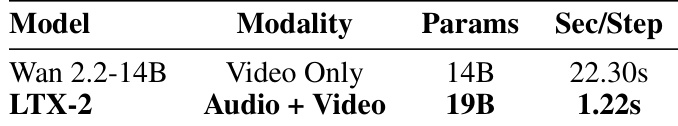Command Palette
Search for a command to run...
LTX-2:高效联合音视频基础模型
LTX-2:高效联合音视频基础模型
摘要
近期的文本到视频扩散模型能够生成引人入胜的视频序列,但普遍存在一个关键缺陷:生成内容始终无声,缺乏音频所承载的语义、情感与氛围线索。为此,我们提出LTX-2——一个开源的基础模型,可统一生成高质量、时序同步的音视频内容。LTX-2采用非对称双流Transformer架构,其中视频流拥有140亿参数,音频流为50亿参数,二者通过双向音视频交叉注意力层连接,并引入时间位置编码与跨模态AdaLN机制,实现共享时间步条件控制,从而在保证高效训练与推理的同时,为视频生成分配更多模型容量。我们采用多语言文本编码器以增强对多样化提示的理解,并提出一种模态感知的无分类器引导机制(modality-CFG),显著提升音视频之间的对齐精度与生成可控性。除语音生成外,LTX-2还能生成丰富且连贯的音频轨道,精准匹配场景中角色、环境、风格与情绪特征,包含自然背景音与拟音(Foley)元素,实现高度沉浸式的视听体验。在各项评估中,LTX-2在开源模型中达到了最先进的音视频质量与提示遵循能力,其性能可与专有模型相媲美,但所需计算资源与推理时间仅为后者的极小部分。目前,所有模型权重与源代码均已公开发布,致力于推动音视频生成技术的开放发展。
一句话总结
Lightricks 旗下的作者提出了 LTX-2,一个统一的开源音视频扩散模型,采用异构双流 Transformer 架构(14B 视频流与 5B 音频流),通过模态感知的无分类器引导和跨模态 AdaLN,实现时间同步、情感连贯的丰富音轨生成(包含背景音与拟音效果),在计算成本极低的情况下达到开源模型的最先进性能。
主要贡献
- 现有文本到视频(T2V)模型生成的视频视觉效果出色但无声,缺乏同步音频带来的语义与情感深度;LTX-2 通过引入统一的开源文本到音视频(T2AV)模型,联合生成高保真音视频内容,填补了这一空白。
- 模型采用异构双流 Transformer 架构,分别配置 140 亿参数的视频流与 50 亿参数的音频流,通过双向音视频交叉注意力与模态感知的无分类器引导连接,实现高效训练与精确的音视频对齐与可控性。
