Command Palette
Search for a command to run...
MemRL:通过情景记忆上的运行时强化学习实现自我演化的Agent
MemRL:通过情景记忆上的运行时强化学习实现自我演化的Agent
摘要
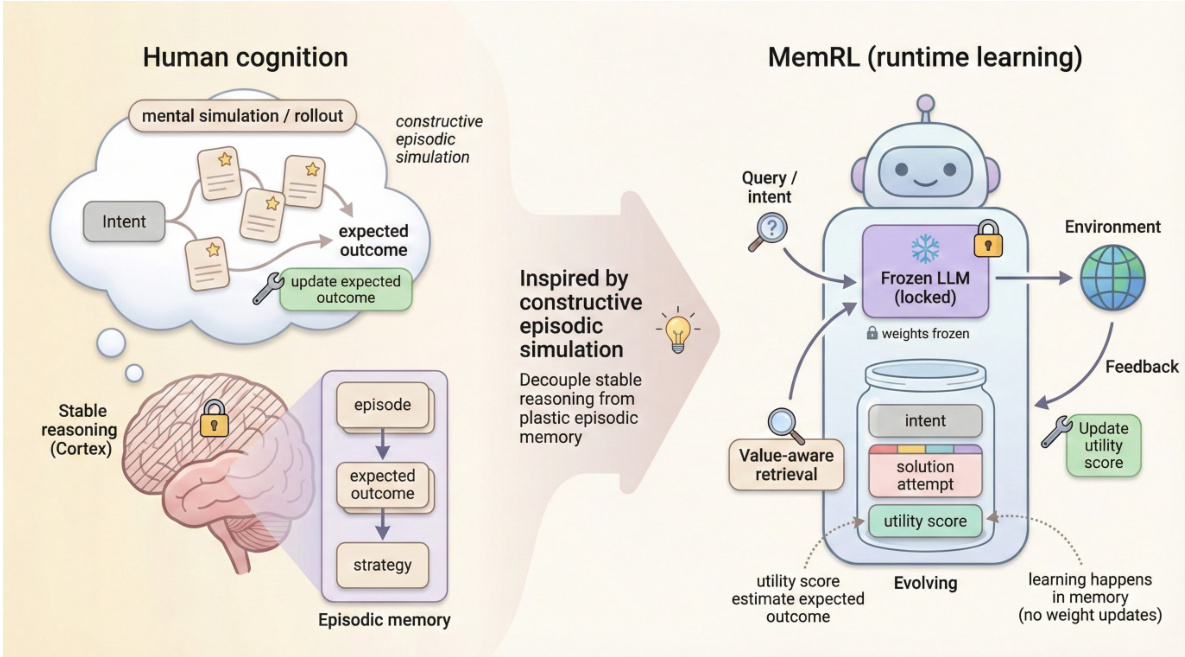
人类智能的核心特征在于,能够通过“建构性情景模拟”掌握新技能——即调用过往经验,综合生成应对新任务的解决方案。尽管大型语言模型具备强大的推理能力,但在模拟这种自我演化过程方面仍面临挑战:微调计算成本高昂,且易引发灾难性遗忘;而现有的基于记忆的方法依赖被动的语义匹配,往往检索到大量噪声信息。为应对上述问题,我们提出 MemRL 框架,该框架使智能体能够通过情景记忆上的非参数化强化学习实现自我演化。MemRL 显式地将冻结的大型语言模型所具备的稳定推理能力,与可塑、持续演化的记忆系统分离开来。与传统方法不同,MemRL 采用两阶段检索机制:首先根据语义相关性筛选候选记忆,再基于学习到的 Q 值(即效用)进行最终选择。这些效用值通过环境反馈以试错方式持续优化,使智能体能够有效区分高价值策略与相似的噪声信息。在 HLE、BigCodeBench、ALFWorld 以及 Lifelong Agent Bench 等多个基准上的大量实验表明,MemRL 显著优于当前最先进方法。分析实验进一步验证,MemRL 有效调和了“稳定性-可塑性”悖论,在无需更新模型权重的前提下,实现了运行时的持续性能提升。
一句话总结
上海交通大学、西安电子科技大学、新加坡国立大学、上海创新研究院、MemTensor(上海)科技有限公司以及中国科学技术大学的作者们提出了MEMRL,一种非参数化强化学习框架,使大语言模型(LLM)代理能够通过动态情景记忆实现自我演化。通过将冻结的LLM与可塑的记忆模块解耦,并采用两阶段检索机制——先按语义相关性筛选,再依据学习到的Q值选择——MEMRL通过试错反馈选择性地更新高价值策略,克服了灾难性遗忘和检索噪声问题。该方法在不更新模型权重的情况下实现持续运行时性能提升,在HLE、BigCodeBench、ALFWorld和Lifelong Agent Bench上显著优于最先进基线,有效解决了终身学习场景中的稳定性-可塑性困境。
