Command Palette
Search for a command to run...
VAR RL 正确实现:应对视觉自回归生成中的异步策略冲突
VAR RL 正确实现:应对视觉自回归生成中的异步策略冲突
摘要
视觉生成目前主要由三种范式主导:自回归(AutoRegressive, AR)、扩散模型以及视觉自回归(Visual AutoRegressive, VAR)模型。与AR和扩散模型不同,VAR模型在其生成过程的各个步骤中处理异构的输入结构,这导致了严重的异步策略冲突问题。该问题在强化学习(Reinforcement Learning, RL)场景下尤为突出,进而引发训练不稳定以及对齐效果不佳的问题。为解决这一挑战,我们提出了一种新型框架,通过显式管理此类冲突,以增强组相对策略优化(Group Relative Policy Optimization, GRPO)的效果。所提方法融合了三个协同作用的组件:1)一种用于引导早期生成阶段的稳定中间奖励机制;2)一种动态时间步重加权策略,以实现更精确的信用分配;3)一种基于奖励反馈学习(Reward Feedback Learning, ReFL)原理设计的新颖掩码传播算法,能够从时空两个维度有效隔离优化影响。实验结果表明,相较于原始的GRPO基线方法,本方法在样本质量与目标对齐性方面均实现了显著提升,为VAR模型提供了更加稳健且高效的优化能力。
一句话总结
清华大学与字节跳动的研究者提出 NextFlow,一种新颖的框架,通过引入稳定化的中间奖励、动态时间步重加权以及受奖励反馈学习启发的掩码传播算法,增强了视觉自回归模型的组相对策略优化,有效解决了异步策略冲突问题,从而在强化学习设置中提升了样本质量和对齐效果。
主要贡献
- 视觉自回归(VAR)模型通过粗到细、多尺度的标记预测过程生成图像,在强化学习过程中面临严重的异步策略冲突,这是由于生成步骤间输入结构高度异质所致,导致训练不稳定且对齐效果劣于自回归和扩散模型。
- 所提出的框架通过三个关键组件增强了组相对策略优化(GRPO):用于早期引导的稳定化中间奖励(VMR),用于平衡各尺度梯度贡献的动态时间步重加权(PANW),以及受奖励反馈学习启发的掩码传播(MP)算法,以实现空间和时间上的优化效果隔离。
