Command Palette
Search for a command to run...
UniCorn:通过自生成监督实现自我提升的统一多模态模型
UniCorn:通过自生成监督实现自我提升的统一多模态模型
摘要
尽管统一多模态模型(Unified Multimodal Models, UMMs)在跨模态理解方面取得了显著进展,但其在将内部知识有效用于高质量生成任务方面仍存在显著短板。我们将其称为“传导性失语症”(Conduction Aphasia)现象:模型能够准确理解多模态输入,却难以将这种理解转化为忠实且可控的生成结果。为解决这一问题,我们提出UniCorn——一种简洁而优雅的自提升框架,无需依赖外部数据或教师监督。该框架将单一UMM划分为三个协同角色:提议者(Proposer)、求解者(Solver)与评判者(Judge),通过自对弈机制生成高质量交互,并采用认知模式重构技术,将隐含的理解知识提炼为显式的生成信号。为验证多模态一致性的恢复效果,我们引入UniCycle——一种基于“文本→图像→文本”重构循环的循环一致性基准测试。大量实验表明,相较于基础模型,UniCorn在六个通用图像生成基准上均实现了全面且显著的性能提升。尤为突出的是,在TIIF(73.8)、DPG(86.8)、CompBench(88.5)以及UniCycle四项任务中达到当前最优(SOTA)表现,同时在WISE任务上实现+5.0的显著增益,在OneIG任务上更是取得+6.5的大幅提升。这些结果表明,我们的方法不仅显著增强了文本到图像(T2I)生成能力,同时保持了强大的多模态理解性能,充分展现了完全自监督式精炼机制在统一多模态智能系统中的可扩展性与有效性。
一句话总结
来自中国科学技术大学(USTC)、复旦大学(FDU)、华东师范大学(ECNU)、香港中文大学(CUHK)、南京大学(NJU)和苏州大学(SUDA)的作者提出 UniCorn,一种自监督框架,通过将统一多模态模型分解为提出者(Proposer)、求解者(Solver)和裁判(Judge)三个角色,实现自对弈与认知模式重构,显著提升文本到图像生成的质量与连贯性,无需外部数据,已在 TIIF、DPG 和 UniCycle 等多个基准上达到最先进水平。
主要贡献
-
本文识别出统一多模态模型(UMMs)中的“传导性失语”现象:尽管跨模态理解能力强大,但难以转化为高质量生成结果。为此提出 UniCorn,一种自提升框架,将单一 UMM 的内部能力重新分配为三个协作角色——提出者、求解者和裁判,实现无需外部数据或教师模型的自监督优化。
-
UniCorn 采用认知模式重构技术,将多智能体交互转化为结构化训练信号,如描述性字幕和评价反馈,从而将隐式理解提炼为显式生成指导,使统一模型架构内实现自主、可扩展的持续改进。
-
大量实验表明,UniCorn 在六个图像生成基准上均达到最先进性能,包括 TIIF(73.8)、DPG(86.8)、CompBench(88.5)和 UniCycle(46.5),在 WISE 上提升 +5.0,在 OneIG 上提升 +6.5;而新提出的 UniCycle 基准通过文本→图像→文本重建验证了多模态连贯性的增强。
