Command Palette
Search for a command to run...
Youtu-Agent:基于自动化生成与混合策略优化的Agent生产率提升
Youtu-Agent:基于自动化生成与混合策略优化的Agent生产率提升
摘要
现有的大型语言模型(LLM)智能体框架面临两大核心挑战:配置成本高与能力固化。构建高质量的智能体通常需要大量人工投入在工具集成与提示工程(prompt engineering)上,而部署后的智能体在面对动态环境时,又难以有效适应,往往依赖昂贵的微调(fine-tuning)才能更新能力。为解决上述问题,我们提出 Youtu-Agent——一个面向大语言模型智能体的自动化生成与持续演进的模块化框架。Youtu-Agent 采用结构化配置体系,将执行环境、工具集与上下文管理三者解耦,支持灵活复用与自动化合成。该框架引入两种生成范式:- 工作流(Workflow)模式,适用于标准化任务,实现高效、可复现的智能体构建;- 元智能体(Meta-Agent)模式,专为复杂、非标准化需求设计,能够自动完成工具代码、提示模板与系统配置的生成。此外,Youtu-Agent 构建了一套混合式策略优化系统:1. 智能体实践(Agent Practice)模块:通过上下文内优化(in-context optimization)机制,使智能体在不更新参数的前提下积累经验、持续提升性能;2. 智能体强化学习(Agent RL)模块:与分布式训练框架深度集成,支持端到端、大规模的 Youtu-Agent 强化学习训练,实现可扩展且稳定的性能优化。实验结果表明,Youtu-Agent 在 WebWalkerQA 任务上达到 71.47% 的准确率,在 GAIA 基准上达到 72.8%,均基于开源权重模型,达到当前领先水平。其自动化生成流程的工具合成成功率超过 81%。在 AIME 2024/2025 基准测试中,Practice 模块分别带来 +2.7% 和 +5.4% 的性能提升。同时,Agent RL 训练在 7B 规模大模型上实现 40% 的训练加速,且性能持续稳定增长;在数学推理与通用/多跳问答任务中,编码能力、推理能力与搜索能力分别提升最高达 35% 和 21%。
一句话摘要
腾讯优图实验室、复旦大学与厦门大学的作者提出 Youtu-Agent,一种模块化框架,通过工作流(Workflow)与元代理(Meta-Agent)模式实现大语言模型(LLM)代理的自动化生成,结合无需训练的经验积累与可扩展强化学习的混合策略优化系统,在 WebWalkerQA 和 GAIA 基准上达到最先进性能,同时降低配置成本,实现无需昂贵微调的持续演化。
主要贡献
- Youtu-Agent 引入模块化、基于 YAML 的架构,将环境、工具集与代理解耦,支持自动化生成可执行代理配置(包括工具代码与提示词),显著降低配置成本,并支持灵活、可复用的组件设计。
- 框架实现双范式生成系统:工作流模式适用于确定性、常规任务,元代理模式适用于动态、复杂需求,实现无需人工干预的代理行为自主合成。
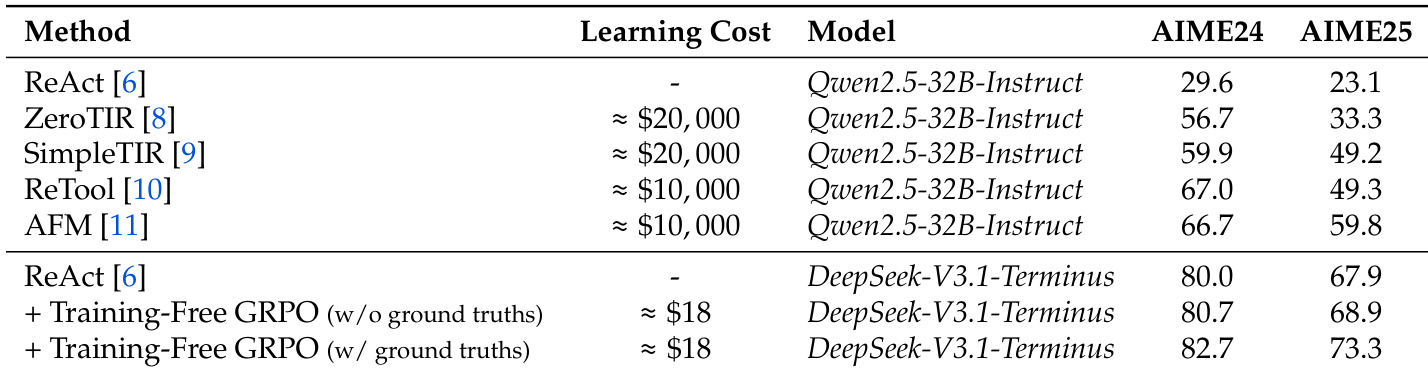
- 拥有混合优化流水线:Agent Practice 模块通过仅使用 100 个样本和 $18 成本的上下文内经验积累,提升性能;Agent RL 模块支持稳定、可扩展的强化学习,实现 40% 速度提升与 128-GPU 支持,使 Qwen2.5-7B 在 AIME 2024 上准确率从 10% 提升至 45%。
引言
