Command Palette
Search for a command to run...
SenseNova-MARS:通过强化学习赋能多模态智能体推理与搜索
SenseNova-MARS:通过强化学习赋能多模态智能体推理与搜索
摘要
尽管视觉-语言模型(Vision-Language Models, VLMs)能够通过代理式推理(agentic reasoning)完成复杂任务,其能力仍主要局限于以文本为中心的思维链(chain-of-thought)或孤立的工具调用。它们难以展现出人类般的流畅能力,即在持续推理过程中无缝地交织动态工具操作,尤其在需要协调外部工具(如搜索与图像裁剪)的知识密集型和视觉复杂场景中表现不足。为此,本文提出SenseNova-MARS——一种新型的多模态代理式推理与搜索框架,通过强化学习(Reinforcement Learning, RL)赋予VLMs交错进行视觉推理与工具使用的综合能力。具体而言,SenseNova-MARS动态整合图像搜索、文本搜索与图像裁剪等工具,以应对细粒度且知识密集型的视觉理解挑战。在强化学习训练阶段,我们提出一种新型算法——批归一化组序列策略优化(Batch-Normalized Group Sequence Policy Optimization, BN-GSPO),有效提升了训练稳定性,并显著增强了模型在工具调用与推理决策方面的综合能力。为全面评估代理式VLM在复杂视觉任务中的表现,我们构建了首个面向搜索任务的基准测试集HR-MMSearch,该基准由高分辨率图像构成,包含大量知识密集型与搜索驱动型问题,具有较高的挑战性。实验结果表明,SenseNova-MARS在开源搜索与细粒度图像理解基准上均达到当前最优性能。具体而言,在面向搜索的基准测试中,SenseNova-MARS-8B在MMSearch上取得67.84的得分,在HR-MMSearch上达到41.64,超越了包括Gemini-3-Flash和GPT-5在内的多个闭源模型。SenseNova-MARS为实现具备高效、稳健工具使用能力的代理式VLM迈出了重要一步。为推动该领域的进一步研究,我们将开源全部代码、模型及数据集,以支持学术界与工业界的持续探索。
一句话总结
