Command Palette
Search for a command to run...
DreamStyle:一种统一的视频风格化框架
DreamStyle:一种统一的视频风格化框架
Mengtian Li Jinshu Chen Songtao Zhao Wanquan Feng Pengqi Tu Qian He
摘要
视频风格化是视频生成模型的重要下游任务,目前仍缺乏深入研究。其输入风格条件通常包括文本、风格图像以及风格化首帧三种形式。每种条件各具优势:文本条件更具灵活性,风格图像能提供更精确的视觉参考,而风格化首帧则使长视频风格化成为可能。然而,现有方法大多仅支持单一类型的风格条件,限制了其应用范围。此外,由于高质量数据集的缺乏,现有方法常出现风格不一致和时间域闪烁等问题。为解决上述局限,我们提出 DreamStyle——一种统一的视频风格化框架,支持(1)文本引导、(2)风格图像引导、以及(3)首帧引导的视频风格化任务,并配套设计了高效的数据整理流程,以获取高质量的成对视频数据。DreamStyle 基于标准的图像到视频(Image-to-Video, I2V)模型构建,采用低秩适配(Low-Rank Adaptation, LoRA)技术,并引入针对特定标记的上投影矩阵(token-specific up matrices),有效缓解了不同条件标记之间的混淆问题。定性与定量实验结果均表明,DreamStyle 在三种视频风格化任务中均表现出色,且在风格一致性与视频质量方面显著优于现有方法。
一句话总结
字节跳动智能创作实验室提出 DreamStyle,一种统一的视频风格化框架,通过基于 LoRA 增强的 I2V 模型与 token 特定上采样矩阵,支持文本、风格图像和首帧引导的生成,实现跨多种条件的一致性、高质量风格化,克服了以往在灵活性和时序连贯性方面的局限。
主要贡献
- 视频风格化长期受限于单一风格条件(文本、风格图像或首帧),限制了灵活性与泛化能力;DreamStyle 提出统一框架,在单一模型中无缝支持三种模态,实现多样化且可控的风格化。
- 为应对高质量训练数据稀缺问题,DreamStyle 采用系统化的数据整理流程:先对初始帧进行风格化,再通过带 ControlNets 的 I2V 模型传播风格,并结合混合自动与人工过滤,确保高保真度。
- 框架采用改进的 LoRA 模块,引入 token 特定上采样矩阵,减少不同条件 token 之间的干扰,相比专用基线模型在风格一致性与视频质量上表现更优,同时支持多风格融合与长视频风格化等高级应用。