作者利用大语言模型(LLM)代理在现实任务自动化中的日益增长趋势,针对高配置成本与静态能力两大挑战,阻碍了可扩展部署。以往框架依赖耗时的提示工程或昂贵的微调,适应性有限且可扩展性差。Youtu-Agent 通过模块化、基于 YAML 的架构,分离环境、工具与代理逻辑,实现代理配置与可执行工具代码的自动化生成。引入两种生成模式——工作流模式用于确定性任务,元代理模式用于动态场景——并配备混合优化系统:Agent Practice 模块通过并行回放与经验共享,实现低成本、无梯度的自我改进;Agent RL 模块支持稳定、可扩展的强化学习,解决并发与熵爆炸问题。该框架仅使用开源模型即在基准测试中取得优异表现,显著提升任务完成率、准确率与训练效率。
数据集
- 数据集名为 AgentGen-80,包含 80 个多样化任务描述,用于评估自动化代理生成能力,涵盖从简单信息检索到复杂多步自动化任务。
- 该数据集专为此研究构建,因当前尚无适用于该任务的成熟基准,且包含均衡的任务类型组合,以确保全面评估。
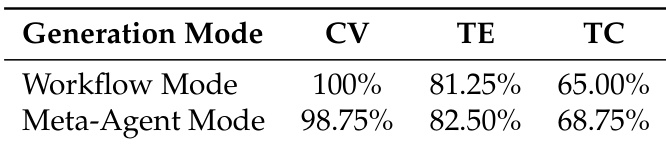
- 评估聚焦三个关键维度:配置有效性(CV),评估生成的 YAML 配置在结构与语义上是否完整正确;工具可执行性(TE),衡量合成工具是否能正常编译与运行;任务完成度(TC),测试代理在端到端任务中达成目标的成功率。
- 数据集仅用于评估,不包含任何训练数据;作为标准化测试平台,用于衡量模型在三个质量维度上的表现。
- 未进行裁剪或元数据构建——每个任务描述均以原始形式使用,评估基于代理生成流水线的完整输出。
方法
Youtu-Agent 框架围绕模块化架构构建,旨在解耦执行组件,实现大语言模型(LLM)代理的自动化生成与持续优化。核心执行框架包含三个分层结构:环境层、工具层与代理层。环境层提供基础执行上下文,抽象低层能力如浏览器导航、命令执行或沙箱代码环境。该抽象使工具与代理可在不同后端间运行,仅需极少修改。工具层封装原子与复合操作,分为环境相关工具、环境无关工具以及用于外部服务集成的模型上下文协议(MCP)工具。代理层包含由 LLM 驱动的规划器/执行器,通过“感知–推理–行动”循环运行。为管理长时交互并控制上下文窗口大小,该层集成上下文管理模块,剔除过时信息,同时保留关键任务历史。

框架由基于 YAML 的结构化配置系统支持,以声明方式指定所有组件,包括环境、工具、代理指令与上下文管理设置。该标准化格式便于手动组合与自动化合成。自动化生成机制利用此配置系统,从高层任务描述生成完整代理配置,采用两种不同范式。工作流模式遵循确定性的四阶段流程:意图澄清与分解、工具检索与临时工具合成、提示工程、配置组装。该流程适用于定义清晰的常规任务的快速开发。对于更复杂或模糊的需求,元代理模式部署更高层级的架构代理,动态规划生成过程。该元代理使用一组可调用工具——search_tool、create_tool、ask_user 与 create_agent_config——进行多轮澄清、检索或合成工具,并组装最终配置。

除执行外,框架强调通过两个主要优化组件实现代理的持续改进。Agent Practice 模块实现低成本、基于经验的改进,无需参数更新。其集成无训练组相对策略优化(Training-free GRPO),通过在小数据集上执行多次回放,生成多样化解决方案轨迹。一个 LLM 评估器对这些轨迹的相对质量进行评估,从成功与失败案例的对比中提炼出语义组优势。该经验知识随后以“文本 LoRA”形式注入代理的上下文,在在线测试中引导推理,而无需修改模型权重。Agent RL 模块提供完整的端到端强化学习流水线,支持可扩展且稳定的训练。该模块通过自定义连接器与现代 RL 框架集成,通过 RESTful API 包装、基于 Ray 的并发机制与分层超时逻辑实现可扩展性。稳定性通过过滤无效工具调用、减少离策略更新与校正优势估计偏差来保障。