引言
统一多模态模型(UMMs)旨在在一个统一框架内整合感知与生成能力,实现跨模态的连贯推理,是迈向通用人工智能的关键一步。然而,一个关键限制依然存在:强大的理解能力往往无法转化为高质量的生成结果,作者将这一现象称为“传导性失语”——模型能够理解内容,却无法可靠地生成对应输出。以往的自提升方法依赖外部监督、精心筛选的数据或任务特定的奖励工程,限制了其可扩展性与泛化能力。本文提出 UniCorn,一种后训练框架,通过将单一 UMM 视为包含三个角色的多智能体系统(提出者:生成多样化提示;求解者:生成图像候选;裁判:利用内部理解评估输出),实现完全自包含的改进。该自生成反馈环路通过将数据重构为结构化信号,使模型在无需外部数据或教师模型的情况下持续优化自身生成能力。为验证真正的多模态连贯性,作者提出 UniCycle 基准,通过文本→图像→文本重建来衡量概念一致性。实验表明,UniCorn 在多个基准上均达到最先进水平,且在分布外条件下仍保持鲁棒性,证明内部理解可被重新利用为强大而自维持的训练信号。
方法
作者提出自监督框架 UniCorn,通过多智能体协作与认知模式重构,弥合统一多模态模型(UMMs)中“理解”与“生成”之间的鸿沟。该框架包含两个主要阶段:自多智能体采样与认知模式重构(CPR)。
在第一阶段,UMM 在功能上被划分为三个协作角色——提出者、求解者与裁判,嵌入单一模型中,实现无需外部监督的自对弈循环。提出者根据十类预定义规则生成多样且具有挑战性的图像生成文本提示,并通过动态种子机制,利用先前采样样本迭代优化提示生成过程。求解者针对这些提示生成一组图像,每条提示采用多次采样(rollouts)以确保多样性与质量。裁判则通过离散评分(0–10)评估生成图像,利用任务特定评分标准与思维链(Chain-of-Thought)推理提供评价信号。该过程如框架图所示,构建了一个闭环系统:模型自主生成、评估并优化自身输出。

在第二阶段,认知模式重构(CPR),将自对弈循环中的原始交互重构为三种不同训练模式,以将隐式知识提炼为显式监督信号。第一种模式为“字幕”(Caption),通过训练模型根据最高分生成图像反推原始提示,建立图像到文本的双向语义对齐,强化图像到文本的逆映射能力。第二种模式为“判断”(Judgement),通过训练模型预测任意提示-图像对的评分,校准模型内部价值体系,利用裁判的推理轨迹与评分标准作为监督信号。第三种模式为“反思”(Reflection),引入迭代自我修正机制,训练模型将次优图像转化为最优图像,利用同一提示下高奖励与低奖励输出之间的对比。该过程在认知模式重构图中详述,将模型内部的“内心独白”转化为结构化数据,支持稳健学习。

这三种重构后的数据类型——字幕、判断与反思——与高质量自采样生成数据结合,用于微调 UMM。整个流程完全自包含,无需外部教师模型或人工标注。框架的有效性进一步通过 UniCycle 基准验证,该基准评估模型从自身生成内容中重建文本信息的能力,如基准图所示。

实验
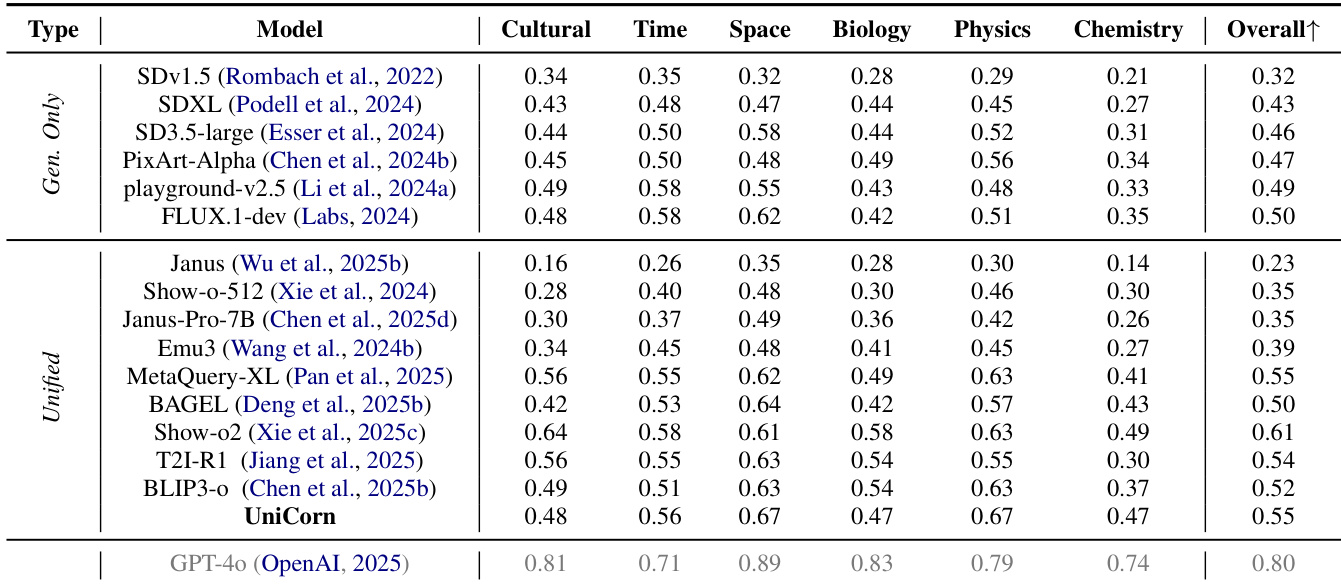
