Command Palette
Search for a command to run...
ShowUI-π:基于流的生成模型作为GUI灵巧手
ShowUI-π:基于流的生成模型作为GUI灵巧手
Siyuan Hu Kevin Qinghong Lin Mike Zheng Shou
摘要
构建具备灵巧操作能力的智能代理,对于实现机器人系统及数字环境中的类人自动化至关重要。然而,现有图形用户界面(GUI)代理普遍依赖离散的点击预测(x, y坐标),难以支持自由形态、闭环式的连续轨迹操作(例如拖动进度条),这类操作需要实时感知与动态调整能力。本文提出 ShowUI-π,首个基于流模型的生成式GUI灵巧操作代理,其核心设计包括:(i)统一的离散-连续动作建模,将离散点击与连续拖拽整合于同一模型框架中,实现对多种交互模式的灵活适应;(ii)基于流模型的动作生成机制,通过轻量级动作专家从连续视觉观测中预测光标增量调整,确保拖拽轨迹的平滑性与稳定性;(iii)拖拽训练数据集与基准评测体系,我们人工收集并合成涵盖五大领域(如 PowerPoint、Adobe Premiere Pro)的 20,000 条拖拽轨迹,并构建 ScreenDrag 基准,提供全面的在线与离线评估协议,用于系统评估 GUI 代理的拖拽能力。实验结果表明,现有专有 GUI 代理在 ScreenDrag 基准上仍表现不佳(例如 Operator 得分为 13.27,最优的 Gemini-2.5-CUA 仅达 22.18),而 ShowUI-π 仅使用 450M 参数即取得 26.98 的得分,充分体现了该任务的挑战性以及我们方法的有效性。我们期望本工作能推动 GUI 代理向数字世界中类人级的灵巧控制迈进。代码已开源,地址为:https://github.com/showlab/showui-pi。
一句话总结
新加坡国立大学Show Lab的作者提出ShowUI-π,一种轻量级基于流的生成模型,通过增量视觉观测联合建模离散点击与连续拖拽动作,实现类人的精细GUI自动化,在新的ScreenDrag基准上以仅4.5亿参数取得26.98分,超越先前代理。
主要贡献
