Command Palette
Search for a command to run...
NextFlow:统一的序列建模激活多模态理解与生成
NextFlow:统一的序列建模激活多模态理解与生成
摘要
我们提出NextFlow,一种在6万亿个交错排列的文本-图像离散标记上训练的统一解码器-only自回归Transformer模型。通过在统一的自回归架构中引入统一的视觉表征,NextFlow原生具备多模态理解与生成能力,可实现图像编辑、交错内容生成以及视频生成等强大功能。受不同模态本质差异的启发——文本具有严格的序列性,而图像则具有固有的层次结构——我们在处理文本时保留传统的下一个标记预测机制,但在视觉生成中采用下一个尺度(next-scale)预测策略。这一方法突破了传统栅格扫描(raster-scan)生成方式的限制,使1024×1024图像的生成仅需5秒,速度较同类自回归模型快数个数量级。为解决多尺度生成过程中的不稳定性问题,我们设计了一套稳健的训练方案。此外,我们提出一种前缀调优(prefix-tuning)策略,以支持强化学习的高效应用。实验结果表明,NextFlow在统一模型中达到当前最优性能,并在视觉质量上媲美专门的扩散模型基线。
一句话总结
来自字节跳动、清华大学和莫纳什大学的作者提出 NextFlow,这是一种统一的仅解码器自回归 Transformer,采用下一尺度预测进行视觉生成——不同于传统的光栅扫描方法——可在 5 秒内完成 1024×1024 图像合成,实现最先进的多模态性能和生产级编辑能力,其稳健的训练与前缀调优策略支持强化学习。
主要贡献
- NextFlow 引入了一种统一的仅解码器自回归 Transformer,基于 6 万亿个交错的文本-图像标记进行训练,通过在单一架构内实现原生多模态理解与生成,克服了独立大语言模型(LLM)与扩散模型范式的局限性。
