Command Palette
Search for a command to run...
熵自适应微调:通过解决自信冲突以缓解遗忘
熵自适应微调:通过解决自信冲突以缓解遗忘
Muxi Diao Lele Yang Wuxuan Gong Yutong Zhang Zhonghao Yan Yufei Han Kongming Liang Weiran Xu Zhanyu Ma
摘要
监督微调(Supervised Fine-Tuning, SFT)是领域适应的标准范式,但其常导致灾难性遗忘(catastrophic forgetting)问题。与此形成鲜明对比的是,基于策略的强化学习(on-policy Reinforcement Learning, RL)能够有效保留模型的通用能力。本文深入探究这一差异,发现其根源在于一个根本性的分布偏差:RL 与模型内部信念保持一致,而 SFT 则强制模型拟合外部监督信号。这种不匹配往往表现为“自信冲突”(Confident Conflicts)类型的 token,其特征为低概率但低熵。在这些情况下,模型对其自身预测具有高度置信,却被迫学习与之相悖的真实标签,从而引发破坏性的梯度更新。为应对这一问题,我们提出熵自适应微调(Entropy-Adaptive Fine-Tuning, EAFT)。与仅依赖预测概率的方法不同,EAFT 采用 token 级别的熵作为门控机制,以区分认知不确定性(epistemic uncertainty)与知识冲突(knowledge conflict)。该机制使模型能够从不确定性样本中学习,同时抑制在冲突数据上的梯度传播。在 Qwen 与 GLM 系列模型(参数规模涵盖 4B 至 32B)上,针对数学、医疗及智能体(agentic)等多个领域开展的大量实验验证了我们的假设。结果表明,EAFT 在保持下游任务性能与标准 SFT 相当的同时,显著缓解了通用能力的退化问题。
一句话总结
北京邮电大学与中关村学院的研究人员提出熵自适应微调(EAFT),一种新方法,通过使用 token 级熵作为梯度更新的门控机制,缓解领域适应中的灾难性遗忘,区分认知不确定性与知识冲突。与标准 SFT 强制对齐外部监督不同,EAFT 在保持通用能力的同时,实现了与 SFT 相当的下游性能,在 Qwen 和 GLM 模型的数学、医疗和智能体任务中表现优异。
主要贡献
- 监督微调(SFT)常因根本性的分布差异导致灾难性遗忘:它迫使模型拟合与内部信念冲突的外部监督,引发“自信冲突”——即高置信度预测与真实标签矛盾,导致破坏性梯度更新。
