Command Palette
Search for a command to run...
驯服幻觉:通过反事实视频生成提升MLLMs的视频理解能力
驯服幻觉:通过反事实视频生成提升MLLMs的视频理解能力
Zhe Huang Hao Wen Aiming Hao Bingze Song Meiqi Wu Jiahong Wu Xiangxiang Chu Sheng Lu Haoqian Wang
摘要
多模态大语言模型(MLLMs)在视频理解任务中取得了显著进展。然而,这类模型存在一个关键缺陷:过度依赖语言先验,容易导致视觉上缺乏依据的幻觉现象,尤其在处理违背常识的反事实视频时更为明显。这一局限性源于文本与视频数据之间固有的不平衡问题,而由于收集和标注反事实数据成本高昂,该问题难以有效解决。为此,我们提出 DualityForge——一种新颖的反事实数据合成框架。该框架采用可控的、基于扩散模型的视频编辑技术,将真实世界视频转化为反事实场景。通过在视频编辑与问答(QA)生成过程中嵌入结构化的上下文信息,该框架能够自动构建高质量的问答对,并同步生成原始视频与编辑后视频的配对数据,用于对比学习训练。基于此,我们构建了 DualityVidQA——一个大规模视频数据集,旨在降低 MLLM 在反事实视频上的幻觉现象。此外,为充分挖掘配对数据的对比特性,我们进一步提出 Duality-Normalized Advantage Training(DNA-Train)方法,这是一种两阶段的监督微调与强化学习(SFT-RL)训练范式。其中,强化学习阶段引入成对 ℓ1 优势归一化机制,显著提升了策略优化的稳定性与效率。在 DualityVidQA-Test 上的实验表明,我们的方法在反事实视频任务上显著减少了模型幻觉,相较于 Qwen2.5-VL-7B 基线模型实现了 24.0% 的相对性能提升。同时,该方法在幻觉检测与通用基准任务上均取得显著进步,展现出强大的泛化能力。我们计划开源该数据集与相关代码,以推动该领域的进一步研究。
一句话摘要
清华大学、北航大学与AMAP(阿里巴巴集团)的作者提出DualityForge,一种基于扩散模型的框架,用于生成具有结构化上下文的反事实视频问答对,从而构建DualityVidQA数据集及DNA-Train-7B模型。该模型采用成对ℓ₁优势归一化方法,实现稳定的对比学习训练,在反事实视频推理中显著降低多模态大语言模型(MLLMs)的幻觉现象,同时提升跨基准的泛化能力。
主要贡献
- 我们提出DualityForge,一种新颖的反事实数据合成框架,通过嵌入结构化上下文的可控扩散视频编辑技术,生成精确的反事实视频场景,实现高质量、成对视频-问答数据的自动构建,用于对比学习训练。
- 我们引入DualityVidQA,一个大规模数据集,包含14.4万对视频-问答(10.4万用于SFT,4万用于RL)和8.1万唯一视频,旨在通过真实与编辑后视频对的对比学习,系统性评估并减少MLLMs中的幻觉。