来自商汤研究院、清华大学和中国科学技术大学的作者提出了 SenseNova-MARS,一种融合强化学习与动态工具编排(图像搜索、文本搜索和图像裁剪)的多模态代理推理框架,实现了视觉推理与工具使用的无缝交织,在知识密集型、高分辨率视觉搜索任务上通过新颖的 BN-GSPO 算法和 HR-MMSearch 基准超越了专有模型。
主要贡献
- 现有的视觉语言模型(VLMs)难以将动态工具使用(如图像和文本搜索或图像裁剪)无缝整合到连续的多步视觉推理中,限制了其在真实场景下处理知识密集型和高分辨率视觉任务的能力。
- SenseNova-MARS 引入了一种新颖的多模态代理框架,利用强化学习实现视觉推理与协同工具使用的交织,通过统一的推理过程动态组合图像搜索、文本搜索和图像裁剪工具。
- 该框架在面向搜索的基准上达到最先进水平,在 MMSearch 上得分为 67.84,在新提出的 HR-MMSearch 基准上得分为 41.64,超越了 Gemini-3-Flash 和 GPT-5 等专有模型,所提出的 BN-GSPO 算法提升了训练稳定性与多工具协同能力。
引言
视觉语言模型(VLMs)已向代理式推理发展,但先前系统仅限于以文本为中心的思维链或孤立的工具使用,无法动态交织视觉推理与搜索、图像裁剪等多工具操作——这对知识密集型、高分辨率视觉任务至关重要。现有方法要么专注于仅搜索,要么仅关注图像操作,缺乏集成且自适应的工具协调机制。作者提出 SenseNova-MARS,一种由强化学习驱动的框架,将图像搜索、文本搜索和图像裁剪工具统一于连贯的多轮推理过程中。他们提出 BN-GSPO 算法——一种批归一化的组序列策略优化方法,提升了多工具场景下的训练稳定性和性能,并引入 HR-MMSearch,首个面向高分辨率、搜索驱动视觉理解的基准。实验表明,SenseNova-MARS-8B 在开源基准上达到最先进水平,超越了 Gemini-3-Flash 和 GPT-5 等专有模型,展示了在复杂视觉环境中稳健、类人化的代理推理能力。
数据集
-
HR-MMSearch 基准包含 305 张高分辨率 4K 图像,全部来自 2025 年最新事件,数据源为三家权威国际新闻机构:路透社、美联社(AP)和 CNBC。这确保了预训练 VLM 知识的最小数据泄露,并支持对真实视觉推理的评估。
-
图像被人工划分为八个高影响力领域:体育、娱乐与文化、科技、商业与金融、游戏、学术研究、地理与旅行及其他,每张图像由三位本科水平标注员进行标注。
-
