Command Palette
Search for a command to run...
DreamID-V:通过扩散Transformer弥合图像到视频的鸿沟实现高保真人脸替换
DreamID-V:通过扩散Transformer弥合图像到视频的鸿沟实现高保真人脸替换
Xu Guo Fulong Ye Xinghui Li Pengqi Tu Pengze Zhang Qichao Sun Songtao Zhao Xiangwang Hou Qian He
摘要
视频人脸替换(Video Face Swapping, VFS)旨在将源身份无缝注入目标视频的同时,精确保留原始的姿态、表情、光照、背景及动态信息。现有方法在保持身份相似性与属性一致性的同时,难以有效维持时序一致性。为解决这一挑战,我们提出一个全面的框架,旨在将图像人脸替换(Image Face Swapping, IFS)的优势无缝迁移至视频领域。首先,我们设计了一种新颖的数据处理流程 SyncID-Pipe,用于预训练一个身份锚定的视频合成器,并将其与现有的 IFS 模型结合,构建双向身份四元组(bidirectional ID quadruplets),以实现显式的监督学习。基于该配对数据,我们提出了首个基于扩散变换器(Diffusion Transformer)的框架 DreamID-V,其核心为一种模态感知条件注入模块(Modality-Aware Conditioning module),能够差异化地融合多模态条件信息。同时,我们引入了“合成到真实”课程学习机制(Synthetic-to-Real Curriculum)以及身份一致性强化学习策略(Identity-Coherence Reinforcement Learning),显著提升在复杂场景下的视觉真实感与身份一致性。为应对现有基准数据集有限的问题,我们构建了 IDBench-V——一个涵盖多样化场景的综合性基准测试平台。大量实验表明,DreamID-V 在性能上显著超越当前最先进方法,并展现出卓越的泛化能力,可无缝适配多种人脸替换相关任务。
一句话摘要
清华大学与字节跳动智能创作实验室的徐果、叶福龙等提出 DreamID-V,一种基于扩散 Transformer 的视频人脸交换框架,采用模态感知条件注入与身份一致性强化学习机制,通过弥合图像人脸交换技术与时间一致性之间的差距,实现了高保真视频人脸交换,在多样化的现实场景下超越了先前方法在 IDBench-V 上的表现。
主要贡献
- 视频人脸交换(VFS)在保持身份相似性、属性保真度和时间一致性方面面临挑战,尤其是在直接逐帧应用图像人脸交换(IFS)方法时,容易产生闪烁和抖动伪影。