- LTX-2 在开源系统中实现了最先进的音视频质量与提示遵循能力,可生成包含语音、拟音与环境音的丰富连贯声景,同时在性能上媲美专有模型,但计算成本与推理时间显著更低。
引言
近期文本到视频(T2V)扩散模型的发展已实现高度逼真且时间连贯的视频生成,但这些系统仍为无声状态,缺乏对沉浸式与语义丰富内容至关重要的同步音频。尽管文本到音频(T2A)模型已向通用能力演进,但多数仍局限于特定领域;现有音视频生成方法依赖解耦流水线——先生成视频再添加音频(V2A),或反之——无法建模视觉与听觉之间的双向依赖关系,导致同步性差、环境声学不一致、生成质量欠佳。作者提出 LTX-2,一种高效的联合音视频基础模型,通过解耦但集成的双流架构克服上述局限。该模型采用模态专用的 VAE 对视频与音频分别进行潜空间表示,采用异构 Transformer 设计,根据各模态复杂度动态分配计算资源,并通过 1D 时间 RoPE 的双向交叉注意力实现音视频对齐的亚帧级精度。深层多语言文本编码器确保语音合成准确、富有表现力,具备正确的口型同步与情感语调。最终成果是一个高保真、计算高效的 T2AV 模型,可统一端到端生成同步的语音、音乐与拟音效果,性能超越对称或专有模型,同时支持灵活的编辑工作流,如 V2A 与 A2V。
数据集

- 数据集源自 LTX-Video [11] 使用数据的子集,筛选标准为具有丰富且信息量大的音频内容的视频片段,确保视觉与听觉元素的均衡表达。
- 音频以 16 kHz 采样率的立体声信号处理,每通道独立计算梅尔频谱图,并沿通道维度拼接,以保留空间音频信息。
- 音频自编码器将这些立体声梅尔频谱图转换为紧凑的潜空间,生成的潜变量令牌每个代表约 1/25 秒的音频,编码为 128 维向量。
- 采用定制的视频字幕系统,通过捕捉每一处显著的视觉与听觉细节——包括对话中的说话人、语言与口音识别、环境音、音乐、摄像机运动、光照与主体行为——生成高保真、多模态描述,同时保持事实准确性,避免情感解读。
- 最终形成的多模态语料库,结合处理后的音频潜变量与详细字幕,构成 LTX-2 的训练数据,其中音频潜变量序列与对应字幕以混合比例使用,支持跨模态联合学习。
- 视频与音频未进行显式裁剪;数据以原始时间片段处理,元数据直接由字幕系统构建,以精确对齐文本描述与音频/视觉事件。
方法
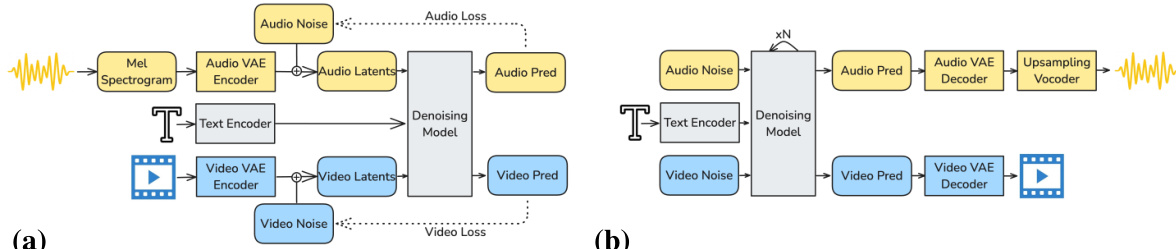