- 现有GUI代理依赖离散点击预测,限制其执行连续、闭环交互(如拖拽)的能力;ShowUI-π通过引入统一框架,将离散点击与连续拖拽均建模为单一基于流的生成模型中的(x, y, m)三元组序列,解决了该问题。
- 该模型采用轻量级动作专家,通过流匹配训练,从流式视觉观测中生成增量光标调整,实现复杂任务(如旋转验证码、专业软件中的精确缩放)的平滑稳定轨迹生成。
- 为评估连续GUI操作,作者提出ScreenDrag基准,包含505个真实世界拖拽任务(覆盖五个领域)和2万条合成轨迹,结果显示ShowUI-π在该基准上取得26.98分,尽管参数量仅450M,仍优于Gemini-2.5-CUA等专有代理(22.18分)。
引言
作者致力于解决GUI自动化代理执行连续精细交互(如拖拽、绘图、旋转验证码)的挑战,这些任务需要实时视觉反馈和精细轨迹控制。以往工作依赖视觉语言模型输出的离散、分词化动作表示,无法捕捉拖拽的连续特性,导致代理仅能执行粗粒度、分步动作。为此,作者提出ShowUI-π,首个用于GUI自动化的基于流的生成模型,将点击与拖拽统一建模为(x,y,m)动作空间中的连续轨迹。通过在轻量级Transformer骨干网络上应用流匹配,ShowUI-π可从流式视觉观测中生成平滑、实时的光标移动。作者引入ScreenDrag基准,包含505个真实世界拖拽任务(五个领域)和2万条密集轨迹标注,支持离线误差度量与在线成功评估。实验表明,ShowUI-π仅用4.5亿参数即达到最先进性能,显著超越现有专有代理,验证了连续轨迹建模在实现类人GUI灵巧性方面的有效性。
数据集

- 数据集ScreenDrag包含跨五个领域(PowerPoint、操作系统桌面与文件管理器、手写、Adobe Premiere Pro、验证码求解)的2万条拖拽轨迹,涵盖日常与专业级任务,均需精确空间控制。
- 数据通过可扩展流水线收集,结合自动化执行与人工示范。自动化数据生成分为三阶段:(i) 使用Windows UI自动化(UIA)或DOM解析元素,(ii) 通过Qwen-2.5-72B大语言模型生成指令,(iii) 使用PyAutoGUI代码在真实系统上执行并合成轨迹。
- 人工示范以60 FPS高分辨率屏幕录制,包含密集光标轨迹与对应任务指令,确保时空保真度。
