Command Palette
Search for a command to run...
GARDO:防止奖励劫持的扩散模型强化方法
GARDO:防止奖励劫持的扩散模型强化方法
Haoran He Yuxiao Ye Jie Liu Jiajun Liang Zhiyong Wang Ziyang Yuan Xintao Wang Hangyu Mao Pengfei Wan Ling Pan
摘要
通过在线强化学习(Reinforcement Learning, RL)对扩散模型进行微调,在提升文本到图像对齐能力方面展现出巨大潜力。然而,由于在视觉任务中精确设定真实目标函数仍具挑战性,模型通常依赖于一个代理奖励(proxy reward),而该奖励仅部分反映真实目标。这种不匹配常导致“奖励欺骗”(reward hacking)现象:代理奖励得分上升,但实际图像质量下降,生成多样性严重退化。尽管现有方法普遍采用对参考策略的正则化以抑制奖励欺骗,但此类方法往往以牺牲样本效率为代价,并阻碍对新颖高奖励区域的有效探索,因为参考策略本身通常并非最优。为应对样本效率、有效探索与奖励欺骗抑制之间的多重矛盾需求,本文提出一种通用框架——具有多样性感知优化的门控自适应正则化(Gated and Adaptive Regularization with Diversity-aware Optimization, GARDO),该框架可兼容多种强化学习算法。其核心思想在于:正则化无需对所有样本一视同仁,而应有针对性地对具有高不确定性的样本子集施加惩罚,从而实现更精准的调控。为解决探索难题,GARDO引入自适应正则化机制,定期更新参考模型以匹配在线策略的能力,确保正则化目标始终具有相关性。针对强化学习中常见的模式崩溃问题,GARDO通过增强高质量且高多样性的样本的奖励信号,激励模型覆盖更多生成模式,同时避免优化过程的不稳定性。在多种代理奖励函数及未见的评估指标下进行的大量实验表明,GARDO能够有效缓解奖励欺骗问题,显著提升生成多样性,且不以牺牲样本效率或探索能力为代价,充分体现了其在实际应用中的有效性与鲁棒性。
一句话总结
香港科技大学、快手科技、香港中文大学MMLab与爱丁堡大学的研究人员提出GARDO,一种通过无奖励训练强化扩散模型的新框架,利用自监督一致性正则化避免奖励劫持,从而在真实应用场景中实现更可靠、更鲁棒的图像生成。
主要贡献
-
使用代理奖励对扩散模型进行微调以实现文本到图像生成时,常导致奖励劫持现象:模型为优化不可靠的奖励信号而牺牲图像质量和多样性,这是由于基于模型或规则的奖励函数在捕捉真实人类偏好方面存在固有局限。
-
GARDO引入门控正则化机制,仅对通过集成奖励模型分歧识别出的高不确定性样本施加KL惩罚,其余样本则自由探索;同时采用自适应参考模型,随策略动态演化,以维持有效探索并避免陷入停滞。