作者采用基于扩散的框架建模文本、视频与音频信号的联合分布,实现同步音视频内容生成。整体系统架构如框架图所示,包含三个主要组件:用于信号压缩的模态专用变分自编码器(VAE)、优化的文本条件化流水线,以及用于联合去噪的异构双流扩散 Transformer(DiT)。流程始于将原始音频与视频输入编码为紧凑的潜空间表示。音频首先转换为 16 kHz 的梅尔频谱图,再由因果音频 VAE 压缩为潜变量的时间序列。视频由时空因果 VAE 编码器处理,生成包含空间与时间信息的 3D 潜变量序列。这些潜变量经线性投影至 Transformer 内部维度后,输入双流 DiT 主干网络。
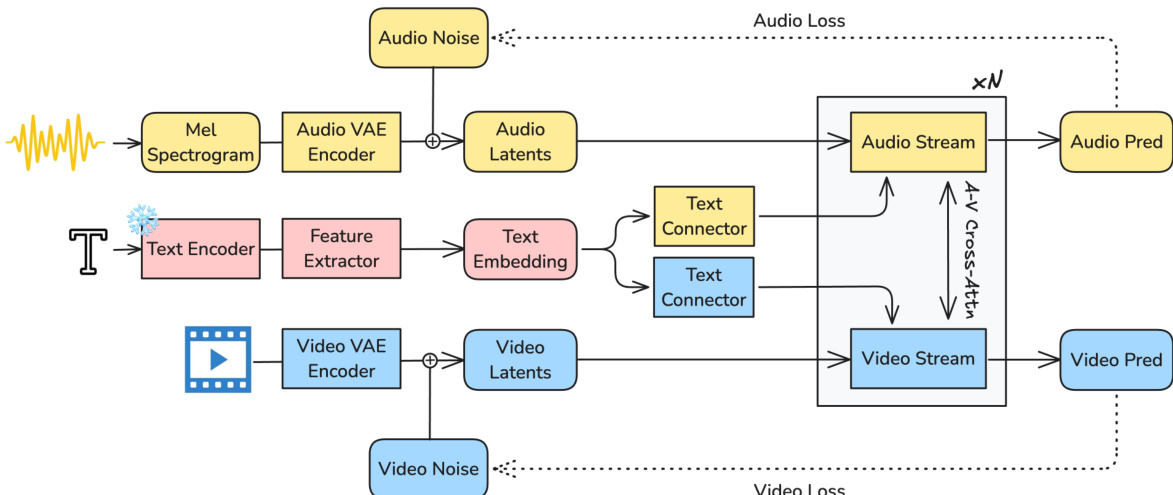
模型核心为异构双流 DiT 架构,视频与音频潜变量通过专用流并行处理。视频流(140 亿参数)专为处理高信息密度的视觉数据设计,音频流(50 亿参数)则优化于效率。每一流通过一系列 DiT 块处理其对应潜变量。每个块内的操作顺序包括:同模态自注意力、基于提示的文本交叉注意力、音视频交叉注意力以实现模态间信息交换,以及用于优化的前馈网络。视频流采用 3D 旋转位置编码(RoPE)以编码时空动态,音频流则使用 1D 时间 RoPE,反映两模态在结构上的差异。这种异构性确保模型大部分容量分配给更复杂的视频生成任务。
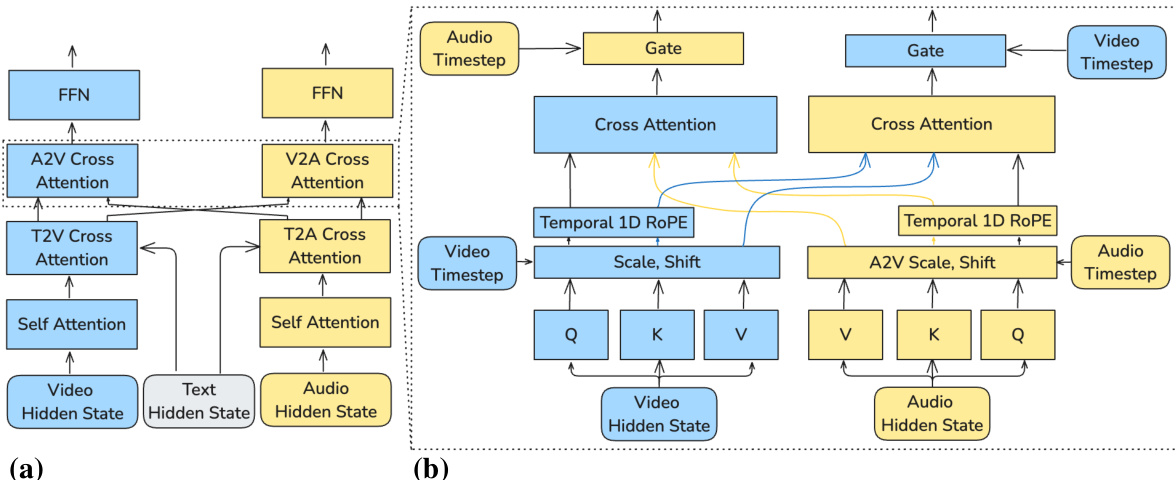
双向音视频交叉注意力机制(如图所示)是模型实现同步的核心。在每一层,该模块实现视频与音频流之间的信息流动。两模态的隐藏状态被投影为查询、键与值。查询与键随后由跨模态 AdaLN 门控调制,其缩放与偏移参数由另一模态的隐藏状态决定。这使得每个模态能够控制自身表示对另一模态的响应程度。时间旋转编码应用于查询与键,以沿共享时间轴对齐其位置,确保跨模态注意力聚焦于时间同步。经过注意力计算的表示再通过额外的 AdaLN 门控,其参数依赖于另一模态的时间步,有效调节去噪过程中跨模态信息的融合。

