Command Palette
Search for a command to run...
VIBE:基于视觉指令的编辑器
VIBE:基于视觉指令的编辑器
Grigorii Alekseenko Aleksandr Gordeev Irina Tolstykh Bulat Suleimanov Vladimir Dokholyan Georgii Fedorov Sergey Yakubson Aleksandra Tsybina Mikhail Chernyshov Maksim Kuprashevich
摘要
基于指令的图像编辑是生成式人工智能领域发展最为迅速的方向之一。过去一年中,该领域已迈上新台阶,数十个开源模型相继发布,同时涌现出多个功能强大的商业系统。然而,目前仅有少数开源方法能够达到实际应用级别的图像质量。此外,当前主流的扩散模型(diffusion backbones)在这些编辑流水线中占据主导地位,但其通常体积庞大、计算开销高昂,难以在众多部署场景和研究环境中高效运行,广泛使用的模型参数量通常在60亿至200亿之间。本文提出了一种轻量级、高吞吐量的基于指令的图像编辑框架,采用具有20亿参数的现代多模态模型Qwen3-VL作为编辑指导核心,并结合16亿参数的扩散模型Sana1.5完成图像生成。在架构设计、数据处理、训练配置及评估策略等方面,本工作聚焦于实现低成本推理与严格的源图像一致性,同时在当前规模下保持对主流编辑类别(如属性调整、物体移除、背景修改、目标替换等)的高质量表现。在ImgEdit与GEdit两个基准测试上的评估结果表明,所提方法在性能上可与显著更重的基线模型相媲美甚至超越,这些基线模型的参数量可达本方法的数倍,且推理成本更高。尤其在需要严格保留输入图像内容的编辑任务中,该方法表现出显著优势。模型仅需24 GB GPU显存即可运行,在配备NVIDIA H100显卡、以BF16精度进行推理的情况下,可实现高达2K分辨率图像的生成,耗时约4秒,且无需额外的推理优化或知识蒸馏技术。
一句话总结
来自SALUTEDEV研发部门的作者提出VIBE,一种基于指令的紧凑型图像编辑流程,采用20亿参数的Qwen3-VL模型进行引导,16亿参数的扩散模型Sana1.5进行生成,在计算成本极低的情况下实现高质量、严格保持源图像一致性的编辑——在24 GB GPU内存下高效运行,于H100上生成2K图像仅需约4秒,性能达到或超越更庞大的基线模型。
主要贡献
-
本文提出VIBE,一种紧凑且高吞吐量的基于指令的图像编辑系统,结合20亿参数的Qwen3-VL视觉语言模型(用于图像感知的指令理解)与16亿参数的扩散模型(Sana1.5),实现高效、源图像一致的编辑,计算开销极小。
-
该方法在ImgEdit和GEdit基准测试中达到最先进性能,尽管模型规模小,但仍能匹配或超越显著更大的模型,尤其在属性调整、物体移除和背景编辑方面表现优异,通过严格的源一致性保持输入图像保真度。