- 它摒弃了图像的光栅扫描下一标记预测,转而采用下一尺度预测,仅用 5 秒即可生成 1024×1024 高分辨率图像——比以往自回归模型快数个数量级,同时双码本分词器确保了语义丰富性与视觉保真度。
- 该模型在统一模型中达到最先进性能,视觉质量媲美专用扩散基线,并支持复杂交错任务,如思维链推理和上下文图像编辑,已在 EditCanvas 基准和多个多模态基准上得到验证。
引言
作者利用统一的仅解码器 Transformer 架构,弥合多模态理解与生成之间的鸿沟,解决大语言模型(LLM)与扩散模型之间长期存在的分离问题。尽管 LLM 在推理和上下文学习方面表现出色,而扩散模型能生成高保真图像,但以往的统一方法要么因低效的光栅扫描自回归生成导致高分辨率下推理速度极慢,要么依赖以重建为导向的分词器,缺乏语义丰富性,限制了理解性能。NextFlow 通过引入下一尺度预测范式,从粗到细分层生成图像,将 1024×1024 图像生成时间缩短至仅 5 秒,并采用双码本分词器,解耦语义与像素级特征,提升概念对齐能力。模型在文本、图文对及交错多模态数据上训练了 6 万亿个标记,结合一种新颖的前缀调优策略用于分组奖励策略优化(GRPO),通过聚焦粗尺度结构预测来稳定强化学习。为实现高保真输出,引入可选的扩散解码器进一步精炼离散生成,实现最先进视觉质量的同时保持统一架构。结果表明,该模型在图像质量上媲美基于扩散的系统,在图像编辑上超越专用模型,并自然支持复杂交错任务,如思维链推理和上下文学习。
数据集

- 该数据集是一个大规模多模态集合,融合图像与文本,旨在支持多样化任务,包括视觉理解、图像生成、图像编辑、交错图文文档生成以及文本生成。
