Command Palette
Search for a command to run...
InfiniteVGGT:面向无限数据流的视觉几何基底Transformer
InfiniteVGGT:面向无限数据流的视觉几何基底Transformer
Shuai Yuan Yantai Yang Xiaotian Yang Xupeng Zhang Zhonghao Zhao Lingming Zhang Zhipeng Zhang
摘要
实现持久、大规模三维视觉几何理解的宏大愿景,长期以来受限于可扩展性与长期稳定性之间不可调和的矛盾。尽管离线模型如VGGT在几何理解能力上展现出令人振奋的性能,但其基于批量处理的特性使其无法适用于实时系统。而流式架构虽被设计用于实时运行,却始终未能满足实际需求:现有方法或无法支持真正无限时序的输入,或在长序列中出现灾难性漂移。为此,我们提出InfiniteVGGT——一种因果视觉几何Transformer,通过引入一个有界但自适应且持续表达的键值(KV)缓存机制,实现了“滚动记忆”的工程化落地。基于此机制,我们进一步设计了一种无需训练、与注意力机制无关的剪枝策略,能够智能地丢弃过时信息,从而在每帧新输入时高效“滚动”记忆向前推进。InfiniteVGGT完全兼容FlashAttention,从根本上缓解了以往在无限时序流式处理与长期稳定性之间的权衡难题,实现了无限时序流式处理能力,并在长期稳定性方面超越现有流式方法。此类系统的终极考验在于其在真正无限时序上的表现能力——这一能力长期以来因缺乏极长时间、连续的基准测试数据而难以严谨验证。为填补这一关键空白,我们提出了Long3D基准数据集,首次实现了对长达约10,000帧序列的连续三维几何估计的严格评估。该基准为未来长期三维几何理解研究提供了权威的评测平台。代码已开源,地址为:https://github.com/AutoLab-SAI-SJTU/InfiniteVGGT
一句话总结
上海交通大学 AutoLab 与 Anyverse Dynamics 的研究者提出了 InfiniteVGGT,一种具有有界自适应 KV 缓存的因果视觉几何 Transformer,通过智能修剪过时信息(无需重新训练)实现了无限时域的流式 3D 几何理解。与以往方法不同,它通过与 FlashAttention 兼容的滚动记忆机制保持长期稳定性,并引入 Long3D 基准——包含 10,000 帧序列——以严格评估连续 3D 估计,为长期视觉几何系统设立了新标准。
主要贡献
- 现有的流式 3D 几何模型在可扩展性与长期稳定性之间面临根本性权衡:要么累积无界内存,要么因有损状态压缩导致灾难性漂移,限制了其在实时系统中的应用。
- InfiniteVGGT 引入了一种因果视觉几何 Transformer,通过无需训练、与注意力无关的剪枝策略实现有界自适应滚动记忆,利用键向量余弦相似度丢弃冗余标记,从而在保持与 FlashAttention 兼容的同时实现无限时域流式处理。
- 为严格评估长期性能,作者提出了 Long3D,首个针对约 10,000 帧序列的连续 3D 几何估计基准,为评估无限时域稳定性与准确性提供了决定性平台。
引言