- 实验表明,该方法显著提升了样本质量和目标对齐效果,相较于原始GRPO,训练曲线稳定,适用于不同前缀尺度,并在文本到图像生成任务中表现更优,为VAR模型建立了一套实用且高效的强化学习方案。
引言
研究者利用强化学习改进视觉自回归(VAR)图像生成,该范式通过在逐步细化的空间尺度上预测标记来生成图像,相比传统的光栅扫描方法具有更高的推理效率和保真度。尽管强化学习在提升其他生成模型的文本到图像对齐性和可控性方面已取得成功,但其在VAR架构中的应用仍面临独特挑战,源于异步、多尺度和并行标记生成的特性。先前工作未能解决因不同尺度间时间依赖性差异导致的策略冲突,造成训练不稳定和性能欠佳。本文主要贡献在于提出一种新颖框架,通过定制化的奖励机制和优化策略,解决这些异步策略冲突,从而实现VAR模型中稳定且高效的强化学习。
数据集

- 数据集包含自建训练语料库和精心筛选的评估集,训练数据在每张图像中的文本渲染区域分布存在显著不平衡——以单区域样本为主,且存在大量超过五个区域的图像构成长尾分布。
- 为缓解此不平衡问题,研究者对训练数据采用基于区域数量的过滤策略,将样本划分为六个区间:1、2、3、4、5 和 >5 区域,其中 >5 区间用于聚合长尾部分以供分析。
- 评估集设计遵循目标分布,区间2至5的概率分别为0.2、0.3、0.3和0.2,确保中等区域数量的均衡表示。
- 过滤后的训练集与评估集用于模型训练与评估,该过滤策略明确旨在使训练分布与目标任务难度对齐,而非泄露评估信息。
- 图像未进行裁剪;相反,基于区域数量及其在预定义区间的分布构建元数据,从而实现对训练与评估条件的精确控制。
方法
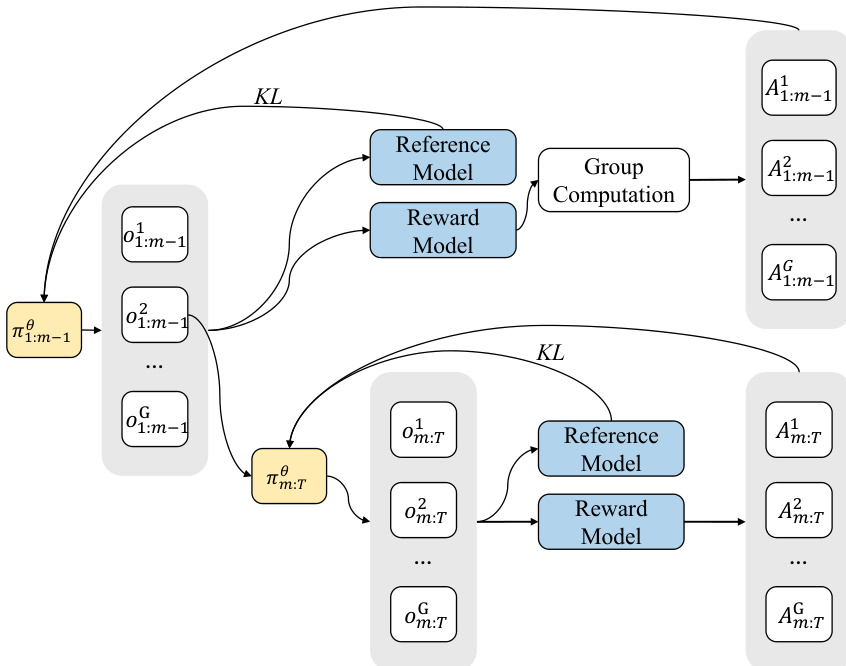
研究者采用分层强化学习框架,以应对视觉自回归(VAR)模型中因生成步骤间异质且并行的动作空间所引发的异步策略冲突。该方法的核心在于两阶段优化过程,将全时域强化学习目标分解为前缀与后缀子任务,从而缓解多步冲突,实现更稳定的训练。这一分解通过“价值作为中间回报”(VMR)机制实现,在中间时间步 m 引入一个中间软回报。框架使用蒙特卡洛估计计算前缀策略 π1:m−1θ 的奖励,随后对前缀与后缀段分别应用组相对策略优化(GRPO),每段均带有局部KL惩罚。该分阶段方法通过确保各阶段标记长度相近来稳定训练,同时保留全局目标值。详细算法在框架图中展示,图中呈现了策略更新、参考模型和奖励计算在两个阶段间的流动过程。