- 在视觉理解方面,数据集包含来自开源来源的图像字幕样本,辅以富含文本的图像(如含文字场景、表格、图表)以及与世界知识关联的图像。字幕通过视觉-语言模型(VLM)重写,以提升质量与细节。数据采用分层结构,包含主类别与子类别,视觉样本突出显示前 10 个最显著类别。
- 图像生成部分包含一个十亿级数据集,来源包括开源仓库、高质量照片集(Megalith、CommonCatalog)及内部图像画廊。图像经过启发式过滤与美学评分(>4.3)以剔除低质量内容。使用零样本 SigLip2 分类器平衡景观、人物、动物、植物和食物等类别的主题分布。所有图像均通过 VLM 进行字幕生成,以获得准确、详细的描述。在 CT 阶段加入少量合成数据,以增强生成的美学效果。
- 传统编辑数据始于开源数据集(UniWorld-V1、RealEdit、ShareGPT-4o-Image),通过人工检查与 VLM 评估过滤分辨率不匹配及低质量编辑。移除未响应指令的不良编辑。为缓解对简单任务的偏见,构建合成数据集,使编辑类型(如添加、删除、替换)与语义类别(局部、全局、视角、文本、风格)的分布更加均衡。
- 在交错生成方面,从 OmniCorpus-CC、OmniCorpus-YT 和 Koala36M 构建视频-文本数据集。原始视频片段经过筛选:时长超过 20 秒的片段被丢弃,仅保留美学评分(>4.3,前 30%)、清晰度(>0.7,前 50%)和运动评分(>4)较高的片段——约剔除 75% 数据。使用 SigLIP 进行语义平衡,对过代表类(如“人物”和“电视新闻”)进行下采样(各移除 50%)。采用运动自适应帧选择,利用 RAFT 光流算法剔除静态或仅含相机运动的帧,保留具有显著物体运动或结构变化的帧。帧以 0.5 FPS 采样,最大保留 5 帧(512px)或 3 帧(1k 分辨率)。VLM 生成帧间连贯的过渡文本,形成交错的图文序列。