- 我们开发DNA-Train,一种两阶段SFT-RL训练方法,在强化学习阶段应用成对ℓ₁优势归一化,实现更稳定的优化,在反事实视频问答任务上相较Qwen2.5-VL-7B提升24.0%相对性能,并在幻觉检测与通用基准上均表现出强泛化能力。
引言
多模态大语言模型(MLLMs)在视频理解方面已取得显著进展,但仍易产生视觉无依据的幻觉——即依赖语言先验而非实际视觉内容,生成看似合理却错误的答案,尤其在违反物理或常识规范的反事实场景中更为明显。这一问题因海量文本数据与有限视频训练数据之间的固有不平衡而加剧,而以往通过纯文本修改缓解幻觉的方法效果有限且耗时费力。作者提出DualityForge,一种基于扩散模型的可控视频编辑框架,通过在编辑过程中嵌入结构化上下文先验(如事件类型、时间位置),系统性生成高质量反事实视频。这使得成对视频-问答数据(原始视频与编辑后视频,搭配对比性问题)的自动化、可扩展合成成为可能,构成了DualityVidQA数据集(14.4万样本)。为充分利用这种对比结构,作者提出DNA-Train,一种两阶段训练范式,结合监督微调与强化学习,并采用ℓ₁归一化的成对优势,稳定策略优化并强化视觉 grounding。实验表明,在DualityVidQA-Test基准上实现24.0%的相对提升,并在通用视频理解任务中取得显著增益,证明合成反事实数据能有效提升MLLM的鲁棒性与泛化能力。
数据集
- 该数据集DualityVidQA基于两个主要视频来源构建:OpenVid与Pexels,分别贡献61,591段与36,333段视频片段,总计97,924个原始视频,用于合成异常注入的多样化基础。
- 视觉异常在三个层级引入:整帧、区域与对象,使用OpenCV及分割工具(Grounding DINO与SAM)。对象级异常针对从视频中提取的特定名词实体,在时间上一致的片段中施加扰动。
- 语义异常包括意外实体行为(如突然出现或消失)以及视觉失真(如模糊人脸或不可读文字),通过VACE视频编辑模型插入,以保留其余视频内容。
- 常识异常——如违反物理定律、因果不一致、材料异常及不自然的人体动作——通过两步流程生成:多模态大模型分析视频并生成编辑指令,再由FLUX-Kontext执行;VACE帧插值将原始与编辑帧合成最终编辑视频。
- 最终数据集包含135,168个注入异常的视频,经质量筛选后用于问答构建。整个过程在NVIDIA H20 GPU上耗时约40,000 GPU小时。
- 训练采用两阶段框架:监督微调(SFT)与强化学习(RL)。SFT阶段从2.5万真实视频与2.5万编辑视频中生成10万对问答,开放性问题与多选题比例为8:2。使用带红色边框的密集描述与视频编辑元数据引导描述生成,GPT-5与Gemini 2.5 Pro生成问题与答案,利用LLaVA-Video中的5,000个上下文参考以确保一致性与多样性。