主要贡献
-
本文针对大语言模型在部署后持续学习与适应而避免灾难性遗忘的挑战,提出MEMRL框架,将稳定推理(通过冻结LLM实现)与可塑的情景记忆解耦,从而在运行时学习中调和稳定性-可塑性矛盾。
-
MEMRL引入了一种新颖的两阶段检索机制:首先根据语义相关性过滤经验,再基于学习到的Q值(效用)进行选择,这些效用通过非参数化强化学习方法结合环境反馈不断优化,使代理能够从噪声中区分出高价值策略。
-
在HLE、BigCodeBench、ALFWorld和Lifelong Agent Bench上的大量实验表明,MEMRL始终优于最先进基线;分析证实,基于效用的更新提升了任务成功率,并通过贝尔曼收缩保持结构完整性,确保无需权重更新即可实现稳定、持续的性能提升。
引言
作者致力于解决大语言模型在部署后持续提升性能而不修改其冻结参数的挑战——这对现实世界代理应用至关重要,因为稳定性与适应性必须共存。以往方法要么依赖计算成本高昂的微调,存在灾难性遗忘风险;要么采用被动检索方法(如RAG),缺乏评估过往经验实际效用的机制,难以区分高价值策略与噪声。为克服这些局限,作者提出MEMRL框架,将稳定推理(由冻结LLM处理)与可塑的情景记忆解耦,利用非参数化强化学习优化记忆使用。MEMRL引入两阶段检索机制:首先按语义相关性筛选候选,再基于学习到的Q值选择最优上下文,Q值通过贝尔曼更新结合环境反馈进行调整。这一闭环过程使代理能够在运行时自我演化,持续优化记忆以优先保留高价值经验。该框架在多个基准上得到验证,展现出持续的性能提升与理论上的稳定性保障,确立了LLM代理运行时学习的新范式。
方法