- 所提出的熵自适应微调(EAFT)方法引入 token 级熵作为门控机制,以区分认知不确定性与有害知识冲突,使模型能够从不确定的 token 中学习,同时抑制冲突样本的梯度,从而保留通用能力。
- 在 Qwen 和 GLM 模型(4B 至 32B 参数)上,针对数学、医疗和智能体领域的广泛实验表明,EAFT 在保持 SFT 下游性能的同时,显著降低通用能力的退化,是一种轻量级替代方案,相比在线策略强化学习具有更低的计算开销。
引言
作者研究了大语言模型中监督微调(SFT)的不稳定性,其常导致灾难性遗忘——即领域特定适应会损害通用能力。尽管在线策略强化学习(RL)通过将更新对齐于模型内部分布来保留通用知识,但 SFT 强制模型拟合外部监督,产生“自信冲突”:在低熵 token 上,模型高度自信,却必须学习一个极不可能的标签,从而触发破坏性梯度更新。先前方法尝试使用概率或 KL 散度作为代理来缓解此问题,但无法有效区分认知不确定性与有害知识冲突。作者提出熵自适应微调(EAFT),一种轻量级、动态的方法,利用 token 级熵作为门控机制,在抑制冲突样本梯度的同时允许从不确定样本中学习。EAFT 在目标领域上达到与标准 SFT 相当的性能,同时在数学、医疗和智能体任务中显著减少遗忘,且计算开销极小,无需参考模型或预过滤数据。
数据集

- 数据集由三个主要来源构成:Numina-Math(Li 等,2024)、BigMathVerified(Albalak 等,2025)和 Nemotron-CrossThink(Aker 等,2025),均聚焦于数学推理。
- 这些提示的响应由 Qwen3-235B-A22B-Instruct 模型(Yang 等,2025)合成,最终训练集包含 19,000 个经验证的正确数据对。
- Numina-Math 包含约 86 万个竞赛级数学问题及解答,涵盖广泛的数学学科和难度级别。
- BigMathVerified 是一个高质量、大规模的数据集,强调推理严谨性和自我修正,专为数学推理中的强化学习设计。
- Nemotron-CrossThink 的数学子集提供高质量的合成问题,经过严格的逻辑验证,利用自我修正模式提升数学推导的精确性。
- 作者使用此 19k 数学训练集进行模型微调,并结合其他领域特定数据(如医疗和智能体数据)采用混合训练策略。
- 在处理过程中,作者应用严格过滤,仅保留模型生成响应经验证为正确的样本,确保数据质量。
- 未提及显式裁剪,但最终训练集通过从验证输出中随机采样形成。
- 元数据构建包括来源归属、问题类型分类和正确性验证,支持可复现性和分析。