- UniCycle 基准通过文本→图像→文本循环验证内部多模态智能,实现 Hard 分数 46.5,较基线模型高出近 10 分,显著优于其他模型,表明其具备更强的自我反思与统一理解能力。
- 在 TIIF 上,UniCorn 在短提示任务上提升 3.7 分,在 OneIG-EN 的文本子任务上提升 22.4 分,表明其具备强大的指令遵循与知识内化能力。
- 在 WISE 上提升 5 分,在 CompBench 上提升 6.3 分,尤其在数值能力(+13.1)与三维空间理解(+6.1)方面表现突出,DPG 上得分 86.8,超越 GPT-4o 的 86.2。
- 消融实验表明,认知模式重构(CPR)稳定了潜在空间,实现了理解与生成之间的互惠增强;移除生成或判断模块将导致性能崩溃。
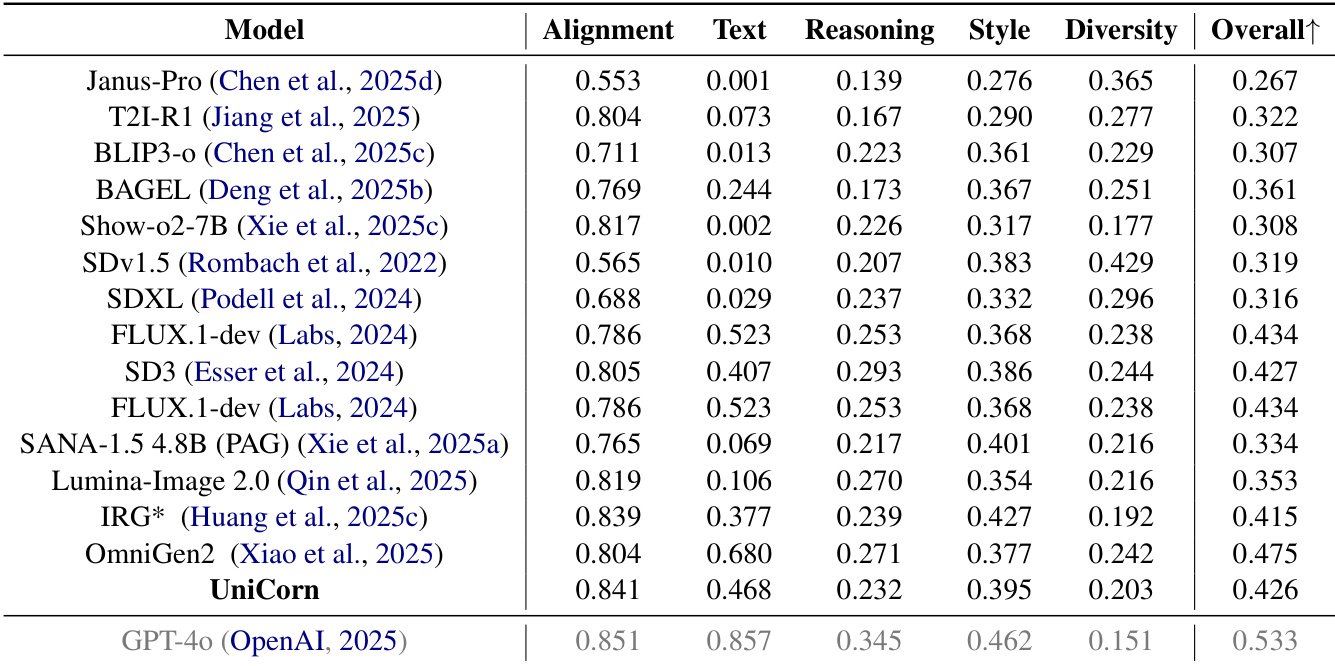
- 扩展实验显示,UniCorn 仅需 5k 自生成样本即可达到 SOTA 性能,优于 IRG(基于 30k GPT-4o 数据训练)与 DALL·E 3,证明其具备高效、无边界自提升能力。
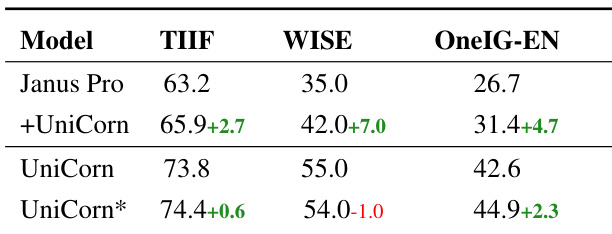
- UniCorn 在不同架构上均具泛化能力,使 Janus-Pro 在 TIIF 上提升 +3.2,在 WISE 上提升 +7.0,验证其在增强知识表达与理解引导生成方面的有效性。
作者使用 UniCycle 基准评估统一多模态模型在文本→图像→文本循环中保留指令关键语义的能力。结果表明,UniCorn 在 UniCycle 上取得最高 Hard 分数(46.5),较其基线模型 BAGEL 提升近 10 分,优于其他模型超 3 分,展现出卓越的自我反思与全面多模态智能。
作者使用 UniCycle 基准评估统一多模态模型在文本→图像→文本循环中保留指令关键语义的能力。结果表明,UniCorn 在 UniCycle 上取得最高 Hard 分数(46.5),显著优于其基线模型 BAGEL 及其他统一模型,表明其具备更强的知识内化与自我反思能力。
作者使用 UniCycle 基准评估多模态模型在文本→图像→文本循环中保留指令关键语义的能力。结果表明,UniCorn 在 UniCycle 上取得最高 Hard 分数 46.5,显著优于其基线模型 BAGEL 及其他统一模型,表明其具备更强的知识内化与自我反思能力。
作者使用表格对比 UniCorn 与其他模型在外部模型与数据依赖性、超参数调优等方面的差异。结果表明,UniCorn 仅使用 5K 训练样本即可在 OneIG-EN 上达到最先进性能,无需依赖外部任务特定模型或标注数据,且无需超参数调优。

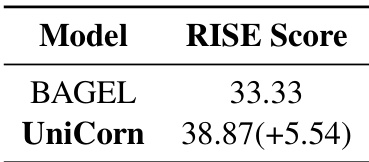
作者使用 RISE 基准评估 UniCorn 及其基线模型 BAGEL 的性能。结果表明,UniCorn 的 RISE 得分为 38.87,较 BAGEL 的 33.33 提升 5.54 分,表明其在指令遵循与生成质量方面有显著提升。