- 该数据集在训练中以多种数据类型混合使用:视觉理解、图像生成、编辑与交错生成数据按定制比例组合。模型在统一预训练阶段训练这些组件,合成数据在 CT 阶段引入以优化生成质量。
- 关键处理包括所有图像数据的 VLM 基础字幕生成、运动感知帧选择以及通过零样本分类实现的语义平衡。元数据通过自动化 VLM 推理与人工筛选构建,确保所有任务中内容的高质量、多样性和代表性。
方法
作者采用统一的仅解码器自回归 Transformer 架构 NextFlow,用于处理交错的文本-图像离散标记序列。整体框架处理多模态输入并生成交错的多模态输出,如框架图所示。模型从 Qwen2.5-VL-7B 初始化,提供强大的多模态先验,并扩展以支持使用下一尺度预测范式的视觉标记预测。该方法摒弃传统光栅扫描方式,通过逐步生成更粗粒度的尺度,实现 1024×1024 图像在 5 秒内合成。模型使用单一输出头处理文本与图像标记,通过交叉熵损失训练以预测两种模态的码本索引。
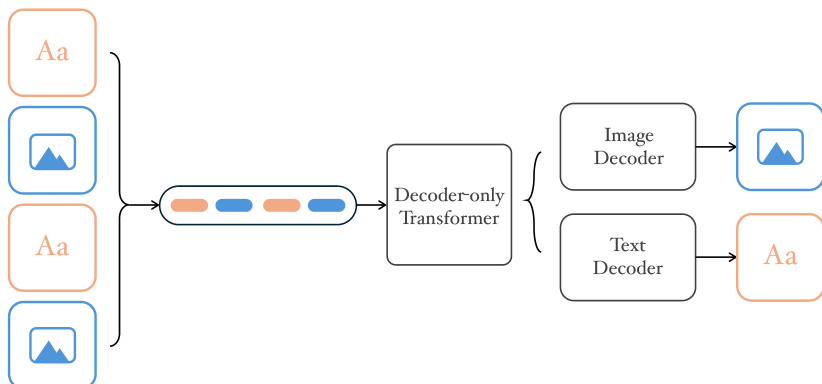
该模型的分词器采用双码本架构,基于 TokenFlow,解耦语义与像素级特征的学习,同时通过共享映射机制保持其对齐。该设计通过重建保真度与语义一致性双重约束量化过程,确保离散标记同时包含高层概念与精细视觉细节。语义编码器从 siglip2-so400m-naflex 初始化,支持可变分辨率与宽高比处理,结合基于 CNN 的像素分支,使自回归模型可直接在原生分辨率下训练。采用多尺度 VQ 进一步提升量化质量。

