Command Palette
Search for a command to run...
HY-MT1.5 技术报告
HY-MT1.5 技术报告
Mao Zheng Zheng Li Tao Chen Mingyang Song Di Wang
摘要
在本报告中,我们介绍了最新推出的两款机器翻译模型——HY-MT1.5-1.8B 与 HY-MT1.5-7B。这是基于专为高性能翻译设计的全流程训练框架所开发的新一代机器翻译模型家族。我们的方法构建了一个多阶段流水线,整合了通用预训练与面向机器翻译的预训练、监督微调、同策略知识蒸馏以及强化学习等关键技术。其中,参数量为18亿(1.8B)的HY-MT1.5-1.8B模型展现出卓越的参数效率,在标准中-外语及英-外语言翻译任务中,全面超越多个参数规模显著更大的开源基线模型(如Tower-Plus-72B、Qwen3-32B),并优于主流商业API(如Microsoft Translator、Doubao Translator)。该模型在性能上达到了超大规模专有模型Gemini-3.0-Pro的约90%水平;尽管在WMT25及中文-少数民族语言基准测试中略逊于Gemini-3.0-Pro,但仍显著领先于其他竞争模型。此外,HY-MT1.5-7B在同规模模型中创下新的最优性能纪录,在Flores-200基准上达到Gemini-3.0-Pro性能的95%,并在更具挑战性的WMT25及中文-少数民族语言测试集上实现超越。 除了标准翻译任务外,HY-MT1.5系列还支持多种高级约束能力,包括术语干预、上下文感知翻译以及格式保持。大量实证评估结果表明,这两款模型在其各自参数规模范围内,均能为通用及专业翻译任务提供高度竞争力且稳健的解决方案。