-
在多种代理奖励和未见评估指标上的实验表明,GARDO能持续缓解奖励劫持,提升生成多样性,并保持高样本效率,展现出无需牺牲探索性或稳定性的稳健性能。
引言
使用强化学习(RL)对扩散模型进行微调以实现文本到图像生成,对于使输出与人类偏好对齐至关重要,但面临一个根本性挑战:无论是基于有限人类反馈学习的还是基于规则的代理奖励模型,都只是真实人类判断的不完美近似。这种偏差常导致奖励劫持,即模型为获得高代理分数而牺牲图像质量并降低多样性。以往解决方案依赖于对静态参考策略的KL正则化以防止过度优化,但该方法会损害样本效率并抑制探索,使策略被束缚在次优基线附近。本文作者提出GARDO框架,通过三项关键创新克服上述局限。首先,引入门控正则化,仅对一小部分高不确定性样本(通过多个奖励模型之间的分歧识别)施加惩罚,允许其余样本自由优化。其次,采用自适应正则化,定期将参考模型更新为当前在线策略,以保持正则化目标的相关性和有效性。第三,引入面向多样性的优势塑造,放大高质量、多样化样本的奖励,促进模式覆盖而不破坏训练稳定性。在多种代理奖励和未见指标上的实验表明,GARDO能有效缓解奖励劫持,同时保持样本效率、探索性和多样性。
方法
作者采用强化学习(RL)框架优化基于扩散的生成模型,将去噪过程视为马尔可夫决策过程(MDP)。整体框架从策略模型 πθ 开始,该模型以文本提示为条件,通过多步去噪过程生成图像。在每一步 t,状态 st 定义为 (c,t,xt),其中 c 为提示,t 为当前时间步,xt 为噪声图像。策略 πθ 预测动作 at,对应去噪后的图像 xt−1,有效建模从 xt 到 xt−1 的转移过程。奖励函数 R(st,at) 仅在最终步骤 t=0 非零,用于根据代理奖励函数 r(x0,c) 评估生成图像 x0 的质量。转移动态为确定性,初始状态 sT 从预定义分布 ρ0 中采样。目标是学习一个最优策略 π∗,以最大化轨迹上的期望累积奖励。

策略优化采用广义奖励策略优化(GRPO)算法的变体。在每次训练迭代中,采样一批提示,对每个提示,从随机噪声输入出发,通过策略滚动生成 G 张图像。计算每张生成图像 x0i 的奖励,并在 G 个样本组内估计优势 Ati。策略通过结合裁剪重要性采样比率与KL散度正则化项的代理目标进行更新。该目标旨在确保策略更新的稳定性,同时防止与数据收集所用行为策略产生过大偏离。

为解决奖励劫持和模式崩溃问题,作者引入门控KL正则化机制。该机制仅对代理奖励不确定性高的样本施加KL惩罚。不确定性通过比较样本的代理奖励 R~ 的胜率与同一样本在一组辅助奖励模型 {R^n}n=1K 上的平均胜率来量化。该方法确保正则化仅作用于代理奖励不可靠的样本,从而避免对策略施加不必要的约束。此外,采用自适应KL正则化方案,定期将参考策略 πref 重置为当前策略 πθ,以保持其相关性,防止KL惩罚主导损失并阻碍探索。