作者利用非参数化强化学习框架MemRL,使冻结的大语言模型(LLM)通过与环境交互实现自我演化。该方法的核心是将记忆检索视为基于价值的决策过程,构建于基于记忆的马尔可夫决策过程(M-MDP)框架中。代理行为被分解为两个独立阶段:检索与生成。生成响应 yt 的联合策略定义为所有可能检索记忆项的边缘分布,结合检索策略 μ(m∣st,Mt) 选择记忆上下文 m,以及推理策略 pLLM(yt∣st,m) 根据查询和检索上下文生成输出。关键创新在于直接优化检索策略 μ,而非依赖静态相似性度量,从而根据其功能效用选择记忆。
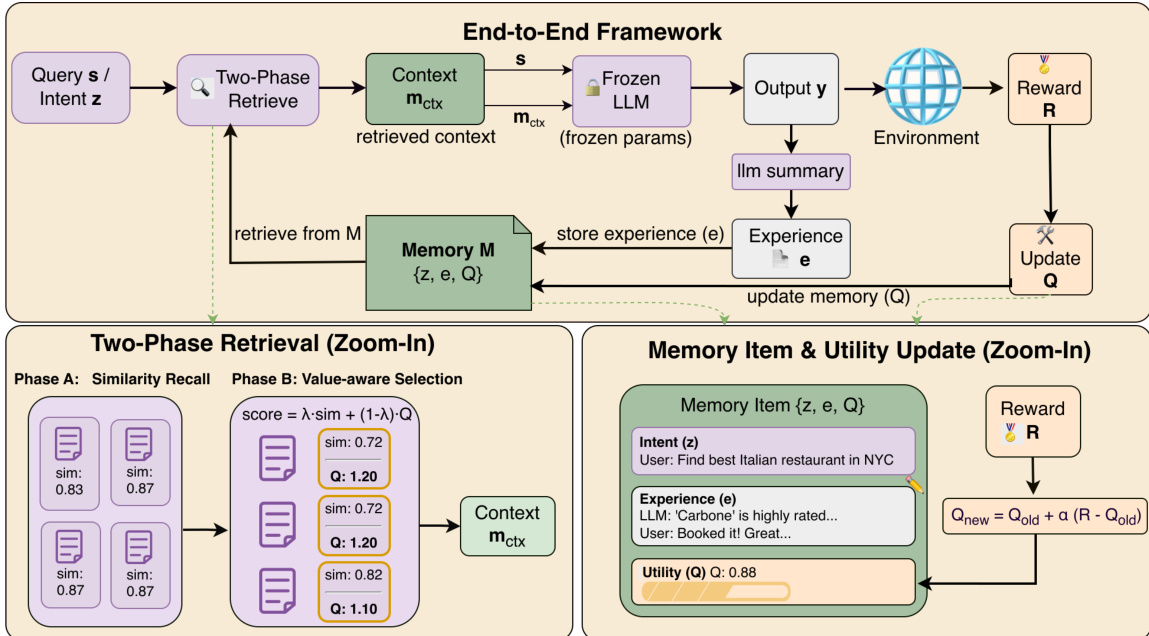
该框架的架构围绕结构化记忆库 M 构建,其组织为意图-经验-效用三元组 (zi,ei,Qi)。其中,zi 是过去查询的意图嵌入,ei 是原始经验(如成功解决方案轨迹),Qi 是学习到的效用值,近似于将该经验应用于相似意图时的预期回报。这一结构使代理能够基于过往经验的实际有效性做出决策,而不仅依赖语义相似性。
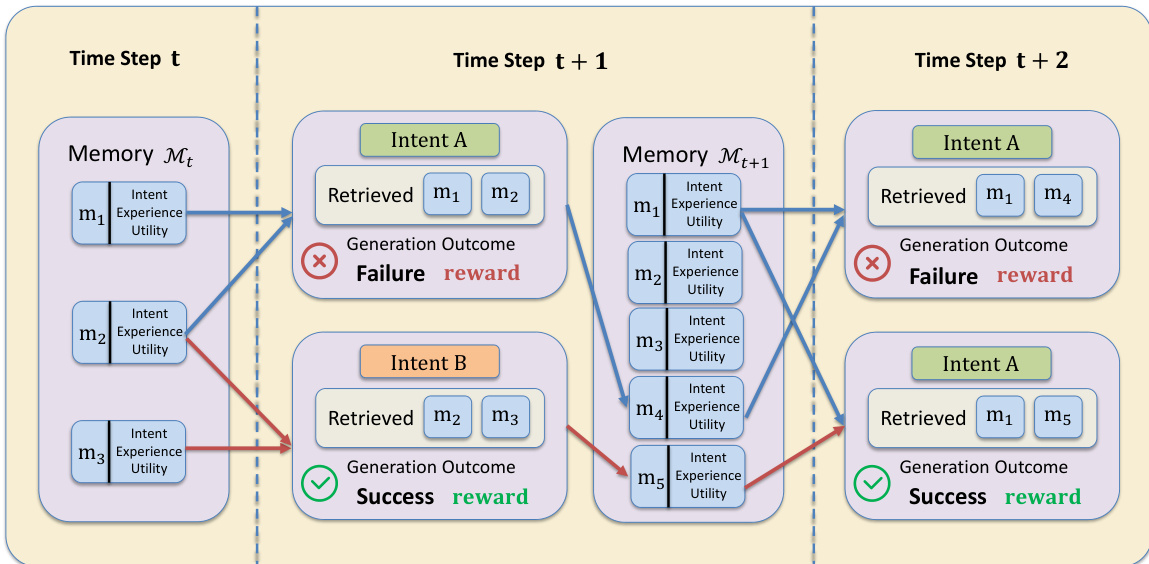
为选择最有用的上下文,MemRL采用两阶段检索机制。阶段A:相似性召回,作为粗筛。给定当前查询意图 s,计算 s 与所有存储意图嵌入 zi 的余弦相似度,检索出前K个语义最相似的记忆候选池 C(s),确保检索具有上下文相关性。阶段B:价值感知选择,进一步优化该候选池,基于学习到的效用选择最优上下文。采用复合评分函数平衡语义相似性与效用:score(s,zi,ei)=(1−λ)⋅sim^(s,zi)+λ⋅Q^(zi,ei),其中 ^ 表示z-score归一化。这使得策略能够优先选择高效用记忆,即使其语义相似度不高,从而有效过滤“干扰”记忆。
学习过程完全在记忆空间内进行,不修改LLM权重。代理生成输出并从环境中获得奖励 R 后,对检索记忆的效用分数进行更新。采用类似蒙特卡洛的更新规则:Qnew←Qold+α(R−Qold),其中 α 为学习率。该更新使效用估计趋近于使用该经验的实证期望回报。同时,经验被总结并作为新三元组存入记忆库,实现代理知识库的持续扩展。这一效用更新过程受记忆再巩固启发,使代理能够从成功与失败中学习,持续优化其检索策略。