- RL阶段构建2万对反事实问答对,同一问题与选项用于真实与编辑视频,但正确答案不同,迫使模型基于实际视觉内容推理。Gemini 2.5 Pro利用视频描述并识别视觉差异生成这些对。
- 高质量测试集DualityVidQA-Test包含600对真实-反事实视频,共享一个问题但正确答案不同。该测试集经人工与专家评审,确保清晰性、有效性与可答性。测试集分为四类:反物理、对象/场景变形、因果反转与属性变化。
方法
作者采用两阶段训练框架DNA-Train,以缓解多模态大语言模型(MLLMs)中的幻觉问题,同时保持真实世界性能。该框架由监督微调(SFT)阶段与强化学习(RL)阶段构成,旨在显式惩罚错误的视觉 grounding 并奖励准确推理。DNA-Train的整体架构如图所示,展示了从SFT到RL的过渡过程。

第一阶段SFT使用DualityVidQA数据集初始化模型。该数据集通过DualityForge框架构建,通过对真实世界源视频施加可控编辑,生成全面的反事实视频集合。编辑由三类分层异常引导:视觉、语义与常识,每类对应独立的视频编辑流水线。生成的反事实视频与其原始版本共同构成双数据集。第二阶段,模型进入强化学习以优化推理能力。该阶段基于DAPO框架,专为长推理链的稳定优化设计。RL过程对真实与反事实视频分别采样一组响应,根据任务正确性计算奖励,并计算组内优势的ℓ1范数。关键创新在于Duality Advantages Normalization策略,通过将各组优势归一化,确保其对梯度更新的贡献均衡。
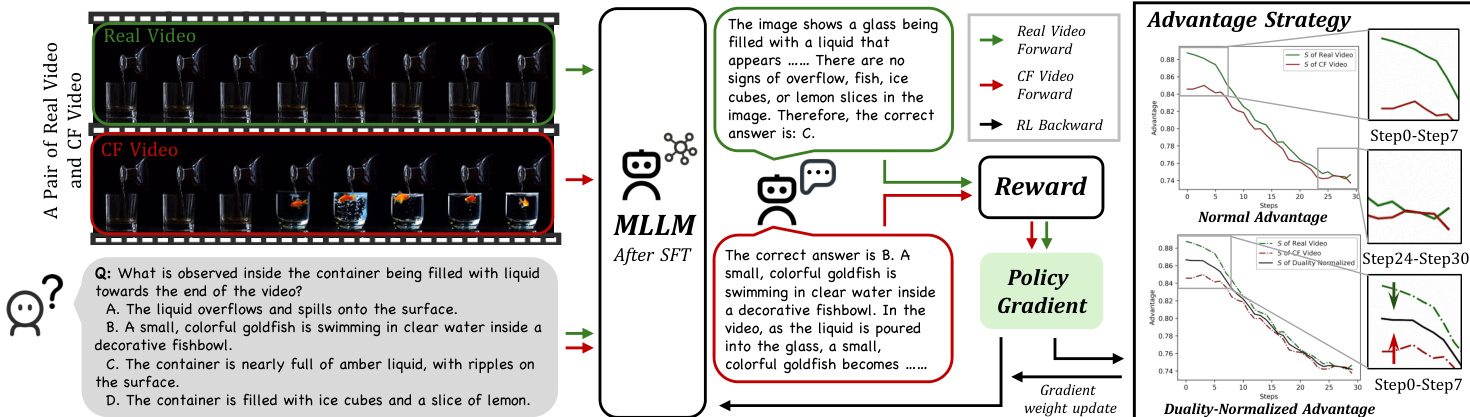
RL阶段的奖励信号为双组件设计,源自共享问题的对比问答对。第一部分为正确性奖励,为选择唯一正确答案分配二值分数,强制模型捕捉细微视觉信息。第二部分为格式奖励,鼓励遵循预设推理结构。总体奖励公式为R=rf+rc。DAPO目标的梯度受优势A^i,t调制,作者采用优势的ℓ1范数S=∑iA^i作为一组响应的总学习信号强度的代理。该公式揭示一个关键特性:学习信号在中等难度任务上达到峰值,而当任务过于简单或不可能时则减弱。为应对真实与反事实数据间学习信号的系统性不平衡,作者引入Duality-Normalized Advantage,将各组优势归一化,确保对梯度更新的贡献相等。这一优雅的重加权方案(A^∗′=α∗A^∗)保证了不同数据类型间学习信号的平衡,促进鲁棒且公平的优化。
实验
- DualityVidQA引入三种视频编辑流水线以生成反事实上下文:视觉异常(通过OpenCV进行像素级编辑)、语义异常(使用掩码生成与VACE编辑的对象编辑)、常识异常(通过FLUX-Kontext与VACE插值实现常识违反编辑)。