为促进样本多样性,作者提出一种面向多样性的优势塑造策略。该策略通过将优势函数乘以每个生成样本的多样性得分 di 来重塑优势函数。多样性得分基于DINOv3模型提取的语义特征空间中与最近邻的余弦距离计算得出。该重塑仅应用于具有正优势的样本,确保模型因生成高质量且新颖的图像而获得奖励。整体训练流程总结于算法1,整合了策略模型、奖励计算、不确定性估计、优势计算、多样性估计以及自适应KL正则化机制。
实验
- GARDO在正样本中采用乘法优势重塑,提升了多样性,实现了对低概率模式的发现,例如中心簇密度仅为参考模型的0.1倍,展现出强大的探索能力。
- 在优势归一化中移除标准差,通过防止微小奖励差异被放大,缓解了奖励劫持,提升了稳定性与泛化能力,且未牺牲样本效率。
- 在GenEval和OCR基准测试中,GARDO在代理奖励上达到与无KL基线相当的水平,同时在未见指标(Aesthetic、PickScore、HPSv3)和多样性上显著优于基线,多样性从19.98提升至24.95。
- GARDO的门控与自适应KL正则化提升了样本效率,在收敛速度上与无KL基线相当,同时有效抑制奖励劫持,仅约10%的样本被施加惩罚。
- 在具有挑战性的计数任务(10–11个物体)中,GARDO显著优于基础模型和原始GRPO,展现出超越预训练分布的新型行为。
- GARDO在不同基础模型(Flux.1-dev、SD3.5-Medium)和RL算法(DiffusionNFT)上均表现出良好的泛化能力,持续实现样本效率与分布外泛化之间的优越权衡,优于多奖励训练方法在代理奖励和未见奖励上的表现。
作者使用计数任务评估不同方法生成超出训练分布的新物体数量图像的能力。结果表明,与基线GRPO方法相比,GARDO在10和11个物体的计数任务上显著提升了准确率,而基线方法无法泛化到这些未见数量。
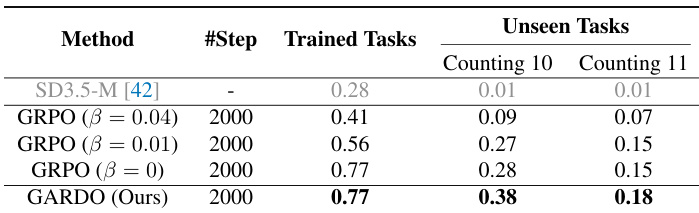
作者使用表格比较所提方法GARDO与多种基线在代理任务和未见任务上的性能。结果表明,GARDO在代理奖励和未见指标上均取得最高得分,尤其在多样性与泛化能力方面表现突出,同时保持高样本效率。该方法优于那些因奖励劫持或强正则化导致过于保守的基线。
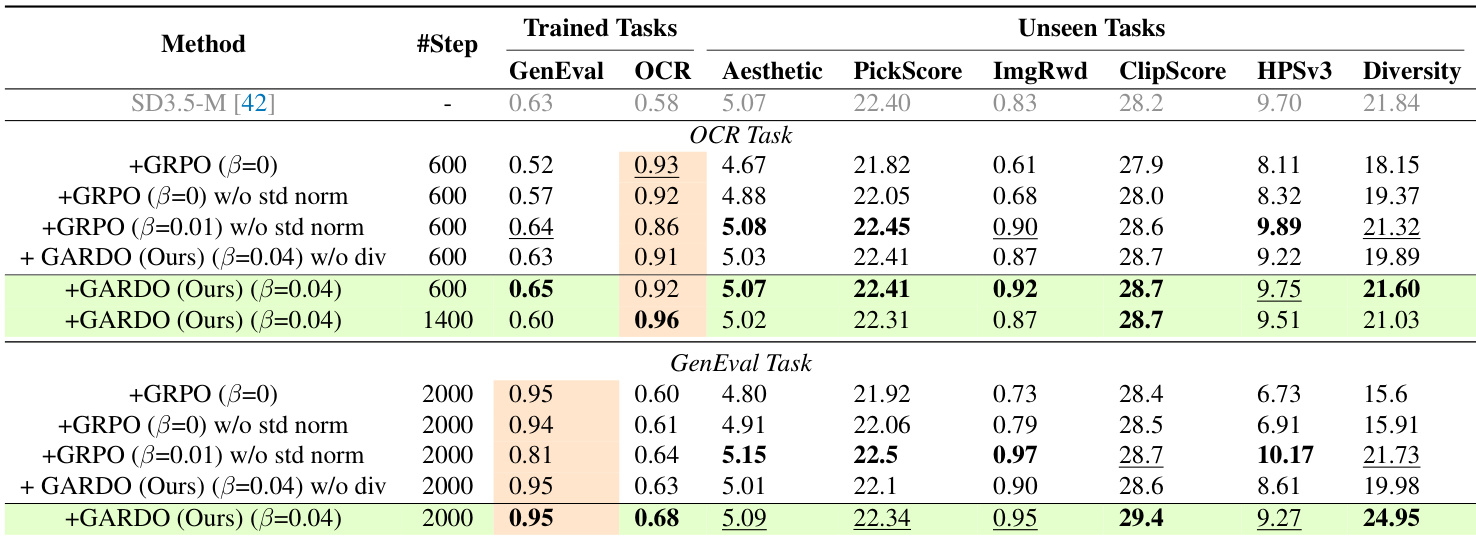
作者使用表格比较所提方法GARDO与多个基线在代理任务和未见任务上的性能。结果表明,GARDO在代理奖励和未见指标(包括GenEval、OCR、Aesthetic、PickScore和多样性)上均取得最高得分,同时保持高样本效率。这表明GARDO能有效缓解奖励劫持,提升泛化能力,且不损害主任务性能。