- PowerPoint任务使用微软官方模板,通过UIA解析并生成旋转、缩放等任务;旋转手柄位置通过启发式方法估算。
- 手写数据使用开源库合成,文本由Qwen-2.5-72B生成,笔画通过Win32鼠标接口渲染以实现精细控制。
- 验证码任务通过修改Go-Captcha库收集,暴露实时元数据(如拼图块位置、成功状态),可筛选仅成功解决的轨迹。
- Adobe Premiere Pro数据通过人工专家示范收集,因UI元数据不可完全访问;两名经验丰富的标注员执行真实编辑任务,如剪辑、图层调整与特效应用。
- 操作系统桌面与文件管理器任务通过修改Windows注册表设置禁用自动排列,提升任务复杂度;使用UIA提取图标与控件的边界框。
- 所有数据使用OBS进行低延迟屏幕录制,并与高频鼠标事件日志同步。
- 数据集包含2万条轨迹的训练集与505条轨迹的基准集(每领域101条),平均录制时长9.62秒,每段视频577帧。
- 模型训练中,ShowUI-π使用ScreenDrag训练数据,以及GUIAct、WaveUI、UGround和ShowUI-Desktop中的桌面点击子集,排除所有非点击与移动端数据。
- 屏幕录制不进行裁剪,完整保留全屏视频与元数据。元数据包括UI元素位置、属性与实时任务状态,支持与轨迹的精确对齐。
- 完整的数据生成代码库与原始采集数据(含PowerPoint模板)将开源,以支持可复现性与社区使用。
方法
作者利用统一的基于流的生成模型ShowUI-π,通过直接建模连续空间轨迹,实现精细GUI操作。该框架基于SmolVLA-450M架构,集成预训练视觉语言模型(VLM)与轻量级动作专家。VLM处理多模态输入,将视觉观测编码为统一嵌入空间,同时融合投影后的动作状态与任务指令,使模型保持对环境与任务上下文的连贯理解。动作专家为与VLM骨干相同层数的Transformer,负责生成动作序列。推理时,VLM与动作专家交替执行自注意力与交叉注意力,使动作专家能基于当前视觉状态与历史动作进行预测。上一步的动作状态被投影回VLM骨干,以指导后续预测,实现细粒度、闭环控制。
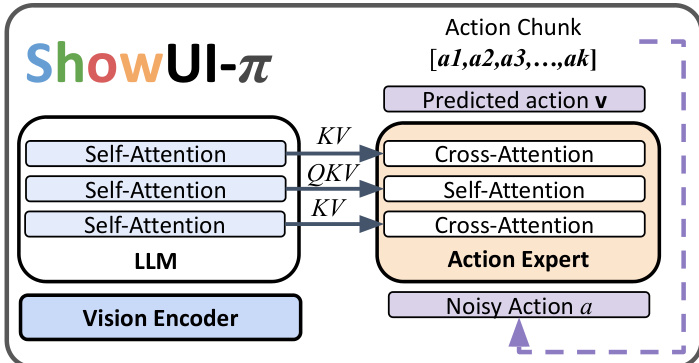