引言
视频风格化是视觉内容生成中的关键任务,能够将现实世界视频转化为艺术化或风格化输出,同时保持运动与结构的一致性。以往方法大多局限于单一风格条件——要么是文本提示,要么是风格图像,各自在灵活性、准确性与可用性之间存在权衡。此外,缺乏高质量、模态对齐的训练数据导致风格一致性差与时序闪烁问题。现有方法在多风格融合与长视频风格化等扩展应用上也因架构僵化与缺乏统一框架而表现不佳。
本文提出 DreamStyle,一种基于原始图像到视频(I2V)模型的统一视频风格化框架,可在同一架构中支持三种风格条件:文本、风格图像与风格化首帧。为实现有效的多条件处理,作者设计了具有共享下采样矩阵与条件特定上采样矩阵的 token 特定 LoRA 模块,降低不同风格 token 间的干扰。核心创新在于可扩展的数据整理流程:首先使用图像风格化模型对初始帧进行风格化,再通过带 ControlNets 的 I2V 模型传播风格,最后结合混合(自动与人工)过滤,生成高质量配对视频数据。该流程解决了训练数据稀缺问题,显著提升了风格保真度与时序连贯性。
DreamStyle 在所有三种风格化任务中均达到最先进性能,相比专用模型在风格一致性和视频质量上表现更优,同时通过统一条件注入实现了多风格融合与长视频风格化等新能力。
数据集

- 数据集包含 4 万对风格化-原始视频对用于持续训练(CT),以及 5 千对用于监督微调(SFT),每对视频分辨率为 480P,最多包含 81 帧。
- 原始视频来自现有视频集合,风格化视频分两阶段生成:首先使用 InstantStyle(风格图像引导)或 Seedream 4.0(文本引导)对首帧进行风格化;其次,通过自研 I2V 模型从风格化首帧生成完整视频。
- 对于 CT,使用 InstantStyle 生成大规模、多样化的数据集,聚焦通用视频风格化能力,每样本配一个风格参考图像。对于 SFT,使用 Seedream 4.0 生成更小但更高质的数据集,每样本含 1 至 16 个风格参考图像,训练时仅使用其中一个。
- 为确保原始视频与风格化视频间运动一致性,采用相同的控制条件(深度与人体姿态)驱动两次视频生成,避免因控制信号提取不完善导致的运动错位。
- 使用视觉-语言模型(VLM)构建元数据,为每段视频生成两个文本提示:一个不包含风格属性(t_ns),一个包含风格属性(t_sty),实现风格无关与风格感知的条件控制。