位置编码采用多尺度 3D RoPE 机制。对于位置为 t 的文本标记,其位置在三个维度上复制为 (t,t,t)。对于视觉标记,空间与尺度信息通过归一化空间坐标与增强的尺度索引显式编码。每个在尺度 s 上、网格坐标为 (i,j) 的块接收位置 (px,py,ps)=(HWC(i+0.5),HWC(j+0.5),s),其中 H×W 为网格尺寸,C 为常数范围因子。该归一化公式支持分辨率无关训练。此外,引入可学习的尺度嵌入与正弦尺度长度位置嵌入,以增强模型对不同分辨率的适应能力。
为解决下一尺度预测范式中早期与晚期尺度间标记数量不平衡问题,作者引入尺度感知损失重加权。其权重设定为 ks=(hs×ws)α1,其中 hs×ws 为尺度 s 的空间分辨率,α 为超参数。该公式提升早期尺度预测的重要性,确保结构生成稳定。训练中还引入自校正机制,以缓解暴露偏差与局部冲突。该机制在编码阶段从 top-k 最近索引的多项分布中采样,而模型目标仍为预测 top-1 索引。视觉输入直接使用码本中的残差特征,不进行累积,从而限制视觉输入特征空间的复杂度,减少局部伪影。
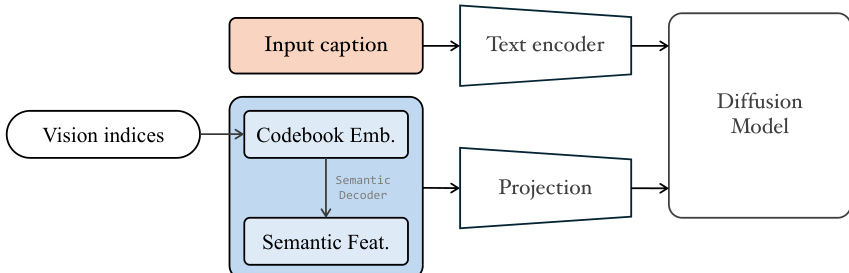
引入可选的扩散解码器作为精炼模块,以突破视觉质量的边界。在完成下一尺度视觉索引预测后,获取来自语义与像素码本的对应嵌入。语义嵌入通过分词器的语义解码器处理,生成高维语义特征。这三个元素——语义嵌入、像素嵌入与解码后的语义特征——被拼接、投影后输入扩散模型,作为视觉条件。扩散模型还通过文本分支整合图像字幕。

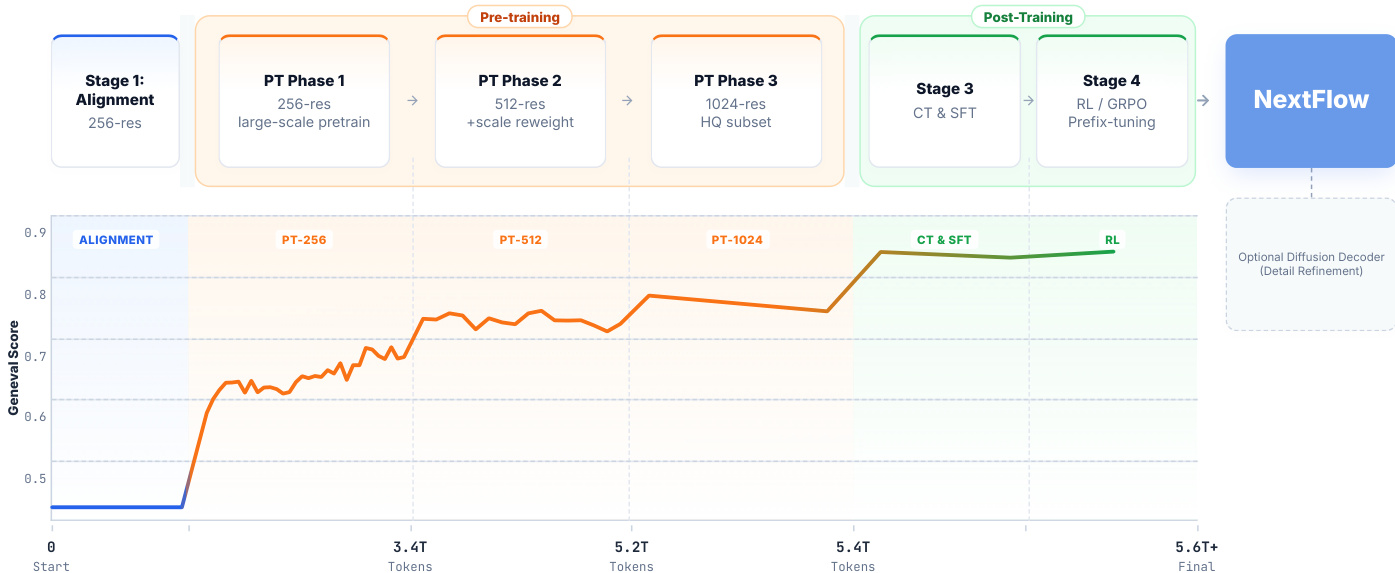
训练流程包含多个阶段。分词器采用多阶段策略:首先独立训练像素分支;然后联合训练所有组件;最后单独微调像素解码器。模型在约 6 万亿个标记上进行预训练,分为三个子阶段:256 级、512 级与 1024 级,采用渐进分辨率课程。在 512 级阶段,应用尺度重加权策略以稳定训练并消除伪影。预训练后,采用两阶段后训练策略:在高质量数据上继续训练以提升美学质量,随后在对话数据上进行监督微调,以增强自然性与上下文适配性。