- 作者提出 DreamID-V,首个基于扩散 Transformer 的 VFS 框架,配备模态感知条件注入模块,实现判别性多模态条件注入,支持高保真身份迁移与连贯的面部动态。
- 提出一种新颖的数据流水线 SyncID-Pipe,利用身份锚定视频合成器与 IFS 模型构建双向身份四元组,结合合成到真实课程学习与身份一致性强化学习,提升真实感与鲁棒性,并在新提出的 IDBench-V 基准上进行验证。
引言
视频中的人脸交换(VFS)在娱乐、创意设计和数字身份等领域具有重要意义,但其在维持时间上身份连续性、姿态一致性与环境保真度方面面临重大挑战——这些问题在基于图像的人脸交换(IFS)中并不显著。尽管 IFS 方法在身份与属性保真度方面表现优异,但直接逐帧应用于视频会导致因缺乏时间一致性而产生闪烁与抖动。现有基于扩散的 VFS 方法虽提升了时间一致性,但在身份保留与属性准确性方面仍落后于 IFS,主要由于监督不足以及对动态面部运动建模较弱。作者提出 DreamID-V,一种基于扩散 Transformer(DiT)的新型视频人脸交换框架,通过三项创新弥合 IFS 与 VFS 之间的差距:一个名为 SyncID-Pipe 的数据流水线,利用 IFS 模型通过身份锚定视频合成器生成高质量、时间一致的视频数据;一种模态感知条件注入机制,实现有效的多模态条件注入;以及一种身份一致性强化学习策略,提升复杂运动下的鲁棒性。为支持严谨评估,作者引入 IDBench-V,一个涵盖多样姿态、表情与光照条件的综合性基准。该框架在身份相似性与时间一致性方面均达到最先进水平,显著优于先前方法,并在各类交换任务中展现出强大适应性。
数据集
- 数据集 IDBench-V 包含 200 组真实世界源视频–目标图像对,旨在评估在具有挑战性的现实条件下的人脸交换性能。
- 源视频覆盖多种复杂场景,如小尺寸人脸、极端头部姿态、严重遮挡、复杂动态表情以及多人杂乱场景。
- 目标图像经过精心挑选,以匹配源视频中的人脸身份,确保评估所用的成对数据。
- 训练集源自 OpenHumanVid,通过基于身份相似性的额外筛选,构建一致的源-目标配对。
- 该基准用于评估基于图像与基于视频的人脸交换方法,并与 SOTA 模型如 FSGAN、REFace、Face-Adapter、DreamID、Stand-In 和 CanonSwap 进行对比。
- 评估涵盖三个主要维度:身份一致性(使用 ArcFace、InsightFace 和 CurricularFace,结合帧级相似性方差)、属性保真度(姿态与表情保真度)以及视频质量(通过 ResNext 计算的 Fréchet 视频距离,FVD)。