针对每张图像,设计知识密集型、面向搜索的问题,聚焦于小尺寸或不显眼的视觉元素——如占据图像面积不足 5% 的文字或物体——要求至少使用三种工具之一:图像搜索、文本搜索或图像裁剪。
-
由三位硕士水平专家组成的团队交叉验证全部 305 个图像-问题对,确保标签准确性、问题质量与正确答案。
-
问题难度通过 Qwen2.5-VL-7B-Instruct 作为代理模型的 pass@8 评估协议确定。在八次滚动中均失败的问题被标记为“难”(共 188 个),通常需要三次或更多工具调用,且常涉及三种工具的协同使用。其余 117 个问题被归类为“易”,通常可通过一次或两次工具调用解决。各领域难度分布大致均衡,每类约 60% 为难样本,40% 为易样本。
-
冷启动监督微调(SFT)阶段使用约 3,315 个高质量样本的精选数据集,来源包括:从 FVQA 过滤并合成的 1,115 条轨迹,强调像素级推理的约 2,000 个 Pixel-Reasoner 语料库样本,以及为多步工具使用手动构建的 200 条复杂推理轨迹。
-
强化学习(RL)阶段使用更大、更多样化的数据集:3,695 个剩余的 FVQA 样本,4,000 个来自 DeepEyes-4K 的高分辨率分析样本,以及完整的 5,729 个样本 Visual-Probe 数据集,以支持广泛的视觉推理。
-
评估中,作者以 HR-MMSearch 为主要基准,用于细粒度代理搜索,辅以 MMSearch、FVQA-test、InfoSeek、SimpleVQA、LiveVQA 和 MAT-Search,覆盖真实世界信息检索、事实准确性与动态新闻推理的多个方面。
-
视觉推理评估包括 V* Bench(来自 SA-1B 的 191 张高分辨率、细节丰富的图像)、HR-Bench(800 张 4K 图像和 800 张 8K 图像,用于测试可扩展性与细节保留能力),以及 MME-RealWorld(涵盖 OCR、遥感、图表、视频监控和自动驾驶等 43 个子任务的 23,599 个 QA 样本,包含高分辨率、杂乱场景)。
-
在 RL 训练期间,文本搜索管道使用本地维基百科知识库进行检索以降低开销,推理阶段则通过 Serper API 实现实时网络搜索。两种模式检索到的段落均由 Qwen3-32B 模型统一摘要后输入主模型。
方法