- 风格参考图像(s_i^1..K)采用与风格化视频相同的引导方式生成,CT 数据集通过 VLM 与 CSD 分数进行风格一致性过滤,SFT 数据集则经过人工过滤与内容一致性验证。
- 训练时,三种风格条件(文本引导、风格图像引导、首帧引导)按 1:2:1 比例采样,模型使用 LoRA(秩 64)训练,优化器为 AdamW,学习率 4×10⁻⁵,总迭代次数分别为 6,000(CT)与 3,000(SFT)。
- 采用两步梯度累积策略,实现有效批大小 16,训练在 NVIDIA GPU 上进行,每 GPU 批大小为 1。
方法
作者以 Wan14B-I2V [48] 基础模型为 DreamStyle 框架的基础,该模型设计用于支持三种不同风格条件:文本、风格图像与首帧。框架架构基于基础模型结构,对输入条件机制进行修改,以支持原始视频与额外风格引导的注入。如图所示,模型处理多种输入模态,包括原始视频、风格化首帧、风格参考图像与文本提示。这些输入通过 VAE 编码器转换为潜在表示:原始视频与风格化首帧生成视频潜在变量,风格图像编码为风格潜在变量。文本提示由文本编码器处理,风格图像的高层语义则通过 CLIP 图像特征分支进一步增强。 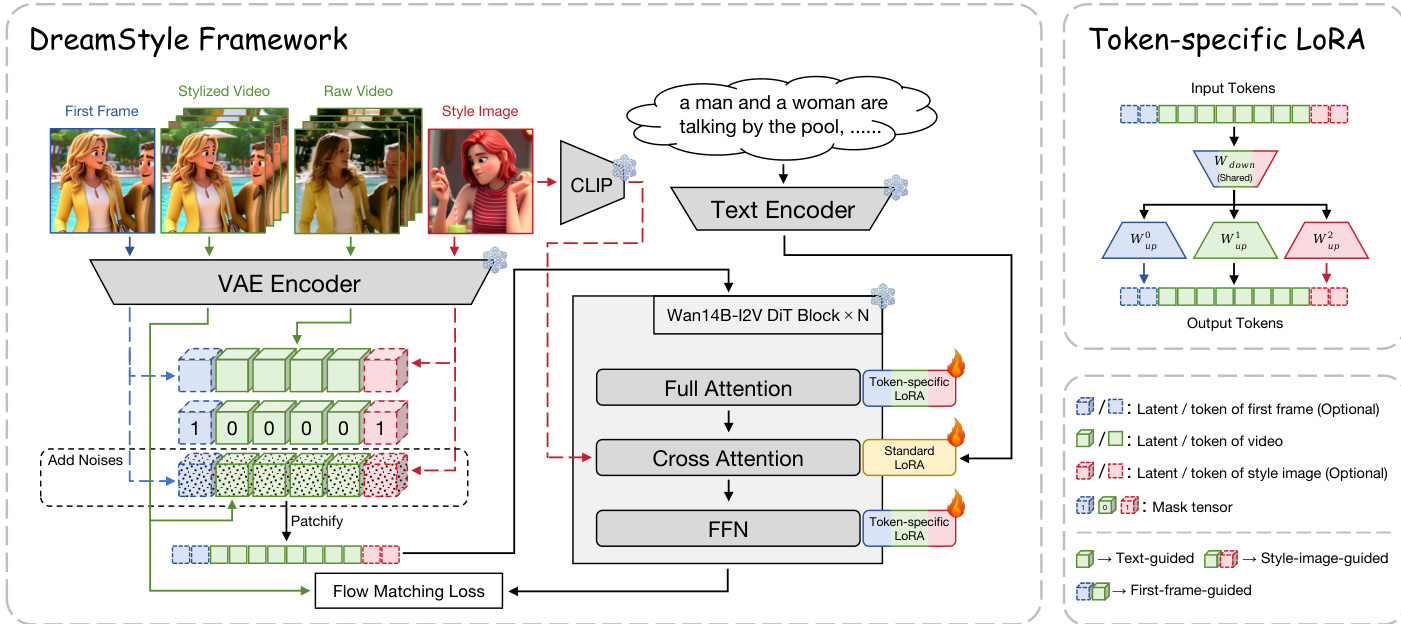
输入潜在变量随后通过添加噪声与掩码张量进行准备。对于原始视频条件,编码后的原始视频潜在变量 zraw 与风格化视频潜在变量 zsty 与掩码张量 04×F×H×W 拼接,掩码值 0.0 表示该条件缺失。对于风格图像条件,VAE 编码的风格参考图像潜在变量 zs 与自身注入噪声后的版本结合,并与掩码张量 14×1×H×W 拼接,掩码值 1.0 表示风格条件存在。首帧条件处理方式类似,将风格化首帧输入图像条件通道,掩码设为 1.0。这些条件化潜在变量经分块处理后转换为 token 序列,输入核心模型。
为解决不同条件 token 间因语义角色差异导致的 token 混淆问题,作者引入 token 特定 LoRA 模块。该修改应用于模型的完整注意力与前馈网络(FFN)层。如图所示,对于输入 token xin,共享下采样矩阵 Wdowni 将其投影,输出残差 token xout 通过根据 token 类型 i 选择的特定上采样矩阵 Wupi 计算。该设计使模型能为每种条件类型学习自适应特征,同时通过大量共享参数保持训练稳定性。 
实验
