Command Palette
Search for a command to run...
Avatar Forcing:面向自然对话的实时交互式头部虚拟形象生成
Avatar Forcing:面向自然对话的实时交互式头部虚拟形象生成
Taekyung Ki Sangwon Jang Jaehyeong Jo Jaehong Yoon Sung Ju Hwang
摘要
说话头生成技术能够从静态肖像图生成逼真的虚拟形象,广泛应用于虚拟通信与内容创作。然而,当前模型尚无法真正体现互动交流的沉浸感,通常仅能生成单向响应,缺乏情感参与度。我们识别出实现真正交互式虚拟形象的两大关键挑战:在因果约束下实现实时动作生成,以及在无需额外标注数据的前提下学习富有表现力、生动自然的反应行为。为应对这些挑战,我们提出一种名为“Avatar Forcing”的新框架,通过扩散强制机制建模实时用户-虚拟形象交互。该设计使虚拟形象能够低延迟地处理实时多模态输入,包括用户的语音与动作信号,从而对言语和非言语线索(如说话、点头、笑声)做出即时响应。此外,我们引入一种直接偏好优化方法,利用通过剔除用户条件构造的合成负样本,实现无需标注数据的表达性交互学习。实验结果表明,该框架支持低延迟的实时交互(延迟约500毫秒),相较基线模型实现6.8倍的加速,同时生成更具反应性与表现力的虚拟形象动作,在用户偏好测试中优于基线模型超过80%。
一句话总结
韩国科学技术院(KAIST)、新加坡南洋理工大学(NTU)与DeepAuto.ai的作者提出Avatar Forcing,一种基于扩散模型的框架,能够实现低延迟(约500ms)的实时、富有表现力的交互式头部虚拟形象,对多模态用户输入(音频与动作)做出响应,相比基线模型提速6.8倍。该框架通过一种新颖的无标签偏好优化方法,利用合成的条件丢弃样本进行训练,使虚拟形象在无需标注数据的情况下学习到生动且情绪响应性强的行为,显著提升了虚拟交流中的参与度。
主要贡献
- 现有说话头生成模型难以实现真正交互式沟通,通常生成单向、非响应式的虚拟形象,因高延迟及对双向语言与非语言线索建模不足,缺乏情感互动性。
- 所提出的Avatar Forcing框架通过采用因果扩散强制与键值缓存机制,实现低延迟(≈500ms)的实时交互,能够对实时多模态输入(如音频与用户动作)生成富有表现力的虚拟形象动作。
- 提出一种新颖的无标签偏好优化方法,通过合成“条件丢失”样本(即人为丢弃用户条件)来训练富有表现力、具响应性的虚拟形象行为,使人类偏好度相比基线提升80%,推理速度提升6.8倍。