模型采用统一动作表示,无缝整合离散点击与连续拖拽。所有交互被建模为(x,y,m)三元组序列,其中(x,y)为光标坐标,m为鼠标按钮状态(按下或释放)。一次点击表示为最小两步轨迹:[(x1,y1,down),(x1,y1,up)],而拖拽则表示为扩展的增量按压-保持轨迹:[(x1,y1,down),(x2,y2,down),…,(xT,yT,up)]。该统一表示简化了动作空间,使策略自然支持灵活的多数据集联合训练。

为实现连续轨迹生成,ShowUI-π采用基于流的增量生成框架。动作专家预测一个时间条件化的速度场vθ,控制预测动作轨迹a^(s)在连续参数s∈[0,1]上的平滑演化。该过程由微分方程dsda^(s)=vθ(a^(s),s∣ot,Q)形式化,其中ot为当前观测,Q为任务指令。为确保高质量轨迹,模型采用重加权流匹配损失,重点强化轨迹的起始与终止段,赋予这些关键步骤10倍权重,而中间步骤为1。该重加权机制确保模型准确对齐起点并精确落点于目标终点。
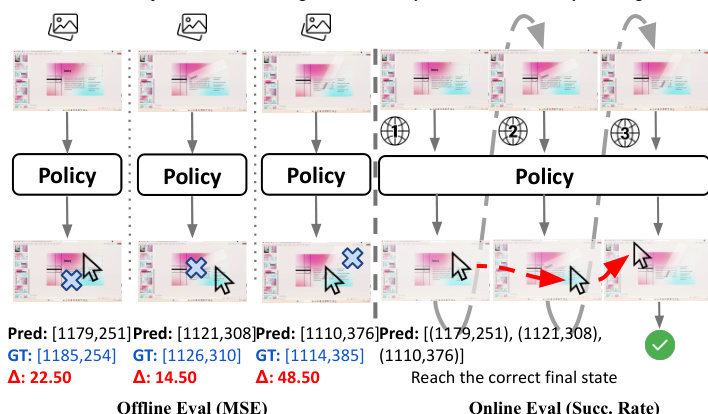
为进一步提升轨迹质量,模型引入方向正则化。标准流方法优化轨迹幅度,但未显式强制方向一致性,可能导致抖动或光标方向错误。为此,引入方向正则化损失:Lreg=T1∑t=1T(1−cos(a^t,ut)),其中a^t与ut分别为预测与真实动作点。该损失项惩罚运动方向偏差,促进轨迹平滑连贯。最终训练目标结合重加权流匹配损失与方向正则化损失,平衡参数λ设为0.1,以确保损失项量级相当。
实验
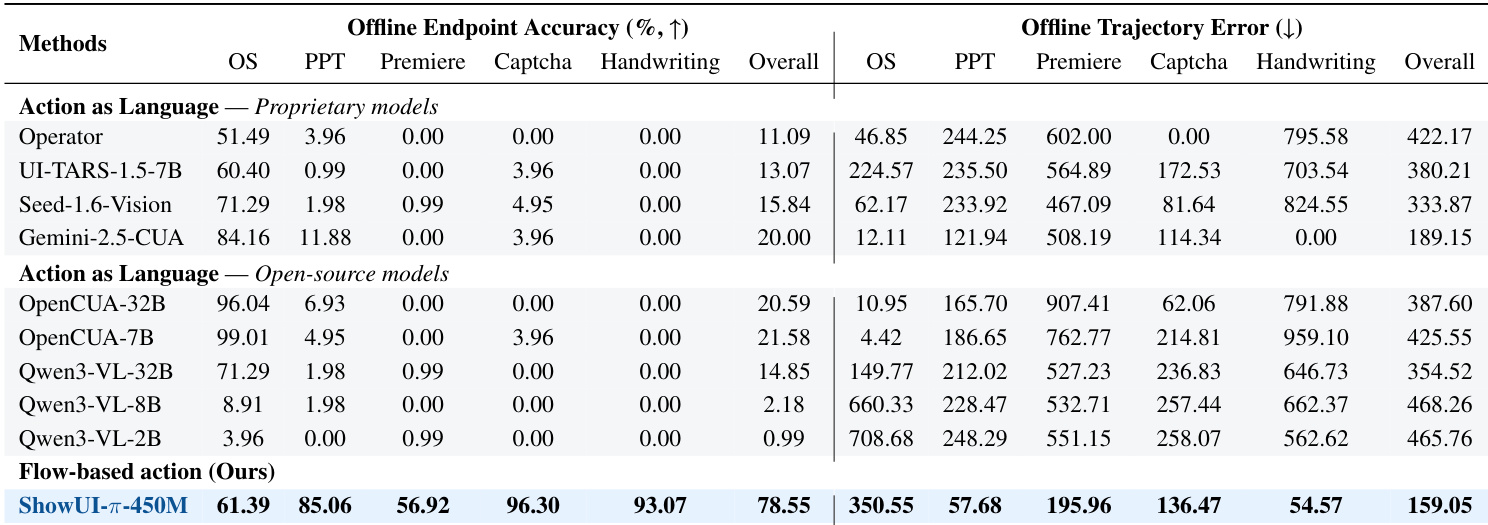
- 离线评估通过平均轨迹误差(ATE)与轨迹终点准确率(TEA)验证模型逐步轨迹精度,ShowUI-π取得最低ATE 159.05像素与最高TEA 78.55%,优于扩散策略与语言建模方法。
- 在线评估通过任务成功率验证真实世界闭环性能,ShowUI-π达到26.98%成功率,超越SOTA专有模型Gemini-2.5-CUA(4.8%)与开源模型OpenCUA-7B(6.19%)。
- 消融实验表明,流匹配在离线与在线设置中均优于语言建模与扩散策略,方向正则化与重加权显著提升成功率,尤其在验证码与自由拖拽任务中。