研究者针对实时系统中连续长期 3D 场景重建的挑战展开研究,现有方法面临根本性权衡:离线模型虽能实现高几何精度,但因批处理机制与流式处理不兼容;而在线方法则或面临无界内存增长,或因激进的状态压缩导致灾难性漂移。以往工作难以在无限时域内同时维持可扩展性与稳定性,尤其因依赖注意力得分的剪枝策略效率低下——这些策略需生成大型注意力矩阵,与 FlashAttention 等优化内核相悖。为此,研究者提出 InfiniteVGGT,一种因果视觉几何 Transformer,通过无需训练、与注意力无关的剪枝策略基于键向量余弦相似度实现有界自适应滚动记忆。该方法可高效动态保留语义上不同的标记,同时丢弃冗余项,保持长期一致性且避免内存溢出。系统完全兼容 FlashAttention,支持无限长度输入流,并在新提出的 Long3D 基准上进行评估——首个专为 10,000+ 帧连续评估设计的数据集——为未来长期 3D 几何理解研究提供了决定性测试平台。
数据集

- Long3D 基准包含 5 个长时连续 3D 视频序列,覆盖多样化的室内外环境,每个序列长度约为 2,000 至 10,000 帧,显著长于以往受限于 1,000 帧或更少的基准。
- 数据通过手持式 3D 空间扫描仪采集,配备 IMU、360° 水平 × 59° 垂直视场角 LiDAR 以及 RGB 相机(800 × 600 分辨率,10 Hz,90° 视场角)。
- 每个序列包含全局对齐的真值点云及对应的不间断 RGB 图像流,支持从连续输入中评估长期 3D 重建。
- 数据集旨在评估密集视角流式重建,即模型需实时处理完整图像流以生成完整、全局一致的点云。
- 评估时,使用迭代最近点(ICP)算法将预测点云与真值对齐,遵循领域内标准实践。
- 性能通过四项成熟指标衡量:准确率(Acc.)、完成度(Comp.)、Chamfer 距离(CD)和法向一致性(NC)。
- 作者将 Long3D 数据集作为主要评估基准,使用 7-Scenes 和 NRGBD 等现有数据集中的短序列进行模型训练,再在 Long3D 上测试以评估长期鲁棒性与连续性。
- 未进行显式裁剪,而是使用完整原始序列,以保留时间连续性。
- 元数据包含场景标识符、采集时间戳及传感器校准数据,用于同步 RGB 与 LiDAR 流,并在评估中支持精确对齐。
方法
研究者采用基于 Transformer 的架构,专为在线 3D 重建设计,建立在离线模型 VGTT 及其流式变体 StreamVGGT 的基础上。该框架逐帧处理输入序列,通过键值(KV)缓存保留时间上下文信息。在每个时间步,模型通过因果时间注意力模块将帧特定特征(来自帧注意力模块)与先前帧的缓存上下文结合,生成 3D 输出——包括相机参数、深度图、点图和跟踪特征。这种增量处理支持流式推理,但导致 KV 缓存随时间累积标记,引发无界内存增长。
为解决此问题,所提方法引入滚动记忆范式,通过剪枝 KV 缓存防止内存溢出,同时保持几何一致性。框架首先基于首帧输入的 KV 缓存建立不可变锚点集。该锚点集作为固定全局参考,确保所有后续 3D 预测均与初始帧坐标系对齐。后续所有帧贡献可变候选集,该集合可被压缩。剪枝策略在每个解码器层和注意力头独立运行,反映其异构信息内容。

候选集中标记的保留由一种多样性感知机制引导。该方法不依赖注意力权重,而是通过特征空间中键向量的几何分散度衡量冗余性。如图所示,不同帧的查询与键几乎占据正交子空间,表明键空间相似度是冗余性的稳定代理。每个键的多样性得分定义为该层与头中所有归一化候选键均值的负余弦相似度。与均值差异较大(即几何上更独特)的键获得更高得分,更可能被保留。