引言
作者致力于解决自然对话中创建真正交互式头部虚拟形象的挑战,要求虚拟形象能实时响应用户的语言与非语言线索(如语音、笑声、头部动作),同时保持生动逼真的动作表现。以往的说话头生成研究多聚焦于音频驱动的口型同步或单向响应生成,缺乏双向交互能力,且因依赖未来上下文而存在高延迟问题。此外,诸如点头或共情表情等富有表现力的倾听行为,由于缺乏标注数据而难以学习,导致虚拟形象僵硬、反应迟钝。为克服这些局限,作者提出Avatar Forcing,一种基于扩散强制的框架,通过低延迟处理多模态输入(音频与动作),实现因果性、实时生成,达到约500ms响应时间,推理速度比基线快6.8倍。其核心创新在于一种无标签偏好优化方法,通过丢弃用户条件合成表现力不足的样本,使模型在无需人工标注的情况下学习更丰富、更具响应性的行为。这使得虚拟形象不仅能够即时响应,还能展现出自然、吸引人的表情,相比基线在人类评估中高出80%。
数据集
- 数据集包含来自RealTalk [16] 和 ViCo [67] 的双人对话视频,选取标准为自然、互动性强的说话者-倾听者动态。
- 视频通过PySceneDetect [44] 检测场景变化后分割为独立片段,便于聚焦分析。
- 使用Face-Alignment [4] 检测并追踪每个面部,随后裁剪并缩放至512×512像素,以统一视觉输入。
- 采用基于视觉的语音分离模型 [30] 分离说话者与倾听者音频,利用视觉线索实现准确的音频分配。
- 所有视频内容统一转换为25帧/秒,音频重采样至16 kHz,确保时间与频谱对齐。
- 从HDTF [66] 数据集中随机选取50个视频用于说话头生成性能评估。
- 训练过程中混合使用RealTalk与ViCo子集,各子集按预设比例贡献于整体训练集。
- 预处理阶段构建元数据,关联说话者与倾听者角色、片段边界及音视频对齐信息,支持交互式虚拟形象生成。
- 除以面部为中心的512×512裁剪外,不进行其他显式裁剪,所有处理均旨在保留自然对话语境与视觉保真度。
方法
作者采用扩散强制作为实时交互式头部虚拟形象生成的核心生成机制,运行于动作潜在空间中。整体框架如图所示,包含两个主要阶段:多模态用户与虚拟形象信号的编码,以及动作的因果推理。动作潜在自编码器(如附图所示)将输入图像 S 映射为潜在变量 z,该变量可显式分解为身份潜在变量 zS 与动作潜在变量 mS。这种分解使模型能够捕捉整体头部动作与细微面部表情,这对真实感虚拟形象生成至关重要。动作生成过程被建模为自回归模型,其中每个动作潜在变量 mi 的预测均基于历史动作潜在变量与一个包含用户音频 aui、用户动作 mui 与虚拟形象音频 ai 的条件三元组 ci。