- 训练数据与跨领域基准结合使用——数学(AIME24/25、GSM8K)、通用(MMLU、IFEval、CLUEWSC)、医疗(MedMCQA、PubMedQA、MedQA)和智能体能力(BFCL v3)——以评估模型性能。
方法
作者研究了监督微调(SFT)中灾难性遗忘的机制,并提出一种新方法以缓解该问题。为理解根本原因,他们从 token 级别分析了 SFT 与在线策略强化学习(RL)数据之间的分布差异。框架图展示了这一区别:在 SFT 中,训练数据常包含“自信冲突”,即模型对某个 token 赋予高置信度(低熵),但真实标签却极不可能(低概率)。当外部监督迫使模型覆盖其强先验时,这种情况发生,例如在数学课上将“球”标记为“截角二十面体”。相比之下,在线策略 RL 通过自回放生成序列,使得 token 自然对齐于模型当前的概率分布,要么落入高概率置信区域,要么进入高熵探索区域。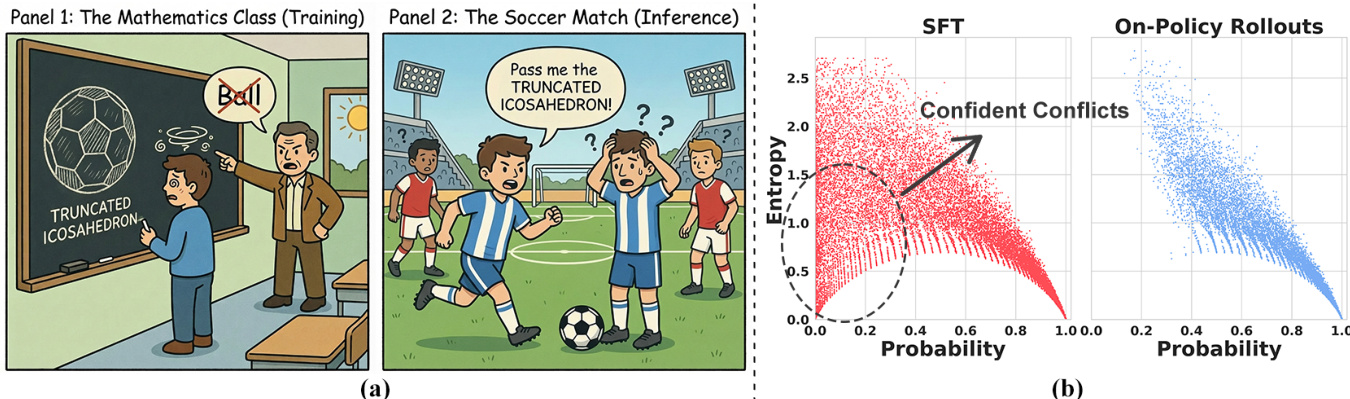
为量化此现象,作者引入两个关键指标:token 级概率 pt=Pθ(yt∣x,y<t),衡量模型对真实 token 的置信度;预测熵 Ht=−∑v∈VPt(v)logPt(v),衡量模型在词汇表上的不确定性。分析揭示出显著的分布差距:SFT 数据呈现出明显的低熵、低概率 token 聚类,作者将其识别为破坏性梯度的主要来源。该洞察通过初步实验得到验证:在训练中屏蔽这些“自信冲突” token 可显著缓解灾难性遗忘。
基于此,作者提出熵自适应微调(EAFT),一种软门控机制,根据 token 级熵动态调节训练损失。EAFT 目标函数为加权和形式,标准交叉熵监督乘以归一化熵项:LEAFT(θ)=−∑t=1TH~t⋅logPθ(yt∣x,y<t)。门控项 H~t 由 top-K token 的熵推导而来,通过 ln(K) 作为 K 个结果的最大熵进行归一化,范围为 [0,1]。该归一化构建了自调节机制:当模型自信但冲突(低熵)时,权重 H~t 趋近于零,有效抑制破坏性梯度;当模型不确定或探索(高熵)时,权重保持较高,允许标准 SFT 目标学习新模式。该方法区别于现有基于概率的重加权策略,因其利用熵区分刚性与不确定性,从而自动降低冲突数据的破坏性更新,同时将监督集中在高熵 token 上以促进适应。
实验
- 主实验验证了 EAFT 在多种领域中缓解灾难性遗忘的同时,保持了强大的目标任务性能。
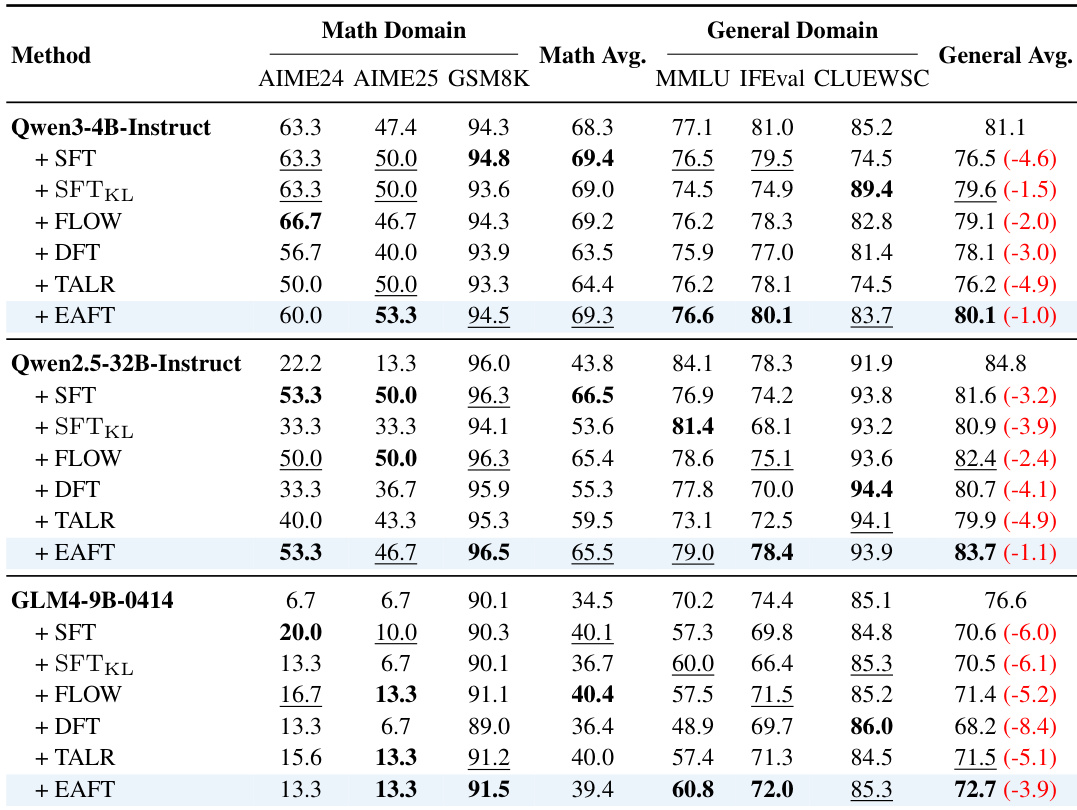
- 在数学基准(AIME24、AIME25、GSM8K)上,EAFT 的结果与最佳方法相差不超过 1 分,同时最小化通用能力的退化。