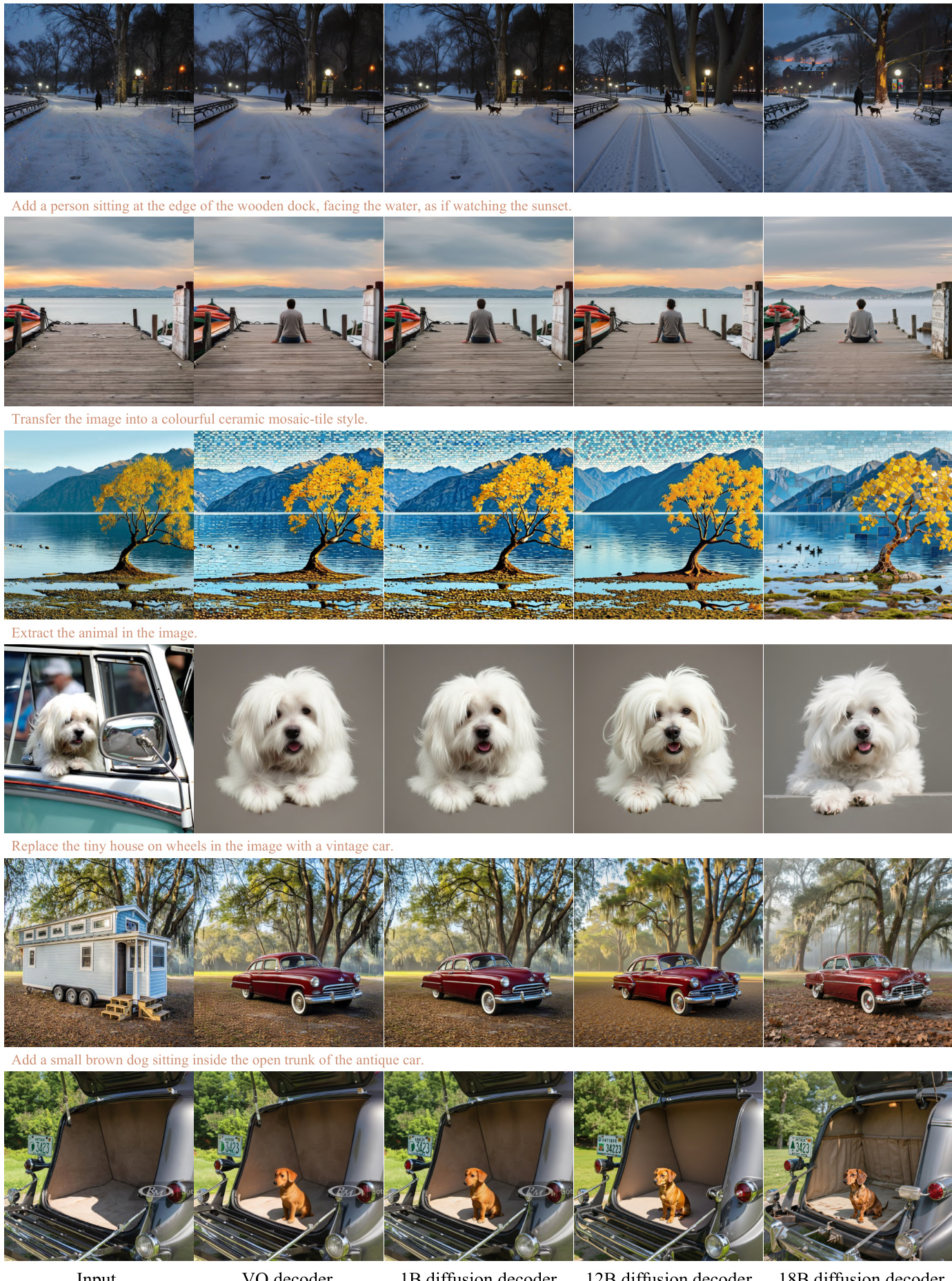
在强化学习中,作者采用分组奖励策略优化(GRPO)并引入前缀调优策略。由于 VAR 架构的早期步骤对全局布局最为关键,强化学习更新聚焦于粗尺度。前 m 个尺度的策略被优化,而更细尺度的策略保持冻结。该方法通过将高方差的强化学习信号集中于最具语义意义的生成步骤,避免对后期策略的噪声更新,从而稳定训练。
实验
- 轻量级消融研究验证了共享单头输出设计,显示其训练损失更低,性能优于双头变体,因此被采纳用于大规模训练。
- 使用残差特征的自校正显著提升性能,在 60% 标记校正概率(p=1.0)时达到最优结果,而累积特征因输入空间复杂度不匹配导致性能下降。
- 训练中引入 25% 纯文本数据不会损害文本到图像生成质量,保持强大的文本能力。
- 高性能内核优化(如融合线性交叉熵、RoPE、RMS 归一化、Flash-Attention)将每 GPU 的峰值内存使用减少约 20GB,提升算术强度。
- 离线预提取图像索引可消除在线编码延迟,支持高效数据打包,提升训练吞吐量。
- 通过预计算 TFLOPS 实现工作负载均衡,减少 GPU 间空闲时间,相比朴素打包实现 4.1 倍加速。
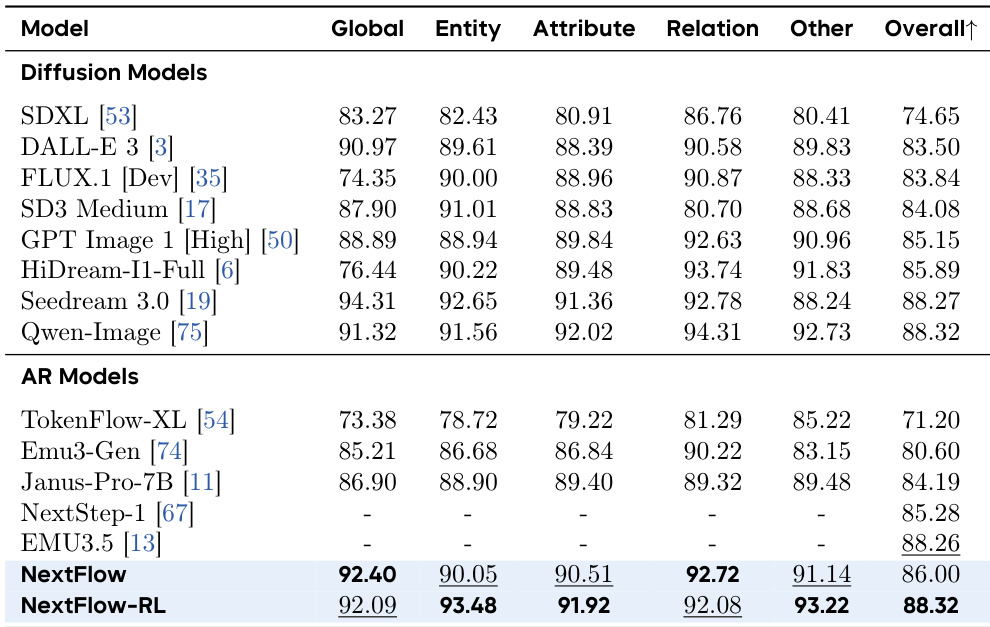
- 在 GenEval 上,NextFlow RL 达到 0.84(最先进),超越 FLUX.1-dev 并与顶级模型持平。
- 在 WISE 上,NextFlow RL 得分为 0.62,与 Qwen-Image 相当,优于自回归基线(如 Show-o: 0.30)。