为增强文本条件化,模型采用超越简单嵌入的复杂流水线。文本提示首先由 Gemma3-12B 解码器-only 语言模型编码。不使用最后一层输出,而是提取所有解码器层的中间特征,捕捉从语音到语义的多层次语言信息。这些特征经聚合后,通过可学习投影矩阵映射至统一嵌入空间。随后,文本连接器模块(由具备全双向注意力的 Transformer 块构成)处理文本嵌入,并通过附加一组可学习的“思考令牌”进行优化。这些令牌作为全局信息载体,使模型可生成额外的上下文聚合令牌或补充缺失信息,从而提升扩散过程的条件信号质量。每个流使用独立的文本连接器,确保模态特定的条件化。
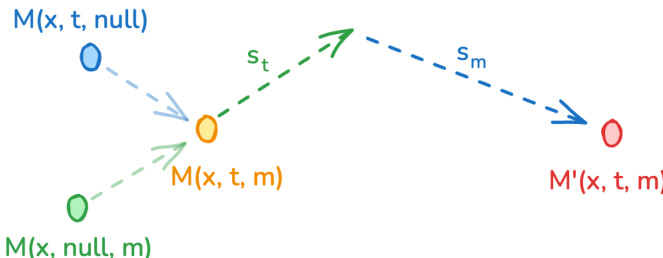
推理阶段,模型采用模态感知的无分类器引导(modality-CFG)方案,以提升音视频对齐与可控性。该方法扩展了标准 CFG 公式,为互补模态引入独立的引导项。对于每一流,引导预测由三部分组合而成:完全条件化模型输出、由 st 缩放的文本引导项,以及由 sm 缩放的跨模态引导项。该公式允许独立调节文本条件化与模态间对齐,使模型可平衡文本提示与跨模态特征的贡献。作者实证观察到,增加跨模态引导强度 sm 有助于互信息优化,从而提升生成视频与音频之间的时间同步性与语义连贯性。
实验
- 在音视频质量、仅视觉性能与计算效率方面对 LTX-2 进行评估,证明其为性能最高的开源音视频模型,具备前所未有的推理速度。
- 在人工偏好测试中,LTX-2 超越开源模型 Ovi,视觉真实感、音频保真度与时间同步性得分与专有模型 Veo 3 和 Sora 2 相当。
- 在仅视频基准测试(Artificial Analysis, 2025 年 11 月 6 日)中,LTX-2 在 Image-to-Video 排名第 3,在 Text-to-Video 排名第 4,超越专有模型 Sora 2 Pro 与大型开源模型 Wan 2.2-14B。
- 在 NVIDIA H100 GPU 上,LTX-2 的每扩散步推理速度比 Wan 2.2-14B 快 18 倍,且在更高分辨率与更长时长下优势进一步扩大;同时因异构设计,也快于 Ovi。
- LTX-2 可生成长达 20 秒的连续视频并同步立体声音频,超过 Veo 3(12 秒)、Sora 2(16 秒)、Ovi(10 秒)与 Wan 2.5(10 秒)的时长限制,支持长篇创作应用。
实验结果表明,LTX-2 的推理速度显著快于 Wan 2.2-14B,每扩散步仅需 1.22 秒,相较 22.30 秒提升 18 倍。作者利用此效率突出 LTX-2 生成长时长音视频内容的能力,支持高达 20 秒的同步音视频生成,超越现有开源与专有模型。