Command Palette
Search for a command to run...
K-EXAONE 技术报告
K-EXAONE 技术报告
摘要
本技术报告介绍了由LG AI Research研发的大规模多语言语言模型K-EXAONE。K-EXAONE基于专家混合(Mixture-of-Experts)架构,总参数量达2360亿,在推理过程中激活约230亿参数。该模型支持长达256K个标记(token)的上下文窗口,涵盖韩语、英语、西班牙语、德语、日语和越南语六种语言。我们在涵盖推理能力、智能体(agentic)行为、通用能力、韩语专项能力及多语言能力的综合性基准测试套件上对K-EXAONE进行了评估。实验结果表明,K-EXAONE在各项任务中的表现与同规模的开源模型相当。K-EXAONE旨在推动人工智能助力美好生活,被定位为一款强大的专有AI基础模型,适用于广泛工业与科研应用场景。
一句话摘要
LG AI Research 发布 K-EXAONE,这是一个拥有 2360 亿参数、激活参数为 230 亿的专家混合(Mixture-of-Experts)模型,支持 25.6K 令牌上下文长度,并涵盖韩语、英语、德语、日语和越南语六种语言。通过采用混合注意力机制、细粒度 MoE 路由与序列级负载均衡,以及使用 FP8 精度的多阶段训练课程,K-EXAONE 在推理、代理式、多语言和长上下文基准测试中均表现出色。该模型集成了多令牌预测模块以实现高效推理,并采用韩国增强型通用分类体系(Korea-Augmented Universal Taxonomy)确保文化语境下的安全性,定位为面向工业与科研应用的主权 AI 基础模型。
主要贡献
- K-EXAONE 通过利用政府支持的资源,克服了韩国在 AI 硬件和数据中心基础设施方面的限制,成功开发出一个万亿参数的基础模型,在区域资源受限的情况下仍实现全球竞争力。
- 该模型引入了一种混合架构,结合推理与非推理能力,采用专家混合(MoE)设计与混合注意力机制,实现高效的长上下文处理与可扩展计算。
