取得更高精度,最显著提升出现在 Synth4K 与真实世界基准上。

研究团队使用表格分析神经隐式场与多尺度特征查询对深度估计性能的影响。结果表明,包含神经隐式场的完整模型在所有数据集上达到最高精度,尤其在 Synth4K 上提升显著;而移除多尺度查询则导致性能明显下降,尤其在高分辨率数据上更为显著。

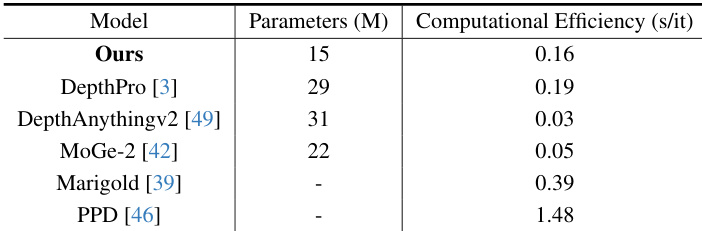
研究团队将本方法与多个最先进深度估计模型在计算效率与参数量上进行对比。结果表明,本模型在所有对比方法中参数量最低,同时保持了具有竞争力的计算效率,在参数效率与细节质量上均优于其他细粒度深度估计方法。
结果表明,Ours-Metric 在 Synth4K 的全图与高频率细节区域的所有指标上均表现最佳,显著优于所有基线方法,在零样本相对与度量深度估计中展现出卓越的准确率与细粒度细节恢复能力,尤其在高频区域表现突出,充分验证了其在高分辨率深度预测中的有效性。