Command Palette
Search for a command to run...
MOSS 语音转写与说话人分离:支持说话人分离的精准语音转写
MOSS 语音转写与说话人分离:支持说话人分离的精准语音转写
摘要
说话人归属时间戳转录(Speaker-Attributed, Time-Stamped Transcription, SATS)旨在准确转录对话内容,并精确确定每位说话人的发言时间,这一能力在会议转录场景中尤为关键。现有SATS系统大多未采用端到端的建模方式,且受限于有限的上下文窗口、较弱的长程说话人记忆能力,以及无法输出时间戳等缺陷。为解决上述问题,我们提出MOSS Transcribe Diarize——一种统一的多模态大语言模型,能够在端到端框架下联合完成说话人归属与时间戳转录任务。该模型基于大规模真实场景数据训练,配备长达128K的上下文窗口,可支持长达90分钟的输入,具备良好的可扩展性与强泛化能力。在多项公开及内部基准测试中,MOSS Transcribe Diarize的表现均超越当前最先进的商用系统。
一句话总结
作者提出 MOSS Transcribe Diarize,这是一种具有 128k 上下文窗口的统一多模态大语言模型,能够实现端到端的说话人归属、时间戳转录,克服了以往在上下文长度和时间戳输出方面的限制。该模型通过利用大量真实世界数据和强大的长程说话人记忆,显著优于当前最先进的会议转录系统。
主要贡献
-
MOSS Transcribe Diarize 首次提出一种统一的多模态大语言模型,可在单次端到端流程中完成说话人归属、时间戳转录(SATS),通过联合建模语音识别、说话人归属和时间戳预测,无需中间传递,消除了易出错的模块化流水线。
-
模型采用 128k 标记的上下文窗口,可一次性处理长达 90 分钟的会议,显著增强长程说话人记忆、话语连贯性,并准确处理跨轮次引用和说话人一致性。
-
基于大量真实世界对话数据训练,MOSS Transcribe Diarize 在多个公开和内部基准测试中均优于当前最先进的商用系统,展现出在长时会议转录中更高的说话人归属准确率和时间精度。
引言
说话人归属、时间戳转录(SATS)在会议助手、客服中心分析和法律取证等应用中至关重要,因为知道谁在何时说了什么,与内容本身同等重要。以往系统通常依赖级联流水线,结合独立的自动语音识别(ASR)和说话人分离(diarization)模块,导致错误传播、长程说话人一致性差、上下文窗口有限,且无法原生输出精确时间戳。