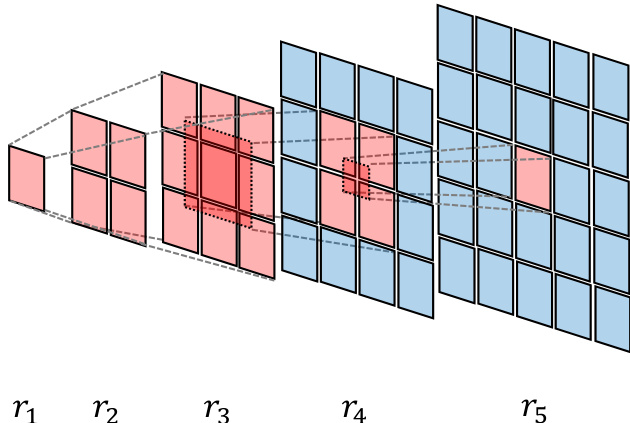
为平衡不同时间步的贡献并抵消因不同标记网格尺寸导致的步长异质性,研究者提出每动作归一化加权(PANW)。该技术通过权重 k_t = 1/(h_t w_t)^\\alpha 对每个动作 mathbfat 的损失进行归一化,其中 ht 和 wt 为时间步 t 的标记网格高度与宽度,alpha 为衰减指数。通过此方式加权损失,PANW确保具有更多查询标记的时间步不会过度影响学习过程,从而在所有时间步间实现更均衡的优化。该归一化对稳定训练动态至关重要,尤其考虑到不同时间步间任务相似性的显著差异,如标记网格尺寸分析所示。
最后,研究者提出一种新颖的掩码传播(MP)算法,以精确识别并优先更新对最终回报贡献最大的标记。该机制受奖励反馈学习(ReFL)原理启发,首先从直接决定奖励的输出组件(如预测的边界框)构建初始掩码。该掩码随后沿模型的多尺度层次结构向后传播,从细粒度到粗粒度特征尺度移动。传播过程引导更新聚焦于最相关的标记,有效在空间和时间上隔离优化影响。这种时空掩码机制降低了空间与时间上的方差,强化了信用分配,提升了跨尺度平衡,从而实现对VAR模型更高效、更有效的优化。
实验
- 在文本渲染(CVTG-2K)和HPS精修(HPSv3)任务上,使用基于两阶段强化学习框架的NextFlow-RL进行实验,通过VMR奖励优化前缀标记,并交替执行GRPO更新。
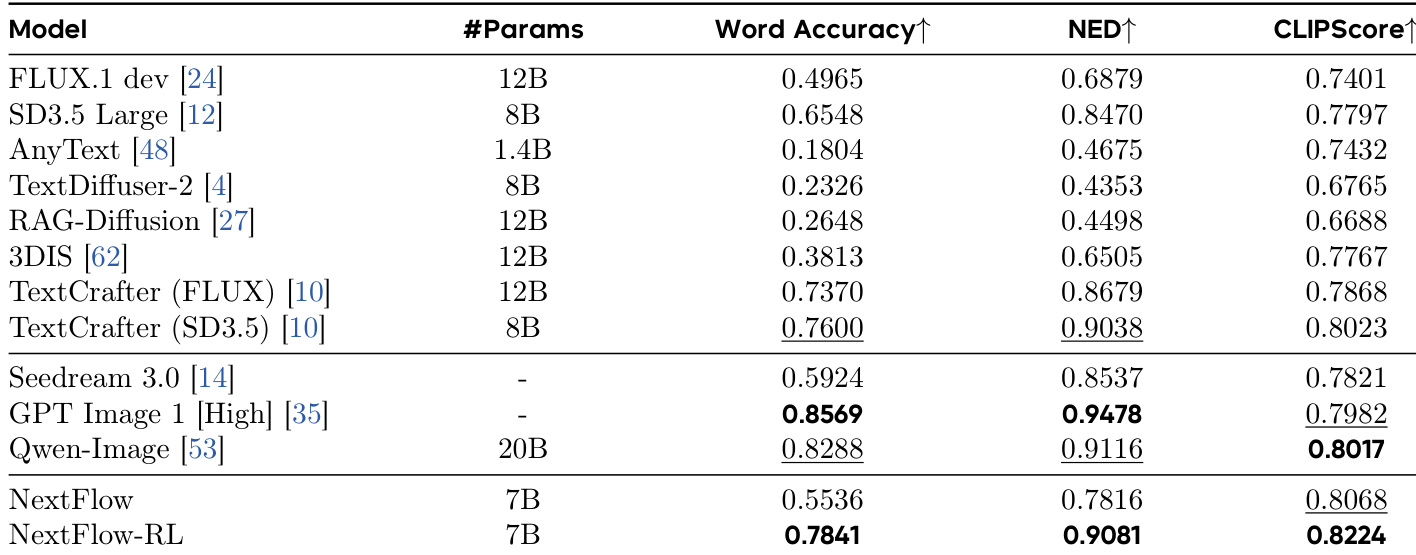
- 在CVTG-2K上,NextFlow-RL达到Word Accuracy 0.7841和NED 0.9081,分别优于NextFlow +0.2305和+0.1265,CLIPScore提升至0.8224(对比0.8068),验证了文本保真度与视觉质量的增强。
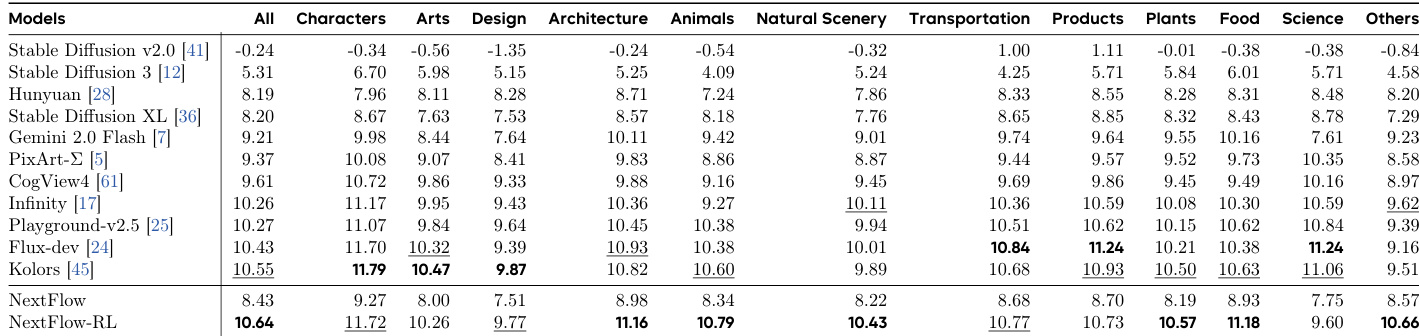
- 在HPSv3上,NextFlow-RL总得分为10.64,在多个类别中排名第一,包括动物(10.79)、自然景观(10.43)、植物(10.57)、食物(11.18)和建筑(11.16),在扩散模型中确立了最先进性能。
- 消融实验确认了最优设计选择:m=m256(128×128至256×256分辨率)以实现性能与效率的平衡,α=0.6至0.8作为衰减指数,K=2样本用于VMR估计,以及细粒度交替训练以实现更优的信用分配。