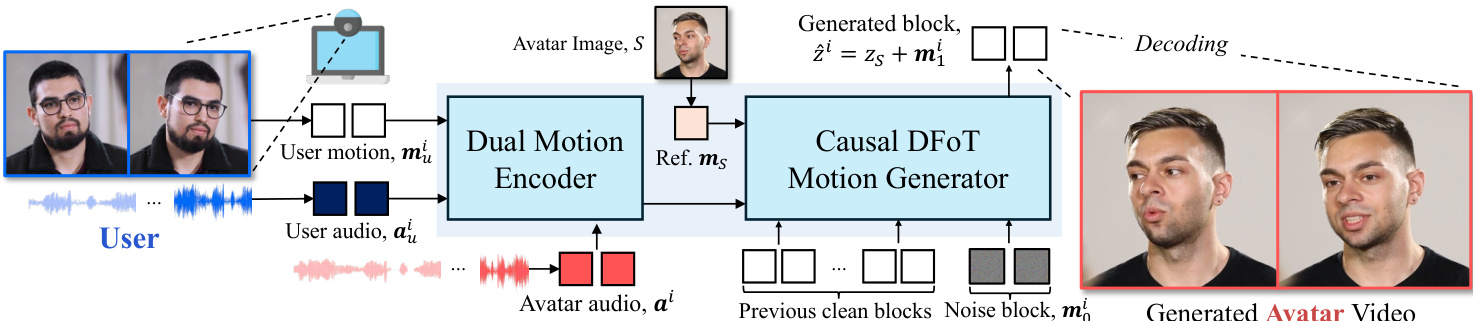
动作生成的核心是一个基于扩散强制的因果动作生成器,建模为向量场 vθ。如图所示,该模型由两个主要组件构成:双动作编码器(Dual Motion Encoder)与因果DFoT动作生成器(Causal DFoT Motion Generator)。双动作编码器首先通过交叉注意力层处理用户动作 mui 与用户音频 aui,以捕捉用户整体动作。该表示随后通过另一交叉注意力层与虚拟形象音频 ai 融合,学习用户与虚拟形象之间的因果关系,生成统一的条件表示。因果DFoT动作生成器(如图所示)在动作潜在空间中采用分块因果结构运行。潜在帧被划分为多个块,以捕捉块内局部双向依赖,同时保持块间因果依赖。每个块应用共享的噪声时间步,并使用注意力掩码防止当前块访问任何未来块,从而在因果约束下实现逐步动作生成。
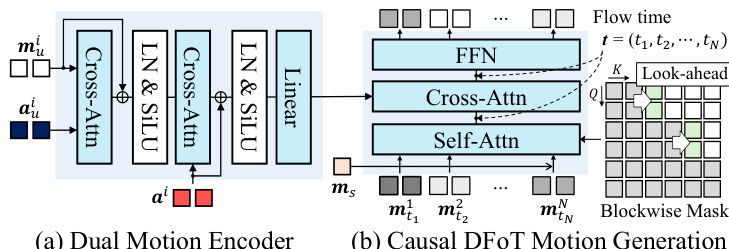
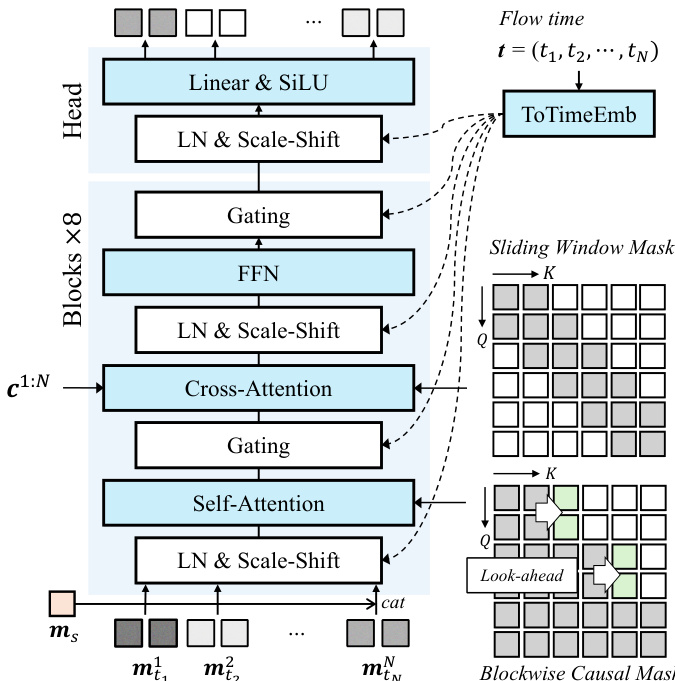
为解决严格因果掩码导致的时间抖动问题,作者在因果掩码中引入前瞻机制。该机制允许每个块有限地访问未来帧,确保块间过渡平滑,同时保持整体因果性。分块前瞻因果掩码 M 定义为:若 ∣j/B∣≤∣i/B∣+l,则帧 i 可以访问帧 j,其中 B 为块大小,l 为前瞻帧数。模型 vθ 通过扩散强制目标进行训练,该目标将向量场 vθ 回归至目标向量场 (m1n−m0n),其中 m0n 为干净动作潜在变量,m1n 为噪声动作潜在变量。推理阶段,模型以分块方式生成动作潜在变量,利用滚动键值(KV)缓存维持上下文,实现低延迟实时交互。下图详细展示了因果DFoT动作生成器的架构,其由八个DFoT Transformer块后接一个Transformer头构成。每个DFoT块通过共享的AdaLN缩放-偏移系数层,根据流时间 t 调制噪声潜在变量。注意力模块使用分块因果前瞻掩码进行自注意力,并采用滑动窗口注意力掩码将驱动信号 c1:N 与噪声潜在变量对齐。
实验
- 在延迟、响应性、动作丰富度、视觉质量、唇部同步等方面评估交互式虚拟形象生成,采用rPCC、SID、Var、FID、FVD、CSIM、LSE-D、LSE-C等指标。
- 在RealTalk数据集上,Avatar Forcing实现0.5秒延迟,响应性与动作丰富度优于INFP*,视觉质量与唇部同步保持相当,支持实时交互。