- 在 PRISM-Bench 上,NextFlow RL 总得分为 78.8,与 Seedream 3.0 和 Qwen-Image 持平,展现强大的美学与文本渲染质量。
- 在 ImgEdit 上,NextFlow RL 得分为 4.49(最高),在 Adjust(4.68)与 Remove(4.67)任务中表现优异。
- 在 OmniContext 上,NextFlow RL 达到 9.22 SC,优于 OmniGen2(8.34),在主体一致性上接近 GPT-4o(9.03)。
- 在 GEdit-Bench 上,NextFlow RL 总得分为 7.87,优于基线在语义一致性和感知质量方面。
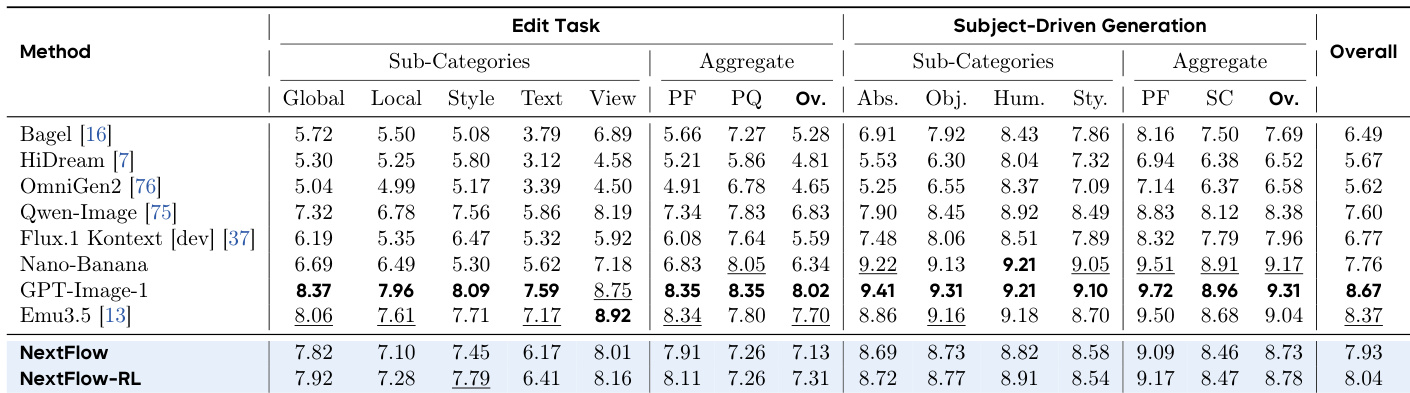
- 在 EditCanvas 上,NextFlow RL 总得分为 8.04,Subject-Driven Generation 子任务得分为 8.78,证实其在细粒度编辑中的均衡卓越表现。
- 在交错生成方面,NextFlow 能生成连贯的交替图文序列,涵盖叙事、食谱与动态场景。
- 上下文学习使 NextFlow 能从示例中推断并应用变换模式,展现强大适应性。
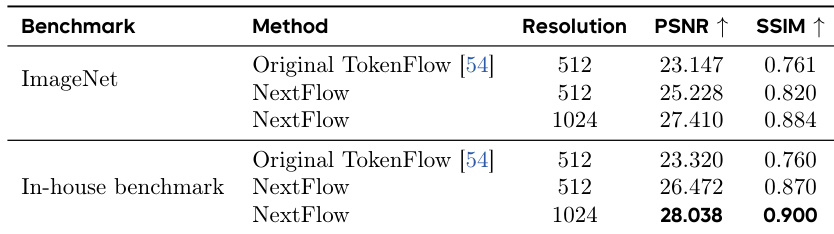
- 在 ImageNet-1K(512²)上,NextFlow 相比 TokenFlow 提升 PSNR +2.08 dB;在 1024² 上达到 28.04 PSNR,验证了多阶段训练与尺度丢弃策略的有效性。
- 在多模态理解基准上,7B 模型在 40M 复合数据(19M 字幕 + 21M SFT)上微调后,在各项任务中表现稳健,超越更大规模基线。
- 推理效率分析显示,由于下一尺度预测范式中的动态标记生成与 KV 缓存,NextFlow 相比 MMDiT 最多减少 6 倍 FLOPs。