- K-EXAONE 将多语言支持扩展至德语、日语和越南语,并在各类基准测试中表现出稳健性能,同时严格遵守 AI 合规协议,有效降低数据隐私、偏见和不当内容相关风险。
引言
大型语言模型(LLMs)的发展日益依赖于规模扩展,开源权重模型通过庞大的参数量不断缩小与闭源模型之间的性能差距。然而,韩国等国家面临显著的基础设施制约——缺乏专用 AI 数据中心和高性能芯片,严重阻碍了大规模模型的开发。为应对这一挑战,韩国政府启动了战略性计划,提供关键资源,使 LG AI Research 成功研发出 K-EXAONE,一个万亿参数的基础模型。作者采用融合推理与非推理能力的混合架构,结合用于长上下文处理的混合注意力机制,以及专家混合(MoE)设计,实现高效且可扩展的计算。K-EXAONE 将多语言支持扩展至德语、日语和越南语,显著提升其全球适用性。一个关键贡献是构建了 CODEUTILITYBENCH,一个真实世界编码基准,用于评估理解、实现、优化和维护等实际编码工作流,K-EXAONE 在该基准上优于其前代模型。此外,作者还提出了 KGC-SAFETY,一个基于韩国增强型通用分类体系(K-AUT)的文化语境安全基准,弥补了以西方为中心的伦理框架在评估韩国社会文化背景下 AI 安全性方面的局限。
数据集

- 数据集由内部资源与公开资源组成,重点评估韩语长上下文理解能力。
- 核心组成部分包括 KO-LONGBENCH,一个内部基准,涵盖文档问答、故事理解、对话历史理解、上下文学习、结构化问答和 RAG 等多样化任务。
- KO-LONGBENCH 旨在评估大语言模型在实际长上下文场景中的表现,包含详细统计数据、提示示例和任务描述,详见 EXAONE 4.0 技术报告 [2]。
- 作者将 KO-LONGBENCH 作为评估套件的一部分,采用 IFBENCH 和 IFEVAL 基准中的提示宽松与提示严格两种度量方式来衡量模型性能。
- 未描述显式裁剪或元数据构建;重点在于利用现有任务结构与提示格式以实现一致评估。
- 数据集用于模型训练与评估流程,混合比例与划分配置依据特定基准指南与技术文档确定。
方法