实验
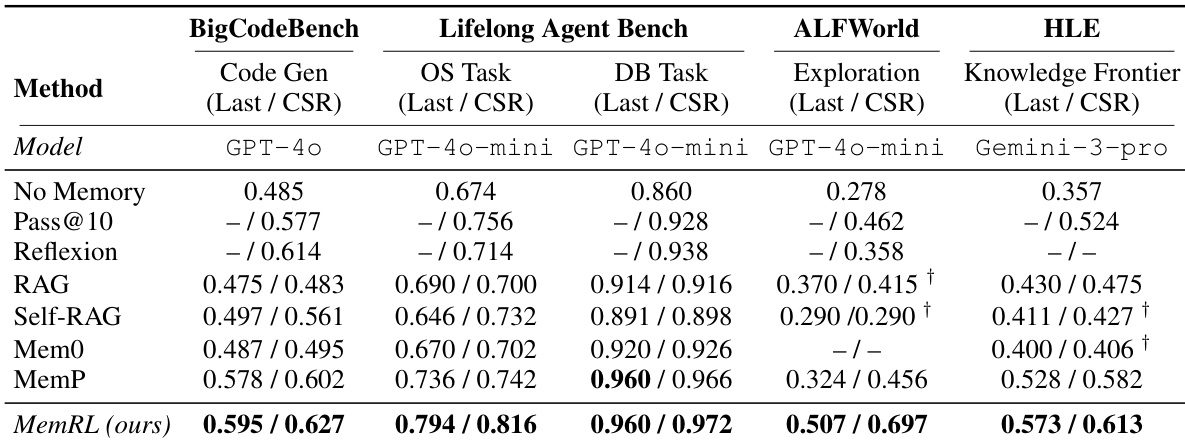
- MEMRL在四个不同基准上均优于多个基线方法(包括RAG、Self-RAG、MemP和Reflexion):BigCodeBench(代码生成)、ALFWorld(具身导航)、Lifelong Agent Bench(操作系统/数据库交互)以及Humanity's Last Exam(HLE,复杂推理),验证了其在运行时学习与迁移设置中的有效性。
- 在ALFWorld上,MEMRL达到最后一轮准确率为0.507,相比MemP(0.324)提升56%,相比无记忆基线(0.278)提升82%,累积成功率(CSR)达0.697,表明其在高复杂度、程序性任务中具有卓越的探索与解法发现能力。
- 在HLE中,MEMRL达到0.573的最终准确率和61.3%的CSR,显著优于MemP(0.528),凸显其从近似失败中学习并保留可复用修正启发式的能力。
- 在BigCodeBench上,MEMRL达到0.508的准确率,超越Self-RAG(0.500)和MemP(0.494);在Lifelong Agent Bench上达到0.746的准确率,优于RAG(0.713),证实其在各领域中的强泛化能力。
- 消融实验表明,采用平衡Q权重(λ = 0.5)的价值感知检索机制表现最佳,纯语义检索早期即趋于饱和,而纯强化学习因上下文脱节导致不稳定。
- 紧凑检索设置(k₁ = 5, k₂ = 3)在HLE上优于更大设置(k₁ = 10, k₂ = 5),表明高质量、低噪声的记忆召回比高容量检索更适用于复杂推理。
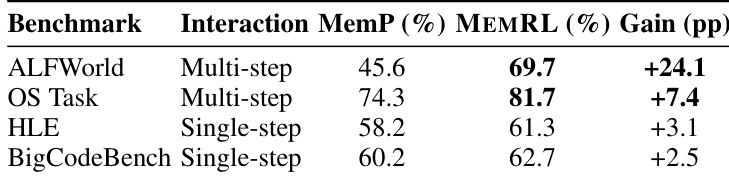
- MEMRL充当轨迹验证器,在多步任务中显著提升性能(如ALFWorld提升24.1个百分点),通过过滤虽初始语义匹配但后续步骤失败的记忆。
- Q-评判器表现出强预测能力(皮尔逊相关系数 r = 0.861),高Q值失败记忆通过编码可迁移的修正启发式增强了鲁棒性,案例研究显示高Q失败记忆可带来100%下游成功率。