一句话总结
腾讯混元团队推出 HY-MT1.5-1.8B 和 HY-MT1.5-7B,这两款高效翻译模型通过多阶段训练流程构建,在翻译质量上超越更大规模的开源及商用系统,同时支持术语控制、格式保留等高级约束,适用于实际部署场景。
主要贡献
- HY-MT1.5-1.8B 和 HY-MT1.5-7B 在各自参数规模下实现当前最优翻译质量:1.8B 模型在 Flores-200 上达到 Gemini-3.0-Pro 约 90% 的性能,7B 模型达 95%,并在 WMT25 和中文-少数民族语言基准上超越 Gemini;同时保持部署效率。
- 模型通过整合通用与翻译专用预训练、监督微调、策略内蒸馏及基于评分标准的强化学习的多阶段训练流程训练而成,可实现高低资源语言对的强泛化能力。
- 除标准翻译外,HY-MT1.5 支持术语控制、上下文感知翻译、格式保留等实用定制功能,可借助提示词驱动适配特定工业场景。
引言
作者利用大语言模型最新进展,解决机器翻译中两大长期瓶颈:翻译质量与推理效率间的权衡,以及对定制化翻译任务支持不足。此前工作要么依赖部署成本高昂的大型闭源模型,要么采用牺牲质量的轻量开源模型,且无法处理上下文连贯性、文档格式或术语控制。为弥合这一差距,他们推出 HY-MT1.5 —— 一组高效高性能模型(1.8B 和 7B 参数),在质量上匹敌或超越顶级闭源模型,同时支持实用部署。其贡献包括定制化训练流程(结合预训练、微调和强化学习),以及内置提示词驱动的定制功能,如术语控制、上下文翻译和格式化输出保留。
方法