作者采用专家混合(MoE)架构构建 K-EXAONE,这是一个拥有 2360 亿总参数的大型多语言语言模型,其中推理过程中约激活 230 亿参数。整体框架基于 Transformer 设计,模型由多个堆叠块组成,通过一系列变换处理输入令牌。如图所示,架构分为两个主要组件:主模型块和多令牌预测(MTP)块,后者在训练与推理中用于自起草。
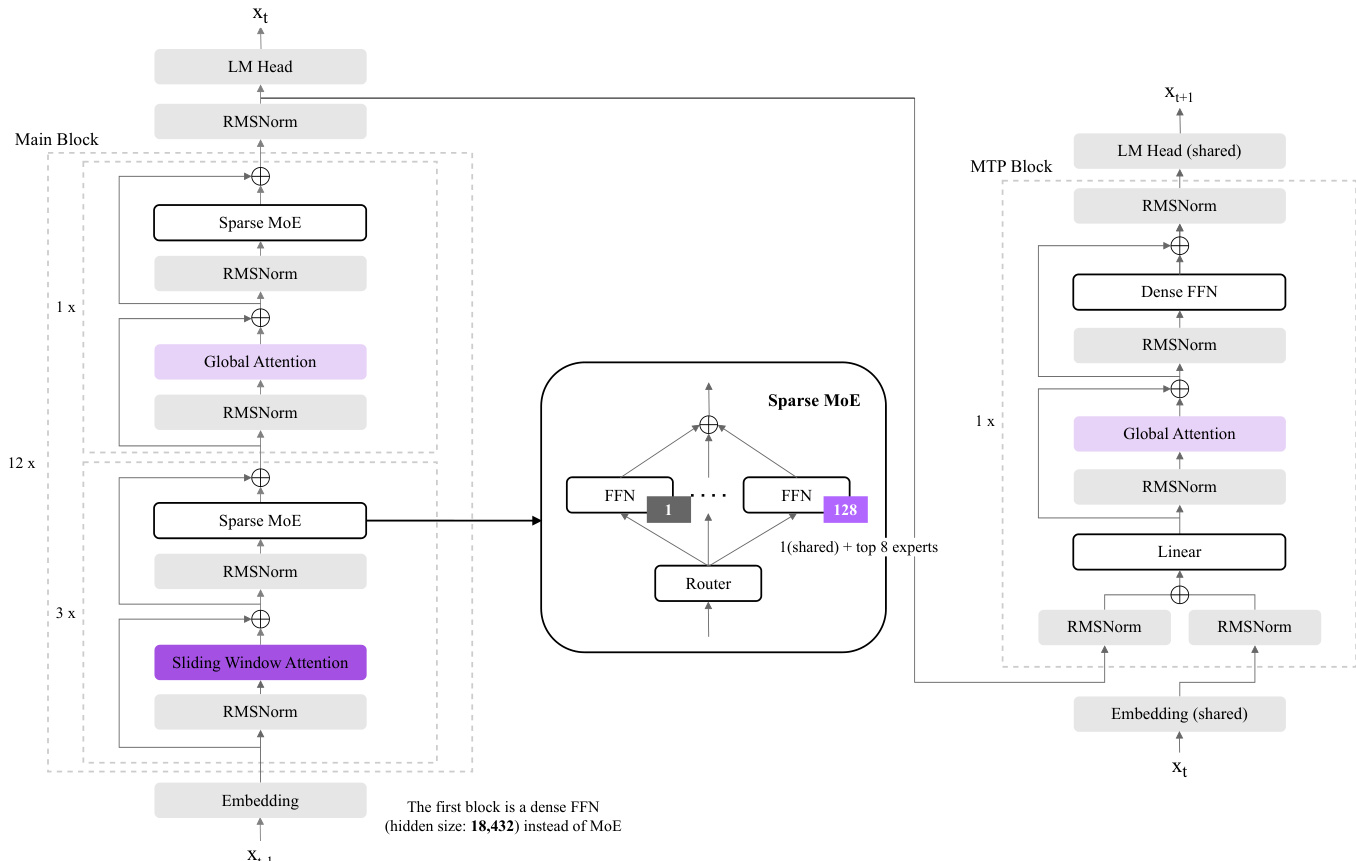
主块处理主输入序列,起始于将输入令牌转换为密集向量的嵌入层。该堆栈中的第一个块是隐藏层大小为 18,432 的密集前馈网络(FFN),作为训练稳定性机制。随后是 12 个块,每个块包含一个稀疏 MoE 层、一个全局注意力机制和 RMSNorm 归一化。MoE 层是核心计算组件,输入被路由至一组专家。具体而言,模型采用细粒度稀疏 MoE 设计,包含 128 个专家,每个令牌选择 top-8 专家与一个共享专家,每条路由决策中同时激活九个专家。路由机制由专用路由器管理,决定每个专家对最终输出的贡献。稀疏 MoE 块后接全局注意力层,计算整个序列的注意力,并通过 RMSNorm 归一化稳定训练动态。
除主块外,模型还引入了混合注意力架构,结合全局注意力与滑动窗口注意力(SWA),以高效处理长上下文输入。架构中包含全局注意力与滑动窗口注意力层,根据不同层选择性应用,以平衡计算成本与建模能力。滑动窗口大小缩减至 128 个令牌,以最小化键值缓存使用,同时保留模型捕捉长程依赖的能力。该设计实现了成本高效的长上下文建模,支持最大 256K 令牌上下文长度。
MTP 块用于训练与推理,旨在增强未来令牌预测能力并提升解码吞吐量。该块结构与主块类似,但包含一个密集前馈网络和一个线性层,用于预测下一个令牌。训练期间,MTP 块被监督以预测一个额外的未来令牌,提供辅助目标,从而最小化路由开销与内存消耗。推理时,MTP 块支持自起草,使模型能够并行生成多个令牌,相比标准自回归解码实现约 1.5 倍的吞吐量提升。MTP 块还包含共享嵌入层和 RMSNorm 归一化,确保与主模型架构的一致性。