- 掩码传播(MP)在保持CLIPScore影响极小的前提下,提升了文本保真度(Word Acc. 0.7071 vs. 0.6855,NED 0.8699 vs. 0.8601),证实其在时空信用分配中的有效性。
研究者使用NextFlow-RL——NextFlow的强化学习增强版本——来提升文本渲染性能。结果表明,NextFlow-RL在所有对比模型中达到最高Word Accuracy(0.7841)、NED(0.9081)和CLIPScore(0.8224),显著优于基础NextFlow模型,并在CVTG-2K数据集上建立了新的最先进水平。
研究者采用两阶段强化学习方法优化图像中的文本渲染,结果表明在 m=128(对应 128×128 分辨率)处选取中间阶段值可实现Word Accuracy、NED和CLIPScore的最佳性能。该配置达到Word Accuracy 0.6677、NED 0.8501和CLIPScore 0.8142,优于其他 m 值及基线NextFlow模型。
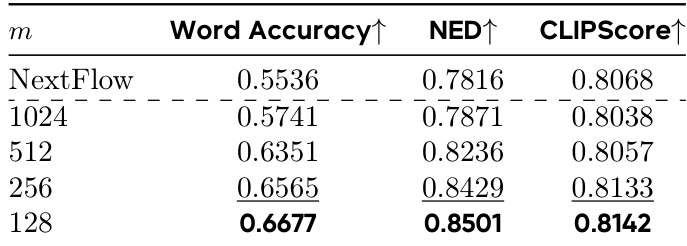
结果表明,奖励函数中衰减指数 α 的变化影响模型性能,α = 0.6 时达到最高Word Accuracy、NED和CLIPScore,表明该值在梯度归一化与各项指标表现间达到最优平衡。
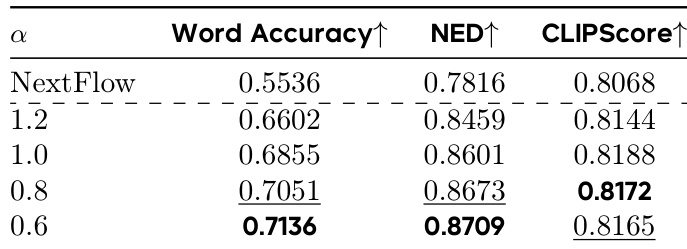
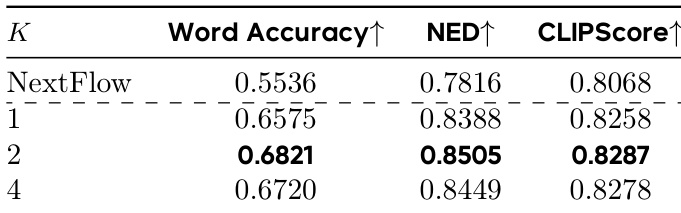
结果表明,增加VMR估计的在线策略样本数 K 可提升文本渲染性能,K=2 时达到最佳Word Accuracy(0.6821)、NED(0.8505)和CLIPScore(0.8287),优于 K=1 和 K=4。研究者采用此配置为默认设置,指出 K=2 在稳定性与性能间取得最佳平衡。
结果表明,NextFlow-RL在HPSv3基准测试的多个类别中均达到最先进性能,优于所有其他基于扩散的模型,在All、Animals、Natural Scenery、Plants和Food等关键指标上领先,同时在Characters和Design类别中排名第二。性能提升证明了两阶段强化学习方案的有效性,该方案通过OCR引导的奖励优化早期标记决策,显著提升了跨多样化领域的文本保真度与视觉质量。