作者采用多阶段训练流程开发 HY-MT1.5-1.8B 和 HY-MT1.5-7B 模型,旨在通过知识迁移与对齐提升多语言翻译性能。整体框架始于基础模型 HY-1.8B-Base 和 HY-7B-Base,经历五个独立阶段。如下图所示,流程从面向翻译的预训练(阶段 1)开始,接着是监督微调(阶段 2),然后是强化学习(阶段 3),最终生成 HY-MT1.5-1.8B-preview 和 HY-MT1.5-7B 模型。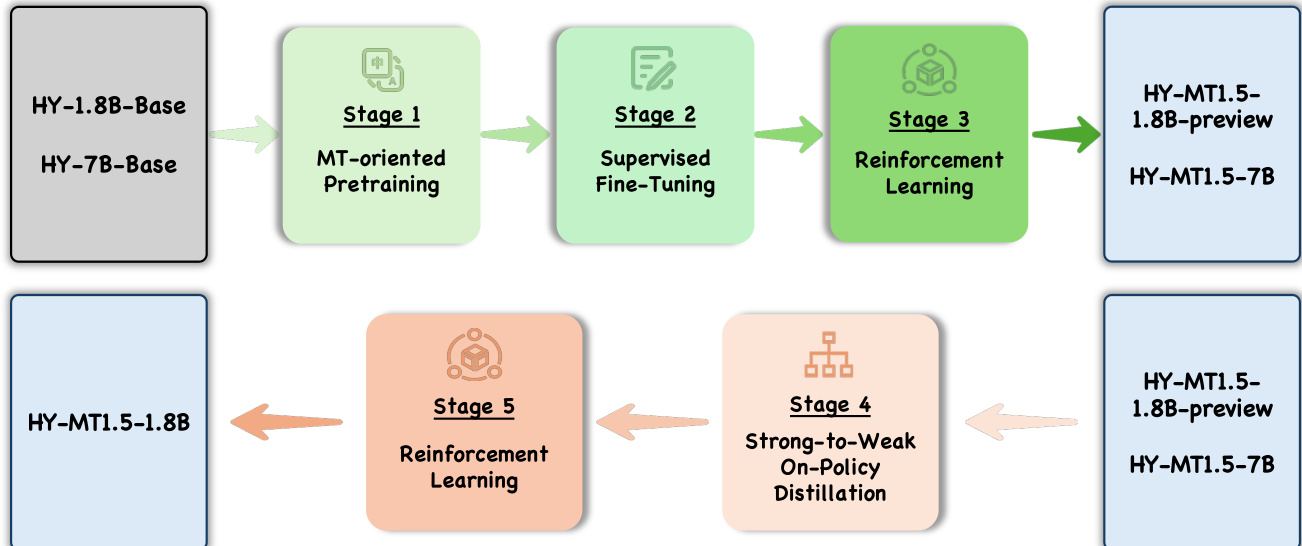
在初始阶段后,框架进入阶段 4:强到弱策略内蒸馏。其中,已完全训练的 HY-MT1.5-7B 模型作为教师,指导较小的 HY-MT1.5-1.8B-preview 模型。该阶段采用逐词逆 KL 散度对齐学生输出分布与教师分布,使 1.8B 模型继承 7B 模型的卓越翻译能力。蒸馏过程使用约 100 万条单语样本,覆盖 33 种支持语言,包括少数民族语言和方言。蒸馏后,模型进入最终强化学习阶段(阶段 5),通过与人类偏好对齐进一步优化翻译质量。
强化学习阶段采用 GRPO(组相对策略优化)算法,基于组内输出的相对比较更新策略,提升训练稳定性。为改进奖励建模,引入基于评分标准的评估系统:基于 LLM 的评估器从准确性、流利性、一致性、文化适宜性和可读性五个维度评分翻译结果。每个维度设定具体评分标准和权重,聚合得分形成最终奖励信号,提供细粒度反馈以引导模型优化。该多维度评估使模型在多个方面同步提升,输出准确、自然、连贯且文化恰当的译文。
实验
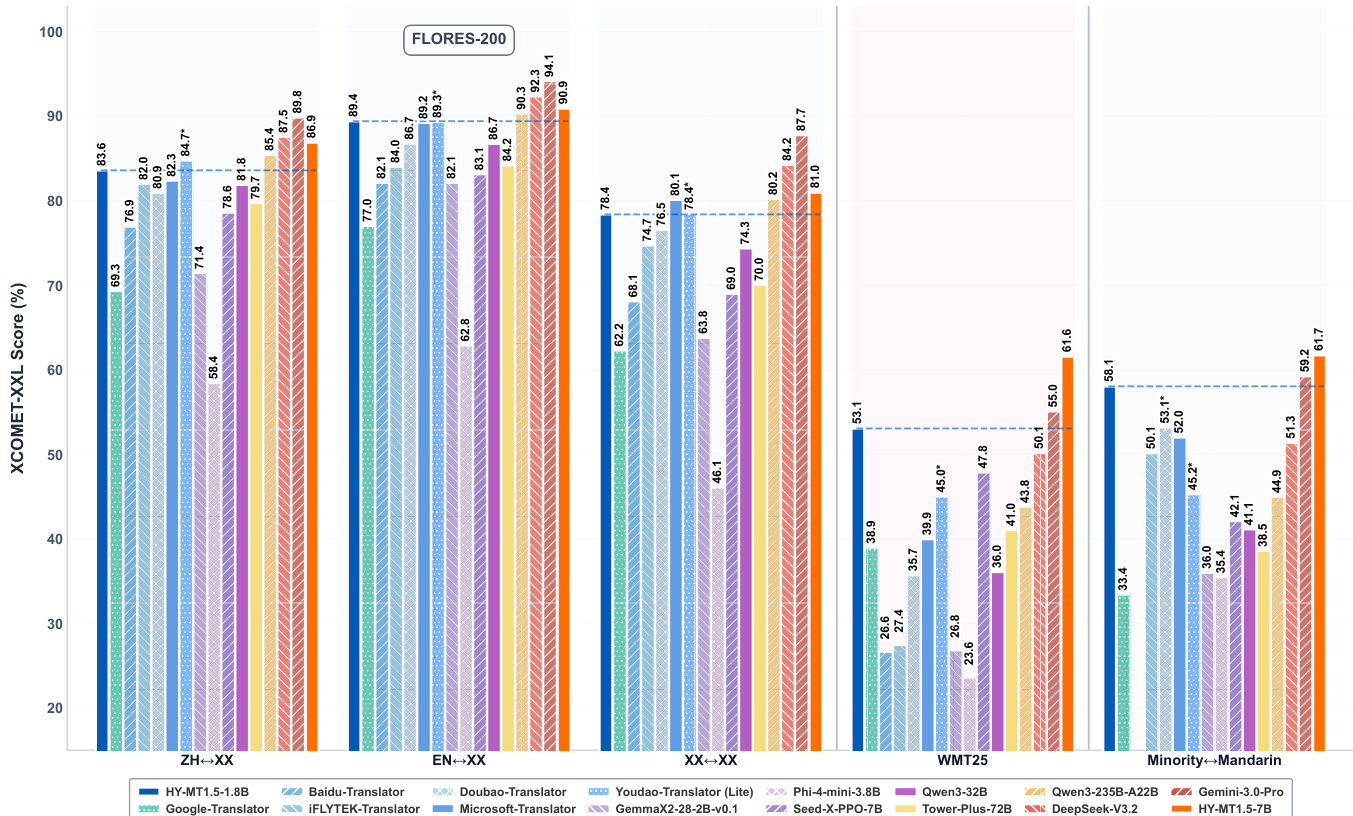
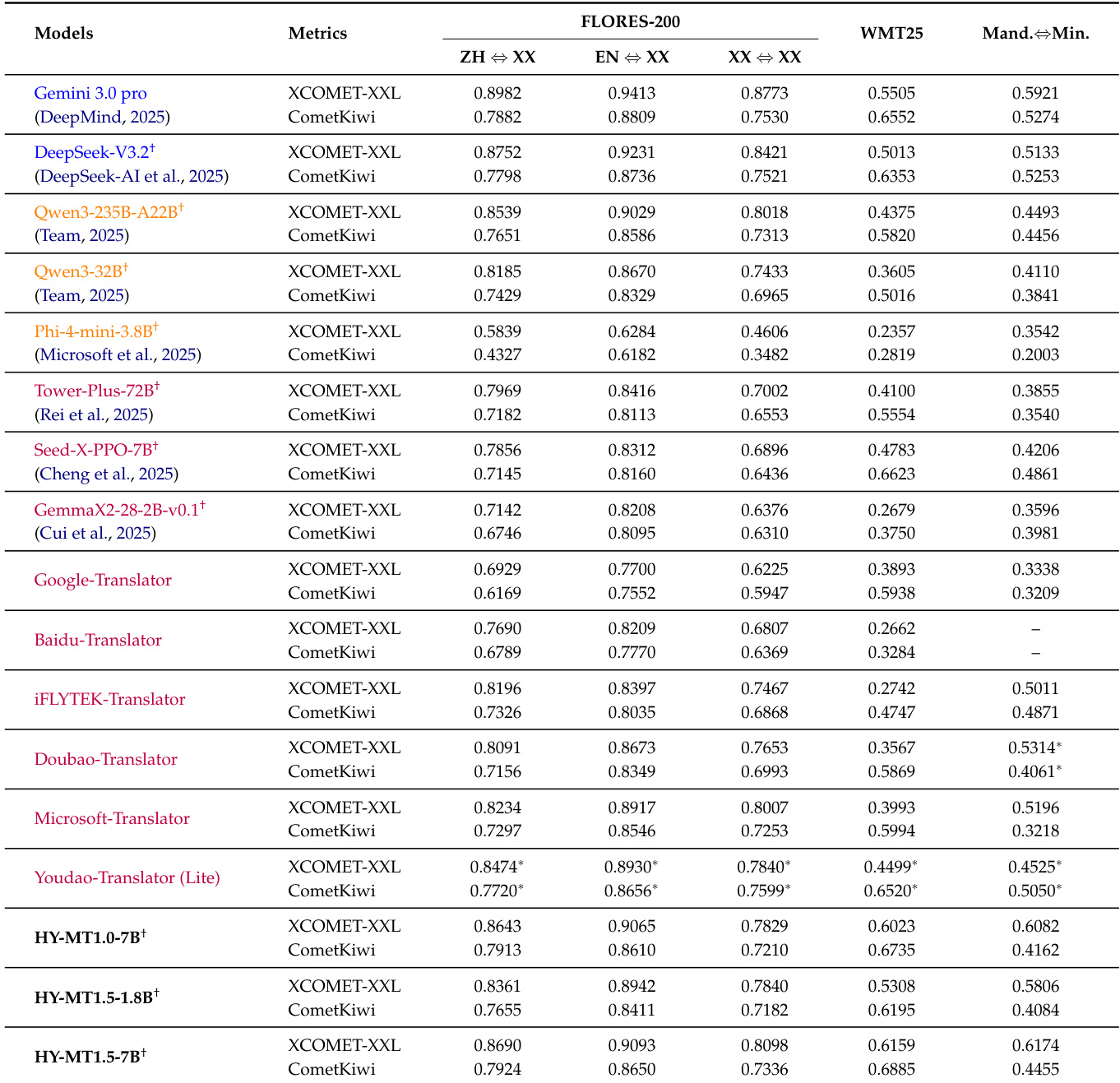