为进一步稳定训练并提升长上下文外推能力,模型引入 QK Norm 与仅 SWA 的 RoPE 等架构特性。QK Norm 在注意力计算前对查询与键向量应用层归一化,缓解深层网络中的注意力 logit 爆炸问题,稳定训练动态。RoPE(旋转位置嵌入)仅应用于 SWA 层,避免干扰全局令牌交互,提升对长序列外推的鲁棒性。这些特性与 MoE 架构和混合注意力机制相结合,使 K-EXAONE 在保持资源效率的同时实现高性能。
实验
- 在 9 个基准类别上评估 K-EXAONE:世界知识、数学、编码/代理编码、代理工具使用、指令遵循、长上下文理解、韩语、多语言性与安全性。
- 在 MMLU-Pro、GPQA-DIAMOND 和 HUMANITY'S LAST EXAM 上,K-EXAONE 展现出强大的学术知识与推理能力,多数数学基准上优于 gpt-oss-120b 与 Qwen3-235B-A22B-Thinking-2507,仅在 HMMT Nov 2025 上落后于 Qwen。
- 在 TERMINAL-BENCH 2.0 上得分为 29.0,在 SWE-BENCH VERIFIED 上得分为 49.4,显示强大的代理式编码能力;在 tau2-BENCH 上得分为 73.2,表明多步工具使用高效。
- 在指令遵循方面,在 IFBENCH 上得分为 67.3,在 IFEVAL 的 REASONING 模式下得分为 89.7,超越多数基线模型。
- 在长上下文基准上,REASONING 模式下 AA-LCR 得分为 53.5,OPENAI-MRCR 得分为 52.3;NON-REASONING 模式下 AA-LCR 得分为 45.2,OPENAI-MRCR 得分为 65.9,展现出稳健的长上下文处理能力。
- 在韩语基准上:KMMLU-Pro 得分为 67.3,KoBALT 得分为 61.8,CLiCK 得分为 83.9,HRM8K 得分为 90.9,Ko-LONGBENCH 得分为 86.8,显示强大的多语言与领域特定性能。