作者采用两阶段训练框架,开发出一种能够对复杂、知识密集型任务进行细粒度视觉分析的代理式搜索-推理模型。整体架构旨在使多模态代理通过推理与工具使用与动态环境交互,目标是基于高分辨率图像回答自然语言查询。该框架运行于多轮交互设置中,代理从初始图像和查询开始,迭代执行推理步骤与工具操作(如文本搜索、反向图像搜索或图像裁剪),直至生成最终答案。该过程围绕正式的任务形式化展开,将观察空间定义为完整的交互历史,包括先前的推理、工具调用及其输出,动作空间则为四种可能动作的集合:文本搜索、图像搜索、图像裁剪或生成最终答案。每一轮交互包含一个推理步骤和一个单一动作,形成不断演进的信息轨迹。

如图所示,训练过程分为两个阶段。第一阶段为冷启动监督微调(SFT)阶段,用于启动模型执行多工具调用的能力。该阶段使用一个小而高质量的多轮交互轨迹数据集,每个样本包含用户查询和目标推理轨迹。SFT 目标为标准的最大似然损失,优化模型在给定输入查询和交互历史的情况下预测正确推理步骤与动作序列的能力。第二阶段采用强化学习(RL)进一步优化模型的推理与工具使用能力。为应对多模态、工具增强环境中训练的挑战——如轨迹长度差异、奖励幅度变化和任务难度不一——作者提出一种新算法:批归一化 GSPO(BN-GSPO)。该方法对优势估计实施两阶段归一化:首先在每个提示批次内进行组级标准化,然后在整个小批量上进行批次级归一化。这种归一化稳定了学习信号,缓解了可能破坏训练的偏差与方差。RL 目标为裁剪的序列级损失,结合归一化优势与 KL 散度项,防止对参考策略的过拟合。

SFT 阶段的训练数据通过三阶段流程构建,如图所示。过程始于数据挖掘,从现有多模态 QA 数据集和专家标注对中构建原始数据池。随后进行过滤,识别出“难例”——即基线模型仅能正确回答一次或更少的问题。针对这些难样本,使用大语言模型(Gemini-2.5-Flash)提示生成完整的解决方案轨迹,包括推理步骤与工具调用。合成轨迹经过质量验证,由另一模型(GPT-4o)检查格式合规性、逻辑连贯性与答案合理性。仅保留验证通过的轨迹,最终形成约 3,000 个高质量样本的数据集。对于 RL 阶段,训练数据来自现有基准的组合,包括 FVQA-train、VisualProbe-train 和 DeepEyes-4K-train,提供事实性与高分辨率视觉分析任务的多样化混合。