- 还采用 VBench 提供的额外指标:背景一致性、主体一致性与运动平滑性,以评估时空一致性。
- 未进行显式裁剪,直接使用原始视频帧与目标图像,通过构建元数据确保身份对齐与场景分类。
方法
作者提出 DreamID-V,一种基于扩散的视频人脸交换(VFS)框架,利用扩散 Transformer(DiT)架构实现高保真身份迁移,同时保持时间一致性与动态属性。整体框架基于一种新颖的数据整理流水线 SyncID-Pipe,该流水线生成双向身份四元组,弥合图像与视频人脸交换之间的差距。该流水线首先使用身份锚定视频合成器(IVS)在源身份与姿态序列条件下重建目标视频。IVS 在大规模人像数据集上通过重建目标进行训练,其中第一-最后一帧视频基础模型(FLF2V)以人像视频的首尾帧及其提取的姿态序列为条件。为有效注入运动信息,作者引入自适应姿态注意力机制,使用轻量级姿态引导器提取姿态特征,并将其与 DiT 的潜在特征对齐。该机制通过可训练的线性层将姿态特征投影至注意力空间,采用改进的注意力公式,结合标准自注意力与姿态条件注意力,实现与噪声潜在视频的精确时空对齐。
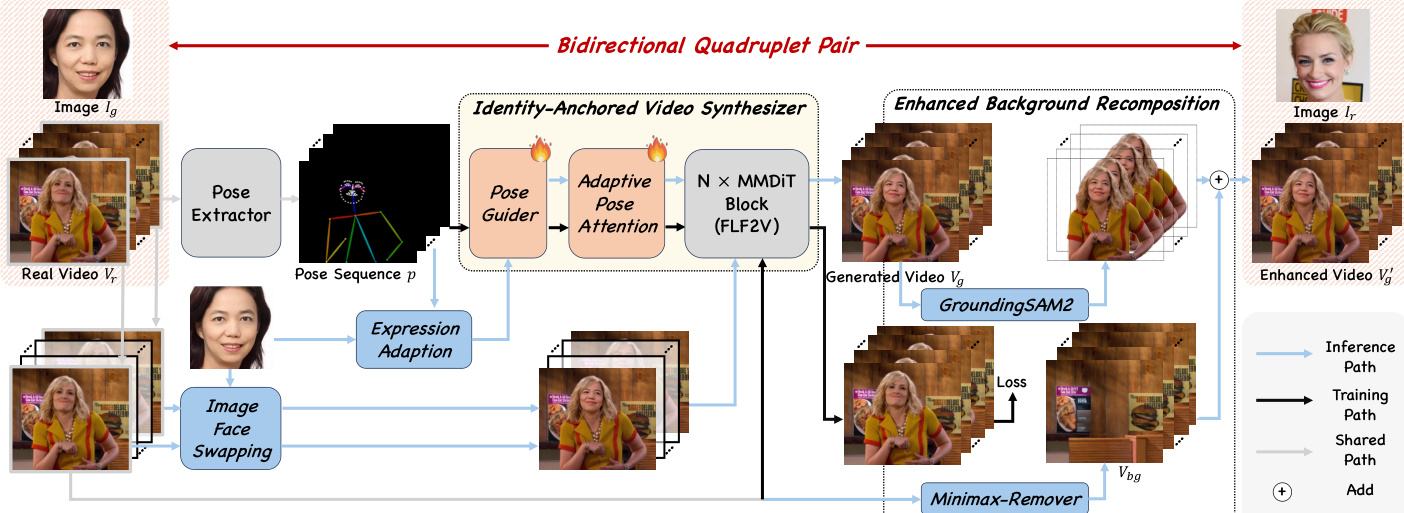
如图所示,DreamID-V 框架的核心是模态感知条件(MC)模块,支持多条件的判别性注入。该模块将输入条件分解为三种不同类型:时空上下文、结构引导与身份信息。时空上下文模块注入参考视频与扩张人脸掩码,与潜在源视频在通道维度拼接,提供背景与光照保真的精确上下文信息。结构引导模块以姿态序列为结构线索,利用预训练的自适应姿态注意力机制控制运动属性,保留精细表情而不破坏高层特征。相比之下,身份信息模块将目标身份视为高层语义特征,通过专用 ID 编码器将其编码为嵌入向量,并沿 token 维度与潜在特征拼接,使身份信息通过 DiT 的注意力机制实现完全交互。
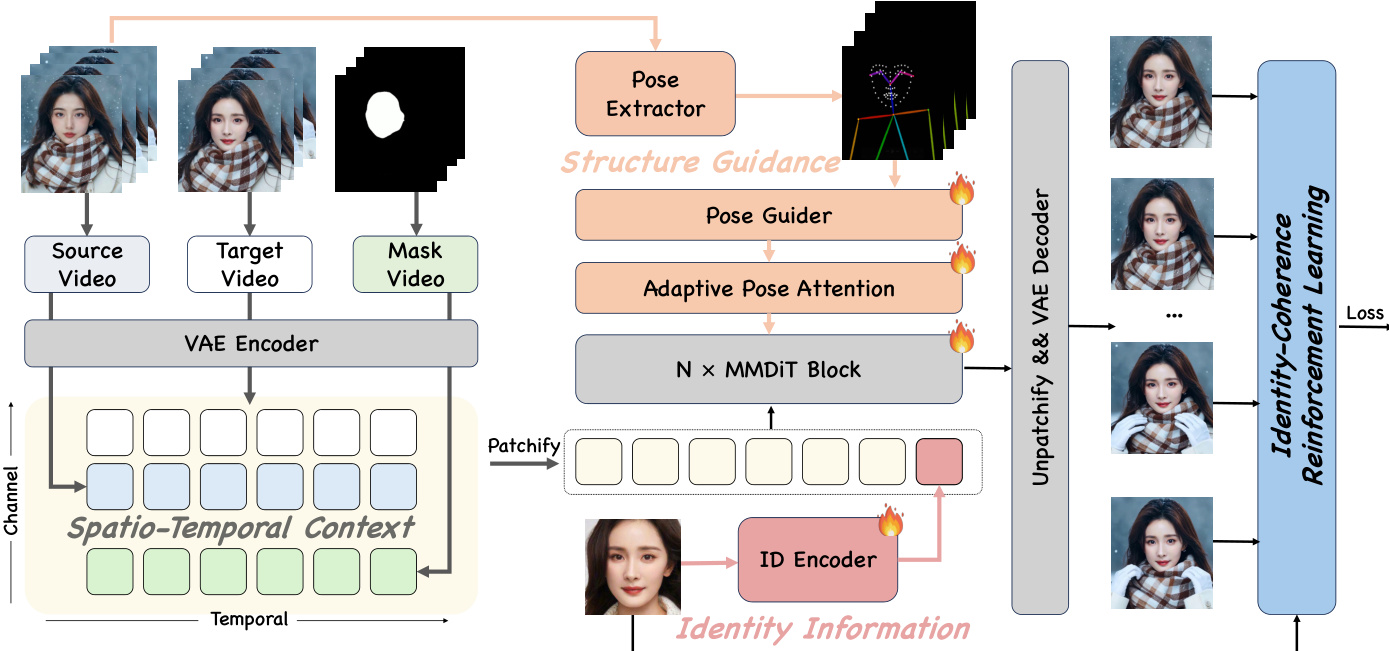
为增强视觉真实感与身份一致性,训练过程引入合成到真实课程学习与身份一致性强化学习(IRL)策略。训练从合成阶段开始,模型在前向生成的成对数据上训练,以实现高身份相似性。随后进入真实增强阶段,使用反向真实成对数据并结合增强背景重构模块对模型进行微调。该模块利用前景掩码与 MinimaxRemover 从真实视频中提取干净背景,并与生成视频的前景结合,生成更真实且一致的输出。最后,IRL 机制通过动态重加权损失来解决时间身份一致性问题。具体而言,定义 Q 值为生成帧与目标身份之间余弦相似度的倒数,并用于加权流匹配损失,从而引导模型在困难帧中更专注于优化身份保真度。