-
采用四阶段训练流程(对齐、预训练、监督微调、直接偏好优化)在约1500万组三元组上进行训练,利用多样化的现实世界指令和先进的数据过滤技术,确保高质量、符合人类意图的编辑,可在NVIDIA H100上以2K分辨率在4秒内完成生成。
引言
基于指令的图像编辑实现了直观、语言驱动的视觉修改,使内容创作摆脱专家级工具的限制。然而,大多数开源系统依赖大型扩散模型(60亿–200亿参数),导致高计算成本和缓慢推理速度,而专有模型在真实场景质量上仍占主导。以往工作常面临源一致性难题——难以保留身份、构图或光照等非预期细节,尤其在复杂编辑中,且常使用合成或模板化指令,与真实用户行为偏离。作者提出VIBE,一种紧凑、高吞吐量的编辑流程,使用20亿参数的Qwen3-VL视觉语言模型生成图像感知的编辑指令,16亿参数的扩散模型(Sana1.5)负责生成。其核心贡献是四阶段训练流程——对齐、预训练、监督微调和直接偏好优化,实现严格源一致性与高质量编辑,仅需24 GB GPU内存,H100上生成2K图像约4秒。系统基于约1500万组三元组训练,数据来自多样化的现实来源,经过严格过滤与数据增强(包括三元组反转与自举),以降低噪声并提升鲁棒性。VIBE在ImgEdit和GEdit基准测试中匹配或超越更庞大的基线模型,尤其在属性调整、物体移除和背景编辑方面表现突出,同时保持高效与可访问性。
数据集
-
数据集由多个来源构成,包括UltraEdit等大规模编辑数据集的重制版本、来自照片与视频的真实世界三元组、感知与识别数据集生成的合成数据,以及精心筛选的文本到图像(T2I)图像。在初始2100万组三元组中过滤掉噪声数据后,最终选取约770万组高质量三元组用于预训练。
-
预训练数据包含640万组来自基于重制UltraEdit的流水线的三元组,候选编辑由指令引导模型生成,并通过自动化验证进行筛选。图像重采样至860×860至2200×2200分辨率,宽高比在[1:6, 6:1]之间,通过面部对齐(IoU阈值0.9)和单应性校正强制空间一致性,消除几何偏移。
-
监督微调(SFT)阶段使用约680万组高质量三元组,数据来源多样:真实三脚架照片(4,139组)、RORD视频帧(通过基于嵌入的多样性采样保留10%)、VITON-HD用于服装变更(含合成与调和)、LVIS用于对象级与全图风格化(363,280组风格化三元组与363,280组反转三元组)、视觉概念滑块(195,525组)、从Open Images v7及其他真实照片集自主挖掘(290万组)、ControlNet引导的修复(177,739组)、以及HaGRID和EasyPortrait等感知数据集(分别107,619组与40,000组)。
-