- 22名参与者的主观偏好研究显示,Avatar Forcing在所有指标上偏好度超过80%,尤其在响应性、动作丰富度与非语言对齐方面表现突出。
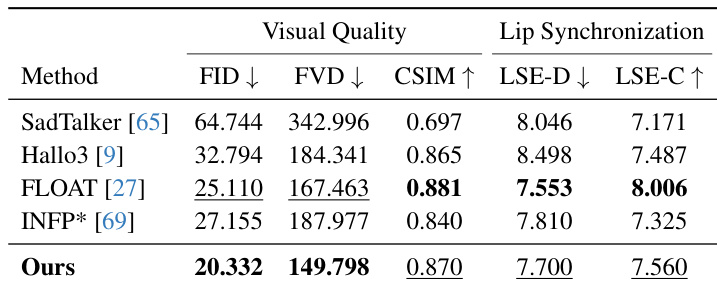
- 在HDTF数据集上,Avatar Forcing在图像与视频质量(FID、FVD)方面表现优异,唇部同步(LSE-D、LSE-C)强于SadTalker、Hallo3、FLOAT与INFP*。
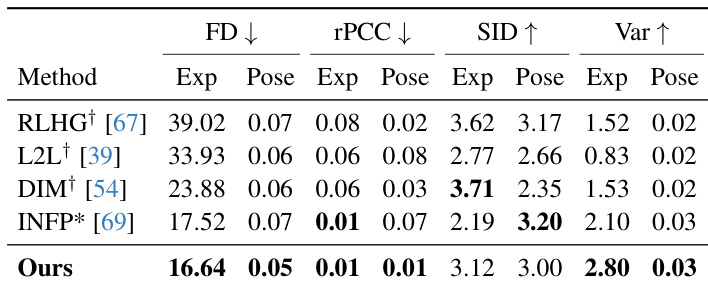
- 在ViCo数据集上,Avatar Forcing在用户-虚拟形象动作同步(rPCC)、表情与姿态多样性(SID、Var)及分布相似性(FD)方面优于倾听头虚拟形象模型(RLHG、L2L、DIM、INFP*)。
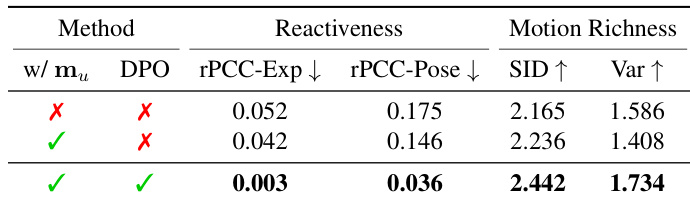
- 消融实验表明,用户动作输入对响应性与表现力至关重要,移除后在无声音频下表现为静态行为。
- 通过DPO进行偏好优化显著提升rPCC、SID与Var,使虚拟形象动作更具表现力与响应性,经由定量指标与定性可视化双重验证。
作者通过消融实验评估用户动作输入与偏好优化对虚拟形象生成的影响。结果表明,同时包含用户动作输入与偏好优化可显著提升响应性与动作丰富度,当两者均存在时性能最佳。
结果表明,所提模型实现最低延迟0.5秒,显著优于基线在响应性与动作丰富度方面的表现,同时保持竞争力的视觉质量与唇部同步。模型在响应性与动作丰富度指标上的卓越表现,表明其相比现有方法具有更富表现力与同步性的虚拟形象行为。

结果表明,所提方法在视觉质量方面表现更优,表现为更低的FID与FVD分数,且身份保留能力更强(CSIM值更高),优于SadTalker、Hallo3、FLOAT与INFP*。模型还保持了竞争力的唇部同步性能,LSE-D分数更低,LSE-C分数更高,表明生成的唇部动作与音频对齐效果良好。
结果表明,所提模型在响应性、动作丰富度、语言对齐、非语言对齐及整体偏好方面均优于基线INFP*与Tie。模型在生成富有表现力且同步的虚拟形象动作方面表现卓越,用户-虚拟形象交互指标显著提升。

结果表明,所提模型在所有指标上均优于基线,Frechet距离(FD)最低(表达与姿态),多样性相似性指数(SID)最高,表达与姿态方差(Var)最高。模型在动作同步性方面表现更优,表达与姿态的残差皮尔逊相关系数(rPCC)最低,表明虚拟形象动作更具响应性与表现力。