BN-GSPO 中使用的奖励模型旨在评估完整交互轨迹的质量。序列级奖励由两个部分组成:准确性和格式合规性。准确性奖励衡量预测答案与真实答案之间的语义一致性,使用大语言模型作为裁判进行评估。格式奖励确保严格遵守交互协议:非最终轮次必须包含推理轨迹和单一工具调用,而最终轮次必须包含推理轨迹和答案。所有内容必须用特殊标签包裹,所有工具调用必须符合指定的 JSON 模式。这种双组件奖励函数引导模型生成既正确又结构良好、符合协议的轨迹。

如图所示,文本搜索管道在训练与推理阶段保持一致,以确保学习行为的有效迁移。训练阶段使用本地维基百科知识库,避免实时网络搜索的成本。检索过程使用 E5-retriever 获取前 k 个段落,随后进行两阶段摘要:首先由 Qwen3-32B 模型对每个段落单独摘要,然后生成所有段落的最终整体摘要。这种两阶段摘要过程确保模型在与推理阶段格式相同的训练数据上学习核心工具使用行为。推理阶段,对 Serper Search API 返回的结果应用相同的摘要流程,使模型即使从未见过真实网络搜索输出,也能有效泛化。该管道还使用 Playwright 获取 HTML 内容,使用 BeautifulSoup 解析,避免 JavaScript 渲染以保持效率并降低被机器人检测的风险。
实验
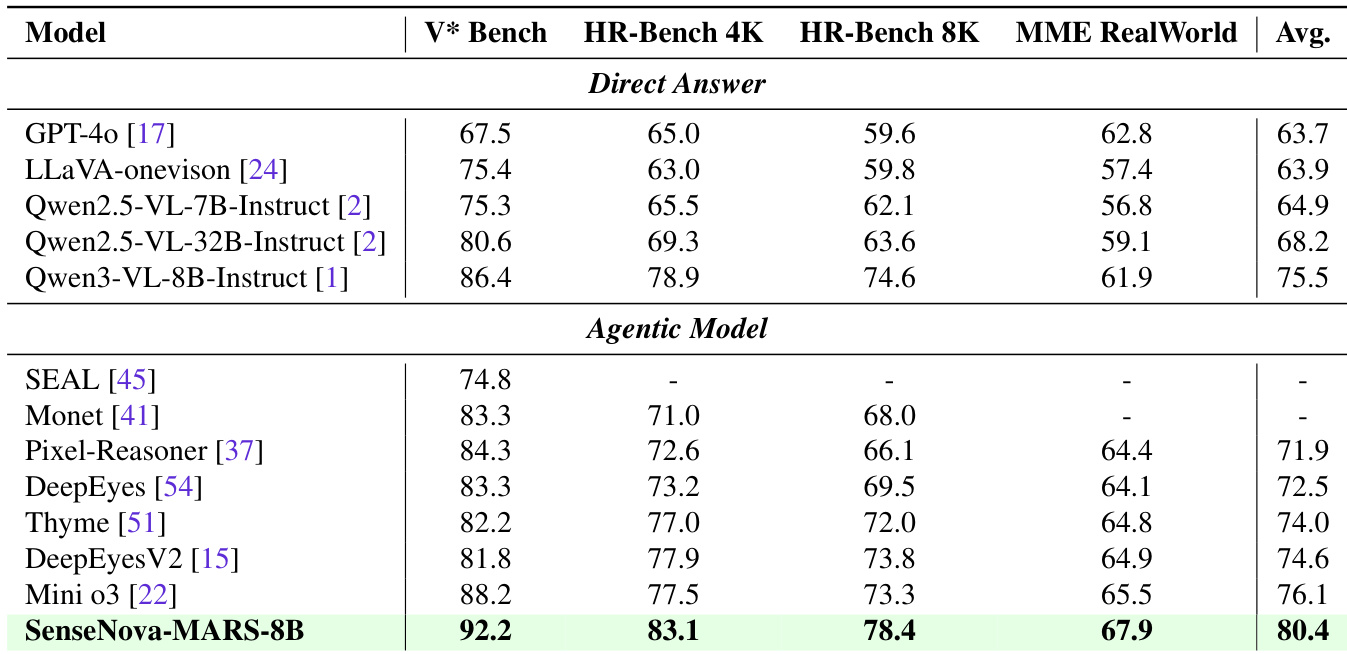
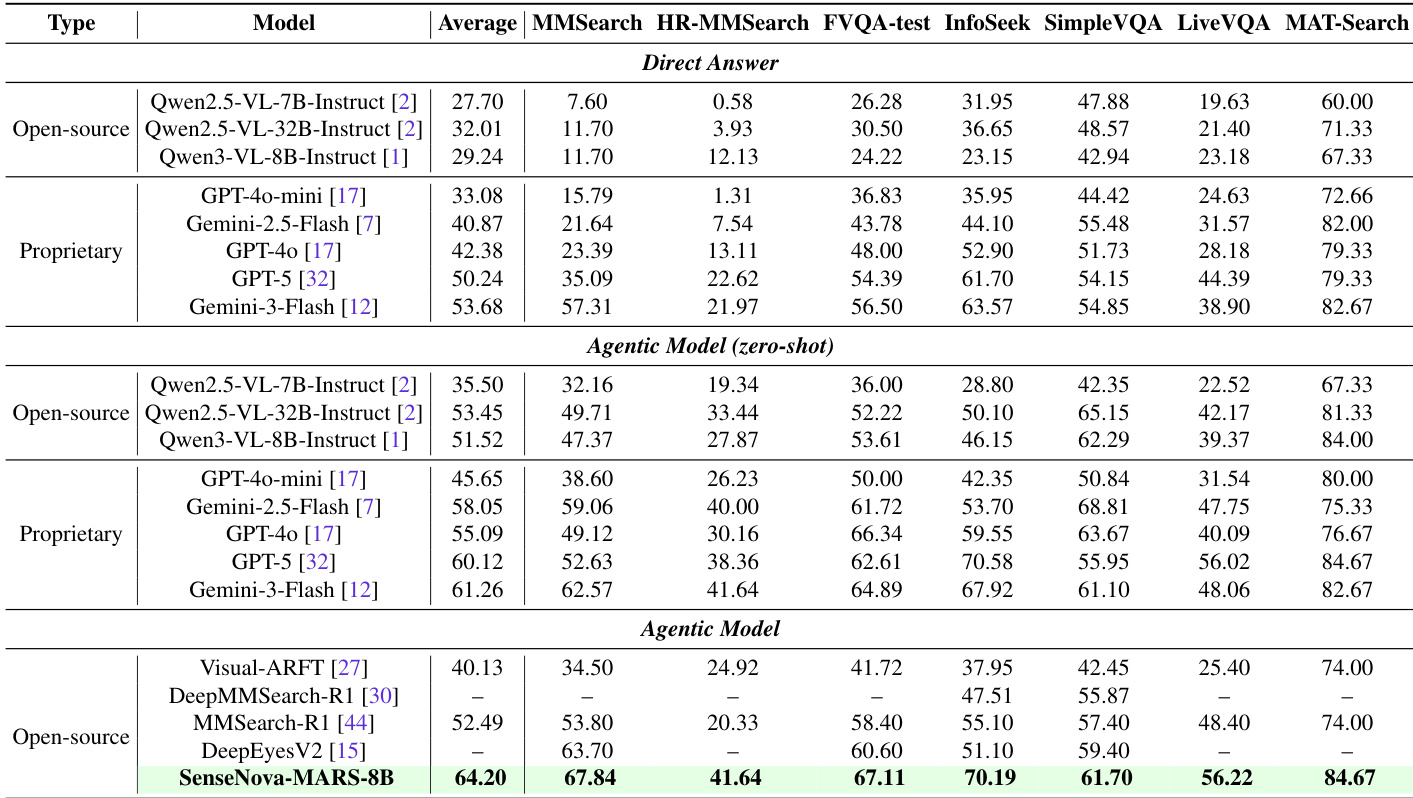
- 通过 LLaMA-Factory 和 veRL 的两阶段 SFT 与 RL 流程训练的 SenseNova-MARS-8B,在开源 8B 模型中达到最先进性能,超越 GPT-5、Gemini-2.5-Flash 和 Gemini-3-Flash 等专有模型,在面向搜索的基准上平均领先 Qwen3-VL-8B 12.68 分,领先 MMSearch-R1 11.71 分(在 Agentic Model 工作流下)。
- 在视觉理解基准上,SenseNova-MARS-8B 在 V* Bench 上取得 92.2 的最高分,HR-Bench 4k 为 83.1,HR-Bench-8k 为 78.4,MME-RealWorld 为 67.9,超越现有工具型模型,相比 Qwen3-VL-8B 平均提升 4.9 分。
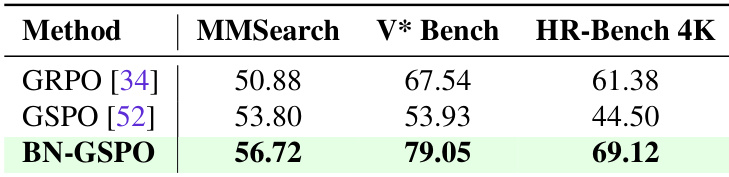
- 所提出的 BN-GSPO 算法在搜索与感知任务中表现出更优的稳定性与平衡性能,相比 GRPO 和 GSPO,有效缓解了多工具 RL 训练中的奖励尺度方差问题。