为DPO构建了基于生成增强的检索数据集,使用来自公开与内部来源的真实世界编辑请求。流程包括聚类用户意图、通过从Qdrant向量数据库检索生成基于真实表达的合成指令、使用Gemini 3 Flash验证指令-图像适用性,并通过专有模型生成目标图像。最终数据集包含176,532组三元组,额外通过指令反转与编辑间复合过渡生成三元组。
-
所有SFT数据均通过任务调优的Gemini验证器(阈值3.5)和基于面部IoU的几何过滤器(阈值0.9)进行过滤,分别剔除约15%和35%的数据以消除伪影与空间不一致。对输入-输出对应用单应性校正。
-
模型采用多阶段训练流程:预训练阶段使用编辑与T2I数据混合(编辑占比50%,T2I占比50%),随后在真实、合成与增强三元组的均衡混合上进行SFT。DPO训练使用结合自生成、对称与蒸馏对的复合偏好数据集,以提升指令遵循性与美学质量。
-
元数据构建包括真实用户意图的语义聚类、合成指令基于检索的自然语言对齐,以及自动生成反转与复合指令,以提升数据集多样性与双向性。
方法
作者采用双组件架构实现基于指令的图像编辑,整合大型视觉语言模型(VLM)与扩散Transformer。VLM(具体为Qwen3-VL-2B*)处理输入图像与用户提示,生成上下文感知的引导信息。通过在VLM输入序列中引入可学习的元标记(meta-tokens),将其与指令标记拼接,并通过冻结的VLM主干进行处理。生成的元标记隐藏状态记为T^M,随后通过一个轻量级、可训练的连接模块映射至扩散模型的条件空间。该连接模块采用Transformer编码器堆叠实现,将VLM输出转换为条件特征CT,输入扩散Transformer。扩散Transformer基于Sana1.5-1.6B模型,通过去噪一个受输入图像、用户提示及连接模块输出条件的潜在表示,合成编辑后的图像。整体流程如框架图所示。
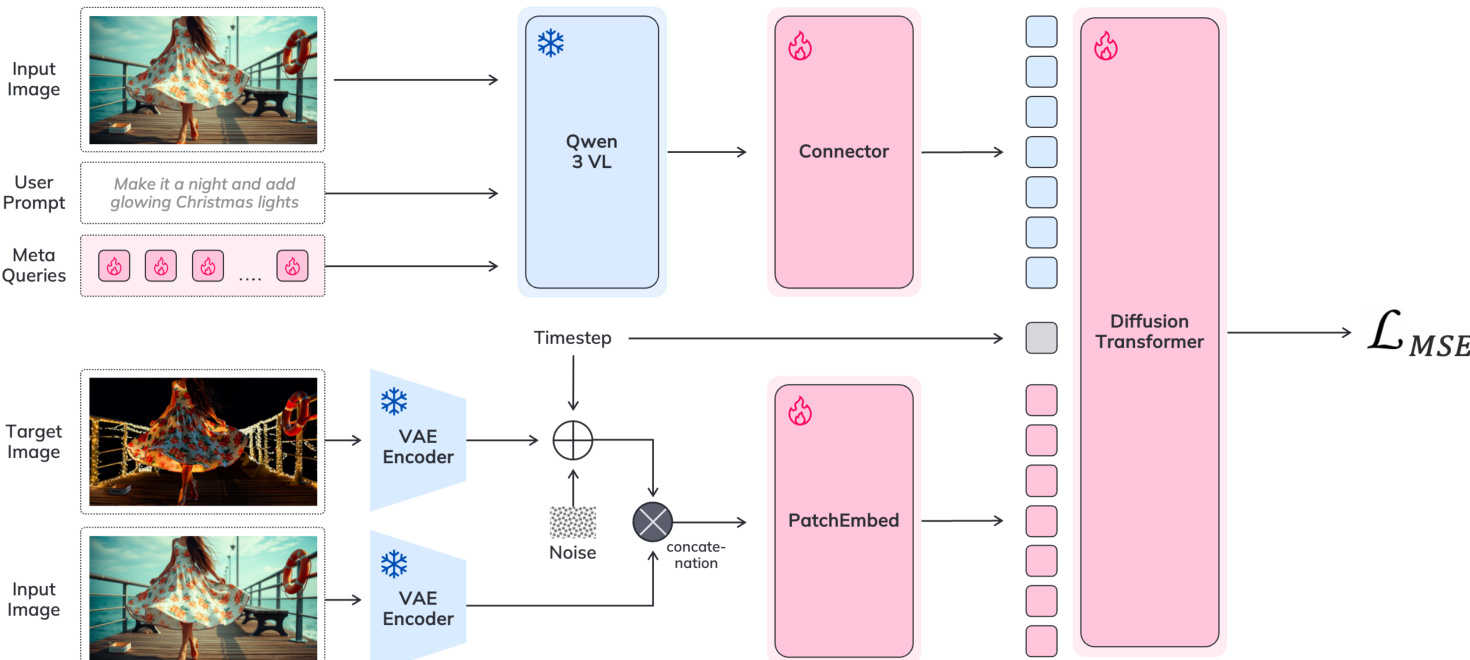
训练过程分为四个阶段,以确保稳定性和高质量输出。第一阶段为连接器对齐阶段,VLM与扩散模型冻结,仅训练连接器在文本到图像生成任务上,建立两组件间的稳定接口,防止后续训练中扩散模型生成先验的灾难性遗忘。第二阶段为多阶段训练阶段,从5122分辨率开始,逐步推进至20482。该阶段采用混合数据策略,在同一批次中同时训练模型于基于指令的编辑三元组与高质量文本到图像对。对于文本到图像样本,使用空条件图像,其在注意力层中被掩码。这种联合训练正则化学习并保留模型的基础生成能力。第三阶段为大规模预训练与监督微调(SFT),在最高20482分辨率下进行,使用高质量、过滤后的数据集。此阶段模型同时训练于编辑与文本到图像任务,VLM主干保持冻结。最终阶段应用扩散DPO(DPO)以优化模型的指令遵循性与视觉质量。训练流程还采用混合分辨率策略,同时在3842至20482分辨率、多样宽高比的数据上训练,加速收敛并保留高分辨率生成先验。该方法区别于传统渐进式缩放,因预训练的扩散主干无需低分辨率预热。