尽管近期已有混合或半端到端方法,但仍受限于长对话的可扩展性,存在分块伪影,缺乏稳健的长程记忆。本文提出 MOSS Transcribe Diarize,一种统一的多模态大语言模型,可在单次端到端流程中完成 SATS。其采用 128k 标记上下文窗口,无需分块即可处理长达 90 分钟的会议,实现强大的长程说话人记忆、连续话语建模和原生的段级时间戳输出。该方法消除了模块间不匹配,减少身份漂移,并在公开和内部基准测试中均优于当前最先进系统。
数据集

- 数据集包含真实和模拟的多语言音频,数据来源包括公开语料库、播客、电影及内部收集,旨在覆盖多样化的多说话人场景。
- 真实数据包括 AISHELL-4 测试集,包含来自会议室的长时、远场重叠录音;作者在训练和评估中均使用远场信号的平均通道。
- 另外构建了两个测试集:来自高质量 YouTube 采访的播客,配有字幕作为参考转录文本;电影数据集,包含中、英、韩、日、粤语的短时重叠音频片段,均经人工标注以获得高质量真实标签。
- 模拟数据通过概率模拟器生成,该模拟器随机选择 2–12 个说话人,将他们的语句分割为词序列,使用对数正态权重,并在时间轴上以高斯分布的间隔放置,以强制交替并允许重叠比例高达较短片段的 80%。
- 段落边界对齐至低能量点,并通过 50 ms 的交叉淡入淡出进行平滑处理,以提升听觉连续性。
- 混合音频还添加了真实世界噪声和混响,信噪比(SNR)在 0 到 15 dB 之间均匀采样。
- 模型使用真实与模拟数据的混合进行训练,训练划分基于精心筛选的真实与合成数据集。
- 评估时,模型在三个基准上测试:AISHELL-4(真实会议音频)、播客(多嘉宾访谈)和电影(重叠影视片段),性能通过归一化转录文本衡量。
- 所有系统统一应用输出归一化:移除括号内容、尖括号标签及非说话人方括号注释,仅保留说话人 ID(如 [S1])和纯文本,用于 CER/cpCER/Δcp 评分。
- 播客和电影测试集将在 Hugging Face 上公开发布,以支持未来研究。
方法
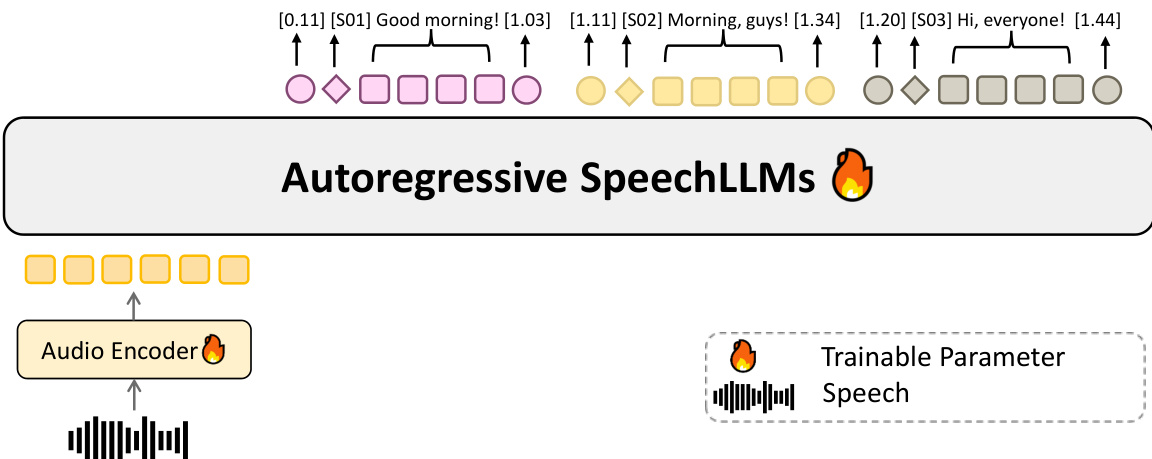
作者采用统一架构实现说话人归属、时间戳转录(SATS),将语音编码器与预训练文本大语言模型(LLM)的特征空间通过可学习投影进行融合。该框架支持在单次流程中端到端建模转录、说话人归属和时间戳预测,依托 128k 标记上下文窗口。模型通过音频编码器处理输入音频,提取声学嵌入。这些嵌入随后通过可训练的投影模块映射到预训练文本 LLM 的特征空间,使 LLM 能够联合对齐说话人身份与词汇内容。