- 文本引导视频风格化:DreamStyle 超越商业模型(Luma、Pixverse、Runway)与开源基线 StyleMaster,在 CLIP-T 与 DINO 指标上均取得最高分,表明其在风格提示遵循与结构保持方面表现更优。在测试集上,其在风格一致性(CSD)与动态程度上均优于竞品,用户研究整体质量得分约为 4 或更高。
- 风格图像引导风格化:DreamStyle 达到最佳 CSD 分数,尤其在涉及几何形状的复杂风格处理上表现突出,定量指标与视觉质量均优于 StyleMaster。
- 首帧引导风格化:DreamStyle 实现最优风格一致性(CSD)与强视频质量,尽管因风格化首帧偶尔引发结构冲突,DINO 分数略低;视觉结果证实主要结构元素得以保留。
- 多风格融合:DreamStyle 在推理阶段成功融合文本提示与风格图像,实现超越单一引导的创造性风格融合。
- 长视频风格化:通过将短视频段首尾衔接(以末帧作为下一段首帧),DreamStyle 超越 5 秒限制,实现长序列风格化,且风格保持一致。
- 消融实验:token 特定 LoRA 显著提升风格一致性,减少风格退化与混淆;分两阶段在 CT 与 SFT 数据集上训练,实现风格一致性与结构保持的最佳平衡。
结果表明,DreamStyle 在文本引导视频风格化任务中全面超越对比方法,CLIP-T 与 DINO 指标最高,表明其在风格提示遵循与结构保持方面表现卓越。在风格图像引导与首帧引导任务中,DreamStyle 在多数指标上达到最佳或第二佳表现,尤其在风格一致性方面表现突出,同时保持强整体质量。
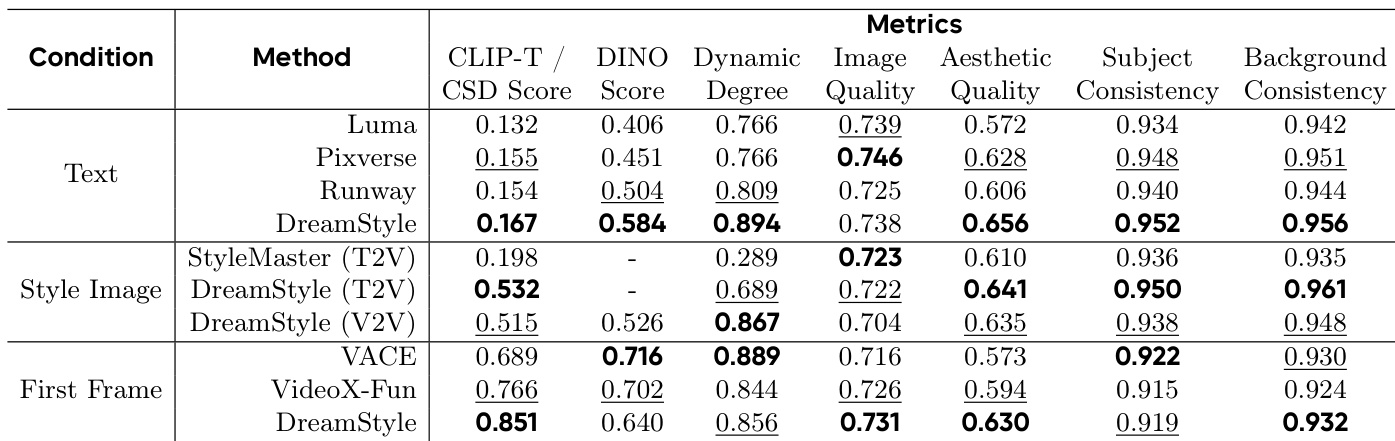
结果表明,DreamStyle 在所有三种视频风格化任务中均在风格一致性、内容一致性和整体质量上取得最高分。在文本引导风格化中,其超越 Luma、Pixverse 与 Runway,尤其在风格一致性和内容保留方面表现优异。在风格图像引导与首帧引导任务中,DreamStyle 在风格一致性和整体质量上均领先,相比 StyleMaster、VACE 与 VideoX-Fun 表现更优。
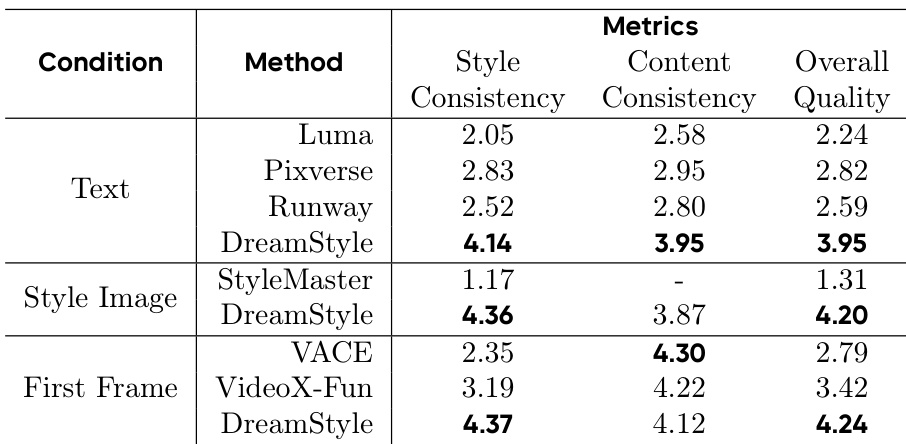
结果表明,token 特定 LoRA 显著提升风格一致性,完整模型 CSD 得分为 0.515,优于无该模块版本(0.413)。完整模型在结构保持方面也表现强劲,DINO 指标得分为 0.526;而仅使用 CT 数据训练的消融版本虽达最高 CSD 分数,但以牺牲结构保持为代价。