实验
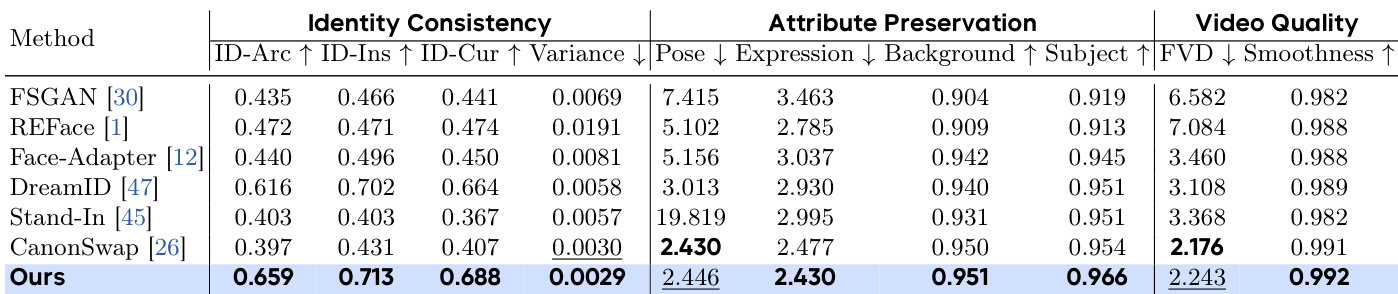
- 在 IDBench 上的定量比较显示,DreamID-V 在所有指标上均取得最高分,超越了包括 CanonSwap、Face-Adapter、DreamID 和 Stand-In 在内的最先进模型。在包含 19 名评估者的 IDBench 用户研究中,DreamID-V 在身份一致性、属性保真度与视频质量三个维度上均获得最高平均分(1–5 分制)。
- 图 4 的定性分析表明,DreamID-V 在身份相似性、表情保真、背景一致性以及遮挡与复杂表情下的鲁棒性方面表现卓越,显著优于 Face-Adapter、Stand-In、CanonSwap 和 DreamID。
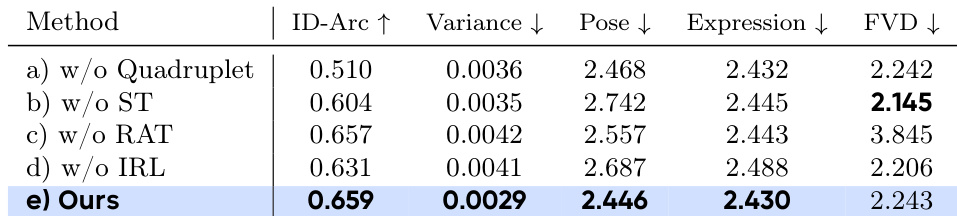
- 表 3 与图 5 的消融研究证实了各组件的有效性:SyncID-Pipe 通过连接 VFS 与 IFS 领域实现高身份相似性;Sync-to-Real 训练策略在真实感与身份保真之间取得平衡;身份一致性强化学习(IRL)阶段显著提升身份相似性,尤其在侧脸视角与复杂运动下,同时降低帧间方差。
- 模型展现出强大泛化能力,通过扩展训练数据成功应用于配饰、服装、耳机与发型交换,如图 6 所示。
- 图 9 的 T-SNE 可视化结果表明,IVS 模块生成的合成视频在分布上与 DiT 模型的潜在空间对齐,使得在合成数据上训练时收敛更快,性能更优。
实验结果表明,消融研究验证了 DreamID-V 中各组件的有效性。完整模型(e)在 ID-Arc 指标上达到最高分 0.659,方差最低为 0.0029,表明其具有卓越的身份相似性与时间一致性。其在姿态与表情保真度方面也表现优异,FVD 分数与最佳变体相当,凸显了身份一致性强化学习阶段在复杂运动下维持高身份相似性的重要性。
实验结果表明,DreamID-V 在所有指标上均达到最高身份一致性,ID-Arc、ID-Ins 与 ID-Cur 分数最优,方差最低,表明其具有强时间稳定性。在属性保真度与视频质量方面,DreamID-V 优于所有对比方法,尤其在姿态与表情保真度方面表现突出,同时保持高平滑性与低 FVD。
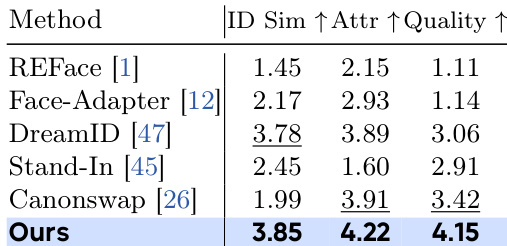
实验结果表明,DreamID-V 在所有评估指标上均取得最高分,身份相似性得分为 3.85,属性保真度为 4.22,视频质量为 4.15,全面超越所有对比方法。作者通过合成到真实训练与身份一致性强化学习相结合,实现了高身份相似性与鲁棒的属性保真,同时保持了逼真的视频质量。