如图所示,系统以分块方式处理音频,时间信息以格式化的时间戳文本显式插入编码器输出之间。该方法避免依赖随时间推移性能下降的绝对位置索引,从而实现对小时级音频的精确时间戳生成,同时保持说话人归属的稳定性。模型在多样化的野外对话和具备属性感知的模拟混合数据上训练,涵盖重叠、轮流发言和声学变化,增强了在真实场景中的鲁棒性。
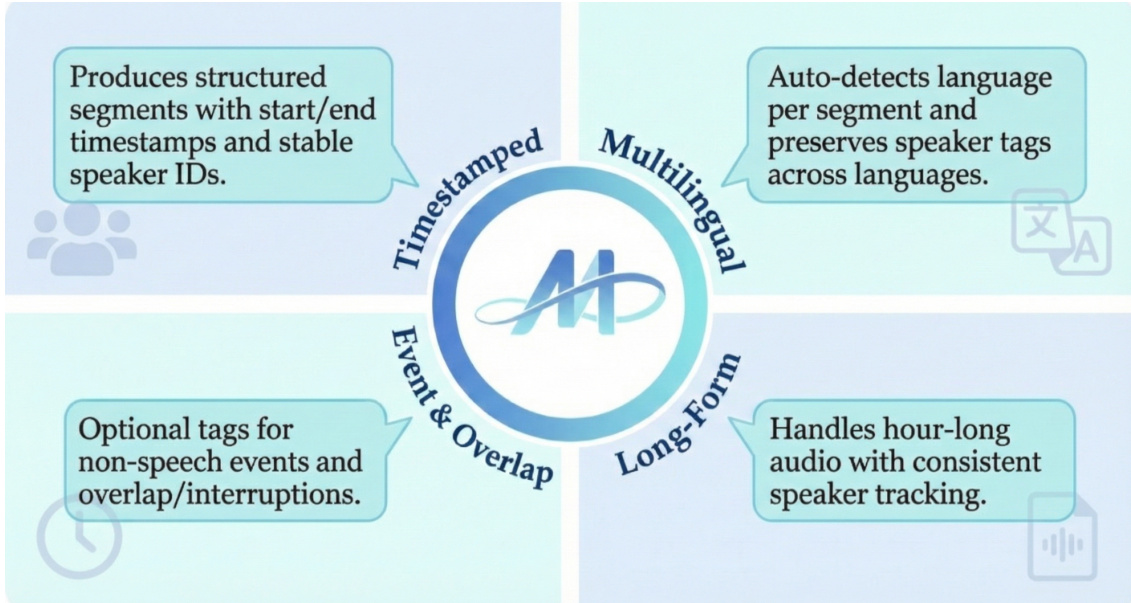
该框架生成带有起止时间戳和稳定说话人 ID 的结构化段落,如图所示。支持多语言输入,可自动检测每段语言,并在不同语言间保留说话人标签。模型还能处理长达一小时的音频,实现一致的说话人追踪,并支持可选的非语音事件标签及重叠/打断标记,实现对完整事件和重叠的全面建模。
实验
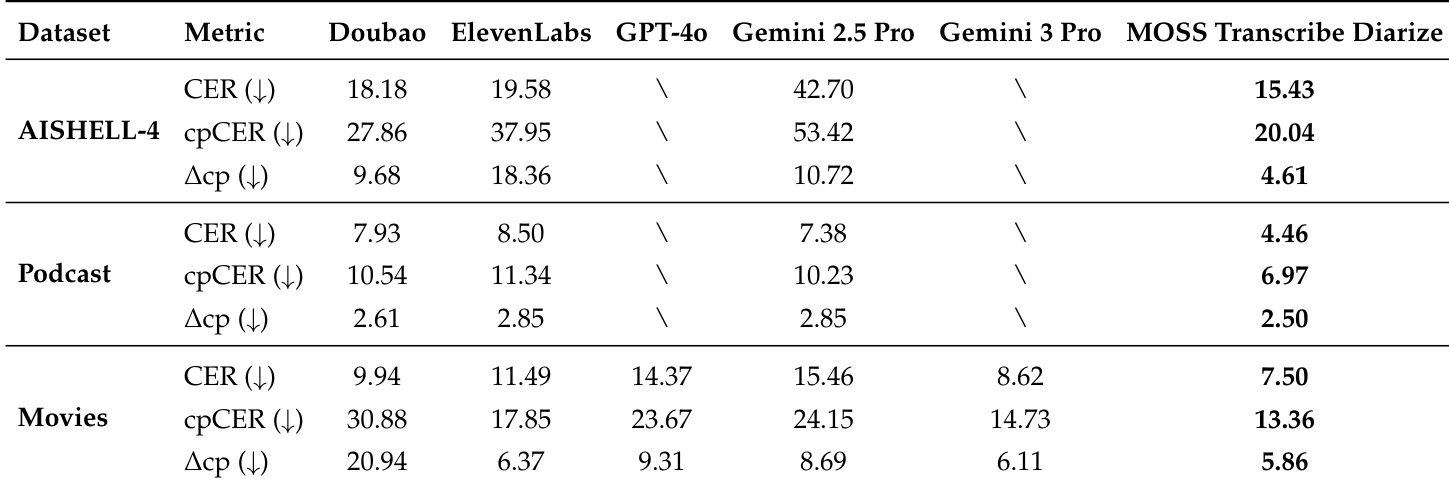
- 在 AISHELL-4、播客和电影基准上使用 CER、cpCER 和 Δcp 指标评估语音识别、说话人分离及联合性能。
- 在 AISHELL-4 上,达到最低的 cpCER 和 Δcp,优于包括 GPT-4o 和 Gemini 3 Pro 在内的闭源模型,后者因长度限制或输出格式问题在长时输入上失败。
- 在播客测试中,取得最佳 cpCER 和最小 Δcp,表明在频繁换人、长时多说话人讨论中具有更优的说话人归属能力。
- 在电影测试中,尽管语句短、重叠度高,仍超越所有基线模型的 cpCER 和 Δcp,表明其具备鲁棒的说话人边界检测能力。
- 各数据集上一致的低 Δcp 表明,说话人归属错误对整体性能下降贡献极小,验证了端到端、长上下文建模的有效性。
作者通过表格为实验所用数据集提供背景信息,显示 AISHELL-4 测试集包含时长约 2290 秒的长时会议录音,有 5–7 个说话人;播客包含更长的对话,最多 11 个说话人,平均时长 2658 秒;电影数据集包含短时、高重叠片段,最长 29.888 秒,说话人数量 1–6 个。这些特征与实验结果一致:MOSS Transcribe Diarize 在长时和复杂对话数据上表现最佳,展现出对不同音频长度和说话人数量的鲁棒性。

结果表明,MOSS Transcribe Diarize 在所有数据集上均达到最低的 cpCER 和 Δcp,表明其在语音识别与说话人归属联合性能上更优。在 AISHELL-4 上,其在 CER 和 cpCER 上均显著优于所有基线,Δcp 显著更小,表明在长对话中说话人归属更可靠。在播客和电影测试中,再次在 cpCER 和 Δcp 上取得最佳表现,凸显其在长时与短时对话场景下的鲁棒性。