- MEMRL展现出更优的稳定性,遗忘率更低(0.041 vs. MemP的0.051),且CSR与轮次准确率同步增长,归因于贝尔曼收缩的理论保证以及通过归一化和相似性门控实现的有效噪声过滤。
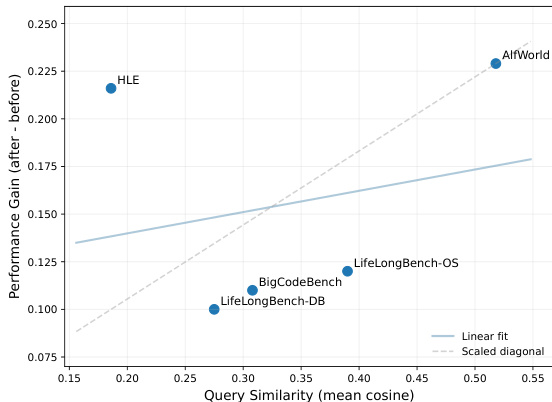
- 性能提升与数据集内查询相似度相关,ALFWorld(相似度0.518)因强模式复用获得最高提升(Δ = +0.229),而HLE(相似度0.186)通过运行时记忆化独特领域解法也实现高提升(Δ = +0.216),展示了MEMRL在泛化与特定知识获取方面的双重能力。
结果表明,MEMRL的性能提升与查询相似度相关,结构重复性高的任务(如ALFWorld)获得更高增益。然而,尽管HLE相似度较低,仍通过运行时记忆化实现高增益,表明MEMRL可根据任务结构支持模式泛化与特定知识获取。
作者使用表格对比MEMRL与MemP在四个基准上的表现,显示MEMRL在所有情况下均取得更高准确率。性能增益在多步任务(如ALFWorld)中最为显著,MEMRL准确率提升24.1个百分点;而在单步任务(如BigCodeBench)中增益较小,表明MEMRL的价值感知检索在复杂、序列化环境中尤为有效。
作者使用MEMRL评估其在多种记忆增强基线上的表现,涵盖代码生成、操作系统交互和具身导航等任务。结果表明,MEMRL在所有任务上均取得最高准确率,相较于RAG和MemP等基线有显著提升,尤其在ALFWorld等探索密集型复杂环境中表现突出。
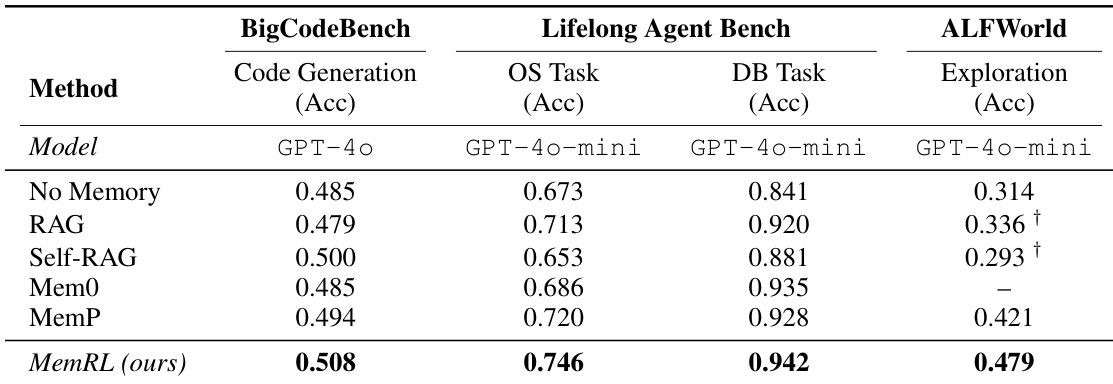
作者使用MEMRL评估其在多种记忆增强基线上的表现,涵盖代码生成、具身导航、操作系统/数据库交互及复杂推理等任务。结果表明,MEMRL在运行时学习与迁移设置中始终优于所有基线,所有任务上均取得最高准确率与累积成功率,尤其在ALFWorld和HLE等探索密集型环境中表现出显著优势。