- 在通用基准(MMLU、IFEval、CLUEWSC)上,EAFT 显著优于标准 SFT,平均性能下降大幅减少(例如 CLUEWSC 仅下降 1.6 分,而 SFT 下降 10.7 分)。
- 在医疗领域(MedMCQA、PubMedQA、MedQA),EAFT 将通用能力平均值保持在 84.5(SFT 为 81.3),并在目标任务上略优于 SFT(73.7 vs. 73.6)。
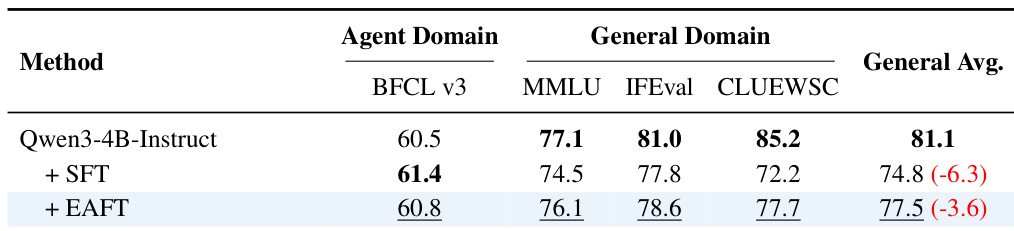
- 在智能体工具使用领域(BFCL),EAFT 达到 60.8(与 SFT 的 61.4 相差不到 1%),同时将通用性能保持在 77.5(SFT 为 74.8)。
- 梯度分析证实,EAFT 抑制了“自信冲突”区域(低熵、低概率)的大梯度,防止破坏性更新。
- 训练动态显示,EAFT 在低熵 token 上稳定损失,同时在高熵 token 上与 SFT 保持一致,实现有效适应而不过度优化。
- 消融研究确认熵感知门控是关键机制——软门控(EAFT)优于硬屏蔽(Masked SFT),在保留目标性能的同时消除遗忘。
- Top-K 熵近似(K=20)与精确熵的相关性达 0.999,且计算开销可忽略,支持高效实现。
作者使用 EAFT 在数学任务上微调模型,同时保留通用能力。结果表明,EAFT 在目标数学基准上保持竞争力,同时相比标准 SFT 显著减少通用领域得分的下降,其中 CLUEWSC 和 MMLU 的提升最为明显。
作者使用 EAFT 在智能体工具使用任务上微调 Qwen3-4B-Instruct 模型,结果表明其在目标 BFCL 基准上保持竞争力,同时相比标准 SFT 显著减少通用能力的下降。结果表明,EAFT 仅造成平均 3.6 分的下降,而 SFT 下降 6.3 分,充分证明其在缓解灾难性遗忘方面的有效性。
作者使用 EAFT 在医疗领域数据上微调 Qwen3-4B-Thinking 模型,结果表明其在提升目标领域性能的同时保留了通用能力。结果表明,EAFT 在通用基准上的平均得分更高(84.5),优于标准 SFT(81.3),并在医疗任务上表现更优(73.7 vs. 73.6),表明其有效缓解了灾难性遗忘。

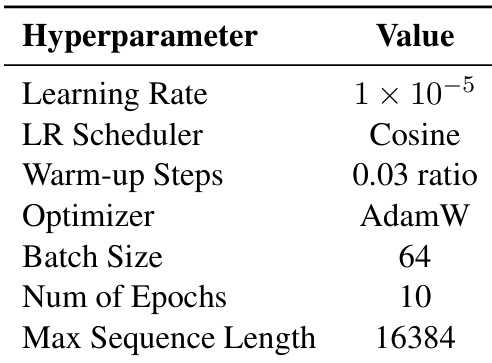
作者在所有模型上使用统一的超参数设置,包括学习率 1×10−5、AdamW 优化器和 10 个训练轮次。这些设置保持一致,以确保 EAFT 与基线方法之间的公平比较。