实验
- 严格主导对过滤有效减少了奖励过优化,实现了平衡增益,性能匹配或超越复杂的多偏好采样策略。
- 按序列连接参考图像相比通道连接提升了指令遵循性能,但使Sana的线性注意力推理时间翻倍,并在DiT模型中导致超线性延迟。
- 元查询配置相比Q-Former与原生编码器基线显著提升了指令遵循能力。
- 对于两种连接器类型,四层均表现最优;ELLA仅在少数情况下带来微弱且不一致的改进。
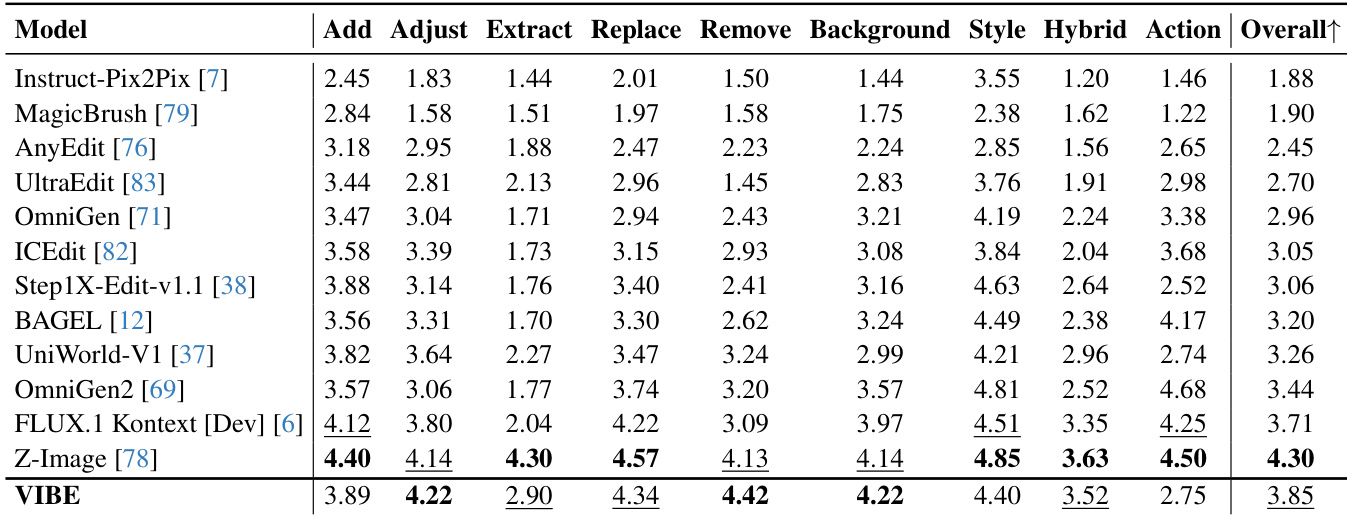
- 在ImgEdit-Bench上,VIBE整体得分为3.85(第二名),在核心类别如Adjust(4.22)、Remove(4.42)和Background(4.22)中领先,尽管主干较小,仍展现出极强的最小编辑保真度。
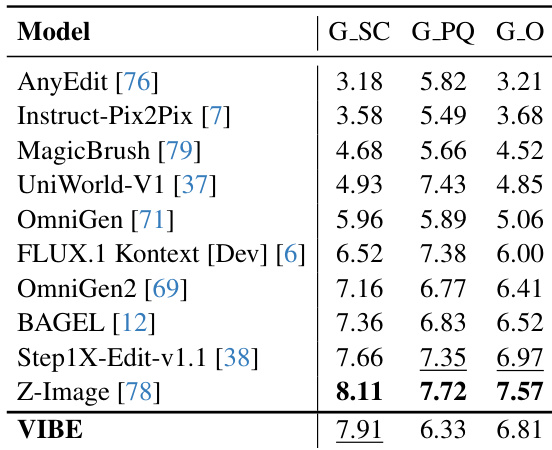
- 在GEdit-Bench-EN上,VIBE整体得分为6.81,语义一致性得分高达7.91(第二高),表明指令遵循可靠,但感知质量(6.33)低于专用模型,可能源于细微伪影而非语义偏差。
- VIBE优先保证忠实、最小侵入性编辑,而非激进场景重建,在局部与结构化编辑中表现优异,但在复杂非局部编辑(如Action)上面临挑战。
结果表明,VIBE在GEdit-Bench-EN上取得7.91的最高语义一致性得分,超越所有其他模型,同时获得6.81的第二高整体得分。模型展现出强大的指令遵循能力,尤其在保留输入图像细节方面,尽管其感知质量得分因细微视觉伪影略低于部分基线。
作者使用一个包含预训练与微调组件的综合性数据集,其中大部分数据来自预训练来源,如UltraEdit Remake和Aurora。总数据集规模约为1450万样本,结合预训练、监督微调与GAN生成数据,支持模型在图像编辑任务中的优异表现。
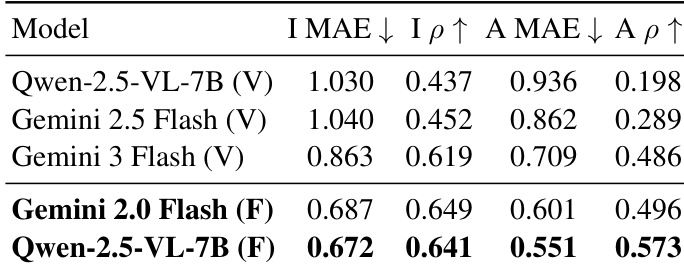
作者通过定量比较评估模型在ImgEdit基准上的性能,重点关注I MAE、I ρ、A MAE和A ρ等指标。结果显示,Gemini 2.0 Flash (F)模型在所有指标上表现最佳,优于Gemini 2.5 Flash (V)和Qwen-2.5-VL-7B (V)与(F),在I MAE和A MAE上最低,I ρ和A ρ得分最高。

作者采用四阶段训练流程,逐步提升分辨率并聚焦于不同可训练模块与数据组合。最终阶段“偏好对齐”仅在高分辨率下使用偏好对,且以DiT作为可训练模块,表明训练重点转向指令遵循与编辑质量的微调。

结果表明,VIBE在ImgEdit基准上取得3.85的整体得分,位列对比方法中的第二名。其在多个核心编辑类别(如Adjust、Remove、Background)中领先,这些类别要求严格保留输入图像,同时在多种操作中展现出强大的指令基础能力,尽管使用了更小的扩散主干。