- 统一动作头设计在精度上媲美独立头,同时减少1亿参数,提升在线拖拽成功率3.7%。
- 定性结果表明,ShowUI-π生成平滑、类人轨迹,能精确跟随PowerPoint旋转、手写与验证码求解任务中的复杂路径。
- 在公开基准(VideoGUI-Action)上的评估显示,尽管训练基于连续观测,ShowUI-π仍取得具有竞争力的拖拽性能,表明其在领域偏移下具备强泛化能力。
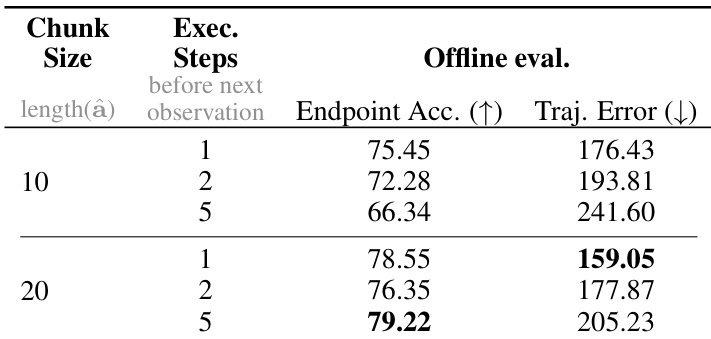
结果表明,将块大小从10增至20可提升终点准确率并降低轨迹误差,最佳性能在块大小为20、单次执行步长下达成,表明更长动作预测与频繁重观测可增强精度。
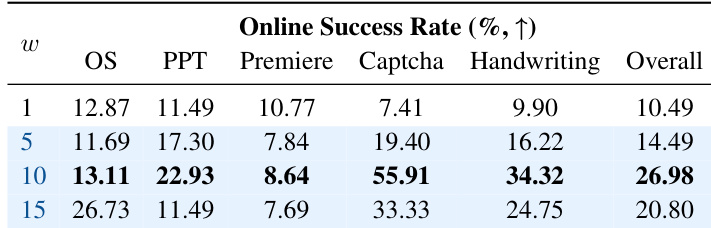
结果表明,线上成功率随时间权重尺度w显著变化,w=10时取得最高总体成功率26.98%,在多个领域表现最优,尤其在验证码任务中。性能在w=10处达到峰值,表明适度重加权可最优平衡关键步骤的准确性,而更高尺度(如15)因过度强调特定步骤导致整体性能下降。
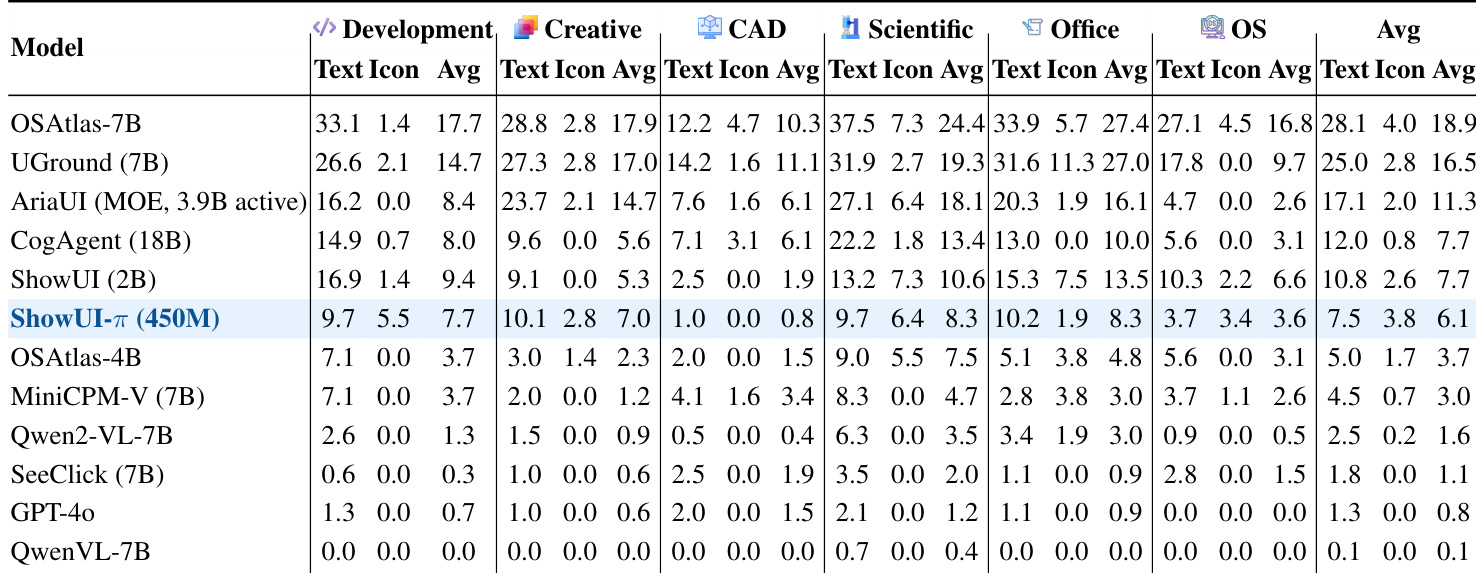
作者采用数据驱动方法在ScreenSpot-Pro基准上评估ShowUI-π,比较不同训练数据配方的性能。结果表明,同时使用拖拽与基础数据进行联合训练显著提升性能,在所有类别中取得最高分,尤其在创意与办公领域,模型得益于ScreenDrag数据集中相关数据的丰富性。

作者采用数据驱动方法实现在线评估中的闭环滚动,模型预测动作与记录状态在容差范围内匹配以获取下一观测,实现连续交互而无需完整操作系统配置。结果表明,ShowUI-π在所有领域中取得最高平均任务成功率6.1%,优于所有基线模型,尤其在创意与办公任务中表现突出,同时在处理自由形式旋转与手写等多样化拖拽动作时表现出鲁棒性。
结果表明,ShowUI-π-450M在所有领域中均取得最高离线终点准确率,尤其在验证码与手写任务中表现优异,同时相比所有基线模型具有最低离线轨迹误差。作者通过此表强调,其基于流的动作建模方法在终点精度与轨迹平滑性上均优于基于语言与扩散的方法。