作者采用共享输出头设计的仅解码器模型,在对齐与监督微调阶段,其总损失与视觉损失均低于独立模态专用头。结果表明,共享头架构始终优于双头方法,因此在后续所有实验中采用更简单且高效的单头设计。
作者采用共享输出头设计的仅解码器模型,在对齐与监督微调阶段,其训练损失更低,性能更优,优于独立模态专用头。结果表明,NextFlow-Rl 在多个基准上达到最先进性能,超越基于扩散的模型及其他自回归模型,在提示遵循、世界知识与美学质量方面表现卓越。
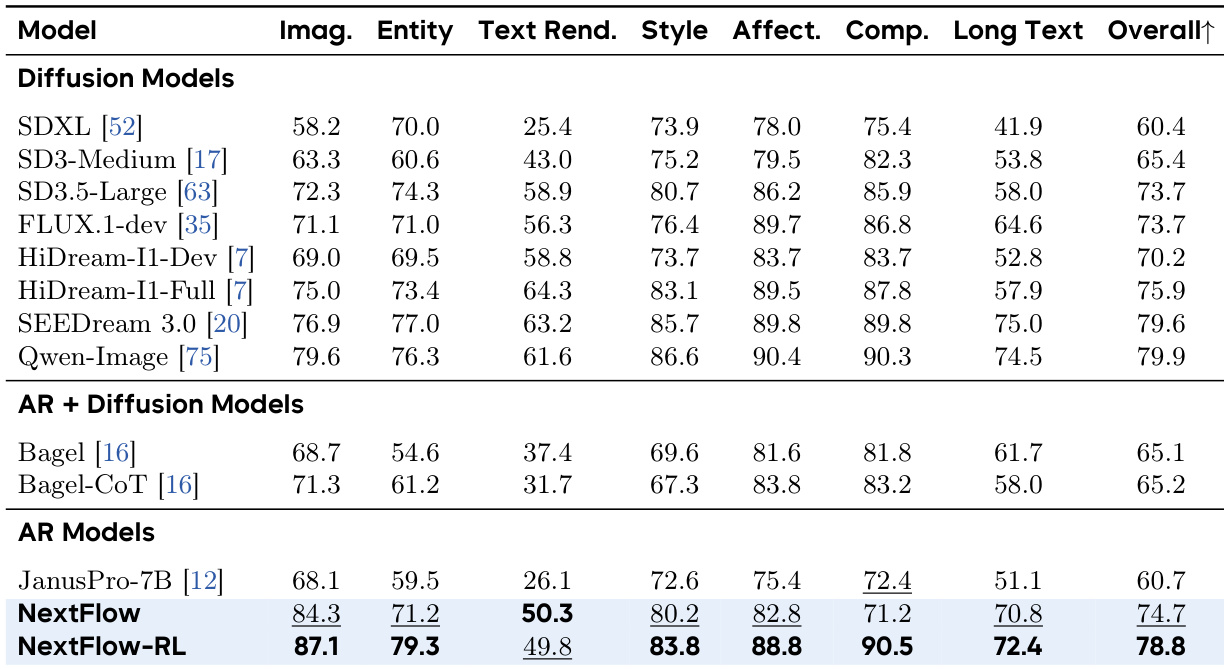
结果表明,NextFlow-RL 在 EditCanvas 基准上取得 8.04 的最高总分,全面超越所有对比方法,涵盖传统编辑与主体驱动生成任务。其在主体驱动生成方面表现尤为突出,得分为 8.78,表明在保持高美学质量的同时能实现精确的局部修改。
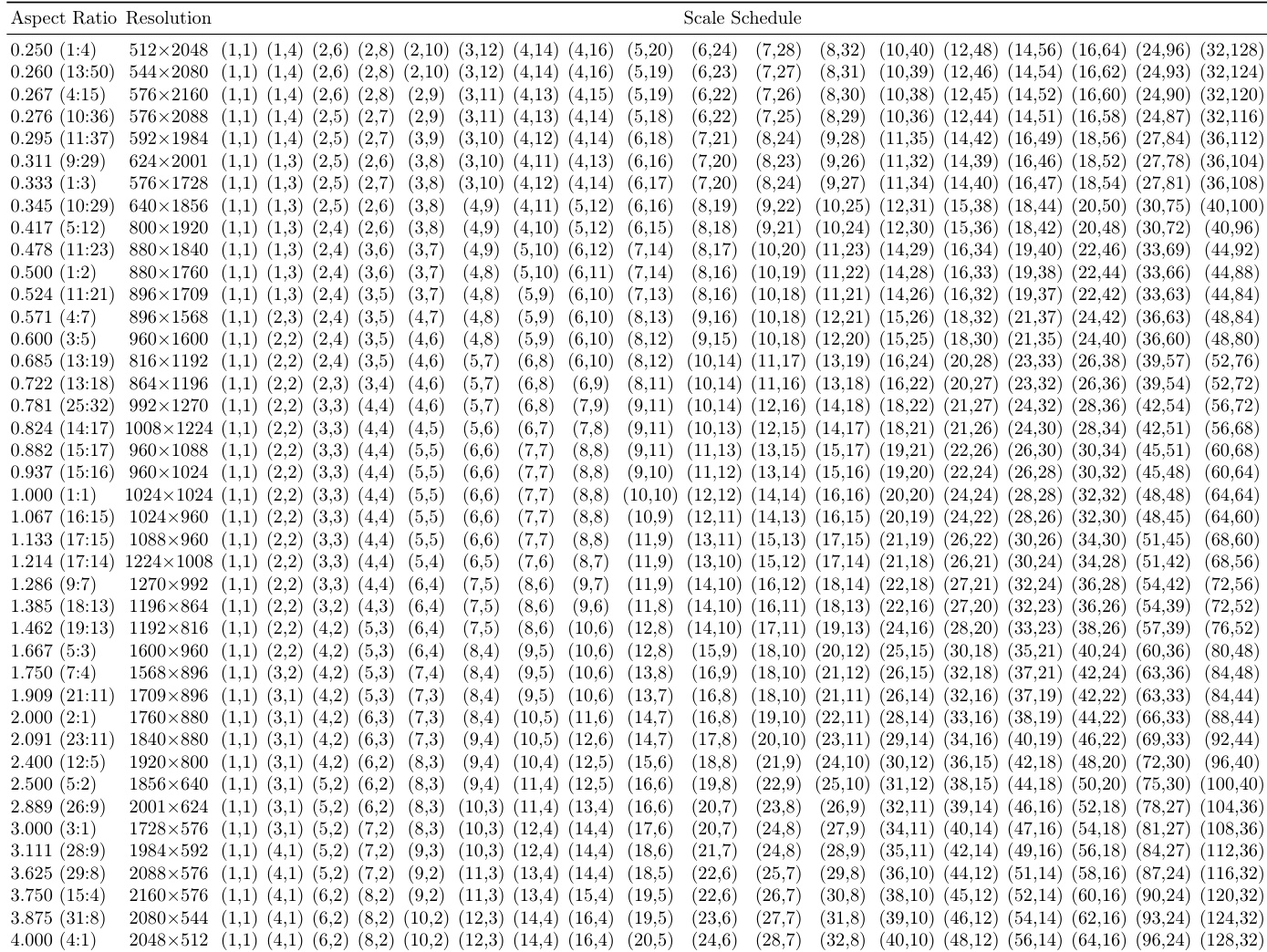
作者采用一种尺度调度策略,在训练步骤中动态变化分辨率与宽高比,从 1×1 逐步增加至目标分辨率。表格显示,模型在广泛分辨率与宽高比下训练,尺度调度在每一步动态调整序列长度,以支持高效的下一尺度预测。
作者将 NextFlow 与原始 TokenFlow 架构在图像重建任务上进行对比,结果显示 NextFlow 在 512×512 与 1024×1024 分辨率下均取得更高的 PSNR 与 SSIM 分数。具体而言,在 ImageNet-1K 的 512×512 分辨率下,NextFlow 提升 PSNR 2.08 dB;在内部基准的 1024×1024 分辨率下,PSNR 达到 28.038,验证了其多阶段训练与尺度丢弃策略的有效性。