为进一步优化内存使用,该方法采用分层自适应预算分配机制。该机制根据各解码器层的平均信息多样性,为其分配非均匀存储预算。某层的多样性得分计算为其所有注意力头多样性得分的均值。通过受温度超参数调制的 softmax 函数对这些得分进行归一化,以确定各层在总内存预算中的分配比例。最终压缩缓存由每层每头按多样性得分保留前 K 个标记,并与不可变锚点集合并构成。该方法确保最具信息量的标记被保留,同时维持有界内存与长时域流式处理的计算效率。
实验
- 在 3D 重建、视频深度估计和相机位姿估计任务上,基于 StreamVGGT 与新型 Long3D 基准进行评估,验证了在长序列流式场景中的有效性。
- 在 7-Scenes 与 NRGBD 数据集上,InfiniteVGGT 保持了最先进的重建精度,且时间误差累积极小,优于 CUT3R 与 TTT3R,同时避免了基线方法常见的 OOM 错误。
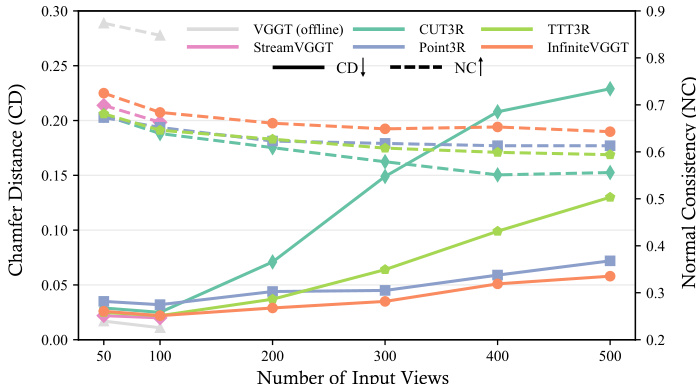
- 在 Long3D 上,序列长达近 10,000 帧,InfiniteVGGT 在多种场景下表现稳健,有效抑制了时间漂移,尽管在 Comp. 指标上略逊于基线。
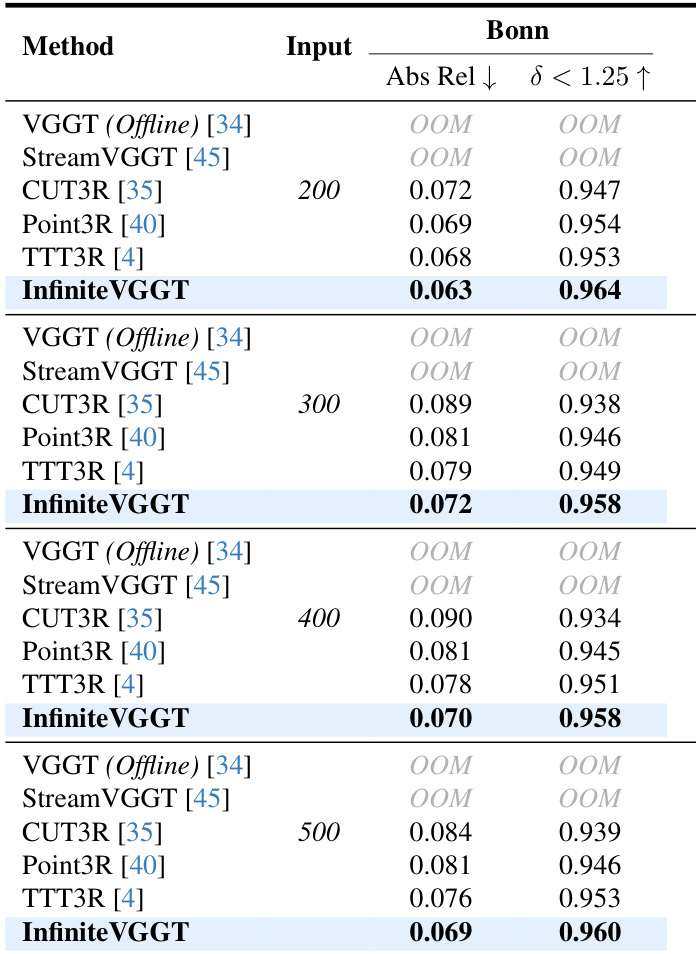
- 在 Bonn 数据集上,InfiniteVGGT 在长连续序列(200–500 帧)上展现出强大的视频深度估计性能,与 CUT3R 和 TTT3R 相当或更优。
- 消融研究证实,基于余弦相似度的标记选择提升了重建精度并降低了推理延迟,而动态分层预算分配与锚点帧保留显著提升了点云质量与稳定性。
- 在短序列(50–100 帧)上,该方法与 StreamVGGT 性能相当,指标差异可忽略,且在法向一致性上略有优势,验证了其高效性与鲁棒性。
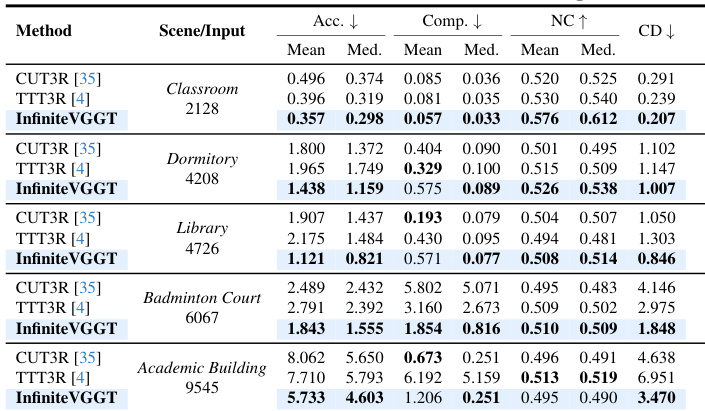
结果表明,InfiniteVGGT 在 Long3D 基准上多个场景与序列长度下均达到最先进性能,多数指标上优于 CUT3R 与 TTT3R。尽管其在时间误差累积方面显著优于其他方法,但在平均 Comp. 指标上表现欠佳,表明这是未来改进的关键方向。
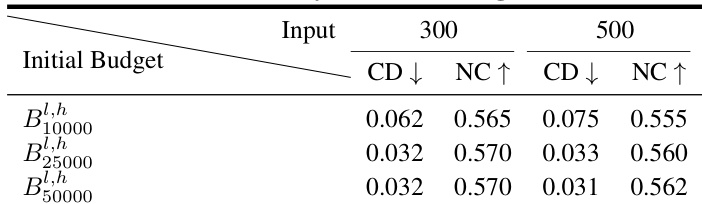
结果表明,增加初始标记存储预算可提升重建质量,从 B10000l,h 提升至 B25000l,h 时,Chamfer 距离显著下降,法向一致性明显改善。但进一步将预算提升至 B50000l,h 未带来额外增益,表明 B25000l,h 已足以实现最优性能。
结果表明,InfiniteVGGT 在 Bonn 数据集上的视频深度估计任务中表现最佳,优于 CUT3R 与 TTT3R 等基线方法,适用于不同输入长度。该方法保持高精度与一致性,绝对相对误差最低,δ < 1.25 指标值最高,充分证明其在长期深度估计中的有效性。
结果表明,InfiniteVGGT 在输入帧数不断增加时仍保持稳定的重建精度,其 Chamfer 距离与法向一致性均优于 CUT3R 与 TTT3R。该方法有效抑制了时间误差累积,在长序列中表现一致,而其他方法因内存限制导致性能下降或失败。
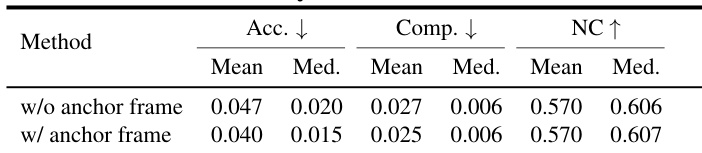
结果表明,引入锚点帧显著提升了重建精度,将平均 Chamfer 距离从 0.047 降低至 0.040,同时保持法向一致性稳定。作者通过该消融实验表明,保留首帧标记可防止误差累积,增强长序列 3D 重建的鲁棒性。