- 在DualityVidQA-SFT上进行监督微调(SFT),采用真实与反事实视频的平衡采样,结合交叉熵损失,以维持两个领域上的性能。
- 在DualityVidVQA-Test上,DNA-Train-7B达到76.8%准确率,优于其他开源模型,展现出最先进的幻觉检测能力,同时保持强大的通用视频理解性能。
- DNA-Train-7B在MVBench与TVBench上超越GPT-4o,在具有挑战性的反物理类别中达到79.2%,表现出对反事实编辑的卓越鲁棒性。
- 消融实验确认,成对真实-反事实数据至关重要,使DualityVid-Test性能提升至70.6,并使通用基准平均提升+1.8。
- DNA-Train在幻觉检测上比GRPO与DAPO基线平均高出10.8分,同时提升所有通用基准性能。
- 性能增益在不同模型规模上保持一致,7B版本在幻觉检测上提升25.9分,且在多种架构(包括LLaVA-Next-Video)上均有效。
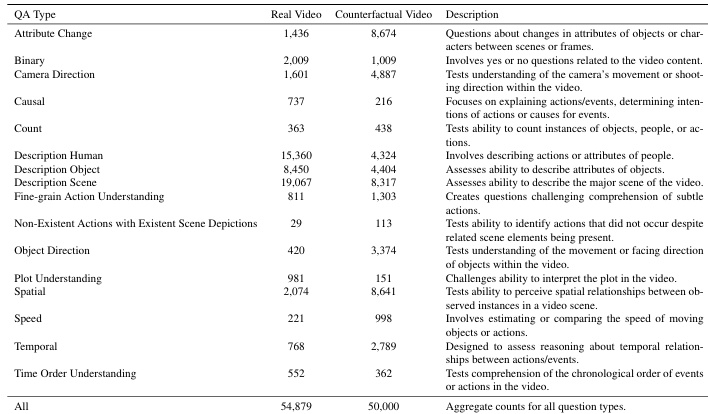
作者使用表格总结其DualityVidQA数据集中真实与反事实视频的问题类型分布,显示反事实视频中属性变化、二元推理与摄像机方向相关问题更多,而真实视频更侧重于对象与动作描述。结果显示,模型在反事实视频上的性能显著下降,尤其在因果推理与细粒度动作类别中,凸显了鲁棒视频理解的关键挑战。
作者采用监督微调与强化学习方法,在真实与反事实视频上训练模型,旨在提升幻觉检测能力而不牺牲通用视频理解性能。结果表明,DNA-Train-7B模型在幻觉检测基准上达到最先进性能,同时在通用视频理解任务上保持强劲表现,优于开源与闭源模型。
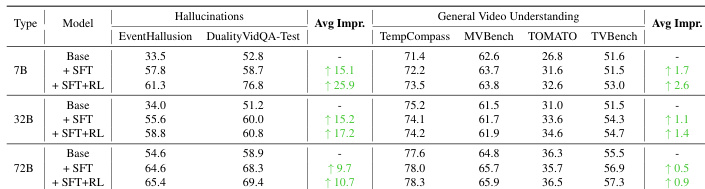
结果表明,DNA-Train-7B模型在DualityVidQA-Test基准上达到最先进性能,整体准确率达76.8%,显著优于其他开源模型,并在反事实视频理解任务中展现出强大鲁棒性。该模型在通用视频理解基准上也保持竞争力,相较于基线模型在所有任务上均有提升,且在不同模型架构与规模下均表现出鲁棒性。
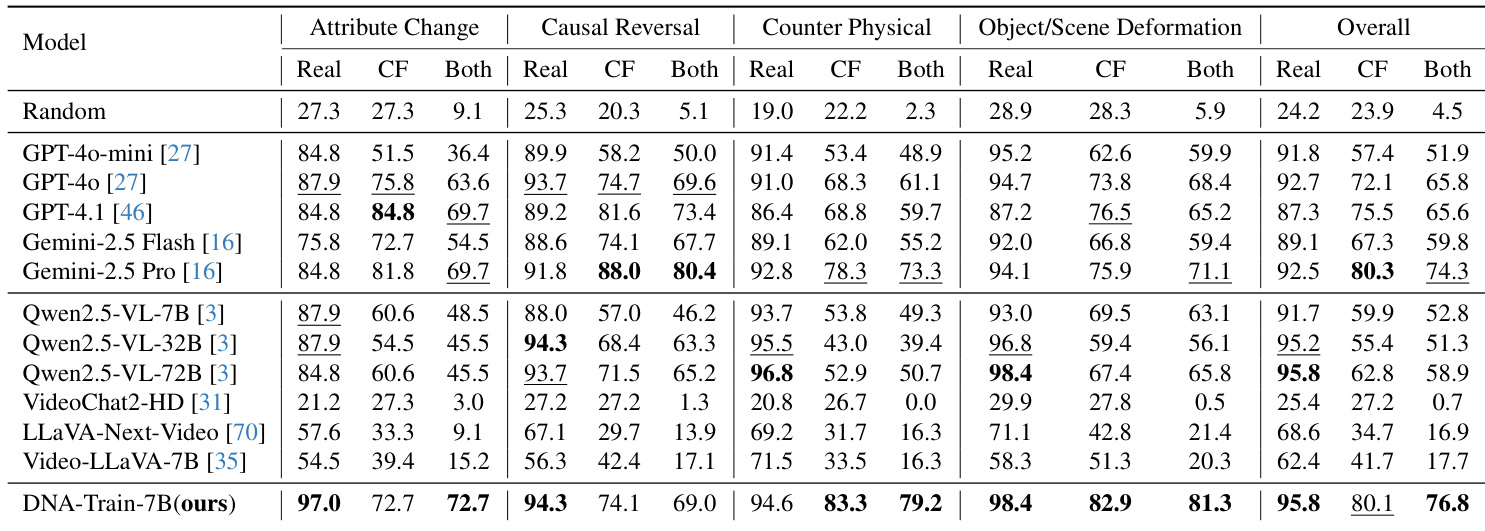
结果表明,成对数据设置在幻觉检测与通用视频理解基准上均取得最高性能,优于仅使用真实或反事实数据的设置。使用成对数据训练的模型在所有任务上的平均性能提升显著,表明结合真实与反事实数据对实现平衡学习具有显著有效性。

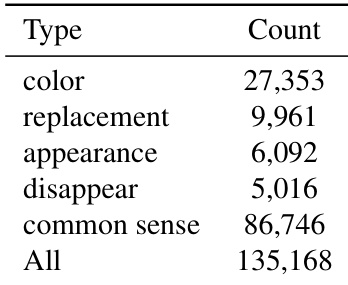
作者使用表格总结其数据集中不同类型的反事实视频编辑分布。数据显示,常识异常为最常见类别,共86,746例;而外观出现与消失编辑最少,分别为6,092例与5,016例。总计135,168例表明该数据集为大规模设计,旨在评估模型在多种视频篡改类型下的鲁棒性。