端到端强化学习训练流水线由三个主要组件构成:RL 框架、连接器与代理框架。RL 框架负责数据加载、回放生成、损失计算与策略更新。连接器作为桥梁,实现 RL 框架与 Youtu-Agent 执行环境之间的转换。其包含 LLM 代理、桥接协议与数据存储,实现无缝通信与数据交换。代理框架(包含 Youtu-Agent 核心)管理代理的生命周期,从初始化到执行与奖励计算。该模块化设计支持在分布式系统中高效集成与可扩展训练。
实验
- 框架效率:仅使用开源模型,在 WebWalkerQA 上实现 71.47% pass@1,在 GAIA(纯文本子集)上实现 72.8% pass@1,建立通用代理能力的强开源基线。
- 自动化代理生成:工作流与元代理模式分别实现 100% 与 98.75% 的配置有效性,工具可执行性达 81.25%–82.50%,任务完成度达 65.00%–68.75%,证明了自动化工具与代理配置合成的有效性。
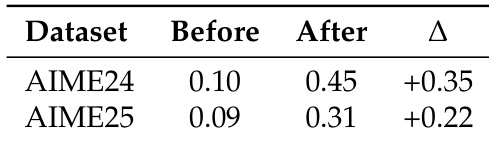
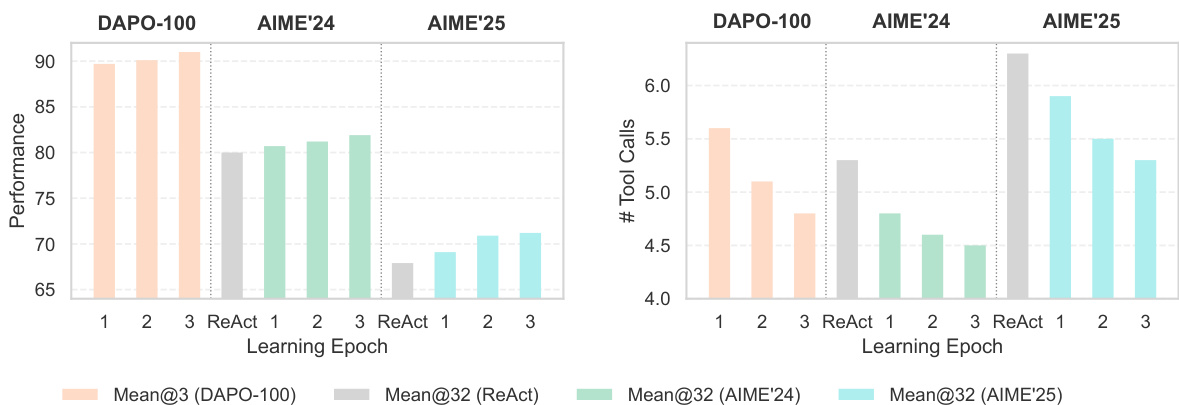
- 持续经验学习:Agent Practice 模块中的无训练 GRPO 在仅使用 100 个训练样本且无梯度更新的情况下,使 AIME 2024 与 AIME 2025 准确率分别提升 +2.7% 与 +5.4%,性能媲美昂贵的强化学习方法,成本仅为极小部分。
- 可扩展且稳定的代理强化学习:Agent RL 模块将训练迭代时间减少 40%,使 Qwen2.5-7B 在 AIME 2024 上准确率从 10% 提升至 45%,在数学/代码与搜索任务中均实现稳定提升,验证了大规模强化学习训练中增强的可扩展性与稳定性。
作者采用无训练方法提升代理在数学推理基准上的性能,在 AIME 2024 与 AIME 2025 上分别实现 +2.7% 与 +5.4% 的绝对提升,无需参数更新且仅使用 100 个训练样本。这表明通过上下文学习积累经验,可低成本有效增强代理能力。
作者在 AIME 2024 与 AIME 2025 基准上评估其无训练 GRPO 方法的有效性,结果显示:在无真实标签训练时,准确率分别为 80.7% 与 68.9%;在有真实标签训练时,准确率分别提升至 82.7% 与 73.3%,均优于 ReAct 基线。结果表明,该方法以极低学习成本与无参数更新,实现显著性能提升。
作者利用 Agent Practice 模块提升代理在数学推理基准上的表现,在 AIME 2024 上实现 +0.35 的绝对提升,在 AIME 2025 上实现 +0.22 提升。结果表明,无训练 GRPO 方法可通过经验积累实现有效学习,无需参数更新,显著提升准确率。
结果表明,无训练 GRPO 方法在 AIME 2024 与 AIME 2025 上各学习周期中均实现一致的性能提升,Mean@32 准确率从第 1 轮到第 3 轮持续上升。工具调用次数随周期递减,表明代理在无参数更新的情况下学习到更高效的求解策略。
作者对比 Youtu-Agent 中两种自动化生成模式,结果显示元代理模式任务完成率略高(68.75% vs. 65.00%),同时保持相当的工具可执行性与配置有效性。结果表明两种模式均有效,元代理模式在端到端性能上略胜一筹。