- HY-MT1.5-1.8B 和 HY-MT1.5-7B 在 Flores-200、WMT25 和中文-少数民族语言基准上验证,达到当前同规模最优性能:HY-MT1.5-7B 在 WMT25 上超越 Gemini-3.0-Pro(XCOMET-XXL 0.6159 vs 0.5505)及中文-少数民族翻译(0.6174 vs 0.5921);HY-MT1.5-1.8B 超越 Tower-Plus-72B 和豆包翻译等更大开源及商用模型。
- 人工评估确认 HY-MT1.5-1.8B 在中英翻译中领先商用系统(平均分 2.74),与自动指标一致。
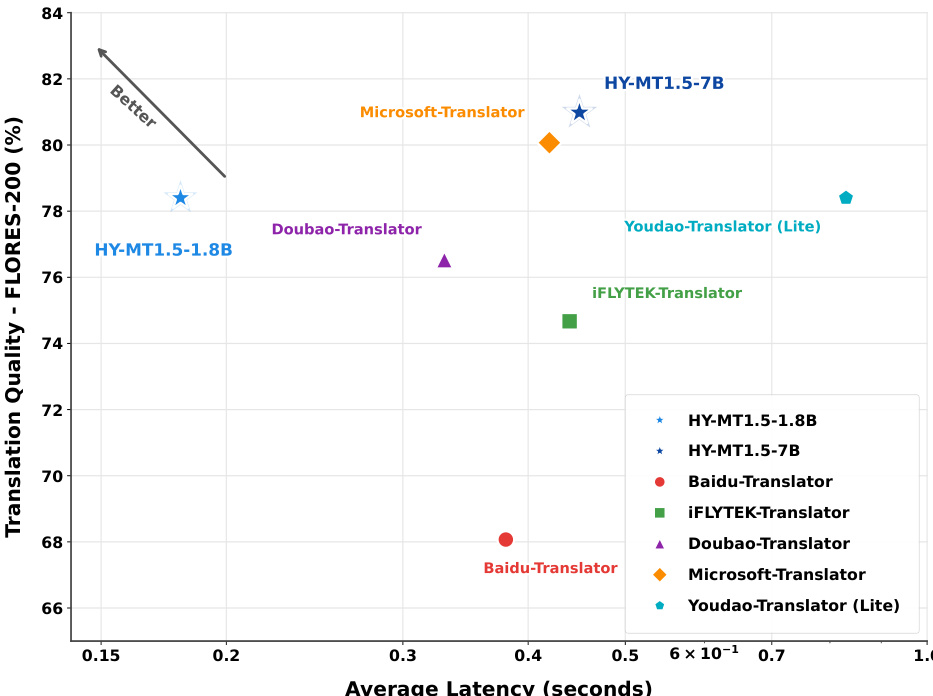
- 效率测试显示 HY-MT1.5-1.8B 在 0.18 秒内实现 78% Flores-200 质量,适合实时使用;HY-MT1.5-7B 在 0.45 秒内实现 >80% 质量,速度相近时优于微软翻译。
- 量化实验表明 FP8 保留近原始精度(如 ZH↔XX XCOMET-XXL 0.8379 vs 0.8361),而 Int4 明显退化,支持通过 FP8 部署至边缘设备。
作者使用 HY-MT1.5-1.8B 和 HY-MT1.5-7B 模型在多个基准上评估翻译性能,包括 Flores-200、WMT25 和中文-少数民族语言对。结果显示,HY-MT1.5-7B 在 WMT25 和中文-少数民族翻译中达到开源模型中的最优水平,优于 Tower-Plus-72B 和 Gemini 3.0 Pro 等更大模型;而 HY-MT1.5-1.8B 展现出强劲效率,兼具竞争性质量与快速推理速度。