- 混合训练数据(结合搜索与感知任务)至关重要,仅在特定数据上训练会导致过度专业化,降低跨领域任务表现。
- 工具使用分析显示,SenseNova-MARS-8B 动态调整策略——在知识密集型任务中依赖搜索工具,在细粒度分析中结合图像搜索与裁剪——而 RL 将冗余工具调用从约 4 次减少至约 2 次,提升效率。
作者采用结合监督微调与强化学习的两阶段训练流程开发 SenseNova-MARS-8B,在搜索导向基准上达到最先进水平,并超越开源与专有模型。结果表明,SenseNova-MARS-8B 在所有评估任务(包括 MMSearch、HR-MMSearch 和 V* Bench)中均取得最高准确率,展示了其在整合外部工具与执行细粒度视觉推理方面的卓越能力。
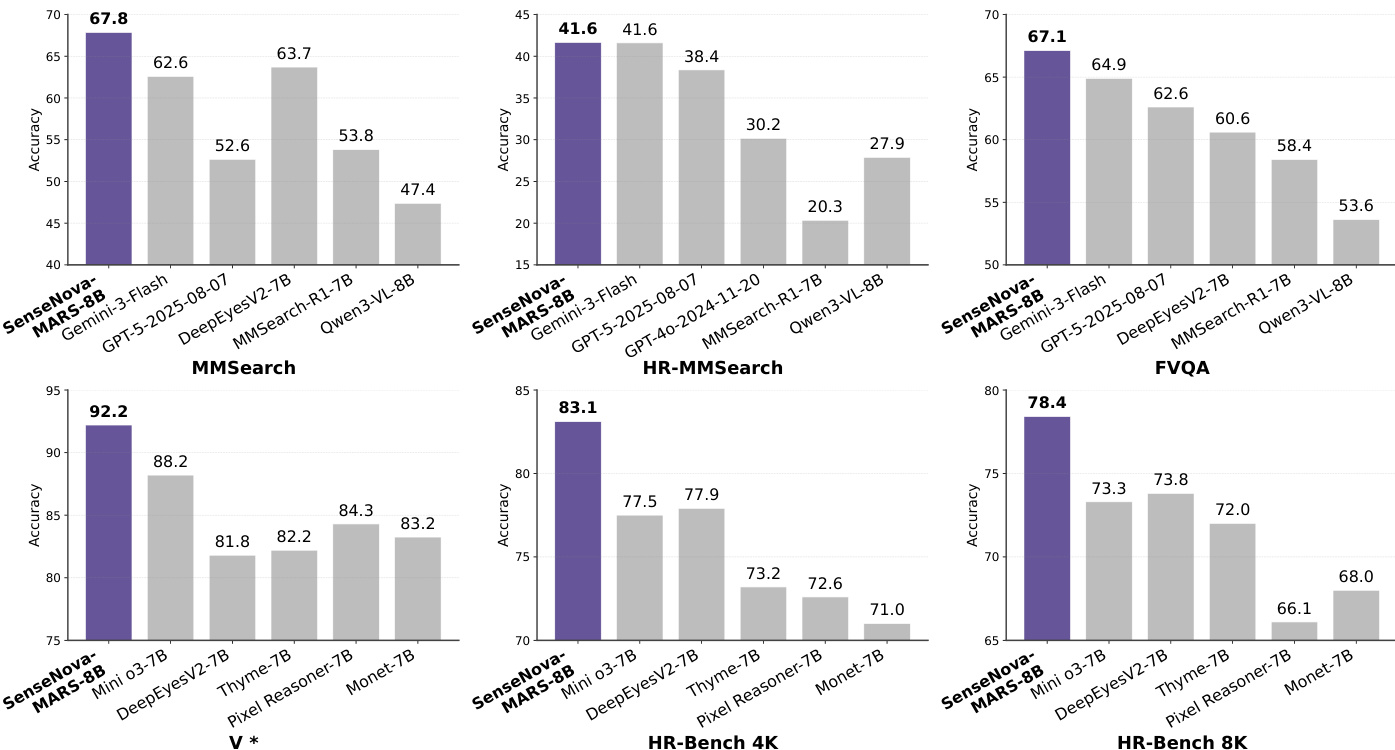
作者采用结合监督微调与强化学习的两阶段训练流程开发 SenseNova-MARS-8B,该模型在搜索导向与视觉理解基准上进行评估。结果表明,SenseNova-MARS-8B 在两类任务中均达到开源模型的最先进水平,超越了 GPT-4o 和 Qwen3-VL-8B 等强基线模型,在多个指标上表现优异。
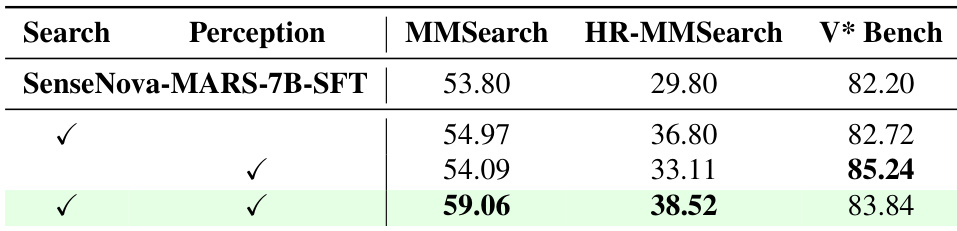
作者采用两阶段训练流程,从监督微调(SFT)开始,随后进行强化学习(RL),开发 SenseNova-MARS-7B。结果表明,结合 SFT 与 RL 能在所有基准上取得最佳性能,最终模型在 MMSearch 上得分为 59.06,在 HR-MMSearch 上为 38.52,在 V* Bench 上为 83.84,优于仅使用 SFT 或仅使用 RL 训练的模型。
作者采用结合监督微调与强化学习的两阶段训练流程开发 SenseNova-MARS-8B,该模型在搜索导向与视觉理解基准上进行评估。结果表明,SenseNova-MARS-8B 在开源模型中达到最先进水平,超越多个专有模型,尤其在代理搜索任务中表现突出,同时展现出强大的细粒度视觉理解能力。
作者在一组基准上比较不同强化学习算法的性能,结果表明 BN-GSPO 在所有任务中均优于 GRPO 和 GSPO。结果显示,BN-GSPO 在 MMSearch、V* Bench 和 HR-Bench 4K 上均取得最高分,证明其在平衡多工具学习与提升整体模型性能方面的有效性。