- 在多语言性方面,MMMLU 得分为 85.7,WMT24++(平均翻译得分)得分为 90.5,表明平衡且高质量的多语言能力。
- 在安全性基准上,WILDJAILBREAK 与 KGC-SAFETY 上取得具有竞争力的安全率,通用价值观与社会安全表现优异,并在处理韩国特定文化敏感性与未来风险方面表现更优。
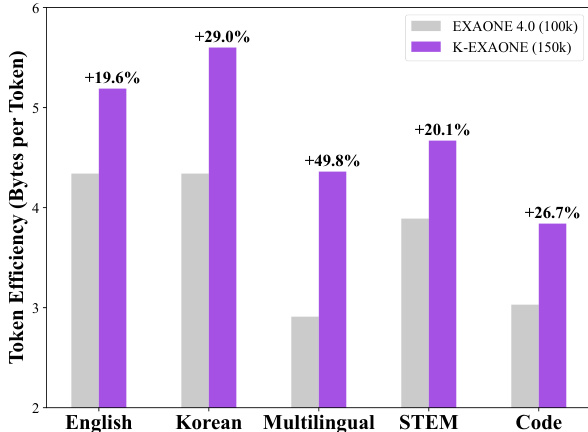
作者使用柱状图比较 K-EXAONE 与 EXAONE 4.0 在不同文本领域中的令牌效率,以每令牌字节数为度量。结果显示,K-EXAONE 在所有类别中均优于 EXAONE 4.0,其中韩语领域提升最为显著,达 +29.0%。
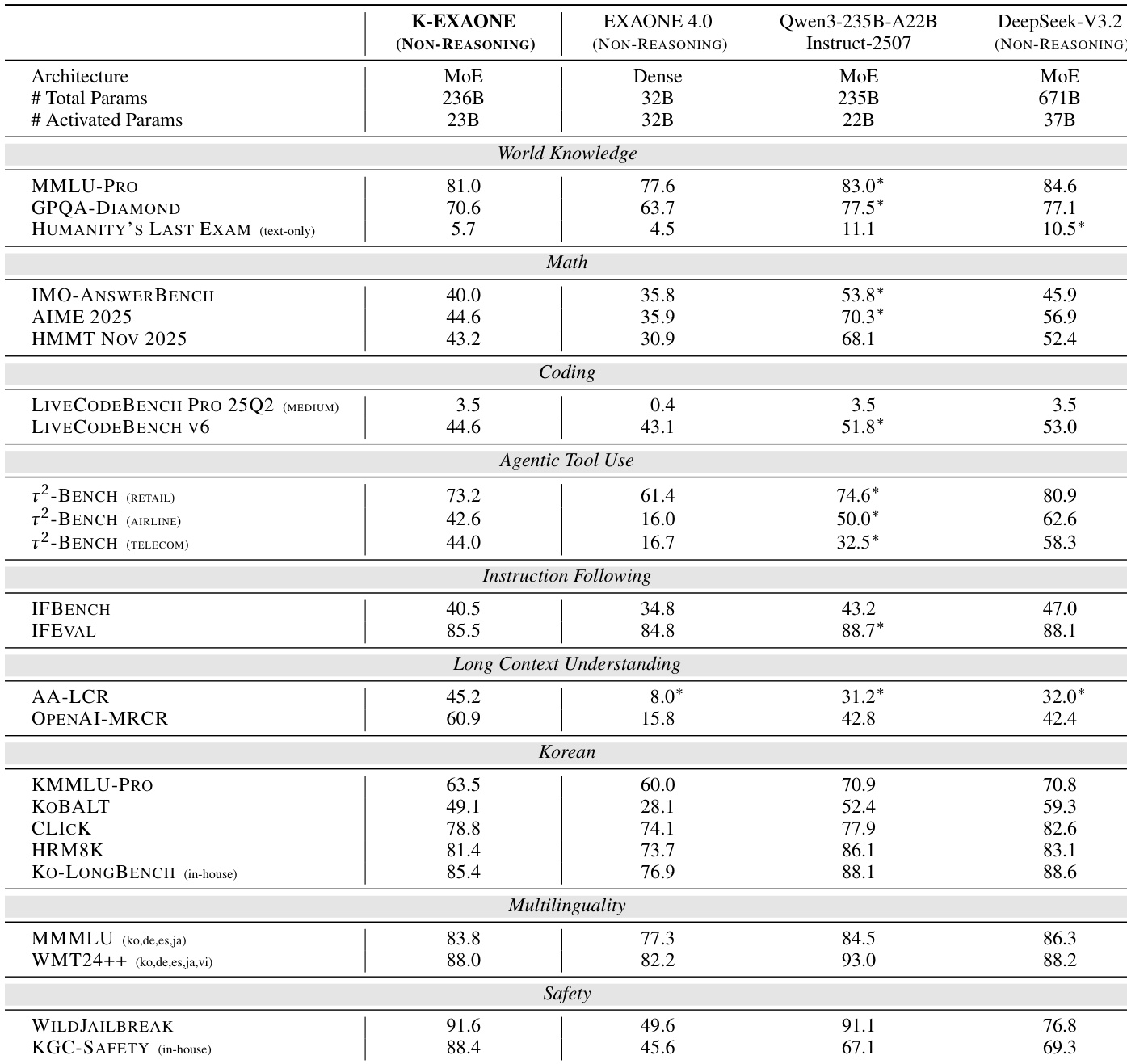
作者使用 K-EXAONE 的非推理模式评估其在多个领域中的性能,结果显示在世界知识、数学、编码与安全性基准上表现强劲。K-EXAONE 在与 Qwen3-235B-A22B-Instruct-2507 和 DeepSeek-V3.2 等更大模型的对比中表现具有竞争力,尤其在韩语基准与安全性评估中表现突出,同时以 230 亿激活参数维持高效参数使用。
作者使用 KGC-SAFETY 基准评估模型在多个维度上的安全性,包括通用人类价值观、社会安全、韩国敏感性与未来风险。结果显示,K-EXAONE 总分为 96.1,超越所有对比模型,尤其在通用人类价值观与社会安全方面表现卓越。

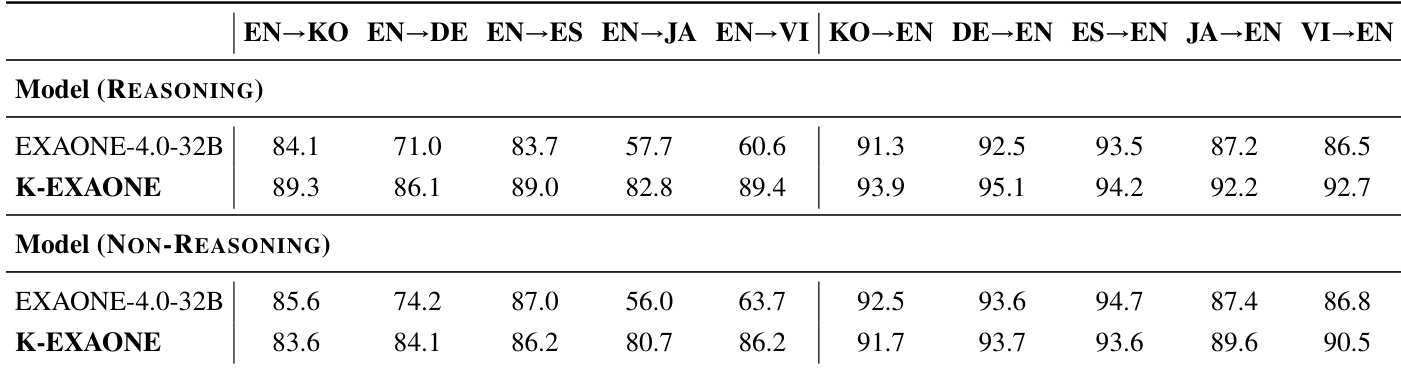
作者使用表格比较 K-EXAONE 与 EXAONE 4.0 在多种语言对上的多语言翻译性能。结果显示,K-EXAONE 在多数翻译方向上得分高于 EXAONE 4.0,尤其在 EN→KO、EN→DE、EN→ES、EN→JA、EN→VI 和 KO→EN 方向上表现更优,表明其多语言翻译质量显著提升。
作者使用表格展示 236B-A23B 模型的关键训练资源,表明其在 11 万亿令牌上进行预训练,计算需求达 1.52 × 10²⁴ FLOPs。该数据为模型规模与计算需求提供了背景参考。