作者使用 HY-MT1.5-1.8B 和 HY-MT1.5-7B 模型评估翻译质量与效率,结果表明 HY-MT1.5-1.8B 在低延迟下实现高质量翻译,HY-MT1.5-7B 在适度增加响应时间下提供更优质量。两模型均优于多个商用及开源基线,展现出性能与速度的良好平衡。
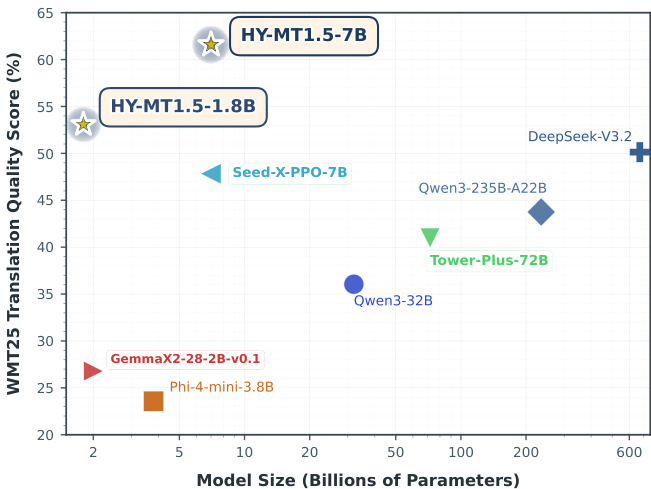
结果显示,HY-MT1.5-7B 在 WMT25 上的翻译质量得分为 61.59%,显著优于所有对比模型,包括超大规模通用模型 Gemini 3.0 Pro 和翻译专用模型 Tower-Plus-72B。较小的 HY-MT1.5-1.8B 模型在 WMT25 上得分为 53.08%,仍优于许多中型和小型通用及翻译专用模型。
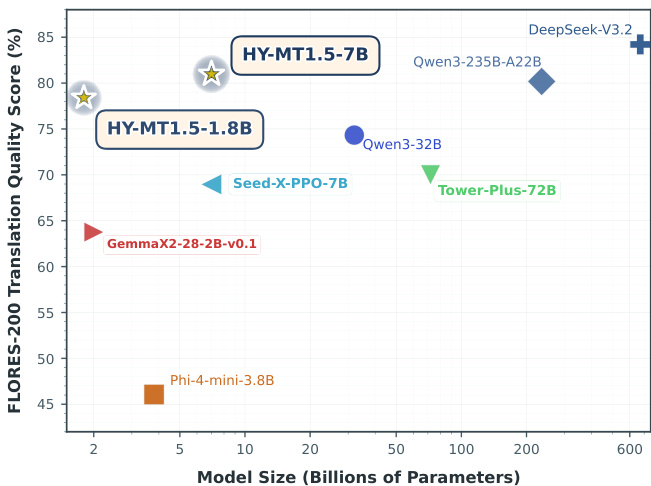
结果显示,HY-MT1.5-1.8B 在 18 亿参数规模下于 FLORES-200 上取得约 78% 的翻译质量得分,展现高参数效率;HY-MT1.5-7B 在 70 亿参数下得分约 86%,优于 Qwen3-32B 和 Tower-Plus-72B 等更大模型,同时相对 DeepSeek-V3.2 等超大规模模型仍保持竞争力。
作者使用表格对比 HY-MT1.5 模型与各基线在 Flores-200 和 WMT25 基准上的表现,显示 HY-MT1.5-7B 在所有翻译方向上均取得高分,优于包括 Tower-Plus-72B 和 Gemini 3.0 Pro 在内的多数模型。结果亦表明 HY-MT1.5-1.8B 表现具有竞争力,尤其在 WMT25 上,尽管规模更小,仍超越许多中型和小型模型。